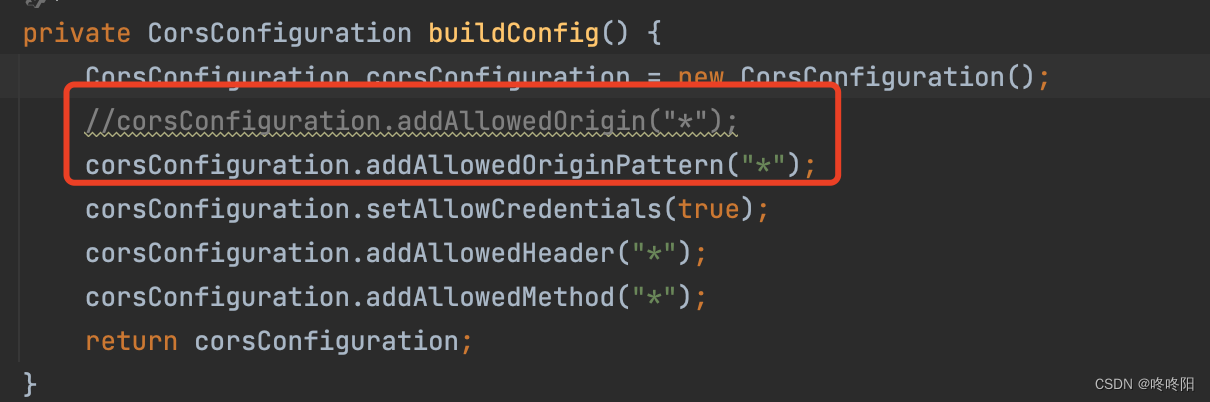
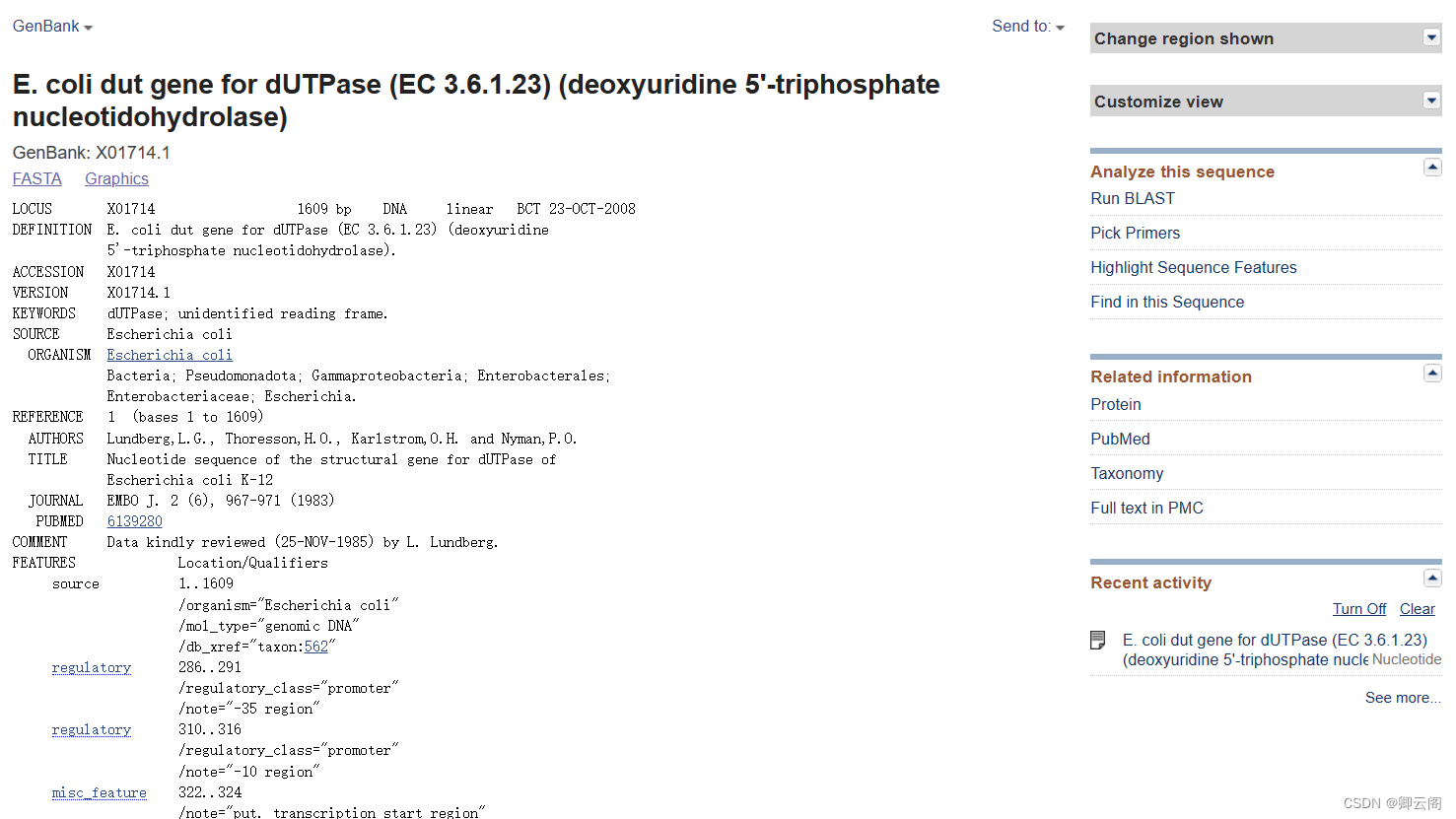
提示:sklearn.preprocessing.RobustScaler(解释和原理,分位数,四分位差)
文章目录
- @[TOC](文章目录)
- 一、RobustScaler 是什么?
- 二、代码
- 1.代码
- 2.输出结果
- 总结
文章目录
- @[TOC](文章目录)
- 一、RobustScaler 是什么?
- 二、代码
- 1.代码
- 2.输出结果
- 总结
提示:以下是本篇文章正文内容,下面案例可供参考
一、RobustScaler 是什么?
RobustScaler 的居中和缩放统计基于百分位数,因此不会受到少数非常大的边缘异常值的影响。
计算公式如下(具体计算公式以官网提供的代码为准):
value_result = (value-Media)/(Q1-Q3)
Q1的位置 = 1 * (n + 1) / 4
Q3的位置 = 3 *(n + 1) / 4
n : 表示数据的个数。
media : 中位数
Q1 : 是第 1 个四分位数(第 25 个分位数)
Q3 : 第 3 个四分位数(第 75 个分位数)

二、代码
1.代码
import pandas as pd
from sklearn.preprocessing import RobustScaler
data = pd.DataFrame(
{
'a': [1, 2, 3, 4, 6, 5, 6],
'b': [5, 6, 6, 5, 6, 5, 6],
'c': [9, 100, 2, 6, 5, 6, 8]
}
)
print(data.values)
robustlizer = RobustScaler(quantile_range=(25.0, 75.0))
robustlizer_data = robustlizer.fit_transform(data)
print(robustlizer.get_params())
print(robustlizer_data)
2.输出结果
[[ 1 5 9]
[ 2 6 100]
[ 3 6 2]
[ 4 5 6]
[ 6 6 5]
[ 5 5 6]
[ 6 6 8]]
{'copy': True, 'quantile_range': (25.0, 75.0), 'unit_variance': False, 'with_centering': True, 'with_scaling': True}
[[-1. -1. 1. ]
[-0.66666667 0. 31.33333333]
[-0.33333333 0. -1.33333333]
[ 0. -1. 0. ]
[ 0.66666667 0. -0.33333333]
[ 0.33333333 -1. 0. ]
[ 0.66666667 0. 0.66666667]]
第一列数据:【1,2,3,4,6,5,6】,重排列:1,2,3,4,5,6,6
media=4
Q1的位置 =(n + 1) / 4 = (7+1)/ 4 = 2,则Q1 = 2,同理Q3 =6
value_result[0] = (1-4)/(6-3)=-1
其他同理
总结
1,由于中位数的选取和分位点的选取规则不一样,可能导致不同的结果,尤其在处理的数据较少时,可能影响较大。
2,根据Q1,Q3的计算公式可得,有时候计算的为分数,所以在这个时候Q1和Q3的取法可能有很大的不同。
3,当数据量足够,数据较密集时,可以看到和计算公式就很吻合。

![[VulnHub靶机渗透] CONNECT THE DOTS](https://img-blog.csdnimg.cn/direct/1e1de44cd6c94f3fa288e101e33ba38a.png)


![Sqli-labs靶场第15关详解[Sqli-labs-less-15]自动化注入-SQLmap工具注入](https://img-blog.csdnimg.cn/direct/0eb65f1156c14e0a8f0a02098b7fd7eb.png)