作者:Chris Hegarty
任何向量数据库的核心都是距离函数,它确定两个向量的接近程度。 这些距离函数在索引和搜索期间执行多次。 当合并段或在图表中导航最近邻居时,大部分执行时间都花在比较向量的相似性上。 对这些距离函数进行微观优化是值得的,我们已经从之前类似的优化中受益,例如 参见 SIMD、FMA。
随着 Lucene 和 Elasticsearch 最近对标量量化的支持,我们现在比以往任何时候都更加依赖这些距离函数的 byte 变体。 根据之前的经验,我们知道这些变体仍有显着性能改进的潜力。
目前的状况
当我们利用巴拿马向量 API 来加速 Lucene 中的距离函数时,大部分注意力都集中在 float(32 位)变体上。 我们对这些方面所取得的性能改进感到非常满意。 然而,字节(8 位)变体的改进有点令人失望 - 相信我,我们尝试过! 字节变体的根本问题是它们没有充分利用 CPU 上可用的最佳 SIMD 指令。
在 Java 中进行算术运算时,最窄的类型是 int(32位)。 JVM 自动将字节值符号扩展为 int 类型的值。 考虑这个简单的标量点积实现:
int dotProduct(byte[] a, byte[] b) {
int res = 0;
for (int i = 0; i < a.length; i++) {
res += a[i] * b[i];
}
return res;
}a 和 b 中的元素相乘的执行方式就好像 a 和 b 都是 int 类型一样,其值是从符号扩展为 int 的相应数组索引加载的字节值。
我们的 SIMD 化实现必须是等效的,因此我们需要小心确保在乘以大字节值时不会丢失溢出。 我们通过显式地将加载的字节值扩展为 short(16位)来做到这一点,因为我们知道所有带符号的字节值相乘时都将适合带符号的 short 而不会丢失。 然后我们在累加时需要进一步扩展为 int (32 位)。
以下是 Lucene 128 位点积代码内循环体的摘录:
ByteVector va8 = ByteVector.fromArray(ByteVector.SPECIES_64, a, i);
ByteVector vb8 = ByteVector.fromArray(ByteVector.SPECIES_64, b, i);
// process first "half" only: 16-bit multiply
Vector<Short> va16 = va8.convert(B2S, 0); // B2S Byte2Short
Vector<Short> vb16 = vb8.convert(B2S, 0);
Vector<Short> prod16 = va16.mul(vb16);
