- B站:啥都会一点的研究生
- 公众号:啥都会一点的研究生
一直想做但没做的板块,整理一段时间内AI领域的前沿动态(符合大多粉丝研究领域/感兴趣方向),了解了解外面世界发展成啥样了,一起看看吧~
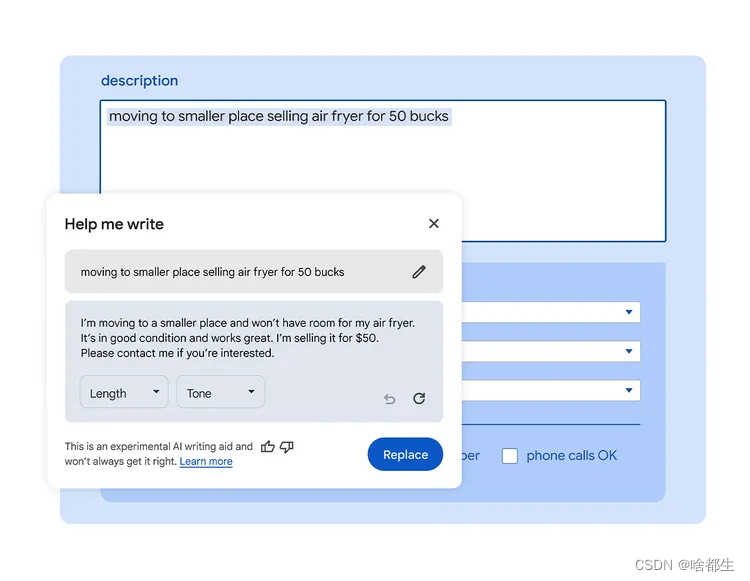
谷歌Chrome推出“Help me write”的AI功能
谷歌最近在其Chrome浏览器中推出了一个名为“Help me write”的实验性AI功能。这个由Gemma提供支持的功能旨在帮助用户根据网页内容编写或完善文本,专注于为短格式内容提供写作建议,例如填写数字调查和评论,以及起草在线销售商品的描述
该工具可以理解网页的上下文,并将相关信息引入其建议中,例如在产品页面上突出显示的关键功能,用于商品评论。用户可以在任何网站的文本字段上右键单击以使用该功能
https://blog.google/products/chrome/google-chrome-ai-help-me-write/
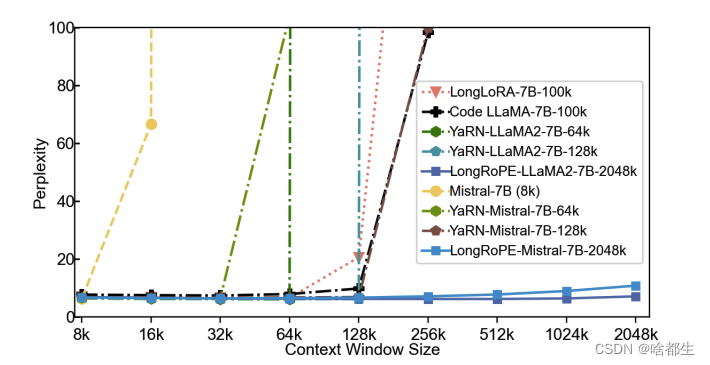
LongRoPE:将LLM上下文窗口扩展到超过200万个token
微软提出了LongRoPE,将预训练大型语言模型(LLMs)的上下文窗口扩展到惊人的2048k tokens
由于高微调成本、长文本的稀缺性以及新标记位置引入的灾难性数值,目前的扩展上下文窗口受到了约128k个token的限制,LongRoPE克服了这些问题
对LLaMA2和Mistral在各种任务上的实验表明,扩展模型保留了原始架构,并进行了轻微的位置嵌入修改和优化
https://twitter.com/_akhaliq/status/1760499638056910955
Stable Diffusion 3打造更强的文生图模型
Stability.AI在早期预告中宣布了Stable Diffusion 3。一款文生图模型,在多主题提示、图像质量和拼写能力方面表现出了更高的性能
