例1.2 为了研究全国31个省、市、自治区2018年城镇居民生活消费的分布规律,根据调查资料做区域消费类型划分。
指标:
食品x1:人均食品支出(元/人)
衣着x2:人均衣着商品支出(元/人)
居住x3:人均居住支出(元/人)
生活x4:人均家庭设备用品及服务支出(元/人)
交通x5:人均交通和通讯支出(元/人)
教育x6:人均娱乐教育文化服务支出(元/人)
医疗x7:人均医疗保健支出(元/人)
其他x8:人均杂项商品和服务支出(元/人)
地区
x1
x2
x3
x4
x5
x6
x7
x8
北京
8064.9
2175.5
14110.3
2371.9
4767.4
3999.4
3274.5
1078.6
天津
8647.5
1990.0
6406.3
1818.4
4280.9
3186.6
2676.9
896.3
河北
4271.3
1257.4
4050.4
1138.7
2355.4
1734.5
1540.5
373.8
山西
3688.2
1261.0
3228.5
855.6
1845.2
1940.0
1635.1
356.4
内蒙古
5324.3
1751.2
3680.0
1204.6
3074.3
2245.4
1847.5
537.9
辽宁
5727.8
1628.1
4169.5
1259.4
2968.2
2708.0
2257.1
680.2
吉林
4417.4
1397.0
3294.8
899.4
2479.7
2193.4
2012.0
506.7
黑龙江
4573.2
1405.4
3176.3
866.4
2196.6
2030.3
2235.3
490.4
上海
10728.2
2036.8
14208.5
2095.5
4881.2
5049.4
3070.2
1281.5
江苏
6529.8
1541.0
6731.2
1493.3
3522.8
2582.6
2016.4
590.4
浙江
8198.3
1813.5
7721.2
1652.4
4302.0
3031.3
2059.4
692.6
安徽
5414.7
1137.4
3941.9
1041.2
2082.1
1810.4
1224.0
392.8
福建
7572.9
1212.1
6130.0
1223.1
2923.3
2194.0
1234.8
505.8
江西
4809.0
1074.1
3795.2
1047.7
1872.1
1813.0
1000.0
381.0
山东
5030.9
1391.8
3928.5
1394.3
2834.3
2174.4
1627.6
398.1
河南
3959.8
1172.8
3512.0
1054.4
1838.0
1769.1
1541.5
321.0
湖北
5491.3
1316.2
4310.6
1253.2
2584.1
2187.5
1907.9
487.0
湖南
5260.0
1215.5
3976.1
1190.2
2322.9
2786.2
1705.5
351.5
广东
8480.8
1135.3
6643.3
1440.8
3423.9
2750.9
1520.8
658.2
广西
4545.7
616.7
3268.5
898.2
2150.1
1798.9
1364.6
291.9
海南
6552.2
655.9
3744.0
826.6
1919.0
2185.5
1236.1
409.2
重庆
6220.8
1454.5
3498.8
1338.9
2545.0
2087.8
1660.0
442.8
四川
5937.9
1173.8
3368.0
1182.2
2398.8
1599.7
1568.6
434.5
贵州
3792.9
934.7
2760.7
878.1
2408.0
1660.0
1083.5
280.1
云南
3983.4
789.1
3081.1
859.9
2212.8
1772.7
1267.7
283.2
西藏
4330.5
1285.2
2102.6
622.3
1847.7
609.3
460.1
262.6
陕西
4292.5
1141.1
3388.2
1200.8
2005.8
2008.8
1749.4
373.2
甘肃
4253.3
1111.5
3095.0
896.9
1640.7
1710.3
1573.9
342.4
青海
4671.6
1350.6
2990.0
932.0
2671.4
1655.6
1842.0
444.0
宁夏
4234.1
1388.2
3014.3
1067.1
2724.4
2139.5
1727.1
420.4
新疆
4691.6
1456.0
2894.3
1082.8
2274.4
1762.5
1592.6
434.9
数据读入X=read.table('biao1.2.txt',header=T)
R 函数笔记 | read.table()函数 - 简书 (jianshu.com)
file填要打开的文件名,如"data"
options填操作
参数 功能 header 逻辑值,指示表格是否包含文件第一行中的变量名称 sep 分隔数据值的分隔符。默认值为sep =“ ”,表示一个或多个空格、制表符、换行符或回车符。使用sep =“,”来读取被逗号","分隔的文件,使用sep =“\t”来读取制表符分隔的文件 row.names 一个可选参数,指定一个或多个变量来表示行标识符 col.names 如果数据文件的第一行不包含变量名(header = FALSE),则可以使用col.names指定包含变量名的字符向量。如果header = FALSE并且省略了col.names选项,则变量将命名为V1,V2,依此类推。 na.strings 指示缺失值代码的可选字符向量。例如,na.strings = c(“9”,“?”)转换每个9和?读取数据时的值为NA colClasses 分配给列的类的可选向量。