本篇来聊聊OLAP与OLTP的区别以及它们各自的适用场景,以此话题为导引和大家聊聊技术视野与知识储备对于研发同学的重要性,最后站在事务处理与在线分析的角度分别论述下两个数据世界的底层构建逻辑。
OLAP、OLTP的概念与区别
概念
了解OLAP、OLTP的概念,识别各自适用场景,发挥各自的功能优势
| 场景 | 特点 |
|---|---|
| OLTP | 偏向数据存储数据事务性(ACID)、实时性 |
| OLAP | 偏向数据分析数据计算、聚合、转换 |
- OLAP(On-Line Analytical Processing)联机分析处理
基本特征是前台接收的用户数据可以立即传送到计算中心进行处理,并在很短的时间内给出处理结果,是对用户操作快速响应的方式之一。应用在数据仓库,使用对象是决策者。OLAP系统强调的是数据分析,响应速度要求不高。
- OLTP(On-Line Transaction Processing)联机事务处理
能够迅速、一致、交互地从各个方面观察信息,以达到深入理解数据的目的。它具有FASMI(Fast Analysis of Shared Multidimensional Information),即共享多维信息的快速分析的特征。主要应用是传统关系型数据库。OLTP系统强调的是内存效率,实时性比较高。
OLTP是基础能力,OLAP是更高层诉求

OLTP是基础能力,是必需品
如果用马斯洛需求理论来拆解和评析,OLTP一定是第一位的,是更为底层、基础的需求实现,它不仅要确保数据的事务性,还要提供数据的检索、变更能力等。
当系统构建满足了最基础的存储/检索需求后,从下到上是足够支撑业务正常运转的,业务发展是一个持续性过程,这其中的业务形态、收益效果需要OLTP场景积累的数据进行验证,而验证的过程其实就是数据筛选的过程,会把单点、离散的数据个体进行聚拢,从更高层次进行审视和分析,也正是因为这一数据查看视角的变化从一定程度上导致了OLTP到OLAP核心点的转变。
