索引的优缺点
索引是一种支持快速查找特定行的数据结构,如果没有索引,就需要遍历整个表进行查找。用于提高数据检索的速度和效率。
好处:
提高检索速度: 索引可以加快数据的检索速度,因为它们允许数据库系统直接定位到存储数据的位置,而不必遍历整个数据表。
优化数据访问路径: 索引可以优化数据访问路径,使得查询更加高效。
坏处:
占用存储空间: 索引会占用额外的存储空间,特别是对于大型数据集来说,索引可能会占用相当大的空间。
影响写操作的性能: 当执行插入、更新和删除等写操作时,数据库系统需要更新索引,这可能会影响写操作的性能。
维护成本高昂: 维护索引需要额外的系统资源和时间成本。随着数据库的增长和索引的数量增加,维护成本可能会变得很高。
数据库索引的底层数据结构
B+树。在数据库中,B+树的高度一般都在2~4层,效率很高。
B+树中,所有记录节点都是按键值的大小顺序存放在同一层的叶子节点,各叶子节点通过指针进行链接。
非叶子节点只存储与搜索有关的key
叶子节点存储数据。从小到大有序,并且使用指针连接在一起。
B+树索引在数据库中的一个特点就是高扇出性。B-tree将数据库拆分成了固定大小的块,通常为4K,块是内部读写的最小单元。这种设计更接近底层硬件,因为磁盘也是以固定大小的块排列的。
问题:如果固定大小的块已经满了该怎么办、答案:分裂多个块解决,空的空间使用空闲空间。
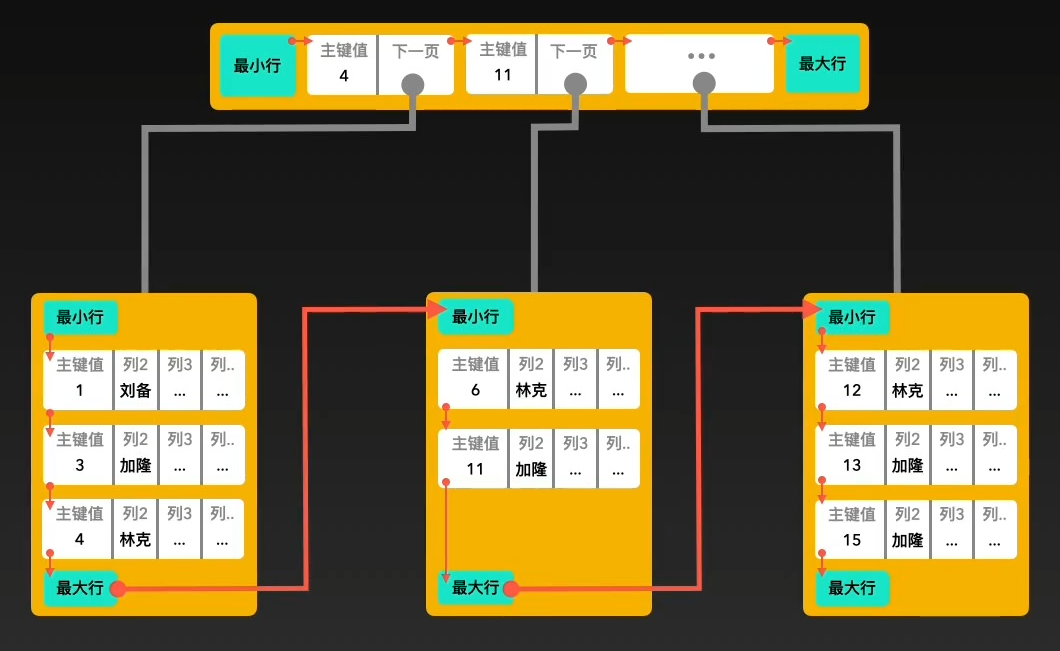
聚簇索引和非聚簇索引
两者主要区别是数据和索引是否分离。
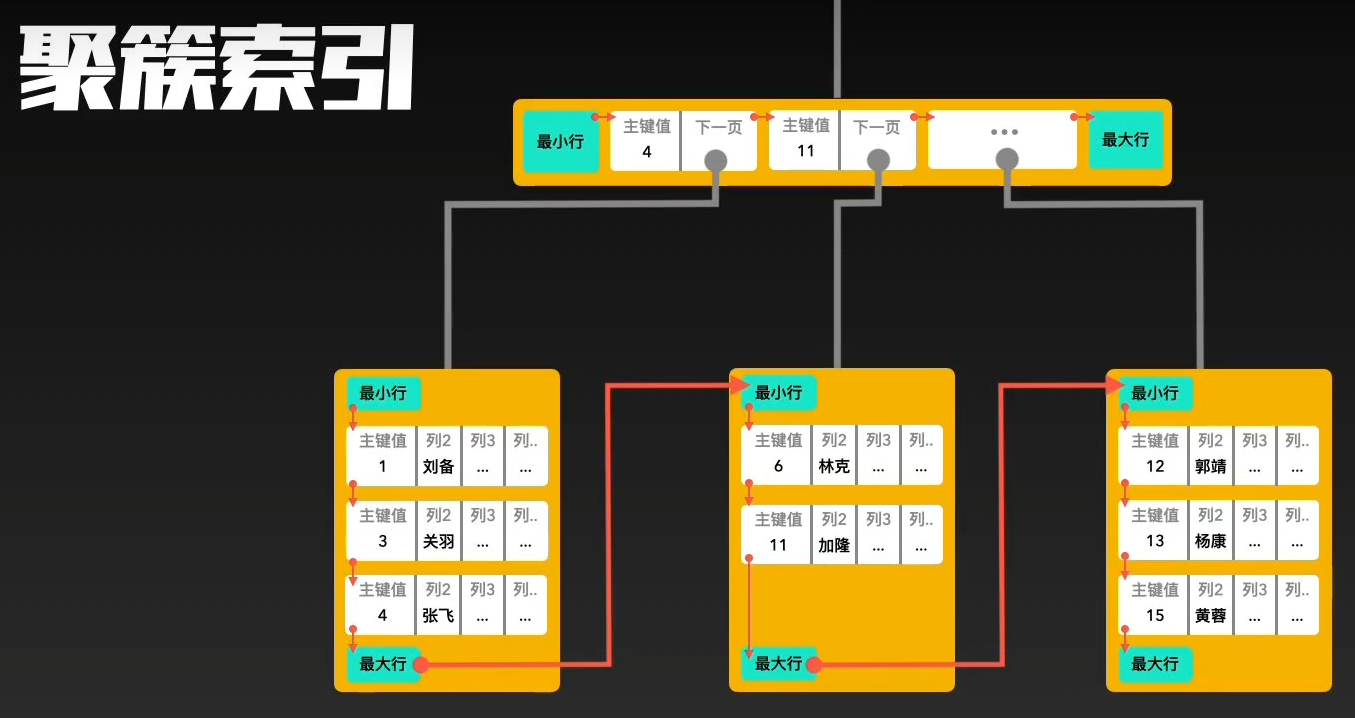
- 聚簇索引是将数据与索引存储到一起,找到索引也就找到了数据;
叶子节点存储真实数据
