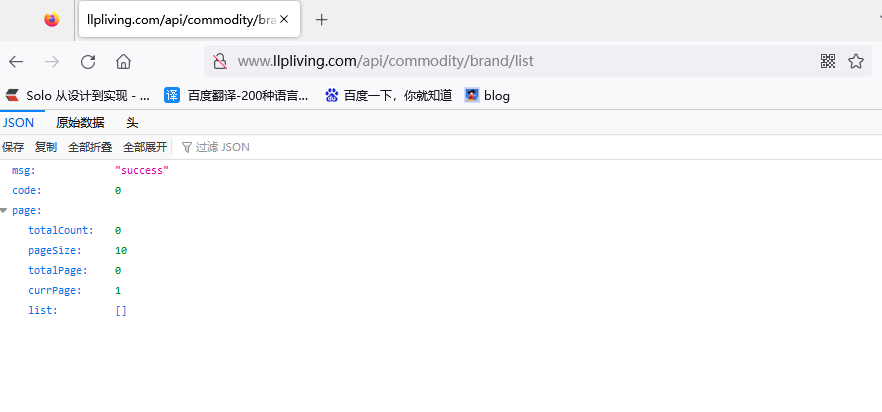
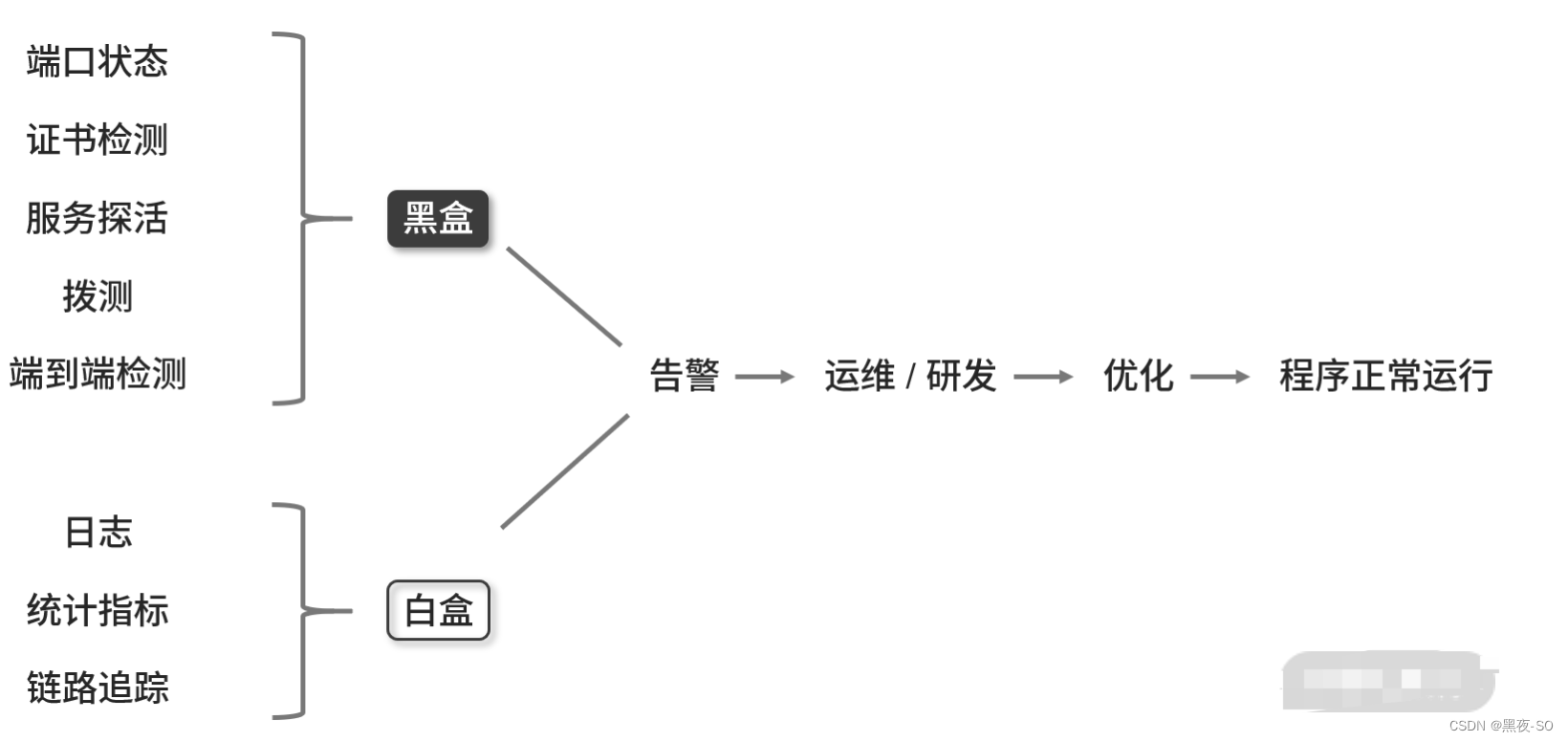
一:字符串离散化的案列
对于这一组电影数据,如果我们希望统计电影分类(genre)的情况,应该如何处理数据?
思路:重新构造一个全为0的数组,列名为分类,如果某一条数据中分类出现过,就让0变为
1.读取文件