OLAP是更高诉求,是进阶物
不知你是否会有疑问 ——— 在没有OLAP、大数据等概念、人们还没有开发出引以为豪的诸多配套组件的年代,较大数据量的分析和处理就没有办法做了吗?答案是NO!可以做,但是体验很不好。
刚毕业那会儿,我是在一家服务传统行业的公司工作,接触的客户也都是传统企业,一次在客户现场下班走,我看到客户开着电脑亮着大屏幕,我问下班为什么不关机呢?客户回答说他要导出数据,现在打开页面开始查,明天早上来的时候就可以看到结果了。这个场景真是既好笑又无奈,好笑的是这糟糕的服务性能让用户体验极差,无奈的是传统行业技术普遍比较过时落后最终也拖累业务。
技术视野与知识储备的重要性
上面这段有趣经历也引出了下面的话题,那就是技术视野的重要性,传统行业也好,个人知识储备也好,一个是从工作而言,另一个是从个人成长来讲,都需要去了解前沿的发展,学习优秀的实践,而不是闭门造车,在彷徨中继续彷徨。
开拓技术视野,方案设计不扭曲
对于业务研发同学而言,关于数据相关的技术栈基本就是mysql、es这些,在设计统计、监控等在线或准在线数据分析需求时,会受限于技术视野和认知在设计开发环节更多地将此类需求的技术方案依附在mysql、es等数据源上进行设计和交付。
其实,除了这些研发熟悉的数据源,大数据平台也提供了诸多的数据能力支持,需要研发同学开阔一些技术视野,跳出个人技术舒适区,向上下游多扩展一些技术联动和资源进行融合,可以将应用层、数据层按需剥离,各司其职,有效发挥各自优势。
