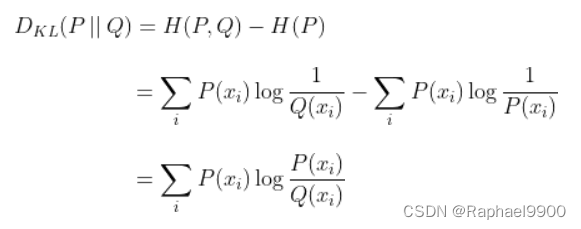文章目录
- 一、任务描述
- 1、介绍知识蒸馏
- 2、介绍架构设计
- 二、实验
- 1、simple baseline
- configs
- 结构设计
- 训练
- 2、medium baseline
- configs
- 3、strong baseline
- configs
- ReLu和leakyRelu
- 知识蒸馏
一、任务描述
●网络压缩:使您的模型更小而不损失性能。
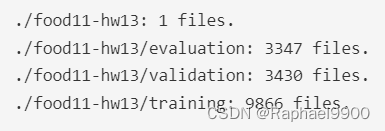
●在这个任务中,您需要训练一个非常小的模型来完成HW3(食物-11数据集上的图像分类)
●图像是从food-11数据集中收集到的11类。
●训练集: 9866张标记图像
●验证集: 3430张标记图像
●评估集: 3347张图像
●不试图找到测试集的原始标签。
●不使用任何外部数据集。
在网络压缩中有许多不同的技术:●知识蒸馏●架构设计●网络剪枝(报告Q3)●参数量化●动态计算
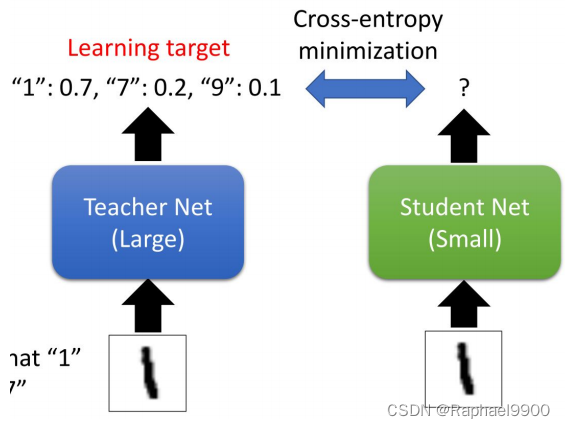
1、介绍知识蒸馏
●在训练一个小模型时,从大模型中提取一些信息(如预测的概率分布),以帮助小模型更好地学习。
●我们提供了一个训练有素的网络来帮助您进行知识蒸馏((test-Acc ≅ 0.899)。
●你可以随时训练你自己的教师网络,但是您不能使用任何预先训练过的模型或其他数据集。
2、介绍架构设计
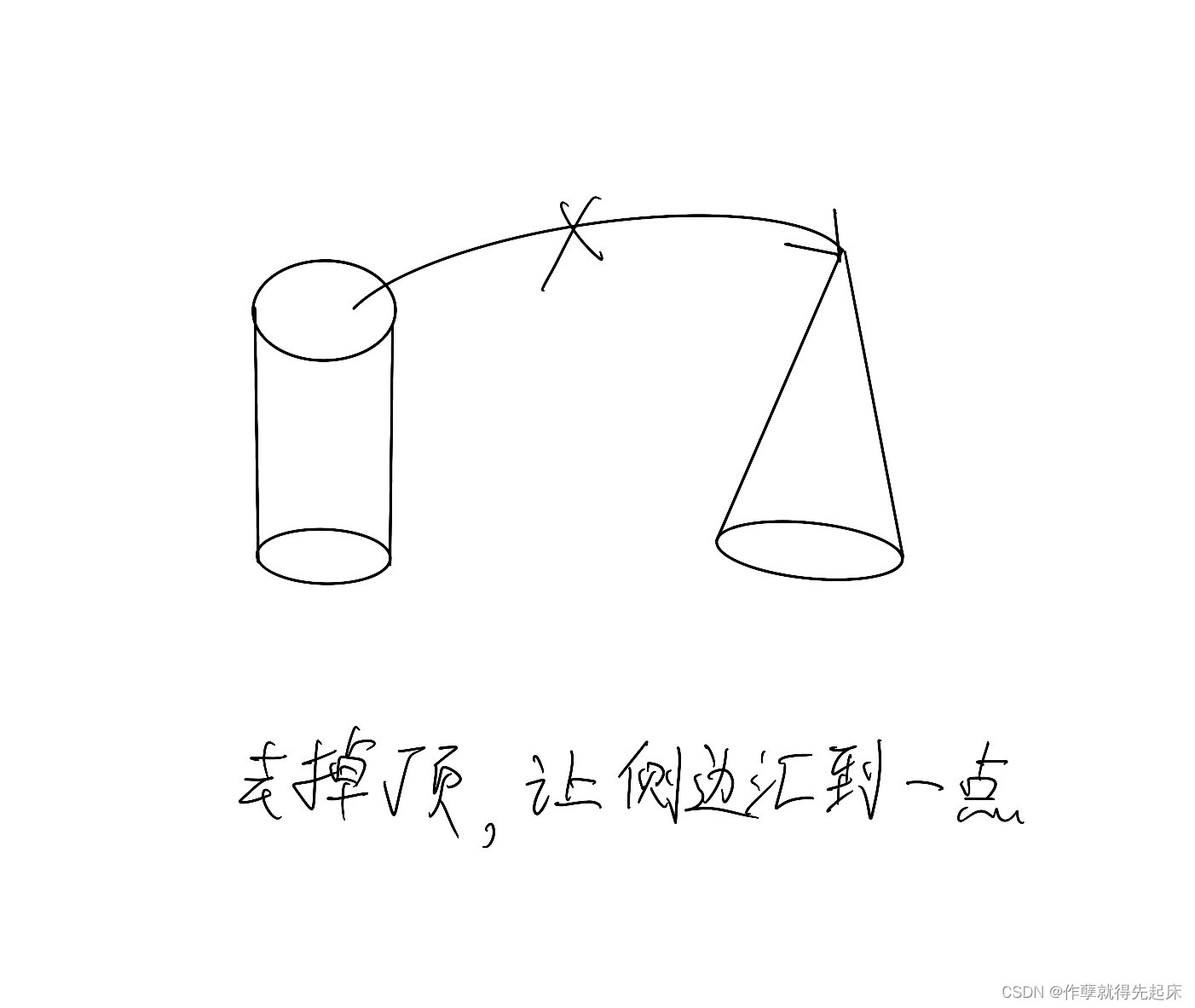
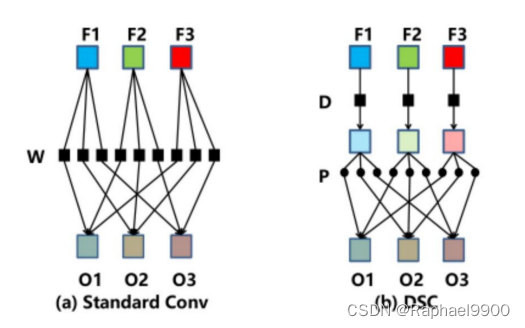
●Depthwise & Pointwise Convolution Layer
○您可以将原始卷积视为密集/线性层,但每一行/每个权值都是一个过滤器,原始乘法变成一个卷积运算。(输入权重→输入滤波器)
○Depthwise:让每个通道首先通过一个各自的滤波器,让每个像素通过共享权重的权重密集/线性。
○Pointwise是一个1x1的转换器。
●强烈建议您使用类似的技术来设计您的模型。(IOkk vs Ikk+IO)
●简单的基线(acc>0.44820,<1小时):○只需运行代码并提交。
●中等基线(acc>0.64840,<3小时):○完成KL散度损失函数,用于知识蒸馏、控制alpha & T和训练时间。
●强基线(acc>0.82370,8~12小时):○用深度和点方向的卷积修改模型体系结构。■你也可以从 MobileNet, ShuffleNet, DenseNet, SqueezeNet, GhostNet中获得伟大的想法。○你在HW3中学到的任何方法和技术。例如,在HW3中使用的超参数。
●最终基线(acc > 0.85159,不可测量):○实现其他高级的知识蒸馏■例如, FitNet, Relational KD, DML○让你的老师更强壮■如果你的老师太强壮,你可以考虑TAKD技术。
二、实验
1、simple baseline
configs
cfg = {
'dataset_root': '../input/ml2022spring-hw13/food11-hw13',
'save_dir': './outputs',
'exp_name': "simple_baseline",
'batch_size': 64,
'lr': 3e-4,
'seed': 20220013,
'loss_fn_type': 'CE', # simple baseline: CE
'weight_decay': 1e-5,
'grad_norm_max': 10,
'n_epochs': 10,
'patience': 300,
}
指定用于图像数据扩充的训练/测试变换。Torchvision为图像预处理、数据包装以及数据扩充提供了许多有用的工具。
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
# 定义 training/testing transforms
test_tfm = transforms.Compose([
#如果您使用提供的教师模型,不建议修改此部分。这个转换是标准的,对于测试来说足够好了。
transforms.Resize(256),#将输入图像调整到给定的大小。
transforms.CenterCrop(224),# 在中心裁剪给定图像。
transforms.ToTensor(),# 将PIL图像或numpy.ndarray转换为张量。
normalize,
])
train_tfm = transforms.Compose([
# add some useful transform or augmentation here, according to your experience in HW3.
transforms.Resize(256), # 您可以对此进行更改
transforms.CenterCrop(224), #您可以对此进行更改,但是要注意给定的教师模型的输入大小是224。
#所提供的教师模型的训练输入大小为(3,224,224)。
#因此,224以外的输入大小可能会影响性能。
transforms.RandomHorizontalFlip(), # 您可以对此进行更改,以给定的概率随机水平翻转给定的图像。
transforms.ToTensor(),
normalize,
])
结构设计
在这项作业中,你必须设计一个较小的网络,并使其运行良好。显然,一个设计良好的架构对于这样的任务是至关重要的。这里,我们介绍深度方向和点方向卷积。这些卷积的变体是网络压缩时架构设计的一些常用技术。
# Example implementation of Depthwise and Pointwise Convolution
def dwpw_conv(in_channels, out_channels, kernel_size, stride=1, padding=0):
return nn.Sequential(
nn.Conv2d(in_channels, in_channels, kernel_size, stride=stride, padding=padding, groups=in_channels), #depthwise convolution
nn.Conv2d(in_channels, out_channels, 1), # pointwise convolution
)
可以用深度方向和点方向卷积替换常规卷积层
class StudentNet(nn.Module):
def __init__(self):
super().__init__()
# ---------- TODO ----------
# Modify your model architecture
self.cnn = nn.Sequential(
nn.Conv2d(3, 32, 3),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.Conv2d(32, 32, 3),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0),
nn.Conv2d(32, 64, 3),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0),
nn.Conv2d(64, 100, 3),
nn.BatchNorm2d(100),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0),
#对各种输入大小采用全局平均池。
nn.AdaptiveAvgPool2d((1, 1)),
)
self.fc = nn.Sequential(
nn.Linear(100, 11),
)
def forward(self, x):
out = self.cnn(x)
out = out.view(out.size()[0], -1)
return self.fc(out)
def get_student_model(): #这个函数应该没有参数,这样我们就可以通过直接调用它来获得你的学生网络。
#你可以在这里修改或者做任何事情,只是记得返回一个nn。模块作为您的学生网络。
return StudentNet()
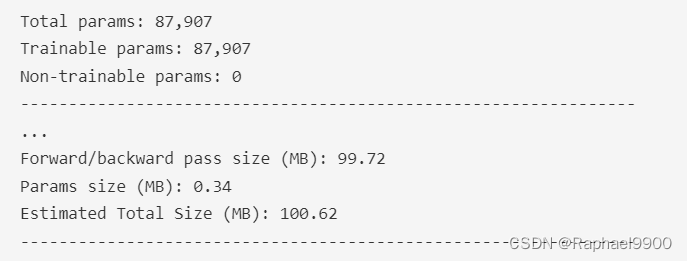
指定学生网络体系结构后,请使用“torchsummary”包获取网络信息并验证参数总数。请注意,您的学生网络的总参数不应超过限制(“torchsummary”中的“总参数”≤ 100,000)。
student_model = get_student_model()
summary(student_model, (3, 224, 224), device='cpu')
def loss_fn_kd(student_logits, labels, teacher_logits, alpha=0.5, temperature=1.0):
pass
训练
student_model.to(device)
optimizer = torch.optim.Adam(student_model.parameters(), lr=cfg['lr'], weight_decay=cfg['weight_decay'])
#初始化跟踪器,这些不是参数,不应更改
stale = 0
best_acc = 0.0
for epoch in range(n_epochs):
# ---------- Training ----------
# 确保模型在训练前处于训练模式。
student_model.train()
# 这些用于记录训练中的信息。
train_loss = []
train_accs = []
train_lens = []
for batch in tqdm(train_loader):
# 一batch包括图像数据和相应的标签。
imgs, labels = batch
imgs = imgs.to(device)
labels = labels.to(device)
logits = student_model(imgs)
# 计算cross-entropy loss.
# 我们不需要在计算交叉熵之前应用softmax,因为它是自动完成的。
loss = loss_fn(logits, labels) # SIMPLE BASELINE
# 应首先清除前一步骤中存储在参数中的梯度。
optimizer.zero_grad()
# 计算参数的梯度。
loss.backward()
# 修剪稳定训练的梯度标准。
grad_norm = nn.utils.clip_grad_norm_(student_model.parameters(), max_norm=cfg['grad_norm_max'])
# 用计算的梯度更新参数。
optimizer.step()
# 计算当前批次的准确度。
acc = (logits.argmax(dim=-1) == labels).float().sum()
# 记录损耗和准确度。
train_batch_len = len(imgs)
train_loss.append(loss.item() * train_batch_len)
train_accs.append(acc)
train_lens.append(train_batch_len)
train_loss = sum(train_loss) / sum(train_lens)
train_acc = sum(train_accs) / sum(train_lens)
# Print the information.
log(f"[ Train | {epoch + 1:03d}/{n_epochs:03d} ] loss = {train_loss:.5f}, acc = {train_acc:.5f}")
# ---------- Validation ----------
# 确保模型处于评估模式,以便像dropout这样的一些模块被禁用并正常工作。
student_model.eval()
# These are used to record information in validation.
valid_loss = []
valid_accs = []
valid_lens = []
# Iterate the validation set by batches.
for batch in tqdm(valid_loader):
# A batch consists of image data and corresponding labels.
imgs, labels = batch
imgs = imgs.to(device)
labels = labels.to(device)
#我们在验证中不需要梯度。
#使用torch.no_grad()加速前进过程。
with torch.no_grad():
logits = student_model(imgs)
loss = loss_fn(logits, labels) # SIMPLE BASELINE
# Compute the accuracy for current batch.
acc = (logits.argmax(dim=-1) == labels).float().sum()
# Record the loss and accuracy.
batch_len = len(imgs)
valid_loss.append(loss.item() * batch_len)
valid_accs.append(acc)
valid_lens.append(batch_len)
#break
# The average loss and accuracy for entire validation set is the average of the recorded values.
valid_loss = sum(valid_loss) / sum(valid_lens)
valid_acc = sum(valid_accs) / sum(valid_lens)
# update logs
if valid_acc > best_acc:
log(f"[ Valid | {epoch + 1:03d}/{n_epochs:03d} ] loss = {valid_loss:.5f}, acc = {valid_acc:.5f} -> best")
else:
log(f"[ Valid | {epoch + 1:03d}/{n_epochs:03d} ] loss = {valid_loss:.5f}, acc = {valid_acc:.5f}")
2、medium baseline
configs
cfg = {
'dataset_root': '../input/ml2022spring-hw13/food11-hw13',
'save_dir': './outputs',
'exp_name': "medium_baseline",
'batch_size': 64,
'lr': 3e-4,
'seed': 20220013,
'loss_fn_type': 'KD', #medium baseline: KD. use Knowledge_Distillation
'weight_decay': 1e-5,
'grad_norm_max': 10,
'n_epochs': 50, # train more steps to pass the medium baseline.