例如,colClasses = c(“numeric”,“numeric”,“character”,“NULL”,“numeric”)将前两列读取为numeric,将第三列读取为character,跳过第四列,并读取 第五列为numeric。 如果数据中有五列以上,则第六列重新从colClasses的第一个numeric开始 quote 用于分隔包含特殊字符的字符串的字符。默认情况下,这是双引号"或单引号' skip 在开始读取数据之前要跳过的文本文件中的行数。此选项对于跳过文件中的标题注释很有用 stringsAsFactors 逻辑值,指示是否应将字符变量转换为因子。除非被colClasses覆盖,否则默认值为TRUE。处理大型文本文件时,设置stringsAsFactors = FALSE可以加快处理速度 text 指定要处理的文本字符串的字符串 comment.char 关闭注释 X=read.table(file, options)
1.散布矩阵图
散布矩阵图在一张图上给出p个变量相互之间的散点图,由此可以直观看出p个变量两两之间的相关关系。
R语言 pairs()用法及代码示例 - 纯净天空 (vimsky.com)
pairs(X) #画散布矩阵图R语言中的pairs()函数用于返回一个绘图矩阵,由每个 DataFrame 对应的散点图组成。
用法: pairs(data)
从该图可以看出,食品支出与生活用品及服务支出、教育及文化娱乐支出之间存在显著线性相关关系,而教育及文化娱乐支出又与居住支出、其他支出之间存在显著线性相关关系,等等。
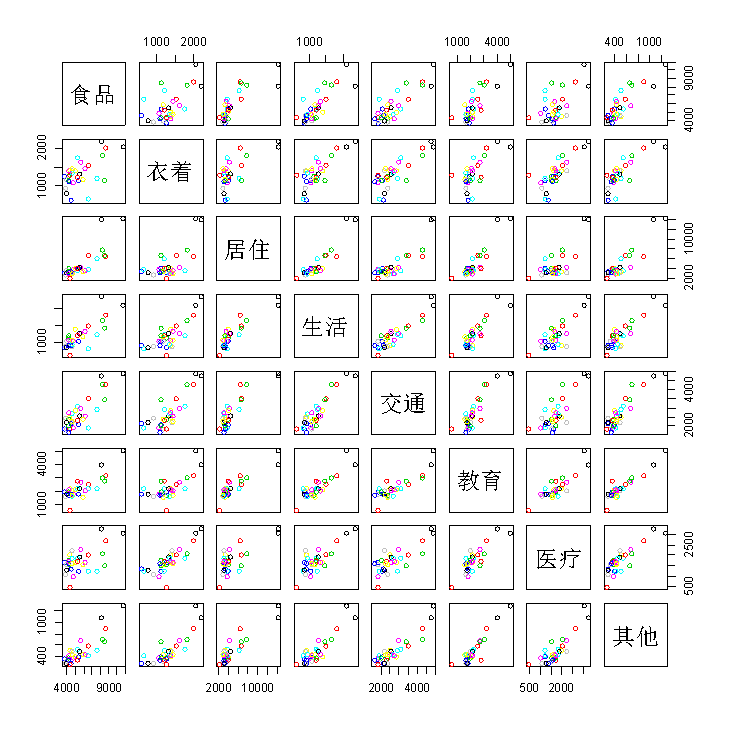
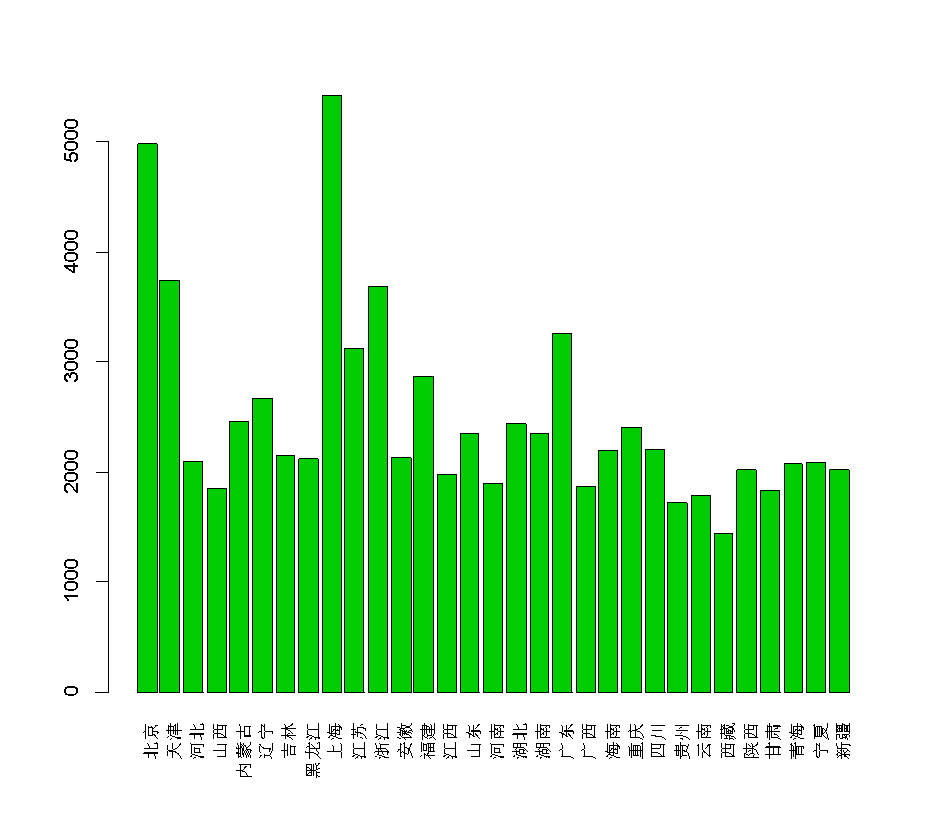
2.均值条形图
均值条形图常用来比较各个样本的样本均值的大小,也可以比较各个变量的样本均值的大小。
R语言:使用barplot()绘制柱状图(条形图) - 知乎 (zhihu.com)
barplot(apply(X,1,mean),las=3)barplot(height, # 柱子的高度 names.arg = NULL, # 柱子的名称 col = NULL, # 柱子的填充颜色 border = par("fg"), # 柱子的轮廓颜色 main = NULL, # 柱状图主标题 xlab = NULL, # X轴标签 ylab = NULL, # Y轴标签 xlim = NULL, # X轴取值范围 ylim = NULL, # Y轴取值范围 horiz = FALSE, # 柱子是否为水平 legend.text = NULL, # 图例文本 beside = FALSE, # 柱子是否为平行放置 )
但是这里我们是直接用的apply函数R 数据处理(二十)—— apply - 知乎 (zhihu.com)
apply(X, MARGIN, FUN, ...)
X: 数组、矩阵、数据框,数据至少是二维的MARGIN: 按行计算或按列计算,1表示按行,2表示按列FUN: 自定义的调用函数...:FUN的可选参数
组合一下,有:
按行做均值条图
barplot(apply(X,1,mean))按列做均值条图
barplot(apply(X,2,mean))这里图1就是按行的,图二按列

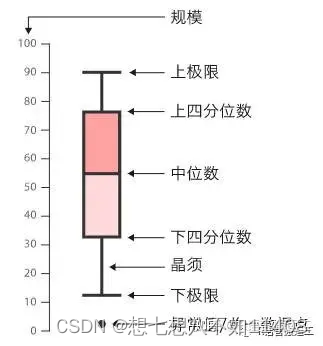
3.箱线图
箱线图可以比较清晰地展示数据的分布特征。
R语言 boxplo函数用法及箱线图介绍_r gg_boxplot_col()-CSDN博客
boxplot(X) #按列做垂直箱线图 boxplot(X,horizontal=T)#水平箱线图boxplot(x, ..., range = 1.5, width = NULL, varwidth = FALSE, notch = FALSE, outline = TRUE, names, plot = TRUE, border = par("fg"), col = NULL, log = "", pars = list(boxwex = 0.8, staplewex = 0.5, outwex = 0.5), horizontal = FALSE, add = FALSE, at = NULL)
主要参数的含义:
x: 向量,列表或数据框。
formula: 公式,形如y~grp,其中y为向量,grp是数据的分组,通常为因子。
data: 数据框或列表,用于提供公式中的数据。
range: 数值,默认为1.5,表示触须的范围,即range × (Q3 - Q1)
width: 箱体的相对宽度,当有多个箱体时,有效。
varwidth: 逻辑值,控制箱体的宽度, 只有图中有多个箱体时才发挥作用,默认为FALSE, 所有箱体的宽度相同,当其值为TRUE时,代表每个箱体的样本量作为其相对宽度
notch: 逻辑值,如果该参数设置为TRUE,则在箱体两侧会出现凹口。默认为FALSE。
outline: 逻辑值,如果该参数设置为FALSE,则箱线图中不会绘制离群值。默认为TRUE。
names:绘制在每个箱线图下方的分组标签。
plot : 逻辑值,是否绘制箱线图,如设置为FALSE,则不绘制箱线图,而给出绘制箱线图的相关信息,如5个点的信息等。
border:箱线图的边框颜色。
col:箱线图的填充色。
horizontal:逻辑值,指定箱线图是否水平绘制,默认为FALSE。


4.星相图
星相图是雷达图的多元表现形式,它将各个观测样品点表现为一个图形,n个样本点就有n个图形,每个图形的每个角表示一个变量。
R stars 星图(蜘蛛图/雷达图)和线段图 - 纯净天空 (vimsky.com)
stars(X,full=F,key.loc=c(13,1.5))stars(x, full = TRUE, scale = TRUE, radius = TRUE, labels = dimnames(x)[[1]], locations = NULL, nrow = NULL, ncol = NULL, len = 1, key.loc = NULL, key.labels = dimnames(x)[[2]], key.xpd = TRUE, xlim = NULL, ylim = NULL, flip.labels = NULL, draw.segments = FALSE, col.segments = 1:n.seg, col.stars = NA, col.lines = NA, axes = FALSE, frame.plot = axes, main = NULL, sub = NULL, xlab = "", ylab = "", cex = 0.8, lwd = 0.25, lty = par("lty"), xpd = FALSE, mar = pmin(par("mar"), 1.1+ c(2*axes+ (xlab != ""), 2*axes+ (ylab != ""), 1, 0)), add = FALSE, plot = TRUE, ...)
x数据的矩阵或 DataFrame 。将为
x的每一行生成一个星形图或线段图。允许缺失值 (NA),但它们被视为 0(缩放后,如果相关的话)。full逻辑标志:如果
TRUE,线段图将占据一整圈。否则,它们仅占据(上)半圆。scale逻辑标志:如果
TRUE,则数据矩阵的列独立缩放,以便每列中的最大值为 1,最小值为 0。如果FALSE,则假设数据已被其他某个缩放算法范围 。radius逻辑标志:在
TRUE中,将绘制数据中每个变量对应的半径。labels用于标记图的字符串向量。与 S 函数
stars不同,如果labels = NULL则不会尝试构造标签。locations具有用于放置每个线段图的 x 和 y 坐标的两列矩阵;或长度为 2 的数字,此时所有图都应叠加(对于“蜘蛛图”)。默认情况下,
locations = NULL,线段图将放置在矩形网格中。nrow, ncol给出当
locations为NULL时要使用的行数和列数的整数。默认情况下,nrow == ncol,将使用方形布局。len半径或线段长度的比例因子。
key.loc带有单位键的 x 和 y 坐标的向量。
key.labels用于标记单位键段的字符串向量。如果省略,则使用
dimnames(x)的第二个组件(如果可用)。key.xpd单位键的剪辑开关(绘图和标签),请参阅
par("xpd")。xlim具有要绘制的 x 坐标范围的向量。
ylim具有要绘制的 y 坐标范围的向量。
flip.labels逻辑指示标签位置是否应在图表之间上下翻转。默认为有点智能的启发式。
draw.segments合乎逻辑的。如
TRUE画一个线段图。col.segments颜色向量(整数或字符,请参阅