不难发现,如果按照这种狭隘的技术设计路径实践出来的系统,无论是架构合理性还是用户体验上都会存在一定问题,因为传统的mysql提供的是离散、单点数据的高效率检索支持,es是搜索引擎在一定程度上也是如此,所以它们并不在数据聚合、统计等的处理上存在优势,如果把不擅长的领域交给它们处理从方案设计初始就是不合理、失败的,会让技术方案过于扭曲,并且在后续交付使用的过程中出现底层不牢固导致诸多问题,重复进行修补也于事无补,陷入方案陷阱中拖累业务,也让研发参与者疲惫不堪。
希望每一位研发小伙伴都有这种技术设计意识,数据存储和处理不仅仅只有关系型数据库!类似地,当发现技术方案支持的业务项目运转过程非常吃力,或许该返工回起点来评估和研判合理性,而不是一味地打补丁做所谓的“功能优化”,要逃离这种用战术勤奋掩盖战略懒惰的操作,方向错了结果也是偏的。
分层设计,各司其职
| 模块分层 | 功能职责 | 数据特点 | 核心角色 | 服务方式 |
|---|---|---|---|---|
| 应用层 | 逻辑编排 | 单点、离散数据、事务性要求,数据量较小 | 研发RD | - |
| 数据层 | 数据处理 | 聚合、统计、转换等,数据量较大 | 数据BP | - SDK/API - 直连数据源 |
比较推荐的技术方案思路是区分好应用层与数据层的分层设计,应用层做好逻辑编排,数据层做好数据处理,分层设计的好处是能够让方案模块化且更为聚焦,针对问题可以分摊到不同资源上进行击破,从需求阶段、设计阶段、实现阶段、运营阶段
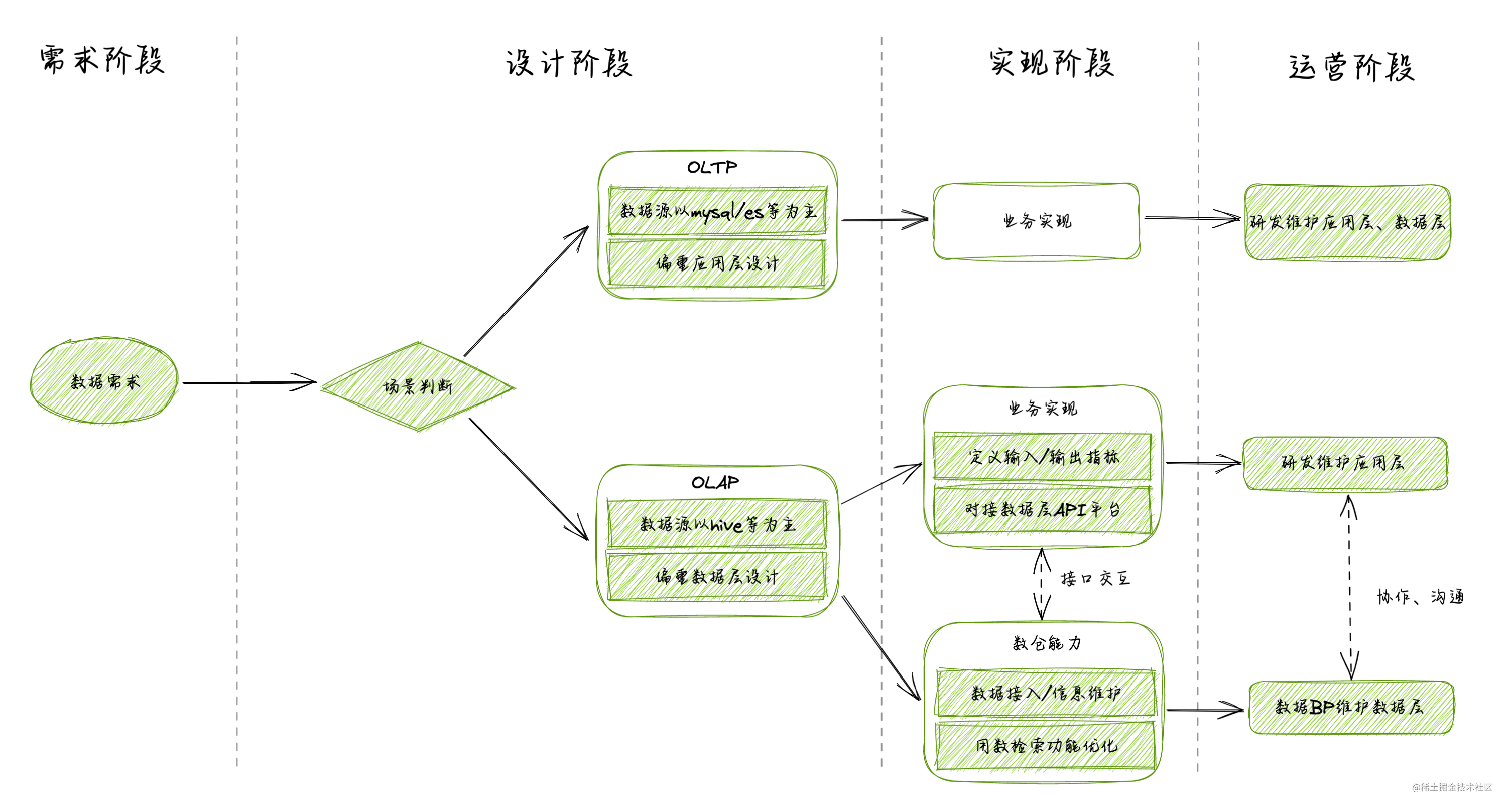
- 『Part-1 需求阶段』
业务提出数据相关需求,该阶段可以研发和数据BP同事共同参与,如果是数据平台能承载的直接交由数据BP同事跟进处理即可,若设计业务功能、页面开发等需要研发介入主导并进行下一步评估。 - 『Part-2 设计阶段』
