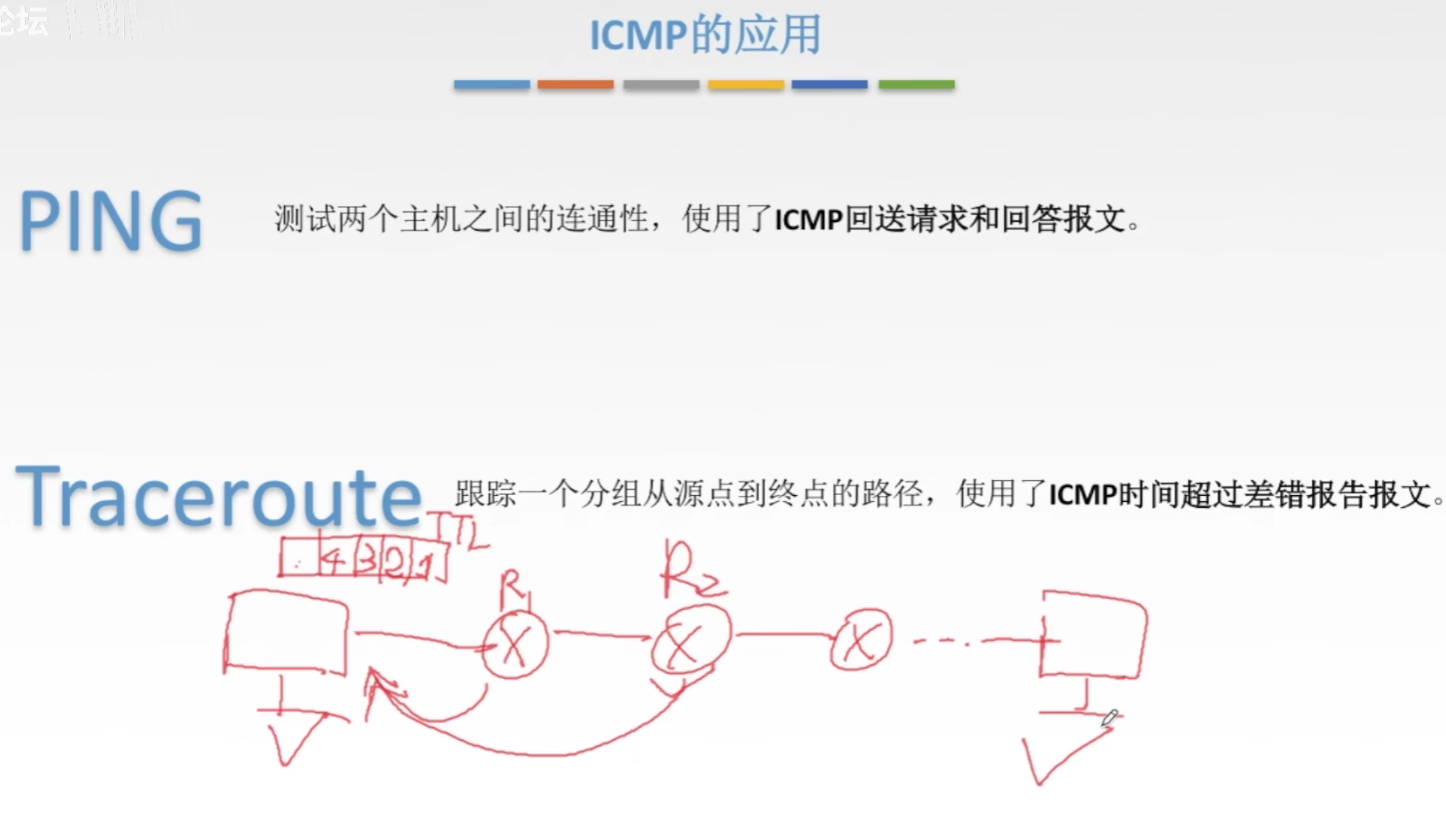
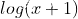接上文
Diffusion的训练推导
1. 最小化负对数似然与变分下界
在弄懂diffusion model前向和反向过程之后,最后我们需要了解其训练推导过程,即用什么loss以及为什么。在diffusion的反向过程中,根据
(
3
)
(3)
(3)式我们需要预测
μ
θ
(
x
t
,
t
)
,
Σ
θ
(
x
t
,
t
)
\mu_{\theta}(x_{t}, t), \Sigma_{\theta}(x_{t}, t)
μθ(xt,t),Σθ(xt,t),如何得到一个合理的均值和方差?类似于VAE,在对真实数据分布情况下,最大化模型预测分布的对数似然,即优化
x
0
∼
q
(
x
0
)
x_{0}\sim q(x_{0})
x0∼q(x0)下的
p
θ
(
x
0
)
p_{\theta}(x_{0})
pθ(x0)的交叉熵
L
=
E
q
(
x
0
)
[
−
log
p
θ
(
x
0
)
]
(12)
\mathcal{L} = \mathbb{E}_{q(x_{0})}[-\log p_{\theta}(x_{0})] \tag{12}
L=Eq(x0)[−logpθ(x0)](12)
注意,我们的真实目标是最大化
p
θ
(
x
)
p_{\theta}(x)
pθ(x),
(
3
)
(3)
(3)对
p
θ
(
x
)
p_{\theta}(x)
pθ(x)取了负
log
\log
log,所以这里要最小化
L
\mathcal{L}
L。与VAE类似,我们通过变分下限VLB来优化
(
12
)
(12)
(12)的负对数似然,如下
−
log
p
θ
(
x
0
)
≤
−
log
p
θ
(
x
0
)
+
D
K
L
(
q
(
x
1
:
T
∣
x
0
)
∣
∣
p
θ
(
x
1
:
T
∣
x
0
)
)
=
−
log
p
θ
(
x
0
)
+
E
q
(
x
1
:
T
∣
x
0
)
[
log
q
(
x
1
:
T
∣
x
0
)
p
θ
(
x
1
:
T
∣
x
0
)
]
=
−
log
p
θ
(
x
0
)
+
E
q
(
x
1
:
T
∣
x
0
)
[
log
q
(
x
1
:
T
∣
x
0
)
p
θ
(
x
0
:
T
)
P
θ
(
x
0
)
]
=
−
log
p
θ
(
x
0
)
+
E
q
(
x
1
:
T
∣
x
0
)
[
log
q
(
x
1
:
T
∣
x
0
)
p
θ
(
x
0
:
T
)
+
log
p
θ
(
x
0
)
⏟
此项与
q
(
x
1
:
T
∣
x
0
)
无关,可直接提出
]
=
E
q
(
x
1
:
T
∣
x
0
)
log
q
(
x
1
:
T
∣
x
0
)
p
θ
(
x
0
:
T
)
(13)