'patience': 30,
}

# Initialize a model, and put it on the device specified.
student_model.to(device)
teacher_model.to(device) # MEDIUM BASELINE
# Initialize optimizer, you may fine-tune some hyperparameters such as learning rate on your own.
optimizer = torch.optim.Adam(student_model.parameters(), lr=cfg['lr'], weight_decay=cfg['weight_decay'])
# Initialize trackers, these are not parameters and should not be changed
stale = 0
best_acc = 0.0
teacher_model.eval() # MEDIUM BASELINE
for epoch in range(n_epochs):
# ---------- Training ----------
# Make sure the model is in train mode before training.
student_model.train()
# These are used to record information in training.
train_loss = []
train_accs = []
train_lens = []
for batch in tqdm(train_loader):
# A batch consists of image data and corresponding labels.
imgs, labels = batch
imgs = imgs.to(device)
labels = labels.to(device)
#imgs = imgs.half()
#print(imgs.shape,labels.shape)
# Forward the data. (Make sure data and model are on the same device.)
with torch.no_grad(): # MEDIUM BASELINE
teacher_logits = teacher_model(imgs) # MEDIUM BASELINE
logits = student_model(imgs)
loss = loss_fn(logits, labels, teacher_logits) # MEDIUM BASELINE
optimizer.zero_grad()
# Compute the gradients for parameters.
loss.backward()
# Clip the gradient norms for stable training.
grad_norm = nn.utils.clip_grad_norm_(student_model.parameters(), max_norm=cfg['grad_norm_max'])
# Update the parameters with computed gradients.
optimizer.step()
# Compute the accuracy for current batch.
acc = (logits.argmax(dim=-1) == labels).float().sum()
# Record the loss and accuracy.
train_batch_len = len(imgs)
train_loss.append(loss.item() * train_batch_len)
train_accs.append(acc)
train_lens.append(train_batch_len)
train_loss = sum(train_loss) / sum(train_lens)
train_acc = sum(train_accs) / sum(train_lens)
# Print the information.
log(f"[ Train | {epoch + 1:03d}/{n_epochs:03d} ] loss = {train_loss:.5f}, acc = {train_acc:.5f}")
# ---------- Validation ----------
student_model.eval()
# These are used to record information in validation.
valid_loss = []
valid_accs = []
valid_lens = []
# Iterate the validation set by batches.
for batch in tqdm(valid_loader):
imgs, labels = batch
imgs = imgs.to(device)
labels = labels.to(device)
with torch.no_grad():
logits = student_model(imgs)
teacher_logits = teacher_model(imgs) # MEDIUM BASELINE
loss = loss_fn(logits, labels, teacher_logits) # MEDIUM BASELINE
acc = (logits.argmax(dim=-1) == labels).float().sum()
# Record the loss and accuracy.
batch_len = len(imgs)
valid_loss.append(loss.item() * batch_len)
valid_accs.append(acc)
valid_lens.append(batch_len)
#break
# The average loss and accuracy for entire validation set is the average of the recorded values.
valid_loss = sum(valid_loss) / sum(valid_lens)
valid_acc = sum(valid_accs) / sum(valid_lens)
# update logs
if valid_acc > best_acc:
log(f"[ Valid | {epoch + 1:03d}/{n_epochs:03d} ] loss = {valid_loss:.5f}, acc = {valid_acc:.5f} -> best")
else:
log(f"[ Valid | {epoch + 1:03d}/{n_epochs:03d} ] loss = {valid_loss:.5f}, acc = {valid_acc:.5f}")
# save models
if valid_acc > best_acc:
log(f"Best model found at epoch {epoch}, saving model")
torch.save(student_model.state_dict(), f"{save_path}/student_best.ckpt") # only save best to prevent output memory exceed error
best_acc = valid_acc
stale = 0
else:
stale += 1
if stale > patience:
log(f"No improvment {patience} consecutive epochs, early stopping")
break
log("Finish training")
log_fw.close()
3、strong baseline
configs
cfg = {
'dataset_root': '../input/ml2022spring-hw13/food11-hw13',
'save_dir': './outputs',
'exp_name': "strong_baseline",
'batch_size': 128,
'lr': 1e-3,
'seed': 20220013,
'loss_fn_type': 'KD',
'weight_decay': 1e-5,
'grad_norm_max': 10,
'n_epochs': 200, # train more steps to pass the medium baseline.