先对需求进行场景判断,若是OLTP场景则建议采用mysql、es等作为数据源,由研发从系统应用层设计实现来进行交付;若是OLAP场景则建议采用以数据平台hive、clickhouse等数据源进行设计来展开。 - 『Part-3 实现阶段』
将数据计算下沉到数据侧,应用层处理业务功能来串联逻辑,数据BP可以提供数据源接入、按照定义输入/输出指标通过API方式进行数据输出的能力,数据层保证数据写入、用数正确、读取性能等,研发只需要关心应用层逻辑即可。这里是一个大的判断方向的推荐,如果需求场景复杂也可以两者结合。 - 『Part-4 运营阶段』
后续运营问题排查、性能优化可以按照数据层、业务层去准确定位问题和进行有效治理,这样的好处是研发不再困于蹩脚的数据结构、数据算力的设计和性能优化中,充分使用和发挥数据BP侧以及大数据平台能力来下沉。
数据存储及组件选择
关于数据库的选型调研可以参考 https://db-engines.com/en/ranking
我们将视角聚焦在数据层,看看在日常业务场景中是如何进行数据组件选型的。
| 数据类型 | 代表组件 |
|---|---|
| 关系型数据 | MySQL、Clickhouse、Hive… |
| 时序数据 | Prometheus、Clickhouse… |
| 文档型数据 | MongoDB、MySQL… |
| 搜索引擎 | ElasticSearch、MySQL、MongoDB、Redis… |
| KV | Redis… |
| 图数据库 | Neo4j… |
- 『关系型数据』
在当下的系统开发中应用层都会秉持面向对象的思想进行设计和抽象,这已经是一种默认和必须的开发规范,这种映射关系下沉到数据层,较为普遍的就是关系型数据库,大部分场景的开发工作还是围绕关系型数据库mysql、oracle等展开。