\begin{aligned} -\log p_{\theta}(x_{0}) &\leq -\log p_{\theta}(x_{0}) + D_{KL}(q(x_{1:T}|x_{0}) || p_{\theta}(x_{1:T}|x_{0})) \\ &= -\log p_{\theta}(x_{0}) + \mathbb{E}_{q(x_{1:T}|x_{0})}[\log \frac{q(x_{1:T}|x_{0})}{p_{\theta}(x_{1:T}|x_{0})}] \\ &= -\log p_{\theta}(x_{0}) + \mathbb{E}_{q(x_{1:T}|x_{0})}[\log \frac{q(x_{1:T}|x_{0})}{\frac{p_{\theta}(x_{0:T})}{P_{\theta}(x_{0})}}] \\ &= -\log p_{\theta}(x_{0}) + \mathbb{E}_{q(x_{1:T}|x_{0})}[\log \frac{q(x_{1:T}|x_{0})}{p_{\theta}(x_{0:T})} + \underbrace{\log p_{\theta}(x_{0})}_{此项与q(x_{1:T}|x_{0})无关,可直接提出}] \\ &= \mathbb{E}_{q(x_{1:T}|x_{0})} \log \frac{q(x_{1:T}|x_{0})}{p_{\theta}(x_{0:T})} \end{aligned} \tag{13}
−logpθ(x0)≤−logpθ(x0)+DKL(q(x1:T∣x0)∣∣pθ(x1:T∣x0))=−logpθ(x0)+Eq(x1:T∣x0)[logpθ(x1:T∣x0)q(x1:T∣x0)]=−logpθ(x0)+Eq(x1:T∣x0)[logPθ(x0)pθ(x0:T)q(x1:T∣x0)]=−logpθ(x0)+Eq(x1:T∣x0)[logpθ(x0:T)q(x1:T∣x0)+此项与q(x1:T∣x0)无关,可直接提出
logpθ(x0)]=Eq(x1:T∣x0)logpθ(x0:T)q(x1:T∣x0)(13)
现在我们得到了最大似然的变分下界,即式
(
13
)
(13)
(13),但是根据式
(
12
)
(12)
(12),我们要优化
E
q
(
x
0
)
[
−
log
p
θ
(
x
0
)
]
\mathbb{E}_{q(x_{0})}[-\log p_{\theta}(x_{0})]
Eq(x0)[−logpθ(x0)],比
(
13
)
(13)
(13)多了个期望,所以这里我们加上期望,同时根据重积分中的Fubini定理,得到
E
q
(
x
0
)
[
−
log
p
θ
(
x
0
)
]
≤
L
V
L
B
=
E
q
(
x
0
)
(
E
q
(
x
1
:
T
∣
x
0
)
log
q
(
x
1
:
T
∣
x
0
)
p
θ
(
x
0
:
T
)
)
=
E
q
(
x
0
:
T
)
log
q
(
x
1
:
T
∣
x
0
)
p
θ
(
x
0
:
T
)
(14)
\begin{aligned} \mathbb{E}_{q(x_{0})}[-\log p_{\theta}(x_{0})] & \leq \mathcal{L}_{VLB} \\ &= \mathbb{E}_{q(x_{0})}\left( \mathbb{E}_{q(x_{1:T}|x_{0})} \log \frac{q(x_{1:T}|x_{0})}{p_{\theta}(x_{0:T})} \right) \\ &= \mathbb{E}_{q(x_{0:T})} \log \frac{q(x_{1:T}|x_{0})}{p_{\theta}(x_{0:T})} \end{aligned} \tag{14}
