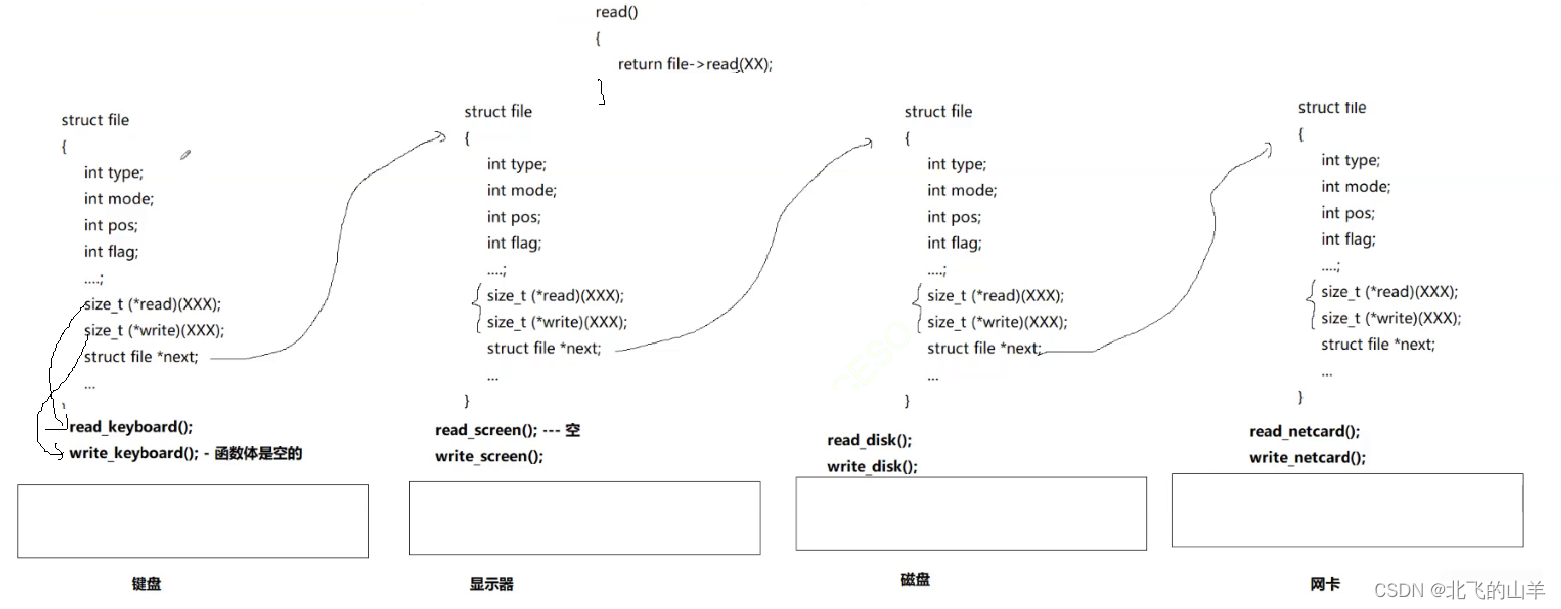
给定两个整数集合,它们的相似度定义为:Nc/Nt×100%。其中Nc是两个集合都有的不相等整数的个数,Nt是两个集合一共有的不相等整数的个数。你的任务就是计算任意一对给定集合的相似度。
输入格式:
输入第一行给出一个正整数N(≤50),是集合的个数。随后N行,每行对应一个集合。每个集合首先给出一个正整数M(≤104),是集合中元素的个数;然后跟M个[0,109]区间内的整数。
之后一行给出一个正整数K(≤2000),随后K行,每行对应一对需要计算相似度的集合的编号(集合从1到N编号)。数字间以空格分隔。
输出格式:
对每一对需要计算的集合,在一行中输出它们的相似度,为保留小数点后2位的百分比数字。
输入样例:
3
3 99 87 101
4 87 101 5 87
7 99 101 18 5 135 18 99
2
1 2
1 3
输出样例:
50.00%
33.33%tips:这里的nc是两个集合都有的元素个数,nt是两个集合一共有的元素个数。(这里的集合是去掉重复元素之后的集合)
代码:
#include <cstdio>
#include <cstring>
#include <iostream>
#include <unordered_map>
using namespace std;
int a[51][10010];
int main()
{
int n;
scanf("%d",&n);
for(int i = 1;i <= n;i++)
{
int m = 0;
scanf("%d",&m);
a[i][0] = m;
for(int j = 1;j <= m;j++) scanf("%d",&a[i][j]);
}
int k = 0;
scanf("%d",&k);
unordered_map<int,int> ha;
while(k--)
{
int i = 0,j = 0;
scanf("%d%d",&i,&j);
int sa = 0,di = 0;//sa相同元素个数,di不同元素个数
ha.clear();//清空哈希表
for(int i1 = 1;i1 <= a[i][0];i1++)
{
ha[a[i][i1]] = 1;//将元素去重
}
for(int i1 = 1;i1 <= a[j][0];i1++)
{
//这里要注意,若没有a[j][i1]这个键,会自动生成a[j][i1]这个键并赋值为1。
if(ha[a[j][i1]] == 1)//两个集合都有
{
sa++;
ha[a[j][i1]]++;//防止重复算,也即是去重
}
}
di = ha.size();//总共的个数。
printf("%.2lf%\n",100.0 * sa / di);
}
return 0;
}