其他数据存储或组件更像是关系型数据库的副本,它们服务的是特殊场景下的功能诉求。当需要复杂的条件筛选检索时,数据可以从关系型数据库复制到es提供强劲的搜索引擎能力;当需要聚合分析时,数据又可以从关系型数据库复制到hive、clickhouse提供离线、实时的用数能力。 - 『时序数据』
顾名思义,时序数据库便是按照时间顺序进行存储的,对于时间范围的数据检索较为友好,较为匹配和适合的场景便是围绕时间轴进行的监控统计、趋势图等,还有按时间周期进行跑批的业务数据。
- 『文档数据』
对于文档数据的使用这里并不指的是一个word、excel、pdf这些文档文件,而是类似JSON、XML这样的泛结构化数据,当下最流行的还是MongoDB,它打破了关系型数据库schema的预定义限制,支持类JSON结构进行自定义拓展和存储,也摒弃了关系型数据库JOIN操作,而是将逻辑关系嵌套入数据结构本身。
对于数据层级较多且存在包含关系的业务数据来说,MongoDB是一个不错的选择,常见的有组织结构关系、试题、书籍等。 - 『搜索引擎』
搜索引擎当下最火爆的首选一定是elasticsearch,具体的特性和能力这里不赘述,可参考ElasticSearch官网。 - 『KV』
KV即键值对存储,它的数据结构、实现相对简单,适合存储小规模量级数据,特别适合作为缓存层数据的存储,常用的缓存设计组件可以分为两类,一种是内存级缓存,如JVM,另一种是应用级缓存,如Redis、Memcached。缓存数据主要解决的是较高并发场景下数据查询问题,特别适合短小、相对惰性的数据进行存储,能够做到以较低成本满足较高业务诉求的目的。一般来说,增加一层缓存是比较容易实现的,短时间的ROI较高,而关于缓存的使用和设计根据业务场景的复杂性还会有很多有意思的实践方案,后面章节会逐一展开论述。 - 『图数据库』