// 32-bit add - S2I Short2Int
acc = acc.add(prod16.convertShape(S2I, IntVector.SPECIES_128, 0));可视化这一点,我们可以看到我们一次只处理 4 个元素。 例如:
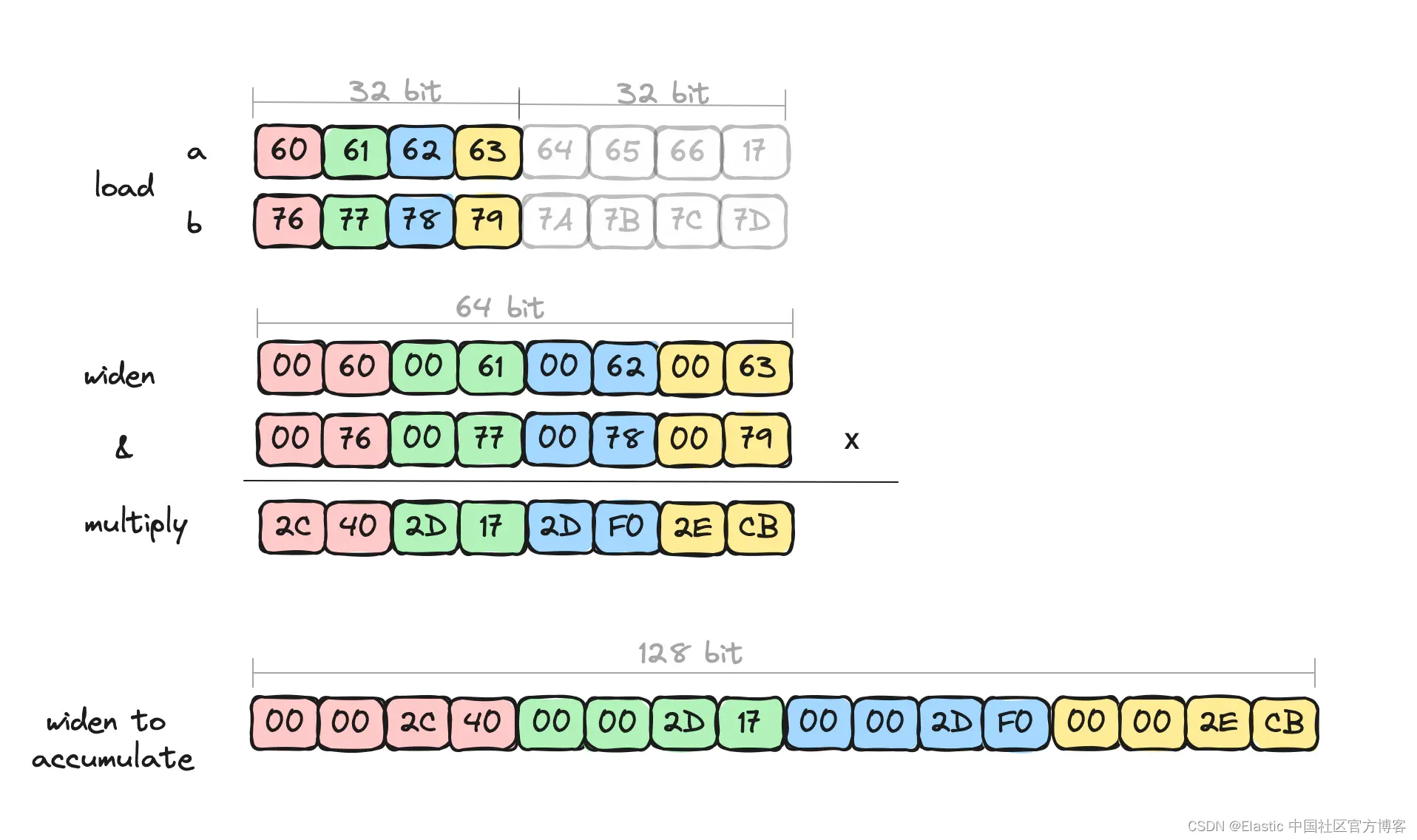
这一切都很好,即使有了这些显式的扩展对话,我们也可以通过算术运算的额外数据并行性获得一些不错的速度,只是没有我们知道的那么快。 我们知道还有剩余潜力的原因是,每次拓宽都会使车道数量减半,这实际上将算术运算的数量减半。 JVM 的 C2 JIT 编译器并未优化显式扩展对话。 此外,我们仅访问数据的下半部分 - 访问下半部分以外的任何内容都不会产生良好的机器代码。 这就是我们将潜在性能 “摆在桌面上” 的地方。
目前,这已经是我们在 Java 中所能做到的最好的了。 从长远来看,Panama Vector API 和/或 C2 JIT 编译器应该为此类操作提供更好的支持,但至少目前,这已经是我们能做的最好的了。 或者是吗?
介绍(另一个)巴拿马 API - FFM
OpenJDK 的巴拿马项目有几个不同的分支,我们已经看到了巴拿马向量 API 的实际应用,但该项目的旗舰是 Foregin Function and Memory API (FFM)。 FFM API 为与 Java 运行时之外的代码和内存交互提供了较低的开销。 JVM 是一项令人惊叹的工程,它抽象了架构和平台之间的许多差异,但有时它并不总是能够做出最佳权衡,这是可以理解的。 当 JVM 无法轻易做到这一点时,FFM 可以拯救我们,如果程序员不喜欢所做的权衡,那么她可以将事情掌握在自己手中。 这就是这样一个领域,巴拿马向量 API 的权衡对于 byte 大小的向量来说并不合适。
我们已经在利用 Lucene 中的外部内存支持来协调对映射的堆外索引数据的更安全的访问。 为什么不使用外部调用支持来调用已经优化的距离计算函数? 由于我们的距离计算函数很小,并且对于我们已经知道最佳 CPU 指令集的某些部署和架构集,为什么不只编写我们想要的一小块本机代码。 然后通过外部调用API来调用它。
采用外部函数 - going foregin
Elastic Cloud 具有针对向量搜索优化的配置文件。 此配置文件针对 ARM 架构,因此让我们看看如何对此进行优化。
让我们使用一些 ARM Neon 内在函数用 C 语言编写距离函数(例如点积)。 同样,我们将重点关注循环的内部主体。 看起来是这样的:
int32x4_t acc1, acc2 // = vdupq_n_s32(0);
...
// Read into 16 x 8 bit vectors.
int8x16_t va8 = vld1q_s8((const void*)(a + i));
int8x16_t vb8 = vld1q_s8((const void*)(b + i));
int16x8_t va16 = vmull_s8(vget_low_s8(va8), vget_low_s8(vb8));
int16x8_t vb16 = vmull_s8(vget_high_s8(va8), vget_high_s8(vb8));
// Accumulate 4 x 32 bit vectors (adding adjacent 16 bit lanes).
acc1 = vpadalq_s16(acc1, va16);
acc2 = vpadalq_s16(acc2, vb16);我们将 a 和 b 向量中的 16 个 8 位值分别加载到 va8 和 vb8 中。 然后,我们将下半部分相乘并将结果存储在 va16 中 - 该结果包含 8 个 16 位值,并且该操作隐式处理加宽。 与上半部分类似。 最后,由于我们对完整的原始 16 个值进行操作,因此使用两个累加器来存储结果会更快。 vpadalq_s16 加法和累加内在函数知道如何在累加到 4 个 32 位值时隐式扩展。 总之,我们在每个循环迭代中对所有 16 字节值进行了操作。 好的!
其反汇编非常干净并且反映了上述本质。
ldr q2, [x1, x8] # loads first vector data into 128-bit q2
ldr q3, [x2, x8] # loads second vector data into 128-bit q3
smull.8h v4, v2, v3 # multiplies low half, result in v4
smull2.8h v2, v2, v3 # multiplies high half, result in v2
sadalp.4s v0, v4 # accumulates into v0
sadalp.4s v1, v2 # accumulates into v1ARM 上的 Neon SIMD 具有算术指令,可以提供我们想要的语义,而无需进行额外的显式扩展。 C 内联公开了这些指令,以便我们可以利用的方式使用这些指令。 对密集包含值的寄存器进行的操作比我们使用巴拿马向量 API 所做的要干净得多。
回到 Java-land
最后一个难题是 Java 中的一个小 “垫片 (shim)” 层,它使用 FFM API 链接到我们的外部代码。 我们的向量数据是堆外的,我们将其映射到 MemorySegment,并根据向量维度确定偏移量和内存地址
static int dot8s(MemorySegment a, MemorySegment b, int dims) {
var mh$ = dot8s$MH();
try {
return (int)mh$.invokeExact(a, b, dims);
} catch (Throwable ex$) {
...
}
}我们还有更多的工作要做,因为现在这是特定于平台的 Java 代码,因此我们仅在 aarch64 平台上执行它,而回退到其他平台上的替代实现。
那么它实际上比巴拿马向量代码更快吗?
性能
上述有符号字节值的点积的微观基准显示,与巴拿马向量代码相比,性能提高了大约 6 倍。 这包括外部呼叫的开销。 加速的主要原因是我们能够将完整的 128 位寄存器与值打包在一起,并对所有这些值进行操作,而无需显式移动或扩展数据。
启用标量量化的宏基准测试 SO_Dense_Vector 显示出合并时间的显着改进,大约快了 3 倍 - 该实验仅插入了用于段合并的优化点积。 我们预计搜索基准也会有所改善。
概括
Java 的最新进展,即 FFM API,允许以比以前更高性能和更简单的方式与本机代码进行互操作。 通过提供通过 FFM 调用的微优化平台特定向量距离函数,可以获得显着的性能优势。
我们期待 Elasticsearch 的未来版本,其中标量量化向量可以利用这种性能改进。 当然,我们正在大量思考这与 Lucene 甚至巴拿马向量 API 的关系,以确定如何改进这些。
原文:Vector Similarity Computations - ludicrous speed — Elastic Search Labs
![[DevOps云实践] IaaC:通过CloudWatch Agent和自定义Metric监视服务器](https://img-blog.csdnimg.cn/direct/9c445477f592414cb16a8246d46d7b5a.png)