由于其卓越的能力,这款下一代图像工具在AI社区中引起广泛关注。宣称提供更好的文本生成,强大的提示遵循能力以及对提示泄漏的抵抗力,确保生成的图像与请求的提示相匹配

https://blog.google/products/google-one/google-one-gemini-ai-gmail-docs-sheets
AnyGPT:迈向通用人工智能的重要一步
上海团队通过研发 AnyGPT 实现了AI能力上的突破。AnyGPT 几乎可以理解和生成任何模式的数据,包括文本、语音、图像和音乐。利用创新的离散表示方法,使单一的底层语言模型架构能够流畅地处理多种模式的输入和输出
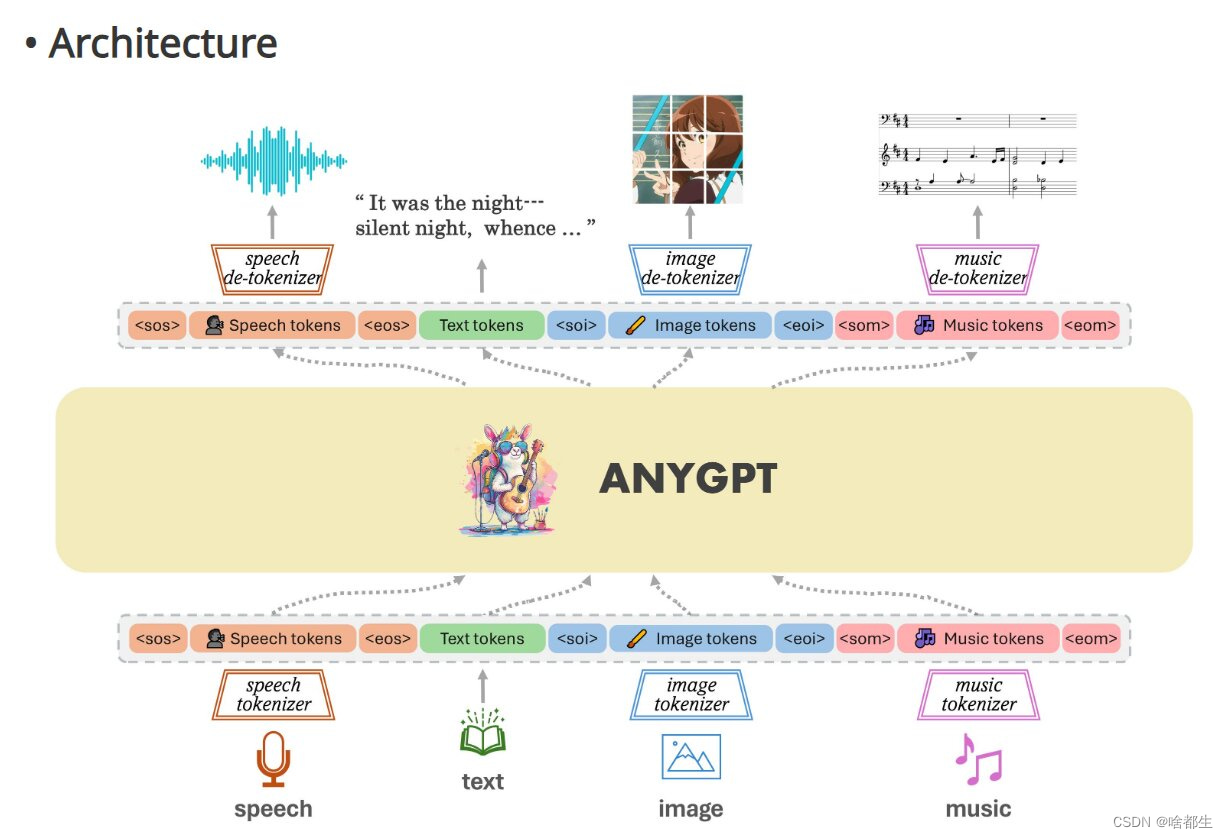
https://arxiv.org/pdf/2402.12226.pdf
Google 发布了第一个开源LLM
谷歌开源了 Gemma,这是一个全新的先进语言模型系列,有 2B 和 7B 两种参数规格。尽管 Gemma 模型非常轻便,可以在笔记本电脑和台式机上运行,但它采用了与谷歌庞大的专有 Gemini 模型相同的技术并实现了卓越的性能,在许多关键的自然语言处理基准测试中,7B Gemma 模型的性能超过了 13B LLaMA 模型
此外,谷歌还发布了 “负责任的生成式人工智能工具包”,以帮助开发人员构建安全的应用程序。其中包括基于谷歌经验的稳健安全分类、调试模型行为和实施最佳部署实践的工具。Gemma 可在谷歌云、Kaggle、Colab 和其他一些平台上使用,并提供免费积分等激励措施

https://blog.google/technology/developers/gemma-open-models
Meta 发布 Aria 录音,助力智能语音识别
Meta 发布了通过 Aria 智能眼镜捕捉到的双人对话多模式数据集。该数据集包含 7 个麦克风的音频、视频、运动传感器和标注。一名参与者戴着眼镜自发地与另一名贡献者交谈
该数据集旨在推动语音识别、扬声器 ID 和增强现实界面翻译等领域的研究。它的音频、视觉和运动信号共同提供了丰富的自然对话捕捉,有助于训练人工智能模型,可以实现闭合字幕和实时语言翻译

https://the-decoder.com/metas-aria-smart-glasses-dataset-helps-shape-the-future-of-ai-conversations/
Adobe 发布新AI助手帮助用户浏览文档
Adobe 在其 Acrobat 软件中推出了一项AI助手功能,帮助用户浏览文档,可以总结内容、回答问题并生成格式化的概述。该聊天机器人旨在节省处理长文件和复杂信息的时间
此外,Adobe 还专门成立了一个 50 人的人工智能研究团队,名为 CAVA(音频、视频和动画协同创作),专注于推进生成式视频、动画和音频创作工具的发展。该研究小组将探索将 Adobe 现有的创意工具与文本视频生成等技术相结合
https://www.theverge.com/2024/2/20/24077217/adobe-acrobat-generative-ai-assistant-chatbot-pdf-document
Groq 的新型AI芯片为助力LLM,性能优于 ChatGPT
Groq 开发了一种特殊的人工智能硬件,称为有史以来第一个语言处理单元(LPU),旨在提高目前通常在 GPU 上工作的人工智能模型的处理能力。这些 LPU 每秒可处理多达 500 个token,远远优于每秒只能处理 30 至 50 个token的 Gemini Pro 和 ChatGPT-3.5
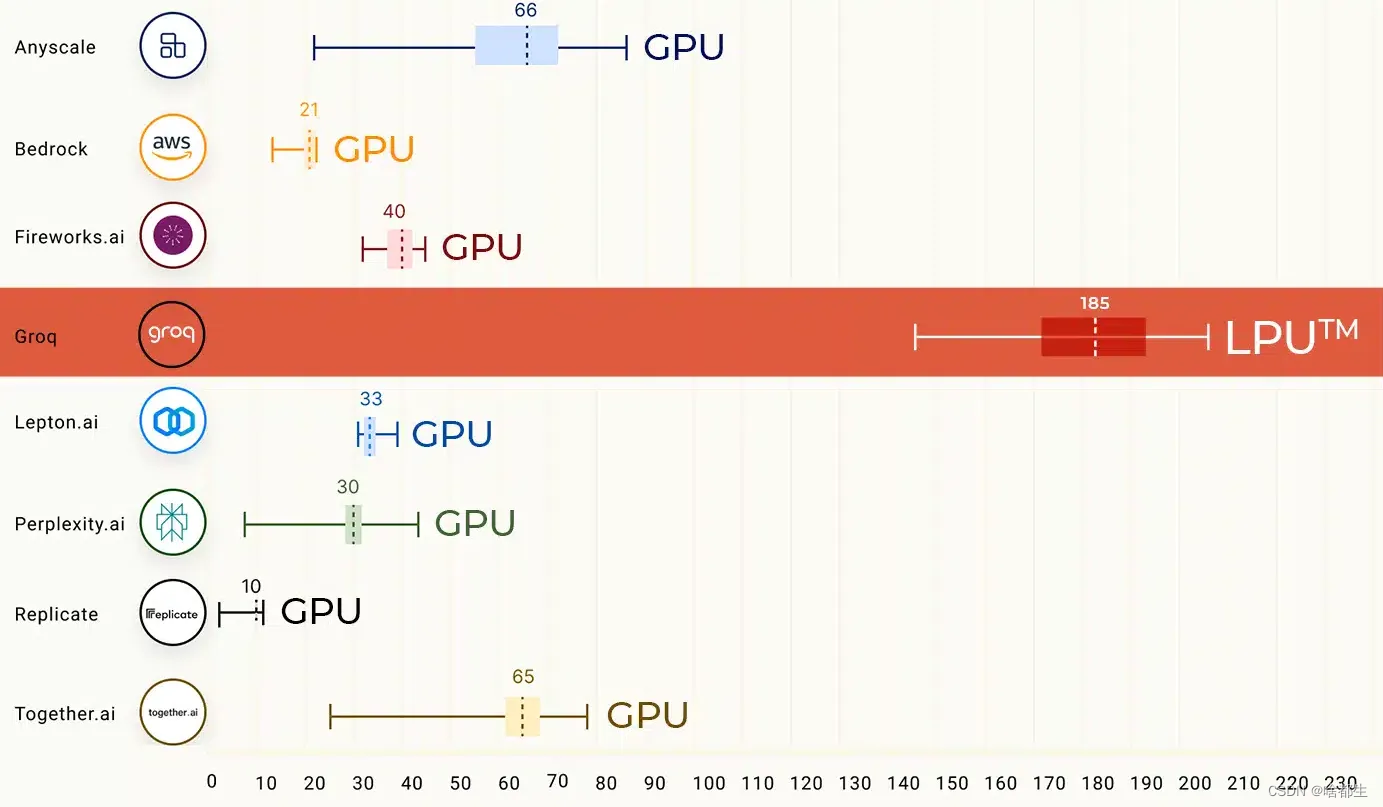
该公司将基于 LPU 的人工智能芯片命名为 “GroqChip”,采用了一种 “张量流架构”,复杂性低于传统 GPU,可实现更低的延迟和更高的吞吐量。使得该芯片成为体育直播或游戏等实时人工智能应用的理想选择