关于图数据库的应用比较聚焦特定领域和行业,比如社交网络、物流等。对于大多数业务来说,图数据库可能是一个技术永远不会涉及的盲区,正所谓业务驱动技术,三板斧能够搞定的事情着实没必要花里胡哨搞不相干的技术噱头来硬贴。
即使业务中用不到,但也推荐研发小伙伴扩展自身技术视野,了解下图数据库的底层逻辑和一些常规技术细节,对于日后技术方案设计可能会有一些帮助和灵感加持,因为技术底层是共通的,多学习一定会有收获。
构建可靠、准确的底盘支持 —— OLTP

在OLTP场景下,数据存储划分可以大致分为三层,如下:
| 层级 | 要求 |
|---|---|
| Level-1 基础数据 | 必须支持事务特性(ACID) |
| Level-2 异构数据 | 以基础数据为源,变换数据结构以支持场景要求 |
| Level-3 辅助数据 | 配合其他数据支持功能 |
- 基础数据 围绕
MySQL进行核心业务数据进行关系存储,部分泛结构化数据存储在MongoDB。 - 异构数据 如为满足复杂查询等特性以
MySQL为源通过binlog+MQ的数据通道方式同步异构出ElasticSearch存储进行功能满足。 - 辅助数据
保证可靠、准确的底气
在数据存储、变更过程中异常是不可避免的,系统异常可以捕获进行逻辑处理而补齐,但是硬件异常对保证数据的破坏性很大,如何守住数据可靠、准确的底气呢?那就是要严格遵从ACID事务特性,MySQL、MongoDB之类目前都具备这种能力,确保技术方案可以放心“食用”,在技术选型上没有后顾之忧。
如何应对高并发写入
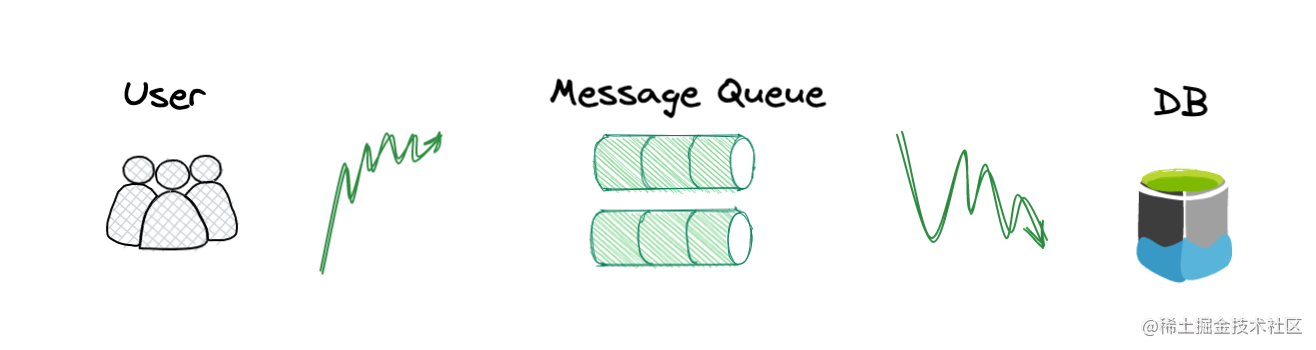
常用方案便是异步处理,将请求的第一受力面切向消息队列进行入队存储,从另一端进行控流消费,这样的好处是可以既不丢失业务请求量,又可以保护数据库不直接面对流量洪峰冲击,让写入流量可控。
异步方案虽好,也需要充分考虑以下问题:
- 消息的事务性 当流量路由到消息队列,消息队列便承载了数据记录的存储职责,需要保证“底气”的可靠,引入一层节点不能出现数据链路断流的问题。
- 消息幂等 流量请求聚合到一个整体的消息队列进行排队消费,根据消息队列的消费特性,不可避免会出现重复消费或重试的情况,需要数据最终存储或下游应用系统充分理解和考虑这种情况并进行兜底和处理,一笔业务产生多个数据是糟糕且不符合预期的。
- 数据最终一致 由于引入中间件处理,增长了数据消费路径,在方案设计时需要考虑数据展示和中间态问题,短时间的数据周转是不易察觉的,而当海量数据冲击下来后,会出现明显的请求入流量大于消费出流量的情况,这种比例倾斜会异常夸张,在数据消费积压、缓慢的过程中,需要处理好数据上游展示和感知能力,避免由于技术方案引入的复杂性导致业务误解的偏差。
如何处理高并发读取
| 数据分类 | 数据存储特点 | 挑战 | 举例 |
|---|---|---|---|
| 个体化数据 | 数据存储离散 | 高并发 | 用户订单、注册状态、账户余额等 |
| 通用化数据 | 数据存储集中 | 高并发 |
在OLTP场景下,高并发读取的特点是读取来源多,个体化数据呈现离散性特点,通用化数据呈现聚集热特点。处理的思路可以从一横一纵两个方向进行,如下:
- 个体化数据
个体化数据要求在准确的基础上尽可能保证性能,检索数据的路径很简单,主要依靠索引进行回表查询,甚至使用覆盖索引完成一次数据读取。问题在于流量洪峰会全部砸在一个数据存储上,这无疑加重数据库负担。
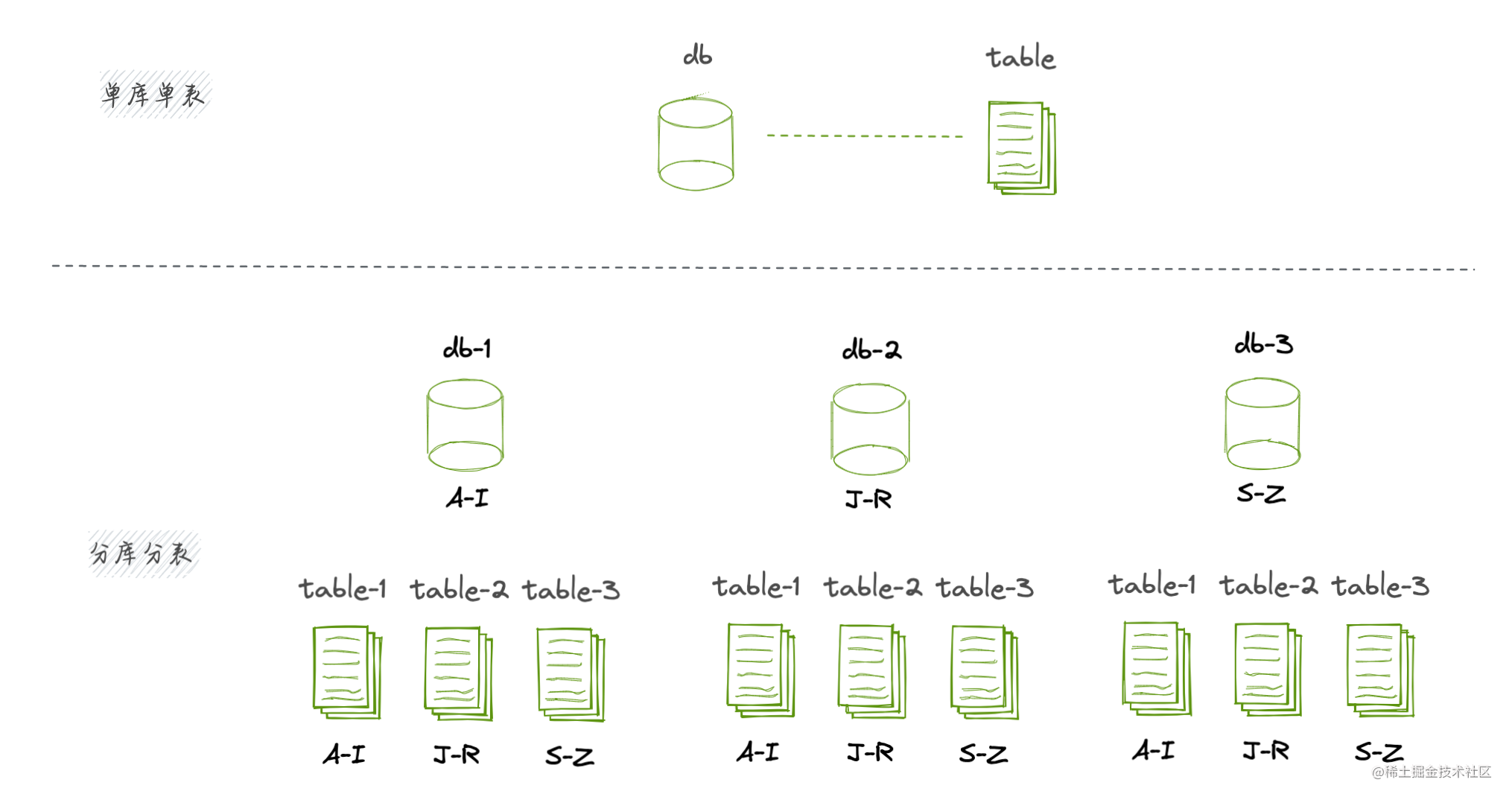
横向方案可以进行水平扩展,提前对数据进行分库分表,让多个数据库、多个表空间来共同分流洪峰,从物理存储上分离,提高每一个单点的性能,最终实现全局的提升。
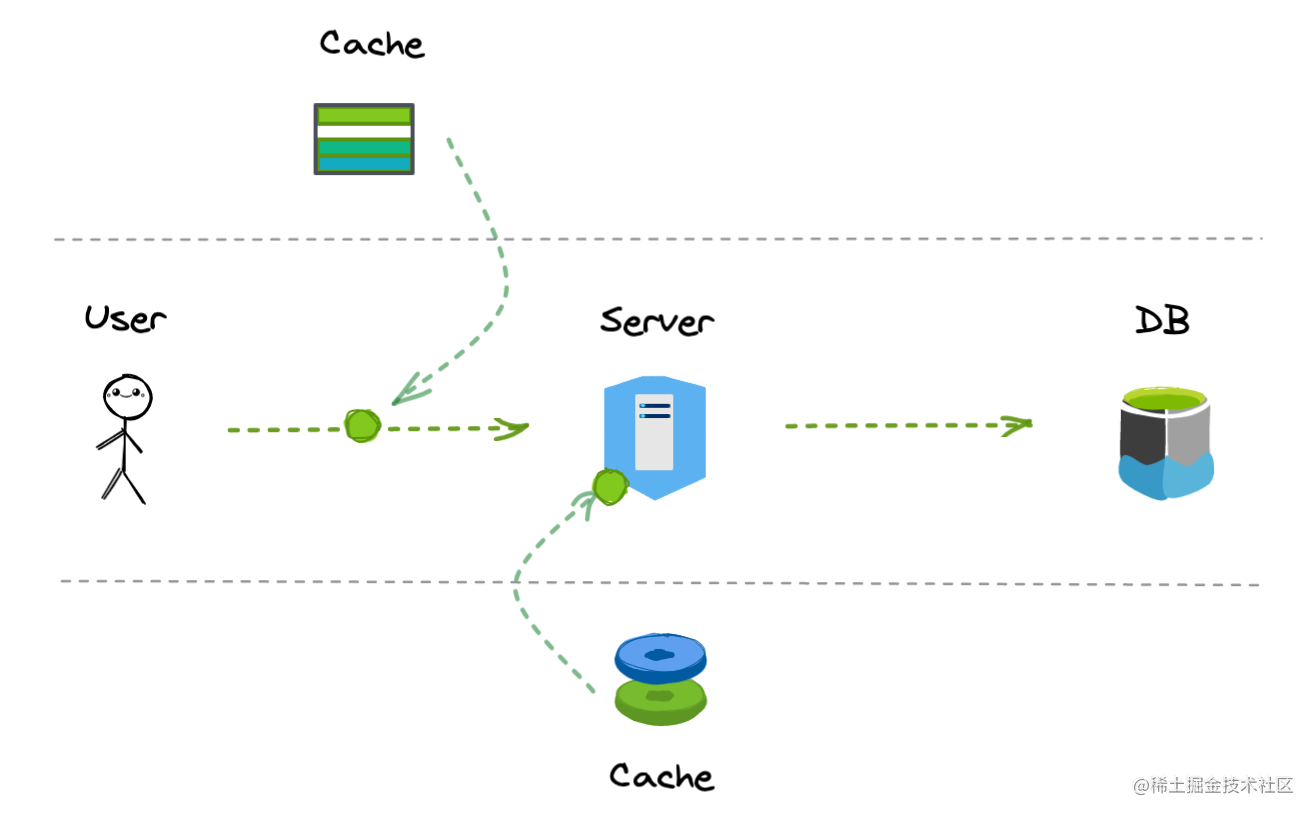
纵向方案可以考虑在请求的数据链路上下功夫,常用的技巧就是增加缓存,通过更上游的缓存层存储提前返回,减少流量进入数据库的概率,从而在一定程度上起到保护作用,而且缓存数据的读取要远远高于数据库的磁盘级别读取。
- 通用化数据
通用化数据较为相对惰性,变更不频繁,但容易形成热点数据,因此需要对其进行分流和均摊,避免将单点冲破。常用的方法是可以参考Nginx的流量分发策略,可以池化、分段复制出相同多份数据存储,轮训、均匀、哈希等方式实现分发控制。
打造聚合、多维的分析能力 —— OLAP
T+1标配套餐
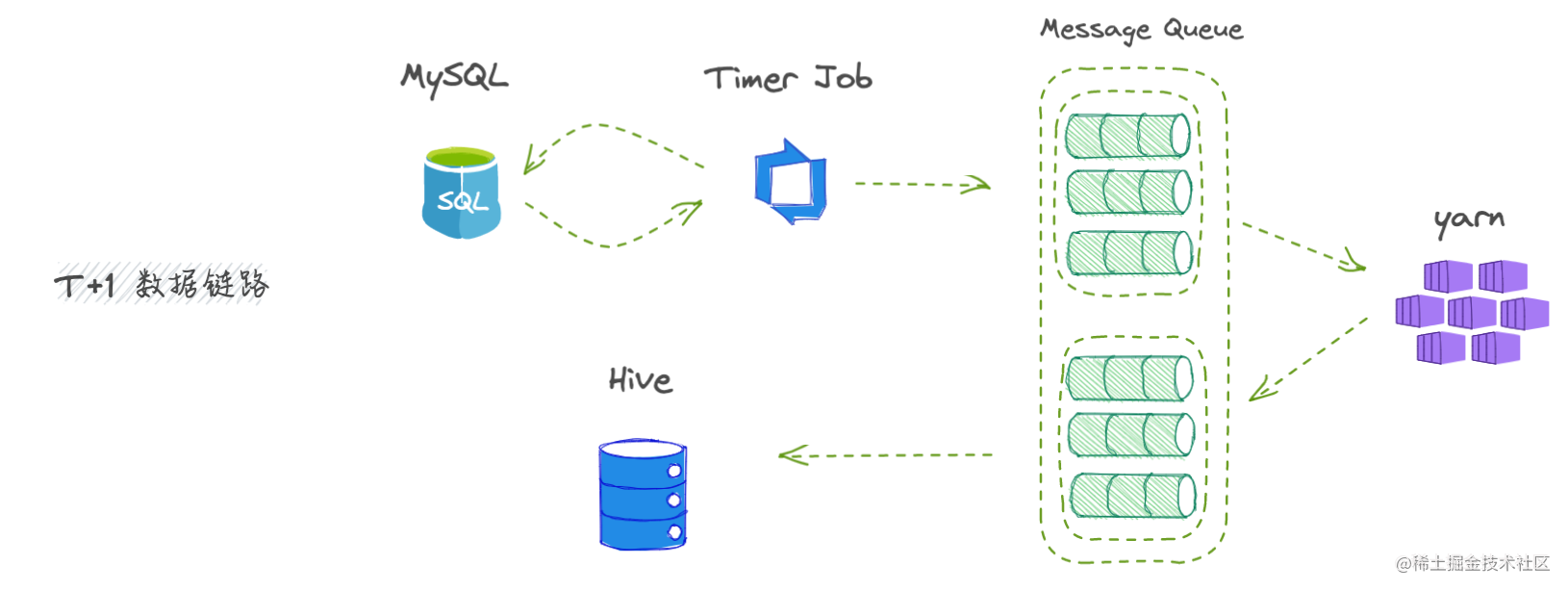
在OLAP场景下,大部分对于实时性要求不高,基于成本考虑,默认提供T+1数据来进行展示或进行分析结果输出。
这部分数据会通过定时任务每天凌晨业务低峰时段进行迁移、计算、处理等。这样做的好处是不会影响业务高峰期间系统的稳定性,且多一个+1时间跨度有充分的容错机会、空间来做好工作任务。
打造实时数据体验
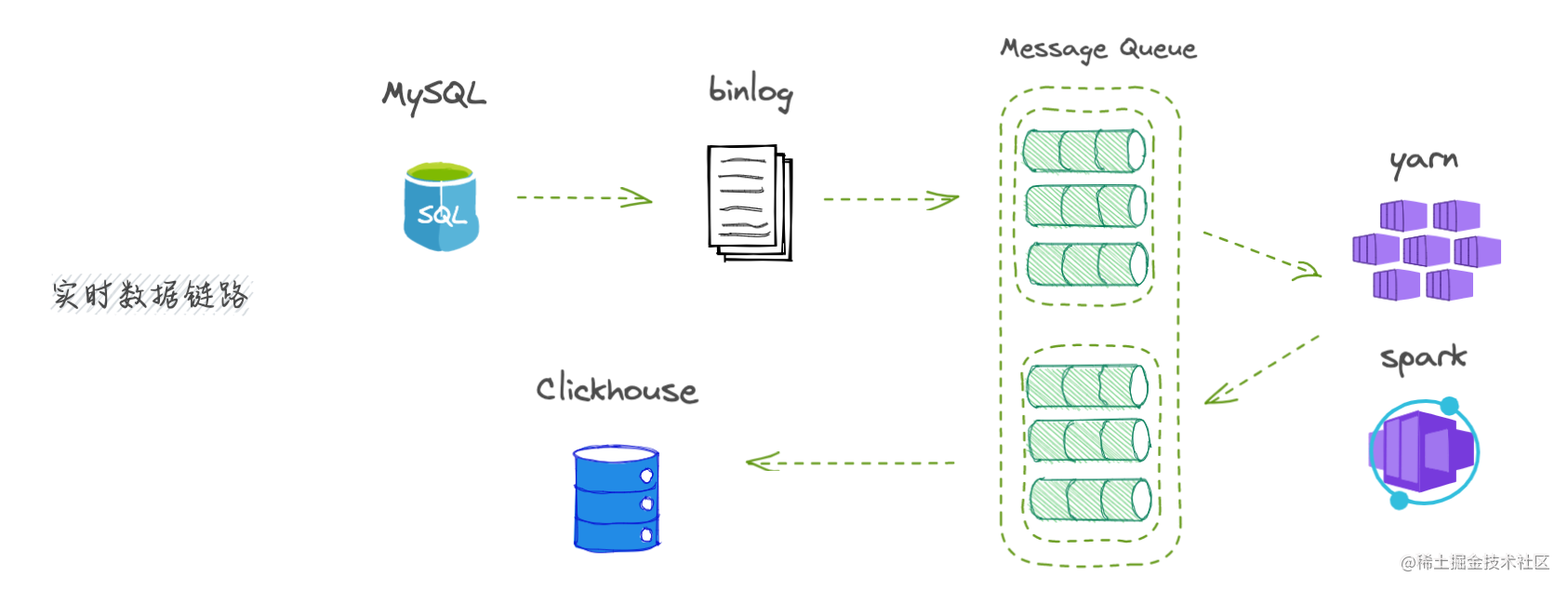
准确来说,是准实时的数据体验,因为对于数据仓库而言都是需要借助数据通道(消息队列)来进行数据传递完成数据更新的。
常用方案是数据仓库监听MySQL数据库的binlog日志,binlog日志是数据库数据操作的全部记录,解析该日志转换为消息投递到消息队列,在消息队列另一端读取数据进行数仓目标数据源的写入和更新即可。
极致的体验必然伴随成本和大量资源投入,特别是面对海量数据更新和持续性更新时,需要借助yarn、spark等进行准实时数据处理、计算,将数据实时化成呈现在体验界面。
🏄🏄🏄 以上便是本章的全部内容,如果觉得有所收获,欢迎 『点赞』、『收藏』、『关注』 一键三连支持喔~