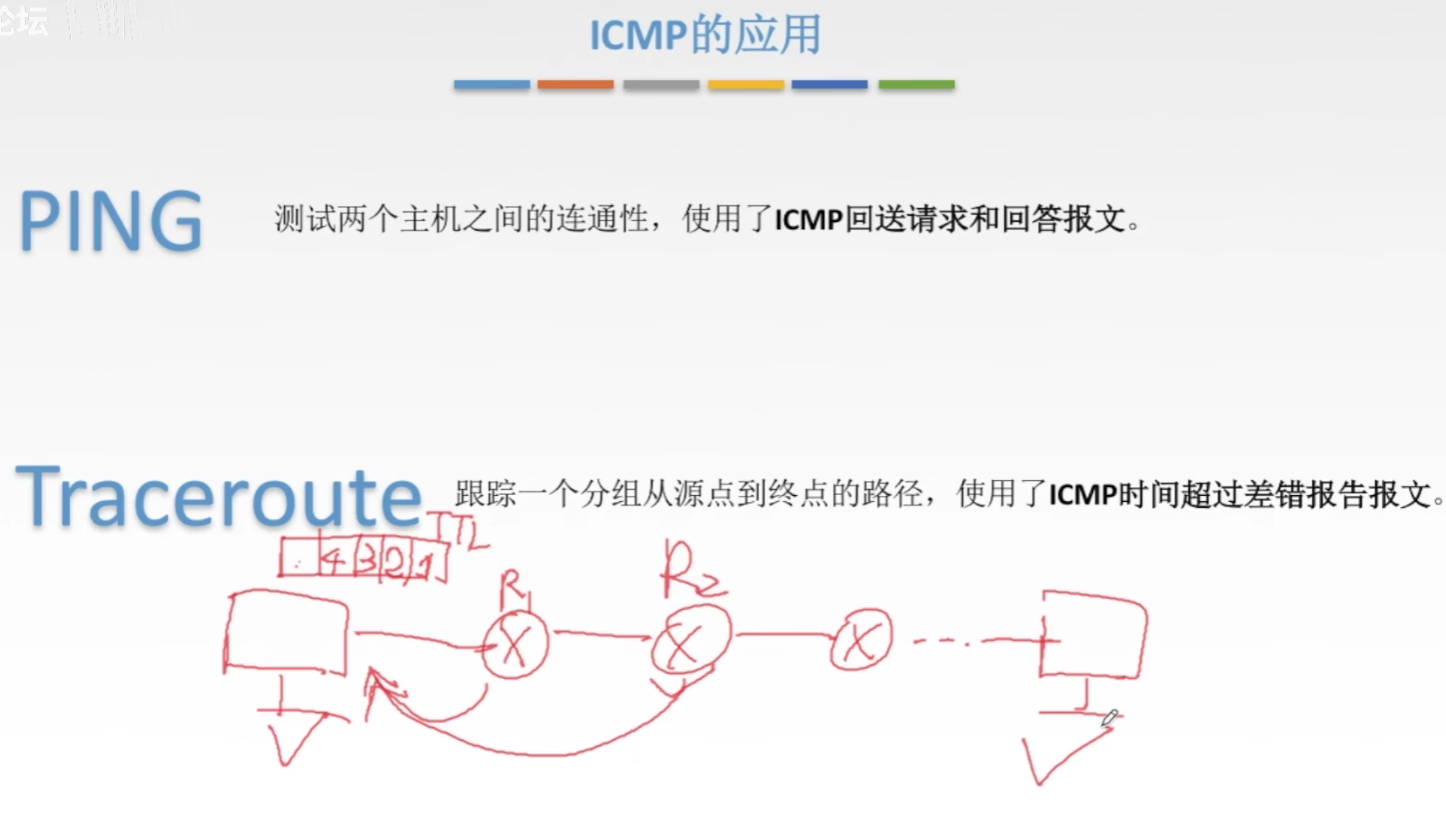
前言
本篇博客主要以神经网络拟合数据这个简单例子讲起,然后介绍网络的保存与读取,以及快速新建网络的方法。
一、神经网络对数据进行拟合
import torch
from matplotlib import pyplot as plt
import torch.nn.functional as F
# 自定义一个Net类,继承于torch.nn.Module类
# 这个神经网络的设计是只有一层隐含层,隐含层神经元个数可随意指定
class Net(torch.nn.Module):
# Net类的初始化函数
def __init__(self, n_feature, n_hidden, n_output):
# 继承父类的初始化函数
super(Net, self).__init__()
# 网络的隐藏层创建,名称可以随便起
self.hidden_layer = torch.nn.Linear(n_feature, n_hidden)
# 输出层(预测层)创建,接收来自隐含层的数据
self.predict_layer = torch.nn.Linear(n_hidden, n_output)
# 网络的前向传播函数,构造计算图
def forward(self, x):
# 用relu函数处理隐含层输出的结果并传给输出层
hidden_result = self.hidden_layer(x)
relu_result = F.relu(hidden_result)
predict_result = self.predict_layer(relu_result)
return predict_result
# 训练次数
TRAIN_TIMES = 300
# 输入输出的数据维度,这里都是1维
INPUT_FEATURE_DIM = 1
OUTPUT_FEATURE_DIM = 1
# 隐含层中神经元的个数
NEURON_NUM = 32
# 学习率,越大学的越快,但也容易造成不稳定,准确率上下波动的情况
LEARNING_RATE = 0.1
# 数据构造
# 这里x_data、y_data都是tensor格式,在PyTorch0.4版本以后,也能进行反向传播
# 所以不需要再转成Variable格式了
# linspace函数用于生成一系列数据
# unsqueeze函数可以将一维数据变成二维数据,在torch中只能处理二维数据
x_data = torch.unsqueeze(torch.linspace(-4, 4, 80), dim=1)
# randn函数用于生成服从正态分布的随机数
y_data = x_data.pow(3) + 3 * torch.randn(x_data.size())
y_data_real = x_data.pow(3)
# 建立网络
net = Net(n_feature=INPUT_FEATURE_DIM, n_hidden=NEURON_NUM, n_output=OUTPUT_FEATURE_DIM)
print(net)
# 训练网络
# 这里也可以使用其它的优化方法
optimizer = torch.optim.Adam(net.parameters(), lr=LEARNING_RATE)
# 定义一个误差计算方法
loss_func = torch.nn.MSELoss()
for i in range(TRAIN_TIMES):
# 输入数据进行预测
prediction = net(x_data)
# 计算预测值与真值误差,注意参数顺序问题
# 第一个参数为预测值,第二个为真值
loss = loss_func(prediction, y_data)
