类别不平衡问题
- 解决方案
- 简单方法
- 收集数据
- 调整权重
- 阈值移动
- 数据层面
- 欠采样
- 过采样
- 采样方法的优劣
- 算法层面
- 代价敏感
- 集成学习:EasyEnsemble
- 总结
类别不平衡(class-imbalance)就是指分类任务中不同类别的训练样例数目差别很大的情况
解决方案
当问题的指标是ROC或者AUC等对类别不平衡不敏感的指标,那么此时不处理和处理的差别没那么大;但是对于召回率为评判指标的模型则需要进行处理
简单方法
收集数据
针对少量样本数据,可以尽可能去扩大这些少量样本的数据集,或者尽可能去增加他们特有的特征来丰富数据的多样性
调整权重
可以简单的设置损失函数的权重,更多的关注少数类。在python的scikit-learn中我们可以使用class_weight参数来设置权重。为了权衡不同类型错误所造成的不同损失,可为错误赋予“非均等代价”
阈值移动
直接基于原始训练集进行学习,但在用训练好的分类器进行预测时,将原本默认为0.5的阈值调整为 正例数 正例数 + 负例数 \frac{正例数}{正例数+负例数} 正例数+负例数正例数
如果正负样本数量相同,对于正样本预测为
y
y
y,那么分类决策规则为:
y
1
−
y
>
1
\frac{y}{1-y}>1
1−yy>1
预测为正例,当正负样本数量不同时,分别为
m
+
,
m
−
m^{+},m^{-}
m+,m−,则观测几率为
m
+
m
−
\frac{m^{+}}{m^{-}}
m−m+,那么当分类器预测几率大于观测几率即为正例:
y
1
−
y
>
m
+
m
−
\frac{y}{1-y}>\frac{m^{+}}{m^{-}}
1−yy>m−m+
可以变化为以下形式:
y
′
1
−
y
′
=
y
1
−
y
⋅
m
−
m
+
>
1
\frac{y'}{1-y'}=\frac{y}{1-y}\cdot \frac{m^{-}}{m^{+}}>1
1−y′y′=1−yy⋅m+m−>1
也可以称为“再缩放”
数据层面
欠采样
对训练集中多数类样本进行“欠采样”(undersampling),即去除一些多数类中的样本使得正例、反例数目接近,然后再进行学习。
- 随机欠采样
随机欠采样顾名思义即从多数类中随机选择一些样本组成样本集 。然后将新样本集与少数类样本集合并。 - Edited Nearest Neighbor (ENN)
遍历多数类的样本,如果他的大部分k近邻样本都跟他自己本身的类别不一样,我们就将他删除;
过采样
对训练集里的少数类进行“过采样”(oversampling),即增加一些少数类样本使得正、反例数目接近,然后再进行学习。
- 随机过采样
随机过采样是在少数类S中随机选择一些样本,然后通过复制所选择的样本生成样本集E,将它们添加到S中来扩大原始数据集从而得到新的少数类集合S+E。 - SMOTE(Synthetic Minority Oversampling,合成少数类过采样)
SMOTE是对随机过采样方法的一个改进算法,通过对少数类样本进行插值来产生更多的少数类样本。基本思想是针对每个少数类样本,从它的k近邻中随机选择一个样本 (该样本也是少数类中的一个),然后在两者之间的连线上随机选择一点作为新合成的少数类样本。
采样方法的优劣
- 优点:
- 平衡类别分布,在重采样后的数据集上训练可以提高某些分类器的分类性能。
- 欠采样方法减小数据集规模,可降低模型训练时的计算开销。
- 缺点:
- 采样过程计算效率低下,通常使用基于距离的邻域关系(k近邻)来提取数据分布信息,计算开销大。
- 易被噪声影响,最近邻算法容易被噪声干扰,可能无法得到准确的分布信息,从而导致不合理的重采样策略。
- 过采样方法生成过多数据,会进一步增大训练集的样本数量,增大计算开销,并可能导致过拟合。
- 不适用于无法计算距离的复杂数据集,如用户ID。
算法层面
代价敏感
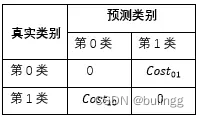
可用于多分类问题,代价敏感学习方法的核心要素是代价矩阵,如表所示。其中
c
o
s
t
i
j
cost_{ij}
costij表示将第
i
i
i 类样本预测为第
j
j
j 类样本的代价。若将第0类判别为第1类所造成的损失更大,则
c
o
s
t
01
>
c
o
s
t
10
cost_{01}>cost_{10}
cost01>cost10;损失程度相差越大,
c
o
s
t
01
,
c
o
s
t
10
cost_{01},cost_{10}
cost01,cost10的值差别越大。当
c
o
s
t
01
=
c
o
s
t
10
cost_{01}=cost_{10}
cost01=cost10时为代价不敏感的学习问题。
集成学习:EasyEnsemble

1:数据中,少数标签的为P,多数标签的N,
为P与N在数量上的比例,T为需要采集的subset份数,也可以说是设置的基分类器的个数。
为训练基分类器i (默认使用AdaBoost,也可以设置为其他,例如XGBoost)的训练循环次数(iteration)。
2-5: 根据少数标签的为P的数量,对多数标签的N进行随机采样产生
,使得采样出来的数量和P的数量一样。
6: 把
和P结合起来,然后给基分类器i学习。这里的公式只单个基分类器的训练过程。论文里用的基分类器是AdaBoost,而AdaBoost是由N个弱分类器组成的,j就是表示Adaboost基分类器里的第j个弱分类器.
7: 重复采样,训练T个这样的基分类器。
8: 对T个基分类器进行ensemble。而这里并非直接取T个基分类的结果(0,1)进行投票,而是把n个基分类器的预测概率进行相加,最后再通过sign函数来决定分类,sgn函数就是sign函数,sgn就是把结果转成两个类,小于0返回-1,否则返回1。.
总结
-
通过某种方法使得不同类别的样本对于模型学习中的Loss(或梯度)贡献是比较均衡的
- 样本层面
- 欠采样、过采样
- 数据增强:从原始数据加工出更多数据的表示,提高原数据的数量及质量,包括几何操作、颜色变化、随机裁剪、添加噪声
- 损失函数层面:代价敏感学习(cost-sensitive),为不同的分类错误给予不同惩罚力度(权重)
- class weight:为不同类别的样本提供不同的权重(少数类有更高的权重),从而模型可以平衡各类别的学习
- Focal loss的核心思想是在交叉熵损失函数(CE)的基础上增加了类别的不同权重以及困难(高损失)样本的权重
- OHEM(Online Hard Example Mining)算法的核心是选择一些hard examples(多样性和高损失的样本)作为训练的样本,针对性地改善模型学习效果
- 模型层面:
- 选择对类别不均衡不敏感的模型:采样+集成树模型(树模型按照特征增益递归地划分数据
- 采样+集成学习:通过重复组合少数类样本与抽样的同样数量的多数类样本,训练若干的分类器进行集成学习
- 决策及评估指标
- 分类阈值移动,以调整模型对于不同类别偏好的情况
- 采用AUC、AUPRC(更优)评估模型表现。AUC的含义是ROC曲线的面积;AUC对样本的正负样本比例情况是不敏感
- 样本层面