最近基于强化学习框架来实现大模型在推理和检索能力增强的项目很多,也是Deep Research技术持续演进的缩影。之前我们讨论过《R1-Searcher:通过强化学习激励llm的搜索能⼒》,今天我们分析下Search-R1【1】。
1. 研究背景与问题
⼤模型(LLM)在⾃然语⾔理解和⽣成⽅⾯展现出了很强的能⼒,但在复杂推理和获取外部最新信息⽅⾯仍然⾯临挑战。传统的LLM在以下⽅⾯存在局限
性:
当前LLM与搜索引擎集成的主要⽅法:
- 检索增强⽣成(RAG):基于输⼊查询检索相关段落,并将它们与查询⼀起输⼊到LLM中⽣成响应。虽然简单,但常常检索不到相关信息或⽆法提供⾜够有⽤的上下⽂。
- 将搜索引擎作为⼯具:通过提⽰或微调LLM来使⽤搜索引擎作为⼯具。基于提⽰的⽅法泛化能⼒弱,而基于训练的⽅法依赖⼤规模⾼质量的标注轨迹。
OpenAI在4月11日开源BrowseComp, 这是专门用于智能体浏览器功能的测试基准。这个测试基准非常有难度,连OpenAI自己的GPT-4o、GPT-4.5准确率只有0.6%和0.9%几乎为0,即便使用带浏览器功能的GPT-4o也只有1.9%。但OpenAI最新发布的Agent模型Deep Research准确率高达51.5%。
将强化学习(RL)应⽤于搜索和推理场景⾯临三个主要挑战:
1. RL框架和稳定性:如何有效地将搜索引擎集成到LLM的RL⽅法中,同时确保优化稳定性,特别是在引⼊检索上下⽂时。2. 多轮交错推理和搜索:理想情况下,LLM应能进⾏迭代推理和搜索引擎调⽤,根据问题复杂性动态调整检索策略。3. 奖励设计:为搜索和推理任务设计有效的奖励函数是⼀个基本挑战,尚不清楚简单的基于结果的奖励是否⾜以引导LLM学习有意义和⼀致的搜索⾏为。
2. Search-R1框架概述
Search-R1是⼀个强化学习框架,使⼤模型能够在推理过程中与搜索引擎进⾏交互,从而提⾼解决复杂问题的能⼒。该框架可以看作是DeepSeek-R1 Zero的扩展,它不仅专注于参数化推理,还引⼊了搜索增强的RL训练,以增强基于检索的决策能⼒。
核⼼创新点
:
1. 搜索引擎作为环境的⼀部分:将搜索引擎建模为环境的⼀部分,使采样的轨迹序列能够交错LLM的token⽣成与搜索引擎检索。Search-R1兼容各种RL算法,包括PPO和GRPO,并应⽤检索token掩码以确保优化稳定。2. 多轮检索和推理⽀持:⽀持多轮检索和推理,通过特定tokens(<search> 和 </search>) 显式触发搜索调⽤。检索内容⽤<information> 和 </information> tokens包围,而LLM推理步骤⽤<think>和</think> tokens包装。最终答案使⽤<answer>和</answer> tokens格式化。3. 简单的基于结果的奖励函数:采⽤简单的基于结果的奖励函数,避免基于过程的奖励的复杂性。结果表明,这种最小奖励设计在搜索和推理场景中是有效的。
3. 强化学习在Search-R1中的应⽤
Search-R1框架通过将强化学习应⽤于LLM与搜索引擎的交互中,解决传统⽅法的局限性。以下是强化学习在Search-R1中的具体应⽤⽅式:
3.1 RL⽬标函数
Search-R1使⽤搜索引擎R扩展了传统的强化学习⽬标函数:
![]()
其中π是策略LLM,π 是参考LLM,r是奖励函数,D 是KL散度。与传统的RL⽅法不同,Search-R1明确将轨迹y建模为π(·|x;R),即包含搜索引擎检索结果的交互式推理过程。
3.2 检索token损失掩码
为了解决检索token优化可能导致的不稳定问题,Search-R1引⼊了检索token损失掩码机制:
掩码函数I(y )确保只对LLM⽣成的令牌进⾏优化,而不包括检索内容。
当I(y )=1时,y 是LLM⽣成的token;当I(y )=0时,y 是检索token。 应⽤检索token掩码的模型性能⼀致优于⽆掩码变体。
3.3 基于PPO的Search-R1
Proximal Policy Optimization (PPO)是⼀种流⾏的actor-critic RL⽅法。Search-R1的PPO变体针对包含搜索引擎调⽤的推理场景进⾏了优化:

其中A 是使⽤⼴义优势估计(GAE)计算的优势估计。
3.4 基于GRPO的Search-R1
Group Relative Policy Optimization (GRPO)通过利⽤多个采样输出的平均奖励作为基线来提⾼策略优化稳定性:
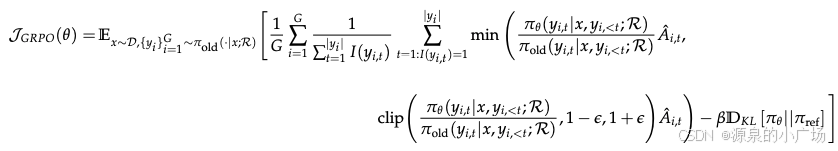

3.5 强化学习⽅法的⽐较
PPO和GRPO在Search-R1中各有优势:
收敛速度:GRPO收敛速度更快,因为PPO依赖于需要预热的critic模型。训练稳定性:PPO提供更稳定的训练⾏为,GRPO在训练较多步骤后可能出现奖励崩溃。最终性能:两种⽅法达到的最终训练奖励相当,也就是说它们在优化Search-R1⽅⾯都是有效的。
4. 系统架构与⼯作流程
Search-R1的系统架构通过创新的设计实现了LLM与搜索引擎的深度融合,下⾯详细介绍其核⼼组件和⼯作流程。
4.1 多轮搜索引擎调⽤⽣成
Search-R1采⽤了⼀个迭代框架,LLM在⽂本⽣成和外部搜索查询之间交替进⾏。具体过程如下:
1. 系统指导LLM在需要外部检索时使⽤特定的搜索调⽤标记(<search>和 </search>)来封装搜索查询。2. 当系统在⽣成序列中检测到这些token时,会提取搜索查询,查询搜索引擎,并检索相关结果。3. 检索到的信息被封装在特殊的检索标记(<information>和</information>)内,并附加到正在进⾏的展开序列中,作为下⼀个⽣成步骤的附加上下⽂。4. 这个过程迭代进⾏,直到:(1)达到最⼤动作数,或(2)模型⽣成最终响应,该响应被封装在指定的答案标记(<answer>和</answer>)之间。
4.2 训练模板
为了训练Search-R1,设计了⼀个简单的模板,指导初始LLM遵循预定义的指令。如下所⽰:
Answer the given question. You must conduct reasoning inside <think> and </think> first every time you get new information. After reasoning, if you find you lack some knowledge, you can call a search engine by <search> query </search>, and it will return the topsearched results between <information> and </information>. You can search as many times as you want. If you find no further external knowledge needed, you can directly provide the answer inside <answer> and </answer> without detailed illustrations. For example,<answer> xxx </answer>. Question: question.