Eq(x0)[−logpθ(x0)]≤LVLB=Eq(x0)(Eq(x1:T∣x0)logpθ(x0:T)q(x1:T∣x0))=Eq(x0:T)logpθ(x0:T)q(x1:T∣x0)(14)
2. 变分下界的详细推导优化
再次回到
(
12
)
(12)
(12)式,我们的目标是最小化交叉熵,现在我们得到了他的变分下界,因此我们将最小化
L
\mathcal{L}
L转移为最小化变分下界,即
L
V
L
B
\mathcal{L}_{VLB}
LVLB,下面我们对变分下界进行化简,化简过程比较长,对一些具有疑惑的化简最后附带详解
L
V
L
B
=
E
q
(
x
0
:
T
)
[
log
q
(
x
1
:
T
∣
x
0
)
p
θ
(
x
0
:
T
)
]
=
E
q
(
x
0
:
T
)
[
log
∏
t
=
1
T
q
(
x
t
∣
x
t
−
1
)
p
θ
(
x
T
)
∏
t
=
1
T
p
θ
(
x
t
−
1
∣
x
t
)
]
=
E
q
(
x
0
:
T
)
[
−
log
p
θ
(
x
T
)
+
log
∏
t
=
1
T
q
(
x
t
∣
x
t
−
1
)
∏
t
=
1
T
p
θ
(
x
t
−
1
∣
x
t
)
]
=
E
q
(
x
0
:
T
)
[
−
log
p
θ
(
x
T
)
+
∑
i
=
1
T
log
q
(
x
t
∣
x
t
−
1
)
p
θ
(
x
t
−
1
∣
x
t
)
]
=
E
q
(
x
0
:
T
)
[
−
log
p
θ
(
x
T
)
+
∑
i
=
2
T
log
q
(
x
t
∣
x
t
−
1
)
p
θ
(
x
t
−
1
∣
x
t
)
+
log
q
(
x
1
∣
x
0
)
p
θ
(
x
0
∣
x
1
)
⏟
1.
提出此项是因为无意义
]
=
E
q
(
x
0
:
T
)
[
−
log
p
θ
(
x
T
)
+
∑
i
=
2
T
log
q
(
x
t
∣
x
t
−
1
,
x
0
)
q
(
x
t
∣
x
0
)
p
θ
(
x
t
−
1
∣
x
t
)
q
(
x
t
−
1
∣
x
0
)
⏟
2.
此项与上一项的变化是额外考虑
x
0
+
log
q
(
x
1
∣
x
0
)
p
θ
(
x
0
∣
x
1
)
]
=
E
q
(
x
0
:
T
)
[
−
log
p
θ
(
x
T
)
+
∑
i
=
2
T
log
(
q
(
x
t
∣
x
t
−
1
,
x
0
)
p
θ
(
x
t
−
1
∣
x
t
)
⋅
q
(
x
t
∣
x
0
)
q
(
x
t
−
1
∣
x
0
)
)
+
log
q
(
x
1
∣
x
0
)
p
θ
(
x
0
∣
x
1
)
]
=
E
q
(
x
0
:
T
)
[
−
log
p
θ
(
x
T
)
+
∑
i
=
2
T
(
log
q
(
x
t
∣
x
t
−
1
,
x
0
)
p
θ
(
x
t
−
1
∣
x
t
)
+
log
q
(
x
t
∣
x
0
)
q
(
x
t
−
1
∣
x
0
)
)
+
log
q
(
x
1
∣
x
0
)
p
θ
(
x
0
∣
x
1
)
]
=
E
q
(
x
0
:
T
)
[
−
log
p
θ
(
x
T
)
+
∑
i
=
2
T
log
q
(
x
t
∣
x
t
−
1
,
x
0
)
p
θ
(
x
t
−
1
∣
x
t
)
+
log
q
(
x
T
∣
x
0
)
q
(
x
1
∣
x
0
)
⏟
3.
