目录
1.什么是语义分割
2.语义分割常见的数据集格式
3.常见的语义分割评价指标
4.转置卷积
1.什么是语义分割
常见分割任务:语义分割、实例分割、全景分割

图一 原始图片 
图二 语义分割 
图三 实例分割 语义分割(例如FCN网络)可以理解为一个分类任务,对每个像素进行分类。
实例分割(例如Mask R-CNN网络)更精细一些,对于同一个类别的不同目标我们也用不同颜色来分割。
全景分割(例如Panoptic FPN网络):语义分割 + 实例分割。
2.语义分割常见的数据集格式
PASCAL VOC(PNG 图片):是单通道的图像,利用调色板模式。
详见博文:
PASCAL VOC数据集介绍
https://blog.csdn.net/qq_37541097/article/details/115787033
MS COCO数据集介绍:
MS COCO数据集介绍



3.常见的语义分割评价指标
Pixel Accuracy是:分子预测图像标签上所有预测正确的像素个数的总和,其分母是图像的总像素个数。
mean Accuracy:每个类别被预测正确的像素总个数/目标像素类别
的总个数。
mean IoU:每个类别的IoU,再对每个类别求平均。
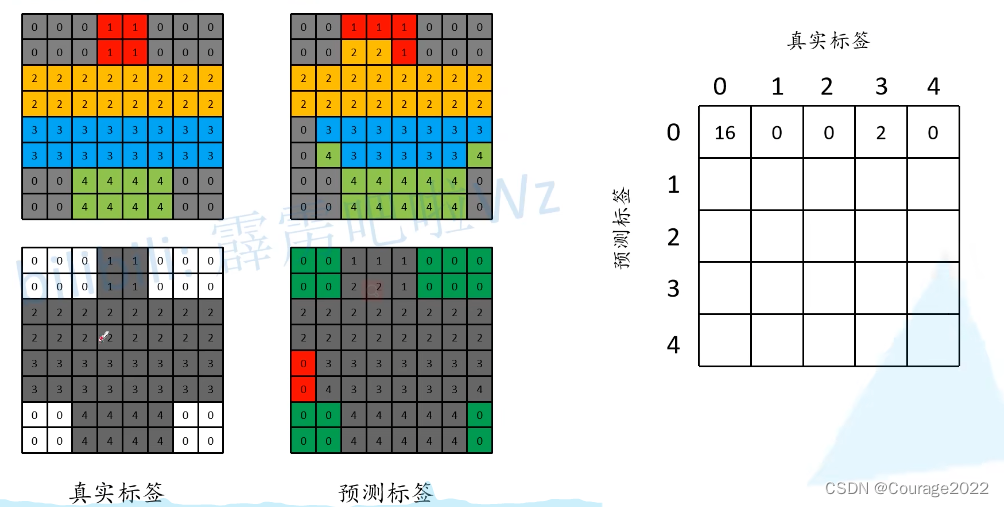
举一个例子:
对于0标签:
我们将预测正确的地方用绿色表示,预测错误的地方用红色表示。
绿色表示预测标签为0,实际标签也为0。图中有16个。
红色表示预测错误的,即预测为0,实际标签不为0。实际标签为1的为0个,实际标签为3的有两个.....。构建上图矩阵。最后混淆矩阵如下:
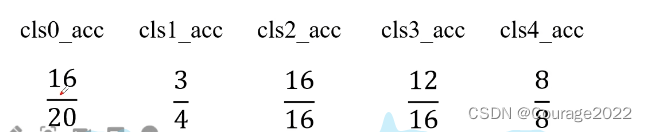
那么我们的global_accuracy:
针对每个类别的accuracy:
mean_IoU:




4.转置卷积
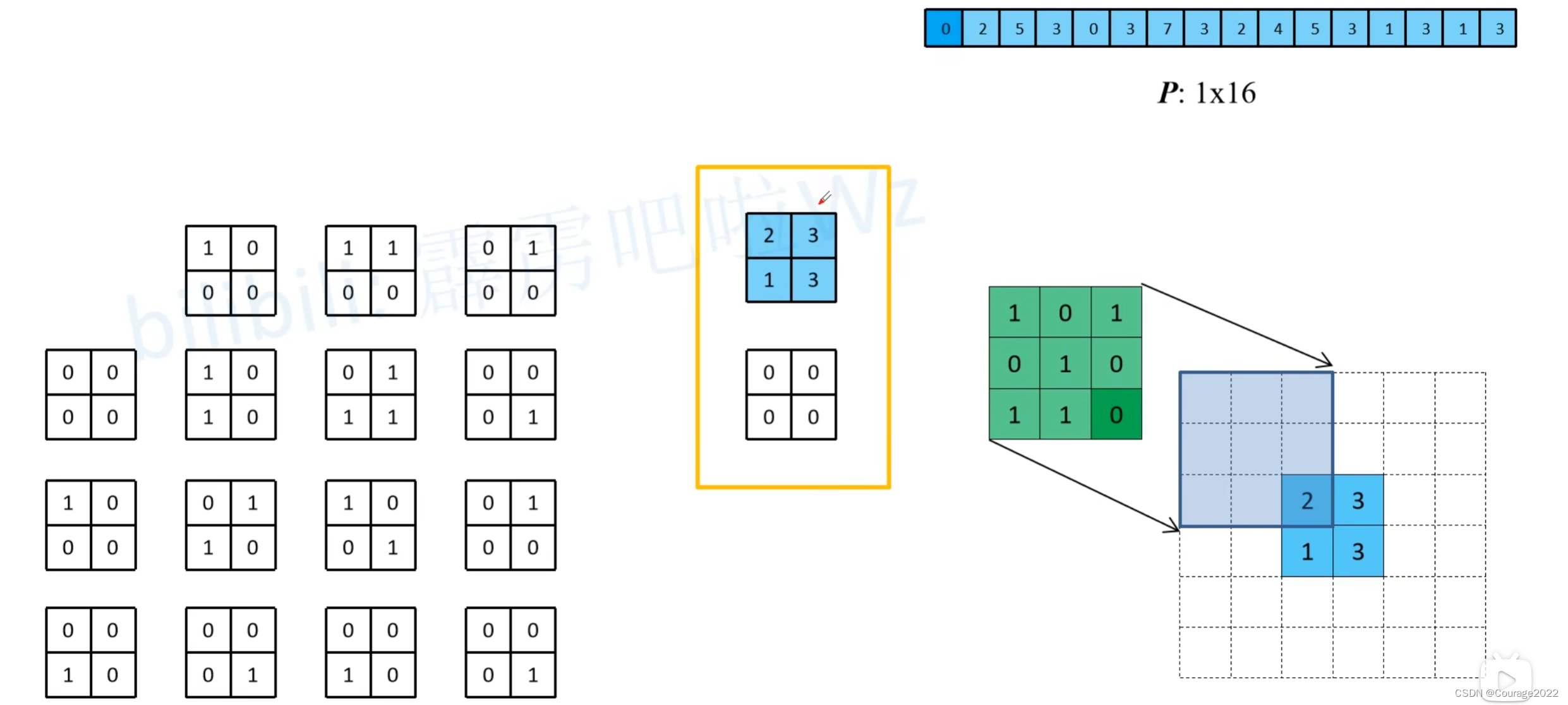
起到下采样的作用。如右图:输入的特征层是
的,我们通过零填充再使用转置卷积,现在的输出特征层是
的。
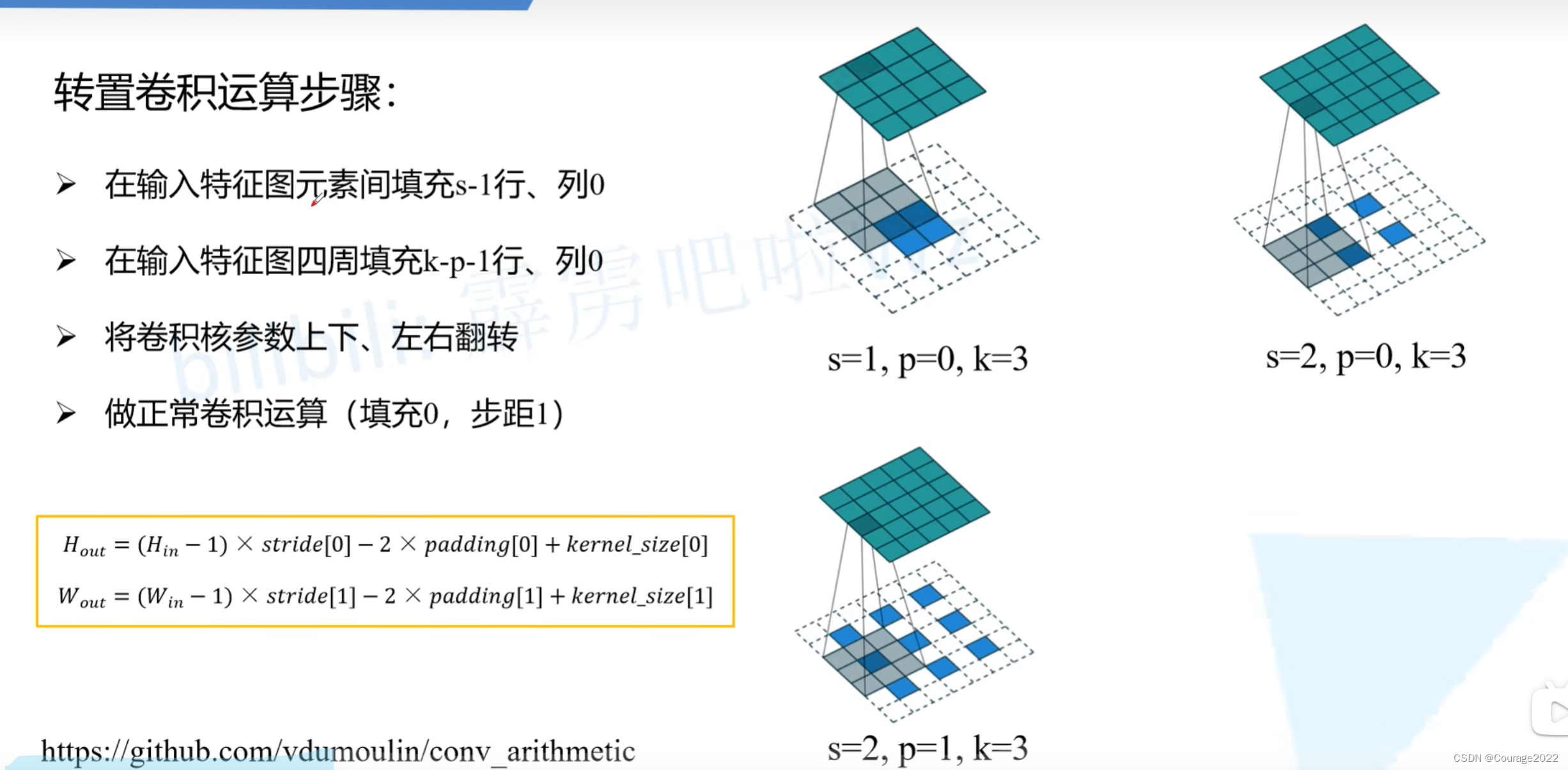
转置卷积的步骤如下:
第一步:这里的
是指步长stride,这里步长为1,1-1=0。我们就不需要在特征图中填充0了。第二幅图中我们的步长stride为2,2-1=1,我们需要在特征图元素间填充1行,图三同理。
第二步:这里的
是指内边距padding,对于图一,k-p-1=3-0-1=2,在周围填充2行2列0;对于图三,k-p-1=3-1-1=1,在周围填充1行1列0。
对于输出特征层的宽度和高度:
我们以一个实例进行讲解:
这里我们输入的特征图(feature map)是
根据第一步:我们无需在元素间填充元素。
根据第二步:在输入
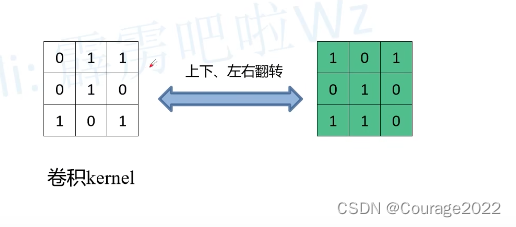
第三步:对kernel进行上下左右翻转,如中间的图,最后我们通过卷积得到了一个
现在我们对转置卷积的做法有了一定的了解,但我们为什么要这么做呢?
看一下pytorch官方给的关于转置卷积的参数们。
普通卷积的计算中,计算如下:
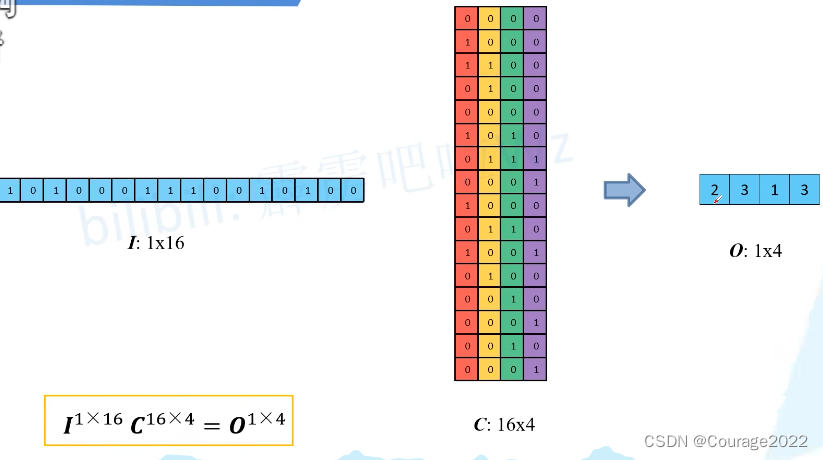
在pytorch官方实现中,我们构建卷积核的等效矩阵。
将输入的特征图(feature map)进行展平,将等效矩阵也进行展平,即进行一个向量化:
最后得到输出的特征矩阵:
那么这里我们提出一个问题:已知矩阵
和矩阵
,能否求得矩阵
。换句话说,即卷积是否可逆?
如果是通过逆矩阵计算的话是不可行的,因为只有方阵才有逆矩阵。即一般的卷积是不可逆的。
那么我们放宽下条件,我们要得到与原始输入矩阵
的矩阵,很明显是可以的,只要乘以
即可,如下图:
这就是转置卷积的计算过程,我们通过
的特征层得到了一个
我们接着来看一个有趣的现象:
我们拿等效矩阵进行对应元素相乘相加:


















![[ AWS - SAA ] 解决方案架构师之设计弹性架构 - 选择可靠的弹性存储(如何选择 SSD vs. HDD)](https://img-blog.csdnimg.cn/b7d116aa30614ab280ba8eadefd1d8f4.png)