这个模板将模型的输出结构化为三个部分:推理过程、搜索引擎调⽤功能和答案。我们刻意限制了约束条件仅为这种结构化格式,避免任何内容特定的偏⻅,例如强制反思性推理和搜索引擎调⽤或⽀持特定的问题解决⽅法。确保模型在RL过程中的⾃然学习动态保持可观察和⽆偏⻅。
4.3 响应⽣成的交互过程
Search-R1的交互过程可以通过以下伪代码表⽰:
算法 1: LLM Response Rollout with Multi-Turn Search Engine Calls输⼊ : 输⼊查询 x, 策略模型 π, 搜索引擎 R, 最⼤动作预算 B输出 : 最终响应 y1: 初始化展开序列 y ← ∅2: 初始化动作计数 b ← 03: while b < B do4: 初始化当前动作 LLM 展开序列 yb ← ∅5: while True do6: ⽣成响应token yt ∼ π(·|x, y + yb)7: 将yt 附加到展开序列 yb ← yb + yt8: if yt in [</search>, </answer>, <eos>] then break9: end if10: end while11: y ← y + yb12: if <search> </search> detected in yb then13: 提取搜索查询q ← Parse(yb, <search>, </search>)14: 检索搜索结果d = R(q)15: 将d 插⼊到展开 y ← y + <information>d</information>16: else if <answer> </answer> detected in yb then17: return 最终⽣成的响应 y18: else19: 请求重新思考y ← y+ "My action is not correct. Let me rethink."20: end if21: 增加动作计数 b ← b + 122: end while23: return 最终⽣成的响应 y
4.4 奖励建模
奖励函数作为训练信号,指导RL中的优化过程。Search-R1采⽤了基于规则的奖励系统,仅包含最终结果奖励,评估模型响应的正确性。例如,在事实推理任务中, 正确性可以使⽤基于规则的标准(如精确字符串匹配)进⾏评估:
![]()
其中a_pred 是从响应y中提取的最终答案,a_gold 是标准答案。与其他⽅法不同,Search-R1没有引⼊格式奖励,因为学习的模型已经表现出很强的结构⼀致性。此外, 也避免训练神经奖励模型,这⼀决定基于LLM对⼤规模RL中特定形式奖励的敏感性,以及重新训练这些模型引⼊的额外计算成本和复杂性。
5. 训练与评测⽅法
Search-R1的训练与评测涉及多个数据集、基线⽅法和实验设置,下⾯将详细介绍相关内容。
5.1 数据集
Search-R1在七个基准数据集上进⾏了评估,这些数据集分为两类:
1. 通⽤问答:NQ、TriviaQA和PopQA
2. 多跳问答:HotpotQA、2WikiMultiHopQA、Musique和Bamboogle
这些数据集涵盖了各种搜索与推理挑战,使能够对Search-R1进⾏全⾯评估。
5.2 基线⽅法
为了评估Search-R1的有效性,将其与以下基线进⾏了⽐较:
1. 不使⽤检索的推理:
直接推理
思维链推理(CoT)
2. 使⽤检索的推理:
检索增强⽣成(RAG)
IRCoT
Search-o1
3. 基于微调的⽅法:
监督微调(SFT)
不使⽤搜索引擎的RL微调(R1)
这些基线涵盖了检索增强和微调⽅法的⼴泛范围,使能够全⾯评估Search-R1在零样本和学习检索设置中的表现。
5.3 实验设置