par),每个向量指定其中一个段(变量)的颜色。如果draw.segments = FALSE则忽略。col.stars颜色向量(整数或字符,请参阅
par),每个向量指定其中一颗星星(案例)的颜色。如果draw.segments = TRUE则忽略。col.lines颜色向量(整数或字符,请参阅
par),每个向量指定其中一条线(案例)的颜色。如果draw.segments = TRUE则忽略。axes逻辑标志:是否将
TRUE轴添加到图中。frame.plot逻辑标志:如果
TRUE,则绘图区域被加框。main情节的主要标题。
sub情节的副标题。
xlabx 轴的标签。
ylaby 轴的标签。
cex标签的字符扩展因子。
lwd用于绘图的线宽。
lty用于绘图的线型。
xpd逻辑或 NA 指示是否应进行裁剪,请参阅
par(xpd = .)。mar
par(mar = *)的参数,通常选择比默认情况更小的边距。...更多参数,传递给
plot()的第一次调用,请参见plot.default,如果frame.plot为 true,则传递给box()。add逻辑上,如果
TRUE将星星添加到当前绘图中。plot逻辑上,如果
FALSE,则不会绘制任何内容。
从该图中可以看出,北京上海天津浙江广东五个地区的消费支出较高。另外,有些地区在各项消费指标上的支出比较均匀,比如北京上海,有些地方不够均匀,如西藏新疆。
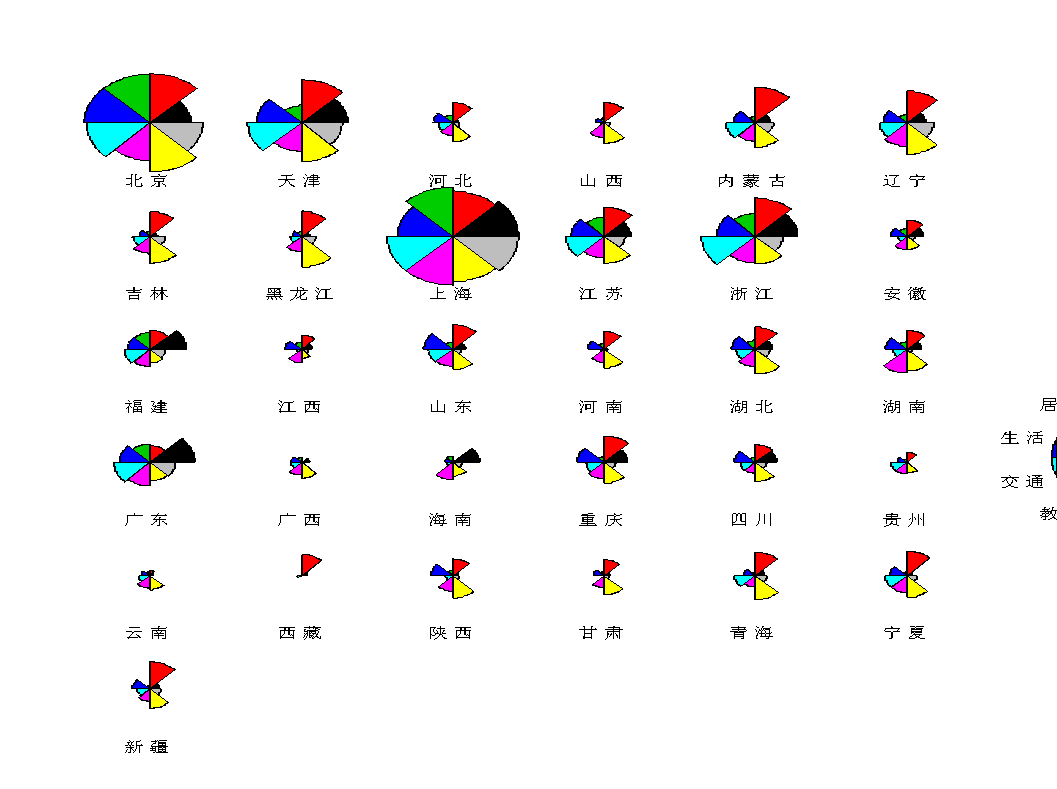
5.脸谱图
运用样本各变量值构造脸的各部位,通过分析脸部位大小或形状来分析各样本数据特征。一般来说,较为丰满、生动的脸谱代表比较理想的样品数据。
#加载aplpack包
library(aplpack)
#按每行7个做脸谱图
faces(X,ncol.plot=7)R语言TeachingDemos包 faces函数使用说明 - 爱数吧 (idata8.com)
语法\用法:
faces(xy, which.row, fill = FALSE, nrow, ncol, scale = TRUE, byrow = FALSE, main, labels)
参数说明:xy : xy数据矩阵,行表示个体,列表示属性
which.row : 定义输入矩阵行的排列
fill : 如果(fill==TRUE),则仅转换面的第一个nc属性,nc是xy的列数
nrow : 图形设备上的面列数
ncol : 面行数
scale : 如果(scale==TRUE),属性将被规格化
byrow : 如果(byrow==TRUE),则xy将被转置
main : 标题
labels : 用作面名称的字符串
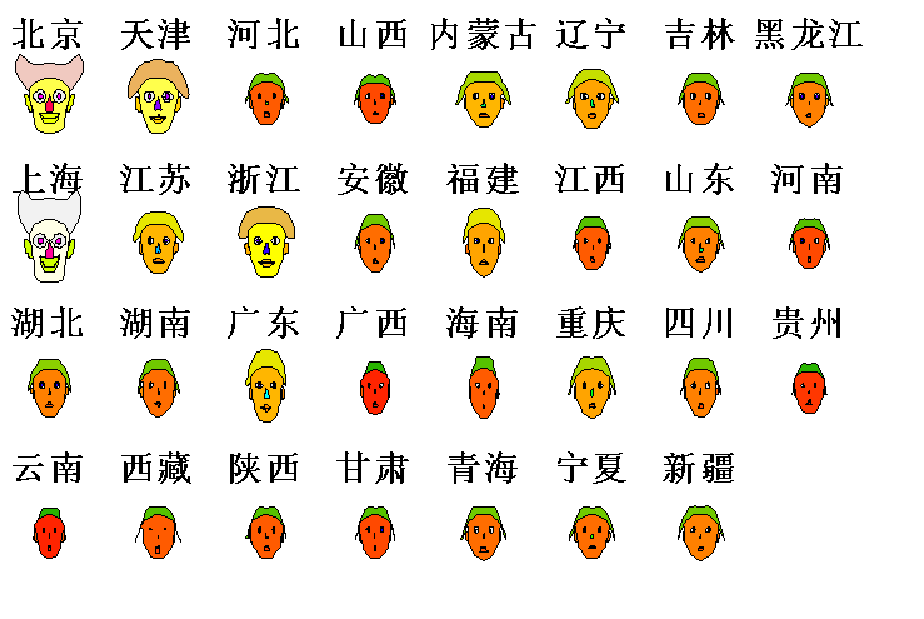
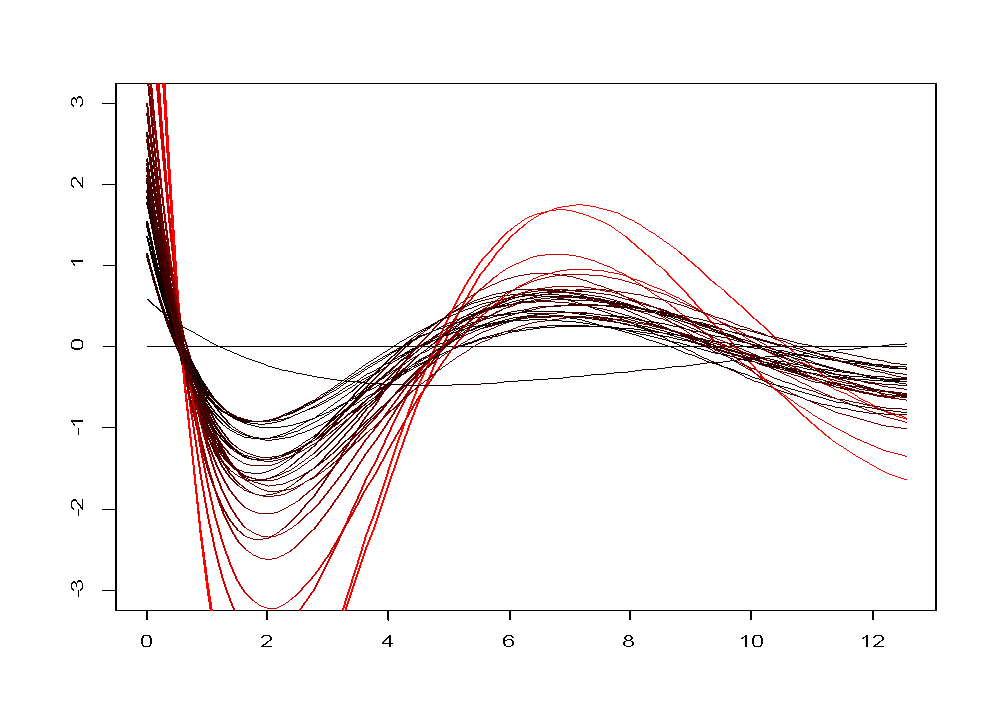
6.调和曲线图
调和曲线图是一种利用三角多项式进行作图的方法,其思想是把高维空间中的一个样品点对应于二维平面上的一条曲线。这种图形有利于对样品进行直观分类,同类样品的曲线之间比较靠近,而不同类样品的曲线之间界限分明,非常直观。
#加载mvstats包
library(mvstats)
plot.andrews(X)
####也可以直接从镜像站加载andrews包绘制调和曲线图
library(andrews)
andrews(X,type=3,clr=5,ymax=3)