上一项展开即可
+
log
q
(
x
1
∣
x
0
)
p
θ
(
x
0
∣
x
1
)
]
=
E
q
(
x
0
:
T
)
[
−
log
p
θ
(
x
T
)
+
∑
i
=
2
T
log
q
(
x
t
∣
x
t
−
1
,
x
0
)
p
θ
(
x
t
−
1
∣
x
t
)
+
log
q
(
x
T
∣
x
0
)
−
log
q
(
x
1
∣
x
0
)
+
log
q
(
x
1
∣
x
0
)
−
log
p
θ
(
x
0
∣
x
1
)
]
=
E
q
(
x
0
:
T
)
[
log
q
(
x
T
∣
x
0
)
p
θ
(
x
T
)
+
∑
i
=
2
T
log
q
(
x
t
∣
x
t
−
1
,
x
0
)
p
θ
(
x
t
−
1
∣
x
t
)
−
log
p
θ
(
x
0
∣
x
1
)
]
=
E
q
(
x
0
:
T
)
[
D
K
L
(
q
(
x
T
∣
x
0
)
∣
∣
p
θ
(
x
T
)
)
⏟
L
T
+
∑
i
=
2
T
D
K
L
(
q
(
x
t
−
1
∣
x
t
,
x
0
)
∣
∣
p
θ
(
x
t
−
1
∣
x
t
)
)
⏟
L
t
−
log
p
θ
(
x
0
∣
x
1
)
⏟
L
0
]
\begin{aligned} \mathcal{L}_{VLB} &= \mathbb{E}_{q(x_{0:T})} \left[ \log \frac{q(x_{1:T}|x_{0})}{p_{\theta}(x_{0:T})} \right] \\ &= \mathbb{E}_{q(x_{0:T})} \left[ \log\frac{\prod_{t=1}^{T}q(x_{t}|x_{t-1})}{p_{\theta}(x_{T}) \prod_{t=1}^{T}p_{\theta}(x_{t-1}|x_{t})} \right] \\ &= \mathbb{E}_{q(x_{0:T})} \left[ -\log p_{\theta}(x_{T}) + \log \frac{\prod_{t=1}^{T}q(x_{t}|x_{t-1})}{ \prod_{t=1}^{T}p_{\theta}(x_{t-1}|x_{t})} \right] \\ &= \mathbb{E}_{q(x_{0:T})} \left[ -\log p_{\theta}(x_{T}) + \sum_{i=1}^{T} \log \frac{q(x_{t}|x_{t-1})}{p_{\theta}(x_{t-1}|x_{t})} \right] \\ &= \mathbb{E}_{q(x_{0:T})} \left[ -\log p_{\theta}(x_{T}) + \sum_{i=2}^{T} \log \frac{{\color{red}q(x_{t}|x_{t-1})}}{p_{\theta}(x_{t-1}|x_{t})} + \underbrace{{\color{blue}\log \frac{q(x_{1} | x_{0})}{p_{\theta} (x_{0}|x_{1})}}}_{1. 提出此项是因为无意义} \right] \\ &= \mathbb{E}_{q(x_{0:T})} \left[ -\log p_{\theta}(x_{T}) + \sum_{i=2}^{T} \underbrace{\log \frac{{\color{red}q(x_{t}|x_{t-1}, x_{0})q(x_{t} | x_{0})}}{p_{\theta}(x_{t-1}|x_{t}) {\color{red}q(x_{t-1}|x_{0})}}}_{2. 此项与上一项的变化是额外考虑x_{0}} + \log \frac{q(x_{1} | x_{0})}{p_{\theta} (x_{0}|x_{1})} \right] \\ &= \mathbb{E}_{q(x_{0:T})} \left[ -\log p_{\theta}(x_{T}) + \sum_{i=2}^{T} \log \left( \frac{q(x_{t}|x_{t-1}, x_{0})}{p_{\theta}(x_{t-1}|x_{t}) } \cdot \frac{q(x_{t} | x_{0})}{q(x_{t-1}|x_{0})} \right) + \log \frac{q(x_{1} | x_{0})}{p_{\theta} (x_{0}|x_{1})} \right] \\ &= \mathbb{E}_{q(x_{0:T})} \left[ -\log p_{\theta}(x_{T}) + {\color{orange}\sum_{i=2}^{T}} \left( \log \frac{q(x_{t}|x_{t-1}, x_{0})}{p_{\theta}(x_{t-1}|x_{t}) } + {\color{orange}\log \frac{q(x_{t} | x_{0})}{q(x_{t-1}|x_{0})}} \right) + \log \frac{q(x_{1} | x_{0})}{p_{\theta} (x_{0}|x_{1})} \right] \\ &= \mathbb{E}_{q(x_{0:T})} \left[ -\log p_{\theta}(x_{T}) + \sum_{i=2}^{T} \log \frac{q(x_{t}|x_{t-1}, x_{0})}{p_{\theta}(x_{t-1}|x_{t}) } + \underbrace{{\color{orange}\log \frac{q(x_{T} | x_{0})}{q(x_{1}|x_{0})}}}_{3. 上一项展开即可} + \log \frac{q(x_{1} | x_{0})}{p_{\theta} (x_{0}|x_{1})} \right] \\ &= \mathbb{E}_{q(x_{0:T})} \left[ {\color{gold}-\log p_{\theta}(x_{T})} + \sum_{i=2}^{T} \log \frac{q(x_{t}|x_{t-1}, x_{0})}{p_{\theta}(x_{t-1}|x_{t}) } + {\color{gold}\log q(x_{T}|x_{0}) - \log q(x_{1}|x_{0}) + \log q(x_{1}|x_{0}) - \log p_{\theta}(x_{0}|x_{1})} \right] \\ &= \mathbb{E}_{q(x_{0:T})} \left[ {\color{gold} \log \frac{q(x_{T}|x_{0})}{p_{\theta}(x_{T})}} + \sum_{i=2}^{T} \log \frac{q(x_{t}|x_{t-1}, x_{0})}{p_{\theta}(x_{t-1}|x_{t}) } {\color{gold} - \log p_{\theta}(x_{0}|x_{1})} \right] \\ &= \mathbb{E}_{q(x_{0:T})} \left[ \underbrace{D_{KL}(q(x_{T}|x_{0}) || p_{\theta}(x_{T}))}_{L_{T}} + \sum_{i=2}^{T} \underbrace{D_{KL}(q(x_{t-1}|x_{t}, x_{0})|| p_{\theta}(x_{t-1} | x_{t}))}_{L_{t}} - \underbrace{\log p_{\theta}(x_{0}|x_{1})}_{L_{0}} \right] \end{aligned}
LVLB=Eq(x0:T)[logpθ(x0:T)q(x1:T∣x0)]=Eq(x0:T)[logpθ(xT)∏t=1Tpθ(xt−1∣xt)∏t=1Tq(xt∣xt−1)]=Eq(x0:T)[−logpθ(xT)+log∏t=1Tpθ(xt−1∣xt)∏t=1Tq(xt∣xt−1)]=Eq(x0:T)[−logpθ(xT)+i=1∑Tlogpθ(xt−1∣xt)q(xt∣xt−1)]=Eq(x0:T)
−logpθ(xT)+i=2∑Tlogpθ(xt−1∣xt)q(xt∣xt−1)+1.提出此项是因为无意义
logpθ(x0∣x1)q(x1∣x0)
=Eq(x0:T)
−logpθ(xT)+i=2∑T2.此项与上一项的变化是额外考虑x0
logpθ(xt−1∣xt)q(xt−1∣x0)q(xt∣xt−1,x0)q(xt∣x0)+logpθ(x0∣x1)q(x1∣x0)
=Eq(x0:T)[−logpθ(xT)+i=2∑Tlog(pθ(xt−1∣xt)q(xt∣xt−1,x0)⋅q(xt−1∣x0)q(xt∣x0))+logpθ(x0∣x1)q(x1∣x0)]=Eq(x0:T)[−logpθ(xT)+i=2∑T(logpθ(xt−1∣xt)q(xt∣xt−1,x0)+logq(xt−1∣x0)q(xt∣x0))+logpθ(x0∣x1)q(x1∣x0)]=Eq(x0:T)
−logpθ(xT)+i=2∑Tlogpθ(xt−1∣xt)q(xt∣xt−1,x0)+3.上一项展开即可
logq(x1∣x0)q(xT∣x0)+logpθ(x0∣x1)q(x1∣x0)
=Eq(x0:T)[−logpθ(xT)+i=2∑Tlogpθ(xt−1∣xt)q(xt∣xt−1,x0)+logq(xT∣x0)−logq(x1∣x0)+logq(x1∣x0)−logpθ(x0∣x1)]=Eq(x0:T)[logpθ(xT)q(xT∣x0)+i=2∑Tlogpθ(xt−1∣xt)q(xt∣xt−1,x0)−logpθ(x0∣x1)]=Eq(x0:T)
LT
DKL(q(xT∣x0)∣∣pθ(xT))+i=2∑TLt
DKL(q(xt−1∣xt,x0)∣∣pθ(xt−1∣xt))−L0
logpθ(x0∣x1)
注意:这里化简有一个疑问是从倒数第2行到倒数第1行的过程中,如果要得到KL散度,是需要加上期望符号的,即 E \mathbb{E} E,但是推导中没有加,这里不知道为啥,但是就这么用好了
公式解释部分,上述公式懂的话可以不看
1.公式中的红笔部分 q ( x t ∣ x t − 1 ) q(x_{t}|x_{t-1}) q(xt∣xt−1)化简
由 x t − 1 x_{t-1} xt−1得 x t x_{t} xt比较困难,但是当提供额外的 x 0 x_{0} x0时, x t − 1 x_{t-1} xt−1和 x t x_{t} xt的候选会减少,选择更加确定,因此这里我们加上 x 0 x_{0} x0,这样推导如下
q ( x t ∣ x t − 1 ) = q ( x t − 1 ∣ x t ) q ( x t ) q ( x t − 1 ) ⟶ a d d x 0 q ( x t − 1 ∣ x t , x 0 ) q ( x t ∣ x 0 ) q ( x t − 1 ∣ x 0 ) q(x_{t}|x_{t-1}) = \frac{q(x_{t-1}|x_{t})q(x_{t})}{q(x_{t-1})} ~~ \stackrel{add~x_{0}}{\longrightarrow} ~~ \frac{q(x_{t-1}|x_{t}, x_{0})q(x_{t}|x_{0})}{q(x_{t-1}|x_{0})} q(xt∣xt−1)=q(xt−1)q(xt−1∣xt)q(xt) ⟶add x0 q(xt−1∣x0)q(xt−1∣xt,x0)q(xt∣x0)
2. 公式中蓝色部分为什么无意义?