# 开始优化步骤
# 每次开始优化前将梯度置为0
optimizer.zero_grad()
# 误差反向传播
loss.backward()
# 按照最小loss优化参数
optimizer.step()
# 可视化训练结果
if i % 2 == 0:
# 清空上一次显示结果
plt.cla()
# 无误差真值曲线
plt.plot(x_data.numpy(), y_data_real.numpy(), c='blue', lw='3')
# 有误差散点
plt.scatter(x_data.numpy(), y_data.numpy(), c='orange')
# 实时预测的曲线
plt.plot(x_data.numpy(), prediction.data.numpy(), c='red', lw='2')
plt.text(-0.5, -65, 'Time=%d Loss=%.4f' % (i, loss.data.numpy()), fontdict={'size': 15, 'color': 'red'})
plt.pause(0.1)训练300次的可视化效果如下。

二、模型的保存与读取
模型保存比较简单,直接调用torch.save()函数即可。 有两种方式可以保存网络,一种是直接保存整个网络,另一种则是只保存网络中节点的参数。代码如下。
# 保存整个网络
torch.save(net,'net.pkl')
# 只保存网络中节点的参数
torch.save(net.state_dict(),'net_params.pkl')保存好网络后就是载入网络,相对也比较简单。对于第一种保存整个网络的方式而言,直接torch.load()即可。 对于第二种方式保存的网络,则需要先建立一个和之前结构一模一样的网络,然后再将保存的参数载入进来。代码如下。
# 直接装载网络
net_restore=torch.load('net.pkl')
# 先新建个一模一样的网络,再载入参数
net_rebuild=Net(n_feature=INPUT_FEATURE_DIM,n_hidden=NEURON_NUM,n_output=OUTPUT_FEATURE_DIM)
net_rebuild.load_state_dict(torch.load('net_params.pkl'))两种方法第二种保存、恢复效率会更高一些,尤其是网络很大很复杂的时候。
三、模型快速搭建
主要利用torch.nn.Sequntial()函数实现而无需新建一个class,示例代码如下。
net2=torch.nn.Sequential(
torch.nn.Linear(INPUT_FEATURE_DIM,NEURON_NUM),
torch.nn.ReLU(),
torch.nn.Linear(NEURON_NUM,OUTPUT_FEATURE_DIM))
print(net2)利用上述代码便可以搭建一个和第一部分一样的网络。唯一有所区别的是这里每一层是没有名字的,以序号标出。 而在之前我们定义层的时候,便指定了每一层的名字。除了这点区别外,其它没有区别了。 但是相比于第一种方法却简单很多了,不用定义类,也不用写初始化和前向传播函数,十分方便。
四、总计
以上便是本篇博客的主要内容,介绍了神经网络拟合数据的例子,以及网络的保存、恢复。 最后介绍了模型的快速新建方法。





![[LeetCode周赛复盘] 第 95 场周赛20230107](https://img-blog.csdnimg.cn/fd9a0b9020f54315838c8684ec010396.png)