2.统计分类列表
![]()
3.构造全为0的数组
![]()
4.给每个电影出现的位置赋值1

5.统计每个分类的电影数量的和

6.排序

7.画图


二:数据合并
数据合并之join(按照行索引合并)
join:默认情况下它是把行索引相同的数据合并在一起


行数的确定:写在join前边的输出结果就以它的行数为准
数据合并之merge(按照列索引合并)
merge:按照指定的列把数据按照一定的方式合并在一起
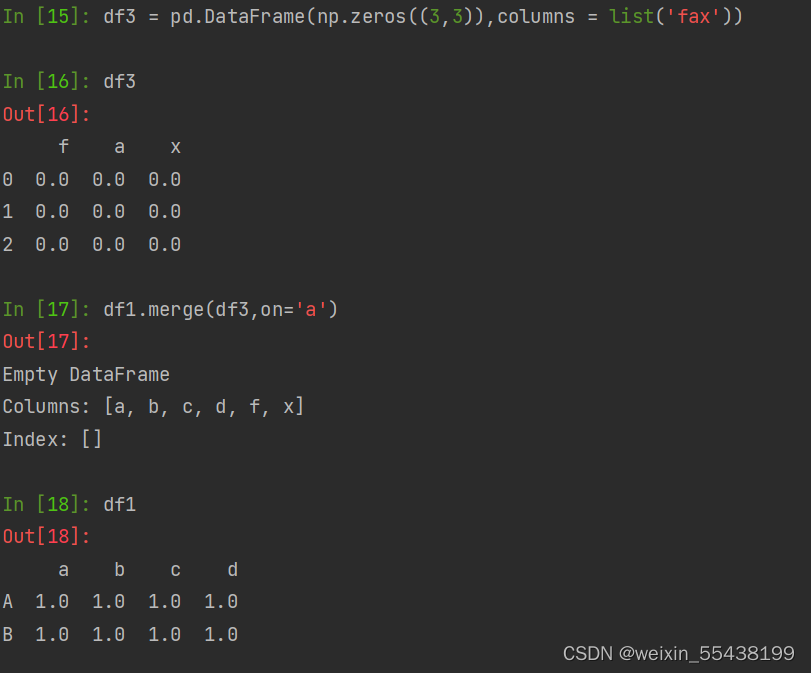
内连接:默认的合并方式inner,取并集。df3与df1的a列没有相同的值,所以输出为Empty DataFrame

df1中有二组数据为1,所以合并f,x出现了二次

df1中有一组数据为1,所以合并之后f,x出现了一次
外连接:merge outer,交集,NaN补全

merge left,左边为准,NaN补全(df1只有二行,所以结果只要二行)

merge right,右边为准,NaN补全

三:数据分组聚合
现在我们有一组关于全球星巴克店铺的统计数据,如果我想知道美国的星巴克数量和中国的哪个多,或者我想知道中国每个省份星巴克的数量的情况,那么应该怎么办?
在pandas中类似的分组的操作我们有很简单的方式来完成:df.groupby(by="columns_name")
统计美国和中国星巴克数量:
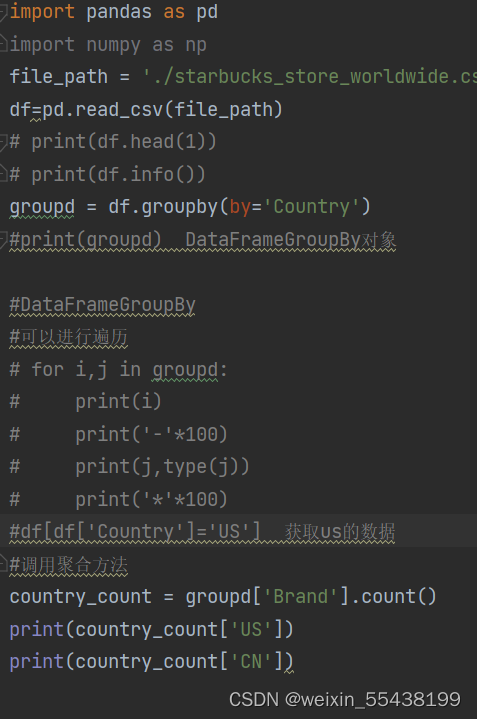
统计中国每个省份星巴克的数量


grouped = df.groupby(by="columns_name")
grouped是一个DataFrameGroupBy对象,是可迭代的
grouped中的每一个元素是一个元组
元组里面是(索引(分组的值),分组之后的DataFrame)
四:数据的索引学习

指定index

重新设置index

五:数据分组聚合练习和总结
Series复合索引

DataFrame复合索引

动手:1使用matplotlib呈现出店铺总数排名前10的国家

2.使用matplotlib呈现出每个中国每个城市的店铺数量

动手:现在我们有全球排名靠前的10000本书的数据,那么请统计一下下面几个问题: