PaddleOCR手写文字识别
- 一. 项目背景
- 二. 环境配置
- 三. 数据构造
- 四. 模型微调
- 五. 串联推理
- 六. 注意事项
- 七. 参考文献
光学字符识别(Optical Character Recognition, OCR),ORC是指对包含文本资料的图像文件进行分析识别处理,获取文字及版面信息的技术,检测图像中的文本资料,并且识别出文本的内容。

PaddleOCR提供的PP-OCR系列模型在通用场景中性能优异,能够解决绝大多数情况下的检测与识别问题。在垂类场景中,如果希望获取更优的模型效果,可以通过模型微调的方法,进一步提升PP-OCR系列检测与识别模型的精度。
一. 项目背景
目前先进的OCR模型在打印体的识别上已经能获得比较好的效果,但由于手写体的风格各异,提高手写体的识别精度具有比较高的挑战。因此需要基于手写数据微调预训练模型,从而提高手写文字的识别效果。

二. 环境配置
1. 安装PaddlePaddle 2.0
在官网上找到对应版本的PaddlePaddle进行安装。
2.克隆PaddleOCR repo代码
【推荐】git clone https://github.com/PaddlePaddle/PaddleOCR
如果因为网络问题无法pull成功,也可选择使用码云上的托管:git clone https://gitee.com/paddlepaddle/PaddleOCR
注:码云托管代码可能无法实时同步本github项目更新,存在3~5天延时,请优先使用推荐方式。
3. 安装第三方库
cd PaddleOCR
pip3 install -r requirements.txt
三. 数据构造
AIstudio上有开源的手写OCR识别数据集:https://aistudio.baidu.com/datasetdetail/102884,由中科院手写数据集及网上开源数据组合而成。训练共24w,测试1.7w,可直接使用paddleOCR训练。
在实际的场景中,我们往往有针对特定场景的数据,因此需要对数据进行标注和分割。PPOCRLabel内置了OCR模型,可以辅助标注。
PPOCRLabel官方文档:https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.7/PPOCRLabel/README_ch.md
1. 安装与运行PPOCRLabel
Windows
pip install PPOCRLabel # 安装
# 选择标签模式来启动
PPOCRLabel --lang ch # 启动【普通模式】,用于打【检测+识别】场景的标签
PPOCRLabel --lang ch --kie True # 启动 【KIE 模式】,用于打【检测+识别+关键字提取】场景的标签
Ubuntu Linux
pip3 install PPOCRLabel
pip3 install trash-cli
# 选择标签模式来启动
PPOCRLabel --lang ch # 启动【普通模式】,用于打【检测+识别】场景的标签
PPOCRLabel --lang ch --kie True # 启动 【KIE 模式】,用于打【检测+识别+关键字提取】场景的标签
MacOS
pip3 install PPOCRLabel
pip3 install opencv-contrib-python-headless==4.2.0.32 # 如果下载过慢请添加"-i https://mirror.baidu.com/pypi/simple"
# 选择标签模式来启动
PPOCRLabel --lang ch # 启动【普通模式】,用于打【检测+识别】场景的标签
PPOCRLabel --lang ch --kie True # 启动 【KIE 模式】,用于打【检测+识别+关键字提取】场景的标签
2. 基于PPOCRLabel的数据标注
下面以五张图片为例介绍一下数据标注过程,首先点击文件->打开目录打开图片所在的文件夹。

点击PaddleOCR->选择模型选择模型语言(每次打开软件都需要选择),点击自动标注。

然后对识别不准确的部分进行手动调整,可以调整检测框,也可以调整右侧的识别结果。比如图片中的“沧海桑田”识别有误,则我们人为进行修改。调整完毕后点击确认按钮保存。
3. 导出标注结果
点击文件按钮,可以看到导出标记结果和导出识别结果两项,分别用于导出文本检测的标签和文本识别的标签。导出后文件内容如图所示:
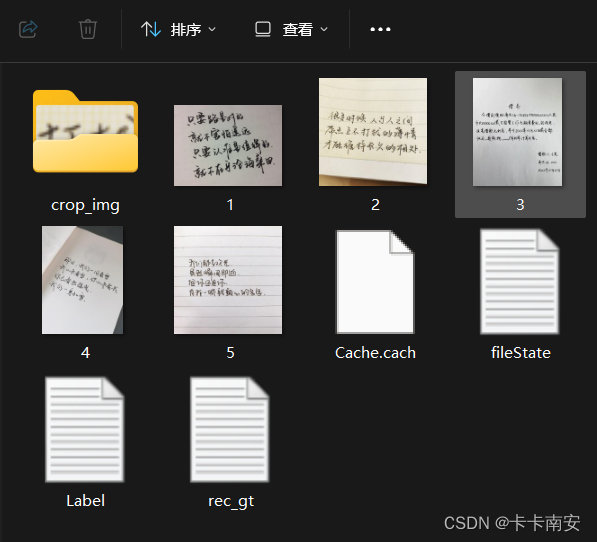
⭐请勿手动更改其中内容,否则会引起程序出现异常
| 文件名 | 说明 |
|---|---|
| Label.txt | 检测标签,可直接用于PPOCR检测模型训练。用户每确认5张检测结果后,程序会进行自动写入。当用户关闭应用程序或切换文件路径后同样会进行写入。 |
| fileState.txt | 图片状态标记文件,保存当前文件夹下已经被用户手动确认过的图片名称。 |
| Cache.cach | 缓存文件,保存模型自动识别的结果。 |
| rec_gt.txt | 识别标签。可直接用于PPOCR识别模型训练。需用户手动点击菜单栏“文件” - "导出识别结果"后产生。 |
| crop_img | 识别数据。按照检测框切割后的图片。与rec_gt.txt同时产生。 |
4. 数据集划分
cd ./PPOCRLabel # 将目录切换到PPOCRLabel文件夹下
python gen_ocr_train_val_test.py --trainValTestRatio 6:2:2 --datasetRootPath ../train_data
参数说明:
-
trainValTestRatio 是训练集、验证集、测试集的图像数量划分比例,根据实际情况设定,默认是6:2:2
-
datasetRootPath 是PPOCRLabel标注的完整数据集存放路径。默认路径是
PaddleOCR/train_data分割数据集前应有如下结构:
|-train_data
|-crop_img
|- word_001_crop_0.png
|- word_002_crop_0.jpg
|- word_003_crop_0.jpg
| ...
| Label.txt
| rec_gt.txt
|- word_001.png
|- word_002.jpg
|- word_003.jpg
| ...
在运行前,需要修改gen_ocr_train_val_test.py中第42行:
imagePath = os.path.join(dataAbsPath, "{}\\{}".format(args.recImageDirName, imageName))
修改为:
imagePath = os.path.join(dataAbsPath, "{}/{}".format(args.recImageDirName, imageName))
否则图片读取时会报路径错误。
运行结束后,train_data文件夹中会出现名为det和rec的文件夹中,文件夹中分别存放文本检测和文本识别对应的图片和分割后的训练集、验证集和验证集列表。
|-train_data
| ...
|-det
|- train
|- 训练集图片
|- val
|- 验证集图片
|- test
|- 测试集图片
|- train.txt
|- val.txt
|- test.txt
|-rec
| ...
| ...
至此,数据集就已经构建完成,根据不同的任务可直接使用paddleOCR训练。
四. 模型微调
OCR识别主要分为三个部分,分别是文本检测、文本方向分类、文本识别。PPOCR模型在文本检测和文本方向分类已经能达到比较好的效果,因此本文仅针对文本识别进行微调,另外两个任务的微调方法与之相同。本案例采用开源的手写OCR识别数据集:https://aistudio.baidu.com/datasetdetail/102884
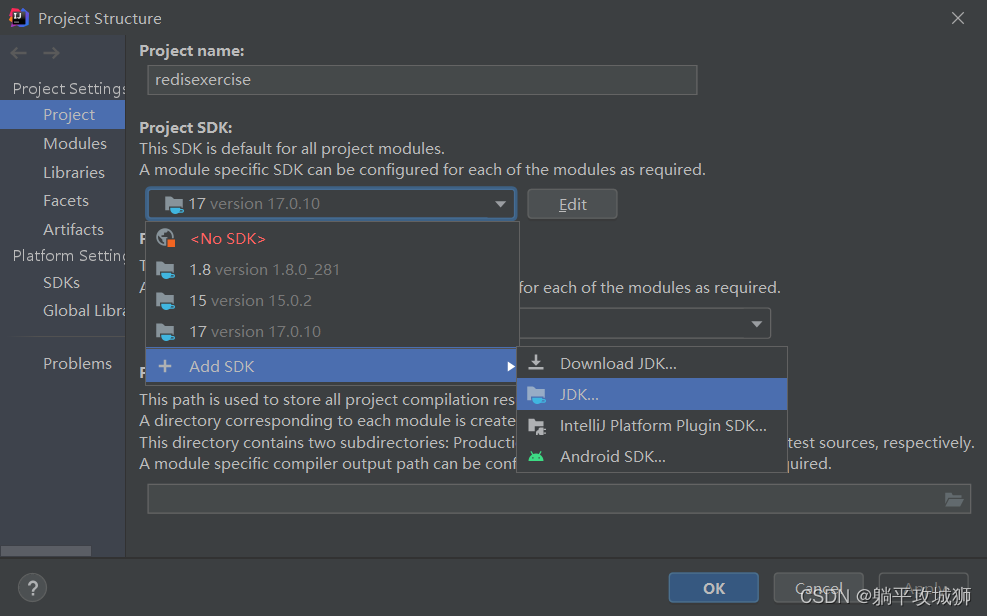
1.下载预训练模型
可使用的模型参考模型列表,本文采用PPOCRv4作为预训练模型:
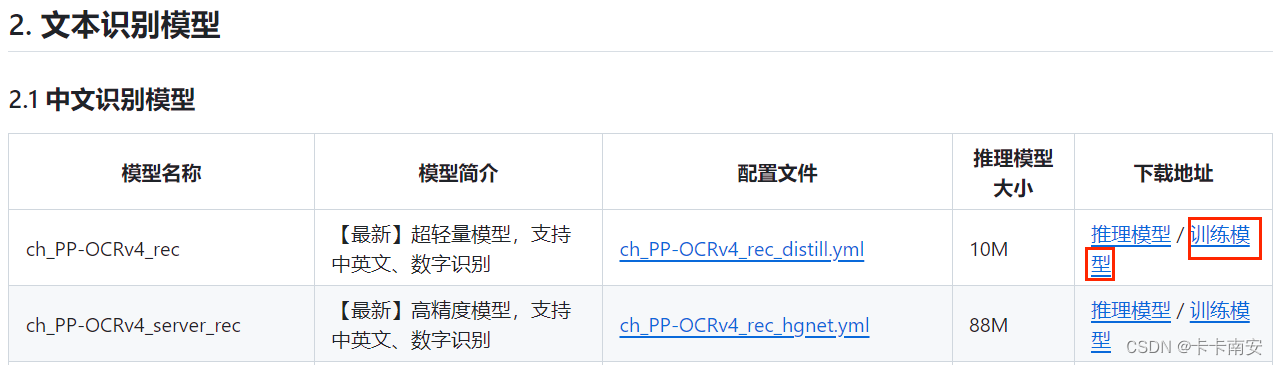
cd PaddleOCR
# 使用该指令下载需要的预训练模型
wget -P ./pretrained_models/ https://paddleocr.bj.bcebos.com/PP-OCRv4/chinese/ch_PP-OCRv4_rec_train.tar
# 解压预训练模型文件
tar -xf ./pretrained_models/ch_PP-OCRv4_rec_train.tar -C pretrained_models
2.参数配置
由上图可得,该模型所对应的配置文件为ch_PP-OCRv4_rec_distill.yml,但是在运行时发生错误,测试后发现该模型所对应的配置文件实际为ch_PP-OCRv4_rec.yml。
主要修改训练轮数和学习率参相关参数,设置预训练模型路径,设置数据集路径。 另外,batch_size可根据自己机器显存大小进行调整。 具体修改如下几个地方:
epoch_num: 100 # 训练epoch数
save_model_dir: ./output/ch_PP-OCR_v4_rec
save_epoch_step: 10
eval_batch_step: [0, 100] # 评估间隔,每隔100step评估一次
pretrained_model: ./pretrained_models/ch_PP-OCRv4_rec_train/student # 预训练模型路径
lr:
name: Cosine # 修改学习率衰减策略为Cosine
learning_rate: 0.0001 # 修改fine-tune的学习率
warmup_epoch: 2 # 修改warmup轮数
Train:
dataset:
name: SimpleDataSet
data_dir: ./train_data # 训练集图片路径
ext_op_transform_idx: 1
label_file_list:
- ./train_data/chineseocr-data/rec_hand_line_all_label_train.txt # 训练集标签
- ./train_data/handwrite/HWDB2.0Train_label.txt
- ./train_data/handwrite/HWDB2.1Train_label.txt
- ./train_data/handwrite/HWDB2.2Train_label.txt
- ./train_data/handwrite/hwdb_ic13/handwriting_hwdb_train_labels.txt
- ./train_data/handwrite/HW_Chinese/train_hw.txt
Eval:
dataset:
name: SimpleDataSet
data_dir: ./train_data # 测试集图片路径
label_file_list:
- ./train_data/chineseocr-data/rec_hand_line_all_label_val.txt # 测试集标签
- ./train_data/handwrite/HWDB2.0Test_label.txt
- ./train_data/handwrite/HWDB2.1Test_label.txt
- ./train_data/handwrite/HWDB2.2Test_label.txt
- ./train_data/handwrite/hwdb_ic13/handwriting_hwdb_val_labels.txt
- ./train_data/handwrite/HW_Chinese/test_hw.txt
由于数据集大多是长文本,因此需要注释掉下面的数据增广策略,以便训练出更好的模型。
- RecConAug:
prob: 0.5
ext_data_num: 2
image_shape: [48, 320, 3]
3.模型训练
我们使用上面修改好的配置文件configs/rec/PP-OCRv4/ch_PP-OCRv4_rec.yml,预训练模型,数据集路径,学习率,训练轮数等都已经设置完毕后,可以使用下面命令开始训练:
# 开始训练识别模型
python3 tools/train.py -c configs/rec/PP-OCRv4/ch_PP-OCRv4_rec.yml
如果训练中断,可采用checkpoints恢复训练:
# 开始训练识别模型
python3 tools/train.py -c configs/rec/PP-OCRv4/ch_PP-OCRv4_rec.yml -o Global.checkpoints="./output/rec_ppocr_v4/best_accuracy"
4.模型验证
验证模型在验证集上的效果:
python3 tools/eval.py -c configs/rec/PP-OCRv4/ch_PP-OCRv4_rec.yml -o Global.pretrained_model="./output/rec_ppocr_v4/best_accuracy"
5.模型导出
将训练模型导出为推理模型:
python3 tools/export_model.py -c configs/rec/PP-OCRv4/ch_PP-OCRv4_rec.yml -o Global.pretrained_model="./output/rec_ppocr_v4/best_accuracy" Global.save_inference_dir="./inference/ch_PP-OCRv4_rec/"

6.模型推理
python3 tools/infer/predict_rec.py --image_dir="./train_data/handwrite/HWDB2.0Test_images/104-P16_4.jpg" --rec_model_dir="./inference/ch_PP-OCRv4_rec/"
五. 串联推理
模型推理部分官方文档:基于Python引擎的PP-OCR模型库推理
在分别得到文本检测、文本方向分类、文本识别的推理模型后,即可将三者串联起来进行模型推理。
在执行预测时,需要通过参数image_dir指定单张图像或者图像集合的路径,也支持PDF文件、参数det_model_dir,cls_model_dir和rec_model_dir分别指定检测,方向分类和识别的inference模型路径。参数use_angle_cls用于控制是否启用方向分类模型。use_mp表示是否使用多进程(Paddle Inference并不是线程安全,建议使用多进程)。total_process_num表示在使用多进程时的进程数。可视化识别结果默认保存到 ./inference_results 文件夹里面。
在本案例中我们只微调了识别模型,因此在模型库中下载了基于PPOCRv4的文本检测和方向分类的推理模型。
# 使用方向分类器
python3 tools/infer/predict_system.py --image_dir="./train_data/handwrite/HWDB2.0Test_images/" --det_model_dir="./ch_PP-OCRv4_det_infer/" --cls_model_dir="./ch_ppocr_mobile_v2.0_cls_infer/" --rec_model_dir="./inference/ch_PP-OCRv4_rec/" --use_angle_cls=true
六. 注意事项
模型微调的注意事项和技巧参考:模型微调
在微调过程中,由于无法加载最后一层FC的参数,在迭代初期acc=0是正常的情况,不必担心,加载预训练模型依然可以加快模型收敛。
七. 参考文献
PaddleOCR官方文档
Paddle-OCR根据垂直类场景自定义数据微调PP-OCRv4模型
OCR手写文字识别



![[DevOps云实践] IaaC:通过CloudWatch Agent和自定义Metric监视服务器](https://img-blog.csdnimg.cn/direct/9c445477f592414cb16a8246d46d7b5a.png)