实验使⽤两种类型的模型:Qwen-2.5-3B(基础/指令)和Qwen-2.5-7B(基础/指令)。对于检索,使⽤2018年Wikipedia转储作为知识来源,E5作为检索器。为确保公平⽐较,所有基于检索的⽅法都设置为检索3个段落。
对于训练,将NQ和HotpotQA的训练集合并,形成了⼀个统⼀的数据集,⽤于训练Search-R1和其他基于微调的基线。评估在七个数据集的测试或验证集上进⾏,以评估域内和域外性能。精确匹配(EM)被⽤作评估指标。
主要超参数设置
- PPO变体:策略LLM学习率为1e-6,值LLM学习率为1e-5。训练500步,策略和价值模型的预热⽐例分别为0.285和0.015。
- GRPO训练:策略LLM学习率为1e-6,每个提⽰采样5个响应。模型训练500步,学习率预热⽐例为0.285。
- 通⽤设置:使⽤8个H100 GPU,总批量⼤小为512,最⼤序列⻓度为4,096个标记,最⼤响应⻓度为500。
- 奖励计算:使⽤精确匹配(EM)计算结果奖励。
6. 实验结果与分析
Search-R1在多个数据集上的实验结果表明其优于基线⽅法,并为模型⾏为提供了重要⻅解。
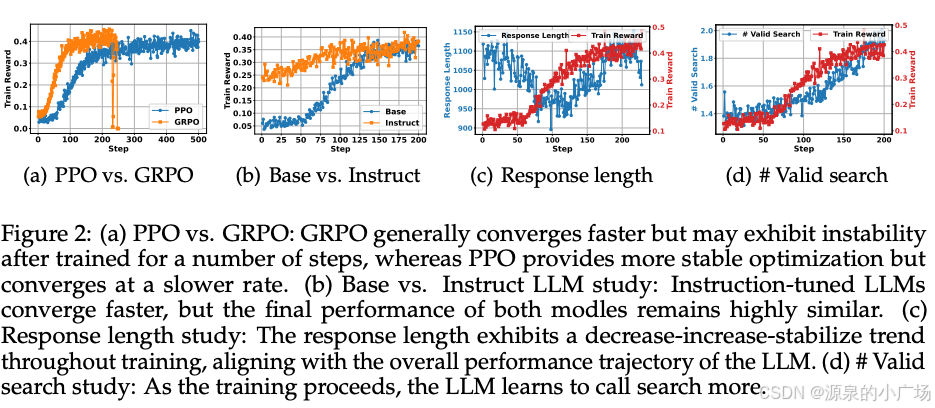
6.1 主要性能结果
在七个数据集上与基线⽅法的⽐较结果表明:
Search-R1在所有数据集上持续优于强基线⽅法,使⽤Qwen2.5-7B和Qwen2.5-3B分别实现了41%和20%的平均相对改进。
Search-R1优于不使⽤检索的LLM推理的RL训练(R1),这也比较符合预期,因为将搜索引⼊LLM推理提供了对相关外部知识的访问,提⾼了整体性能。 Search-R1对基础和指令调整模型都有效,表明DeepSeek-R1-Zero⻛格的RL与基于结果的奖励可以成功应⽤于搜索推理。
较⼤的模型在学习如何进⾏搜索⽅⾯表现更好,7B模型的Search-R1与3B模型相⽐显⽰出更⼤的"性能差距"。
6.2 不同RL⽅法的⽐较
对PPO和GRPO作为基础RL⽅法的Search-R1评估表明:
GRPO在所有情况下的收敛速度都快于PPO。这是因为PPO依赖于critic模型,在有效训练开始前需要⼏个预热步骤。
PPO展⽰了更⼤的训练稳定性。GRPO在训练多步后导致奖励崩溃,而PPO保持稳定。
PPO和GRPO的最终训练奖励是可⽐的。尽管在收敛速度和稳定性上存在差异,但两种⽅法都达到了类似的最终训练奖励和性能,表明两者都适⽤于优化SearchR1。
6.3 基础模型与指令模型的对⽐
对基础LLM和指令调整LLM的训练动态分析表明:
指令调整模型收敛更快,与基础模型相⽐初始性能更⾼。 不过两种模型类型的最终训练奖励在训练后保持⾼度相似。这表明虽然⼀般后训练加速了推理加搜索场景中的学习,但RL可以随着时间有效地弥补差距,使基础模型达到可⽐的性能。
6.4 响应⻓度和有效搜索研究
使⽤Qwen2.5-7b-base模型对Search-R1的响应⻓度和有效搜索引擎调⽤次数进⾏了分析,关键趋势如下:
1. 早期阶段(前100步):响应⻓度急剧减少,而训练奖励略有增加。在此阶段,基础模型学会消除过多的填充词,并开始适应任务需求。2. 后期阶段(100步后):响应⻓度和训练奖励都显著增加。此时,LLM学会频繁调⽤搜索引擎,由于检索到的段落,导致响应更⻓。随着模型更有效地利⽤搜索结果,训练奖励⼤幅提⾼。3. 随着训练的进⾏,LLM学会更多次地调⽤搜索引擎。
6.5 检索token损失掩码
对Qwen2.5-7b-base模型进⾏的实验表明,应⽤检索token掩码可以使LLM有更⼤的改进,缓解意外的优化效果,确保更稳定的训练。使⽤检索token损失掩码训练的Search-R1持续优于没有掩码的变体。
7. 参考材料
【1】Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning