1.主从集群
集群结构:
一.单机安装redis
1.上传压缩包并解压,编译

tar -xzf redis-6.2.4.tar.gz
cd redis-6.2.4
make && make install2.修改redis.config的配置并启动redis
# 绑定地址,默认是127.0.0.1,会导致只能在本地访问。修改为0.0.0.0则可以在任意IP访问
bind 0.0.0.0
# 保护模式,关闭保护模式
protected-mode no
# 数据库数量,设置为1
databases 1redis-server redis.conf二.准备实例和配置
要在同一台虚拟机开启3个实例,必须准备三份不同的配置文件和目录,配置文件所在目录也就是工作目录。
1.创建目录
我们创建三个文件夹,名字分别叫7001、7002、7003:
# 进入/tmp目录
cd /tmp
# 创建目录
mkdir 7001 7002 70032.恢复原始配置
# 开启RDB
# save ""
save 3600 1
save 300 100
save 60 10000
# 关闭AOF
appendonly no3.拷贝配置文件到每个实例目录
# 方式一:逐个拷贝
cp redis-6.2.4/redis.conf 7001
cp redis-6.2.4/redis.conf 7002
cp redis-6.2.4/redis.conf 7003
# 方式二:管道组合命令,一键拷贝
echo 7001 7002 7003 | xargs -t -n 1 cp redis-6.2.4/redis.conf4.修改每个实例的端口、工作目录
修改每个文件夹内的配置文件,将端口分别修改为7001、7002、7003,将rdb文件保存位置都修改为自己所在目录(在/tmp目录执行下列命令):
sed -i -e 's/6379/7001/g' -e 's/dir .\//dir \/tmp\/7001\//g' 7001/redis.conf
sed -i -e 's/6379/7002/g' -e 's/dir .\//dir \/tmp\/7002\//g' 7002/redis.conf
sed -i -e 's/6379/7003/g' -e 's/dir .\//dir \/tmp\/7003\//g' 7003/redis.conf5.修改每个实例的声明IP
虚拟机本身有多个IP,为了避免将来混乱,我们需要在redis.conf文件中指定每一个实例的绑定ip信息
# 逐一执行
sed -i '1a replica-announce-ip ip' 7001/redis.conf
sed -i '1a replica-announce-ip ip' 7002/redis.conf
sed -i '1a replica-announce-ip ip' 7003/redis.conf三.开启主从关系
一.启动三个redis实例
# 第1个
redis-server 7001/redis.conf
# 第2个
redis-server 7002/redis.conf
# 第3个
redis-server 7003/redis.conf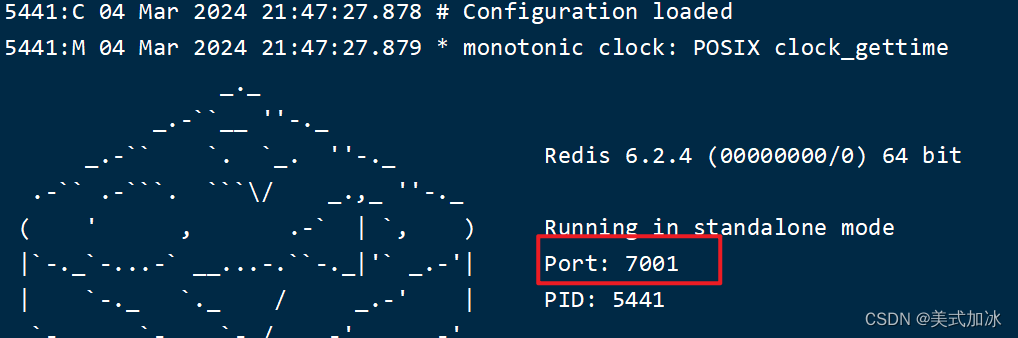

一键停止:
printf '%s\n' 7001 7002 7003 | xargs -I{} -t redis-cli -p {} shutdown现在三个实例还没有任何关系,要配置主从可以使用replicaof 或者slaveof(5.0以前)命令。
有临时和永久两种模式:
-
修改配置文件(永久生效)
-
在redis.conf中添加一行配置:
slaveof <masterip> <masterport>
-
-
使用redis-cli客户端连接到redis服务,执行slaveof命令(重启后失效):
slaveof <masterip> <masterport>在5.0以后新增命令replicaof,与salveof效果一致。
二.slaveof命令连接
连接7002与7003端口,并与7001做连接
# 连接 7002
redis-cli -p 7002
# 执行slaveof
slaveof ip 7001连接7001接口查看状态
# 连接 7001
redis-cli -p 7001
# 查看状态
info replication
三.测试:
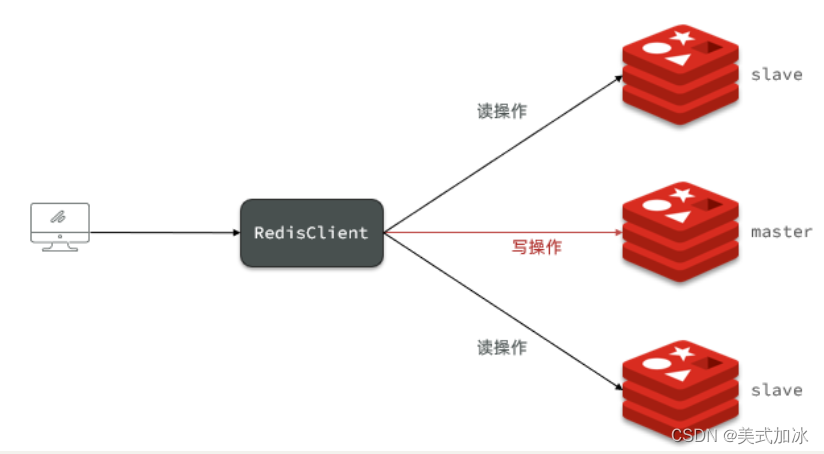
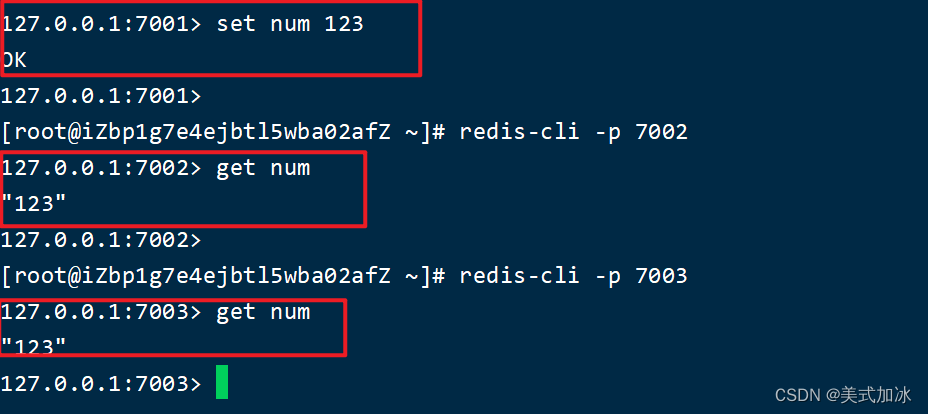
可以发现,只有在7001这个master节点上可以执行写操作,7002和7003这两个slave节点只能执行读操作。
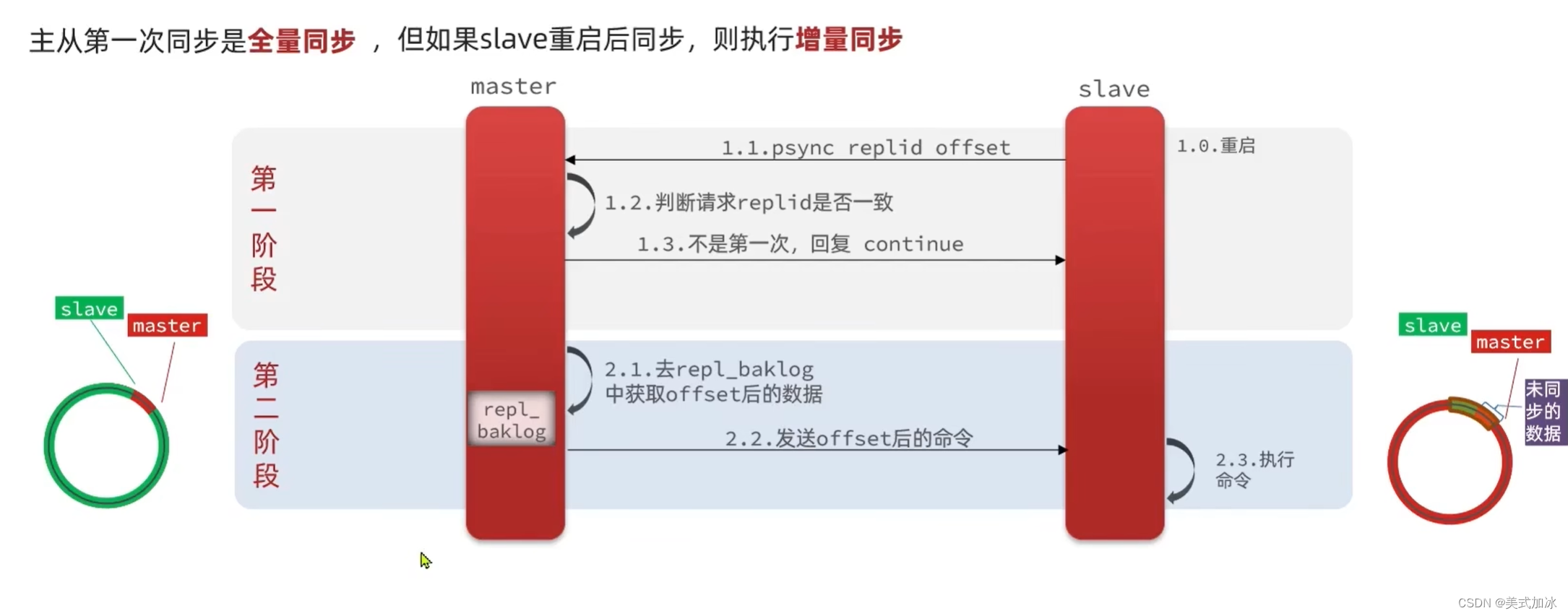
四:数据同步原理(全量同步,增量同步)
master通过Replication Id与offset来判断是否为第一次同步数据
Replication Id:简称replid,是数据集的标记,id一致表示是同一数据集,每一个master都有唯一的replid,slave会继承master节点的replid。
offset:偏移量,记录在repl_baklog中的数据增多而逐渐增大。slave完成同步时也会记录当前同步的offset,如果slave的offset小于master的offset,说明slave数据落后master,需要更新。
因此slave做数据同步,必须向master声明自己的replication id和offset,master才可以判断到底需要同步那些数据。
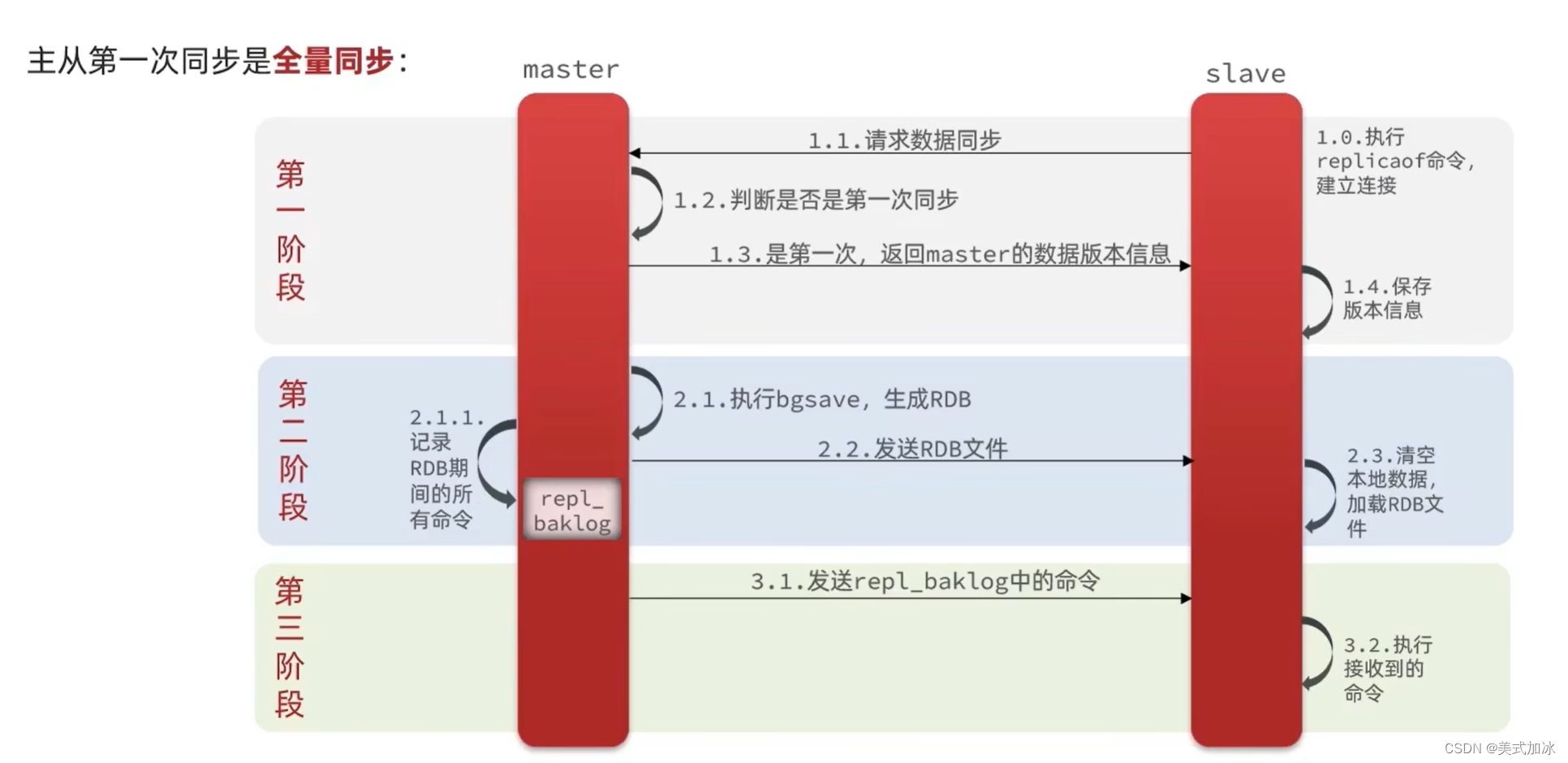
增量同步:将repl_baklog与offset之间记录的命令发送给slave去同步数据。