在红笔公式化简之后,给定 x 0 x_{0} x0, q ( x t ∣ x t − 1 ) q(x_{t}|x_{t-1}) q(xt∣xt−1)可以得到 q ( x t − 1 ∣ x t , x 0 ) q ( x t ∣ x 0 ) q ( x t − 1 ∣ x 0 ) \frac{q(x_{t-1}|x_{t}, x_{0})q(x_{t}|x_{0})}{q(x_{t-1}|x_{0})} q(xt−1∣x0)q(xt−1∣xt,x0)q(xt∣x0),如果我们不将蓝色部分提出,那么 q ( x 1 ∣ x 0 ) q(x_{1}|x_{0}) q(x1∣x0)会变为 q ( x 0 ∣ x 1 , x 0 ) q ( x 1 ∣ x 0 ) q ( x 0 ∣ x 0 ) \frac{q(x_{0}|x_{1}, x_{0})q(x_{1}|x_{0})}{q(x_{0}|x_{0})} q(x0∣x0)q(x0∣x1,x0)q(x1∣x0),此表达式是无意义的
3. 由变分下界得到优化loss
去掉繁琐的推导过程以及最后的期望符号,我们再回头看一下VLB的化简结果
L
V
L
B
∝
D
K
L
(
q
(
x
T
∣
x
0
)
∣
∣
p
θ
(
x
T
)
)
⏟
L
T
+
∑
i
=
2
T
D
K
L
(
q
(
x
t
−
1
∣
x
t
,
x
0
)
∣
∣
p
θ
(
x
t
−
1
∣
x
t
)
)
⏟
L
t
−
log
p
θ
(
x
0
∣
x
1
)
⏟
L
0
\mathcal{L}_{VLB} \propto \underbrace{D_{KL}(q(x_{T}|x_{0}) || p_{\theta}(x_{T}))}_{L_{T}} + \sum_{i=2}^{T} \underbrace{D_{KL}(q(x_{t-1}|x_{t}, x_{0})|| p_{\theta}(x_{t-1} | x_{t}))}_{L_{t}} - \underbrace{\log p_{\theta}(x_{0}|x_{1})}_{L_{0}}
LVLB∝LT
DKL(q(xT∣x0)∣∣pθ(xT))+i=2∑TLt
DKL(q(xt−1∣xt,x0)∣∣pθ(xt−1∣xt))−L0
logpθ(x0∣x1)
- L T = D K L ( q ( x T ∣ x 0 ) ∣ ∣ p θ ( x T ) ) L_{T}=D_{KL}(q(x_{T}|x_{0}) || p_{\theta}(x_{T})) LT=DKL(q(xT∣x0)∣∣pθ(xT)): 这一项中的前向过程 q ( x T ∣ x 0 ) q(x_{T}|x_{0}) q(xT∣x0)是一个前向加噪的过程,而 p θ ( x T ) p_{\theta}(x_{T}) pθ(xT)是一个纯粹的高斯噪声,在我们前向过程中, q ( x T ∣ x 0 ) q(x_{T}|x_{0}) q(xT∣x0)很容易变为高斯噪声,因此 L T L_{T} LT可以看为常量,计算时忽略即可
-
L
t
=
D
K
L
(
q
(
x
t
−
1
∣
x
t
,
x
0
)
∣
∣
p
θ
(
x
t
−
1
∣
x
t
)
)
L_{t}=D_{KL}(q(x_{t-1}|x_{t}, x_{0})|| p_{\theta}(x_{t-1} | x_{t}))
Lt=DKL(q(xt−1∣xt,x0)∣∣pθ(xt−1∣xt)):这一项可以看做拉近2个高斯分布
q
(
x
t
−
1
∣
x
t
,
x
0
)
=
(
x
t
−
1
;
μ
~
(
x
t
,
x
0
)
,
β
~
t
I
)
q(x_{t-1}|x_{t}, x_{0}) = \mathcal(x_{t-1}; \tilde{\mu}(x_{t}, x_{0}), \tilde{\beta}_{t}I)
q(xt−1∣xt,x0)=(xt−1;μ~(xt,x0),β~tI)和
p
θ
(
x
t
−
1
∣
x
t
)
=
N
(
x
t
−
1
;
μ
θ
(
x
t
,
t
)
,
Σ
θ
(
x
t
,
t
)
)
p_{\theta}({x_{t-1}|x_{t}}) = \mathcal{N}(x_{t-1}; \mu_{\theta}(x_{t}, t), \Sigma_{\theta}(x_{t}, t))
pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t))之间的距离,根据多元高斯分布的KL散度求解