非叶子节点存储查询需要的key
一个表有且仅有一个聚簇索引,并且该索引是建立在主键上的,如果没有主键,会建立在unique列上- 而非聚簇索引是将数据和索引存储分离开,索引树的叶子节点存储了数据行的地址。
其他索引项都是非聚簇索引
叶子节点存储聚簇索引的key
非叶子节点存储查询需要的key
查找会先找到叶子节点,拿叶子节点的聚簇索引的key再去搜索聚簇索引

索引为什么不用哈希表而用 B+ 树
哈希表的查询效率的确最高,时间复杂度O(1),但是它要求将所有数据载入内存,而数据库存储的数据量级可能会非常大,全部载入内存基本上是不可能实现的
索引为什么不用红黑树而用 B+ 树
索引的底层用的并不是二叉树和红黑树。因为二叉树和红黑树在某些场景下都会暴露出一些缺陷。
二叉树:在某些场景下会退化成链表,而链表的查找需要从头部开始遍历,而这就失去了加索引的意义。
红黑树:当数据表很多时,会导致索引树的层数很高。索引从根节点开始查找,而如果我们需要查找的数据在底层的叶子节点上,那么树的高度是多少,就要进行多少次查找,并且数据存在磁盘上,访问还需要进行磁盘IO,这会导致效率过低。
提高查询效率的方法
提高查询效率的方法有很多,以下是一些常见的方法:
索引优化: 通过在经常查询的列上创建索引,可以加快查询速度。
优化查询语句: 编写高效的查询语句是提高查询效率的关键。避免使用SELECT *,只选择需要的列;避免使用不必要的子查询等。
内存缓存: 使用缓存技术将热点数据存储在内存中,可以减少数据库访问次数,提高查询速度。
合适的数据类型: 使用合适的数据类型可以减少存储空间并提高查询效率。例如,选择整数型而不是字符串型存储数字数据。
定期优化数据库: 定期清理无用数据、重建索引以及收集统计信息等可以提高数据库性能。