'patience': 40,
}
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
# define training/testing transforms
test_tfm = transforms.Compose([
# It is not encouraged to modify this part if you are using the provided teacher model. This transform is stardard and good enough for testing.
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize,
])
train_tfm = transforms.Compose([
# add some useful transform or augmentation here, according to your experience in HW3.
transforms.RandomResizedCrop((224, 224), scale=(0.7, 1.0)),# 裁剪图像的任意部分,并将其调整到给定的大小。
transforms.RandomHorizontalFlip(0.5),# 以给定的概率随机水平翻转给定的图像。
transforms.RandomVerticalFlip(0.5),# 以给定的概率随机垂直翻转给定的图像。
transforms.RandomRotation(180),# 按角度旋转图像。
transforms.RandomAffine(30),# 保持中心不变的图像的随机仿射变换。
transforms.ToTensor(),
normalize,
])
def dwpw_conv(ic, oc, kernel_size=3, stride=2, padding=1):
return nn.Sequential(
nn.Conv2d(ic, ic, kernel_size, stride=stride, padding=padding, groups=ic), #depthwise convolution
nn.BatchNorm2d(ic),# 让输入满足均值为0,方差为1的分布,batch normalization
nn.LeakyReLU(0.01, inplace=True),# leakyRelu数学表达式:y = max(0, x) + leak*min(0,x) Relu数学表达式:a = max(0, z)
nn.Conv2d(ic, oc, 1), # pointwise convolution
nn.BatchNorm2d(oc),
nn.LeakyReLU(0.01, inplace=True)
)
class StudentNet(nn.Module):
def __init__(self):
super().__init__()
# ---------- TODO ----------
# Modify your model architecture
# 224 --> 112
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = dwpw_conv(64, 64, stride=1)
self.layer2 = dwpw_conv(64, 128)
self.layer3 = dwpw_conv(128, 256)
self.layer4 = dwpw_conv(256, 140)
# Here we adopt Global Average Pooling for various input size.
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(140, 11)
def forward(self, x):
out = self.relu(self.bn1(self.conv1(x)))
out = self.maxpool(out)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = self.avgpool(out)
out = out.flatten(1)
out = self.fc(out)
return out
def get_student_model():
return StudentNet()
ReLu和leakyRelu
优点:Relu得到的SGD的收敛速度较快
缺点:训练的时候很容易卡了,对于小于0的值,这个神经元的梯度永远都会是0。
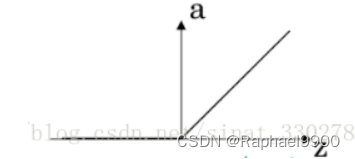
leakyRelu:
知识蒸馏
既然我们有一个学过的大模型,那就让它来教另一个小模型吧。在实现上,让训练目标成为大模型的预测,而不是ground true。
为什么有效?
如果数据不干净,那么大模型的预测可能会忽略带有错误标记的数据的噪声。类之间可能存在一些关系,因此教师模型中的软标签可能有用。例如,数字8更类似于6,9,0,而不是1,7。
如何实施?
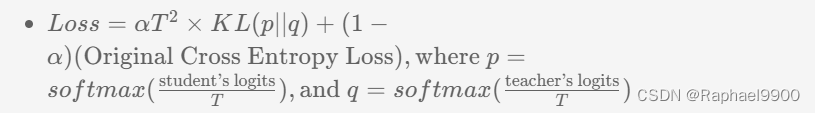
#用KL散度损失实现损失函数,用于知识蒸馏。
CE = nn.CrossEntropyLoss()
def loss_fn_kd(student_logits, labels, teacher_logits, alpha=0.5, temperature=20.0):
# ------------TODO-------------
student_T = (student_logits/temperature).softmax(dim=-1)
teacher_T = (teacher_logits/temperature).softmax(dim=-1)
kl_loss = (teacher_T*(teacher_T.log() - student_T.log())).sum(1).mean()
ce_loss = CE(student_logits, labels)
return alpha*(temperature**2)*kl_loss + (1 - alpha)*ce_loss