L t = E q [ 1 2 ∣ ∣ ∑ θ ( x t , t ) ∣ ∣ 2 2 ∣ ∣ μ ~ t ( x t , x 0 ) − μ θ ( x t , t ) ∣ ∣ 2 ] + C L_{t} = \mathbb{E}_{q}\left[ \frac{1}{2||\sum_{\theta}(x_{t}, t)||_{2}^{2}}|| \tilde{\mu}_{t}(x_{t}, x_{0}) - \mu_{\theta}(x_{t}, t) ||^{2} \right] + C Lt=Eq[2∣∣∑θ(xt,t)∣∣221∣∣μ~t(xt,x0)−μθ(xt,t)∣∣2]+C
把式 ( 10 ) (10) (10)和 ( 11 ) (11) (11)求得的 μ ~ t ( x t , x 0 ) \tilde{\mu}_{t}(x_{t}, x_{0}) μ~t(xt,x0), μ θ ( x t , t ) \mu_{\theta}(x_{t}, t) μθ(xt,t)带入得
L t = E x 0 , z ‾ t [ 1 2 ∣ ∣ Σ θ ( x t , t ) ∣ ∣ 2 2 ∣ ∣ μ ~ t ( x t , x 0 ) − μ θ ( x t , t ) ∣ ∣ 2 ] = E x 0 , z ‾ t [ 1 2 ∣ ∣ Σ θ ( x t , t ) ∣ ∣ 2 2 ∣ ∣ 1 α t ( x t − β t 1 − α ‾ t z ‾ t ) − 1 α t ( x t − β t 1 − α ‾ t z θ ( x t , t ) ) ∣ ∣ 2 ] = E x 0 , z ‾ t [ β t 2 2 α t ( 1 − α ‾ t ∣ ∣ Σ θ ∣ ∣ 2 2 ) ∣ ∣ z ‾ t − z θ ( x t , t ) ∣ ∣ 2 ] = E x 0 , z ‾ t [ β t 2 2 α t ( 1 − α ‾ t ∣ ∣ Σ θ ∣ ∣ 2 2 ) ∣ ∣ z ‾ t − z θ ( α ‾ t x 0 + 1 − α ‾ t z ‾ t , t ) ∣ ∣ 2 ] \begin{aligned} L_{t} &= \mathbb{E}_{x_{0},\overline{z}_{t}}\left[ \frac{1}{2||\Sigma_{\theta}(x_{t}, t)||_{2}^{2}} || \tilde{\mu}_{t}(x_{t}, x_{0})-\mu_{\theta}(x_{t}, t) ||^{2} \right] \\ &= \mathbb{E}_{x_{0},\overline{z}_{t}}\left[ \frac{1}{2||\Sigma_{\theta}(x_{t}, t)||_{2}^{2}} || \frac{1}{\sqrt{\alpha_{t}}}(x_{t} - \frac{\beta_{t}}{\sqrt{1-\overline{\alpha}_{t}}}\overline{z}_{t}) - \frac{1}{\sqrt{\alpha_{t}}}(x_{t} - \frac{\beta_{t}}{\sqrt{1-\overline{\alpha}_{t}}}z_{\theta}(x_{t}, t))||^{2} \right] \\ &= \mathbb{E}_{x_{0},\overline{z}_{t}}\left[ \frac{\beta_{t}^{2}}{2\alpha_{t}(1-\overline{\alpha}_{t}||\Sigma_{\theta}||^{2}_{2})} || \overline{z}_{t}-z_{\theta}(x_{t}, t) ||^{2} \right] \\ &= \mathbb{E}_{x_{0},\overline{z}_{t}}\left[ \frac{\beta_{t}^{2}}{2\alpha_{t}(1-\overline{\alpha}_{t}||\Sigma_{\theta}||^{2}_{2})} || \overline{z}_{t}-z_{\theta}(\sqrt{\overline{\alpha}_{t}}x_{0} + \sqrt{1-\overline{\alpha}_{t}}\overline{z}_{t} , t) ||^{2} \right] \end{aligned} Lt=Ex0,zt[2∣∣Σθ(xt,t)∣∣221∣∣μ~t(xt,x0)−μθ(xt,t)∣∣2]=Ex0,zt[2∣∣Σθ(xt,t)∣∣221∣∣αt1(xt−1−αtβtzt)−αt1(xt−1−αtβtzθ(xt,t))∣∣2]=Ex0,zt[2αt(1−αt∣∣Σθ∣∣22)βt2∣∣zt−zθ(xt,t)∣∣2]=Ex0,zt[2αt(1−αt∣∣Σθ∣∣22)βt2∣∣zt−zθ(αtx0+1−αtzt,t)∣∣2] - L 0 = − log p θ ( x 0 ∣ x 1 ) L_{0}=-\log p_{\theta}(x_{0}|x_{1}) L0=−logpθ(x0∣x1):其他博客解释这个相当于最后一步的熵,但是这个我不是很理解,如果想详细了解可以参考DDPM论文