https://the-decoder.com/groqs-ai-chip-turbocharges-llms-and-generates-text-in-near-real-time/
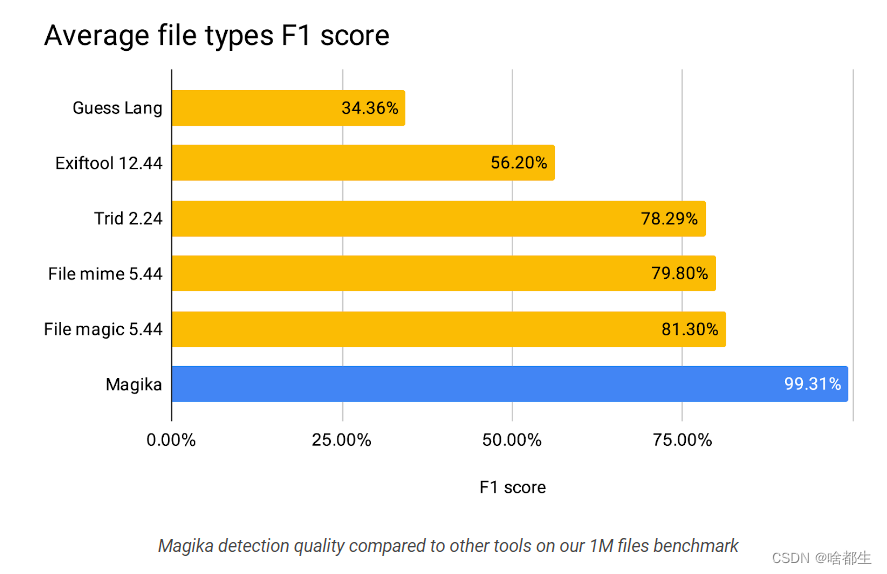
谷歌开源人工智能文件类型识别器 Magika
谷歌开源了其人工智能驱动的文件类型识别系统Magika,以帮助准确检测二进制和文本文件类型。Magika采用了一个定制的、高度优化的深度学习模型,即使在CPU上运行,也能在几毫秒内实现精确的文件识别
得益于其人工智能模型和大型训练数据集,Magika 的性能比其他现有工具高出约 20%。它在文本文件(包括其他工具难以处理的代码文件和配置文件)上的性能提升更大
在内部,Magika 被大规模用于将 Gmail、Drive 和安全浏览文件路由到适当的安全和内容策略扫描程序,从而帮助提高谷歌用户的安全性
https://opensource.googleblog.com/2024/02/magika-ai-powered-fast-and-efficient-file-type-identification.html
NVIDIA的新数据集提高了LLMs数学能力
英伟达发布了开源数学指令调整数据集 OpenMathInstruct-1,该数据集包含 180 万个问题-解决方案对。OpenMathInstruct-1 是一个高质量的合成数据集,比以前的数据集大 4 倍,而且不使用 GPT-4,通过使用 Mixtral 模型合成 GSM8K 和 MATH(两种流行的数学推理基准)的代码解释器解决方案而构建
https://arxiv.org/abs/2402.10176






![[GXYCTF2019]BabyUpload1 -- 题目分析与详解](https://img-blog.csdnimg.cn/direct/18d025e0f70a42a6a7797e8c3bf230c6.png)