所有的
L
L
L就是最终的变分下界,DDPM将其进一步化简如下
L
t
s
i
m
p
l
e
=
E
x
0
,
z
‾
t
[
∣
∣
z
‾
t
−
z
θ
(
α
‾
t
x
0
+
1
−
α
‾
t
z
‾
t
,
t
)
∣
∣
2
]
L_{t}^{simple} = \mathbb{E}_{x_{0},\overline{z}_{t}}\left[ || \overline{z}_{t}-z_{\theta}(\sqrt{\overline{\alpha}_{t}}x_{0} + \sqrt{1-\overline{\alpha}_{t}}\overline{z}_{t} , t) ||^{2} \right]
Ltsimple=Ex0,zt[∣∣zt−zθ(αtx0+1−αtzt,t)∣∣2]
论文没有将方差 Σ θ \Sigma_{\theta} Σθ考虑在训练和推断中,而是将untrained的 β t \beta_{t} βt代替 β t ~ \tilde{\beta_{t}} βt~,因为 Σ θ \Sigma_{\theta} Σθ可能会导致训练不稳定
到这里我们知道了Diffusion model的训练其实也是去预测每一步的噪声,就像反向过程中对均值推导的那样, μ ~ t = 1 α t ( x t − β t 1 − α ‾ t z ‾ t ) \tilde{\mu}_{t} = \frac{1}{\sqrt{\alpha_{t}}}(x_{t} - \frac{\beta_{t}}{\sqrt{1-\overline{\alpha}_{t}}}\overline{z}_{t}) μ~t=αt1(xt−1−αtβtzt),这里的均值不依赖 x 0 x_{0} x0,而他的求解本质上就是 x t x_{t} xt减去随机噪声
4. 训练与推断
最后我们附上论文中训练和推断的过程

知识点补充
1. 重参数化技巧
重参数化技巧在VAE中被应用过,此技巧主要用来使采样可以进行反向传播,假设我们随机采样时从任意一个高斯分布 N ( μ , σ 2 ) \mathcal{N}(\mu, \sigma^{2}) N(μ,σ2)中采样,然后预测结果,最终结果是无法反向传播的(不可导),通常做法是使用标准高斯分布 N ( 0 , I ) \mathcal{N}(0, I) N(0,I)作为引导
具体做法是首先从标准高斯分布中采样一个变量,然后根据高斯分布的均值
μ
\mu
μ和方差
σ
2
\sigma^{2}
σ2来对采样变量进行线性变换,如下
z
=
μ
+
σ
⊙
ϵ
,
ϵ
∼
N
(
0
,
I
)
z = \mu + \sigma \odot \epsilon, \epsilon \sim \mathcal{N}(0, I)
z=μ+σ⊙ϵ,ϵ∼N(0,I)
重参数化之后得到的变量 z z z具有随机性的,满足均值为 μ \mu μ,方差为 σ 2 \sigma^{2} σ2的高斯分布,这样采样过程就可导了,随机性加到了 ϵ ∼ N ( 0 , I ) \epsilon \sim \mathcal{N}(0, I) ϵ∼N(0,I)上,而不是 N ( μ , σ 2 ) \mathcal{N}(\mu, \sigma^{2}) N(μ,σ2)
再通俗解释一下,就是如果我们直接对原来高斯分布采样的话,采样之后的所有计算是可以反向传播的,但是是传不到<在采样这个步骤之前的过程>的,因为数据具有随机性了,反向传播不能传播随机性的梯度,当我们将随机性转移到 ϵ ∼ N ( 0 , I ) \epsilon \sim \mathcal{N}(0, I) ϵ∼N(0,I)上时,因为标准高斯分布之前就没有数据了,所以不用继续传播了,传播的是对其采样之后的 μ \mu μ和 σ \sigma σ
到这里我们知道了Diffusion model的训练其实也是去预测每一步的噪声,就像反向过程中对均值推导的那样, μ ~ t = 1 α t ( x t − β t 1 − α ‾ t z ‾ t ) \tilde{\mu}_{t} = \frac{1}{\sqrt{\alpha_{t}}}(x_{t} - \frac{\beta_{t}}{\sqrt{1-\overline{\alpha}_{t}}}\overline{z}_{t}) μ~t=αt1(xt−1−αtβtzt),这里的均值不依赖 x 0 x_{0} x0,而他的求解本质上就是 x t x_{t} xt减去随机噪声
4. 训练与推断
最后我们附上论文中训练和推断的过程




![[LeetCode周赛复盘] 第 95 场周赛20230107](https://img-blog.csdnimg.cn/fd9a0b9020f54315838c8684ec010396.png)