在初期,已经讲述了Redis安装问题。现在正式进入Redis的入门阶段。
Redis客户端
命令行客户端
redis-cli [options] [commands]
常用到的 options 有:
-h 127.0.0.1: 指定要连接的Redis的IP地址【默认127.0.0.1】-p 6379: 指定连接Redis的端口【默认6379】-a 123456: 输入Redis的链接密码
commands 就是操作 Redis 的命令
ping: 与 Redis 服务端做心跳测试,服务端会正常返回PONG
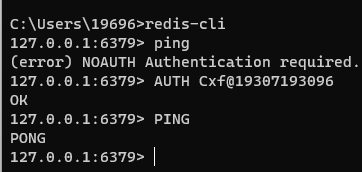
设置了密码之后就需要通过密码验证才能使用redis命令行客户端
图形化界面客户端
用的是csdn的github加速计划,所以不用担心无法访问问题
Win免费下载使用Resp.app
Mac需要付费订阅下载Resp,app
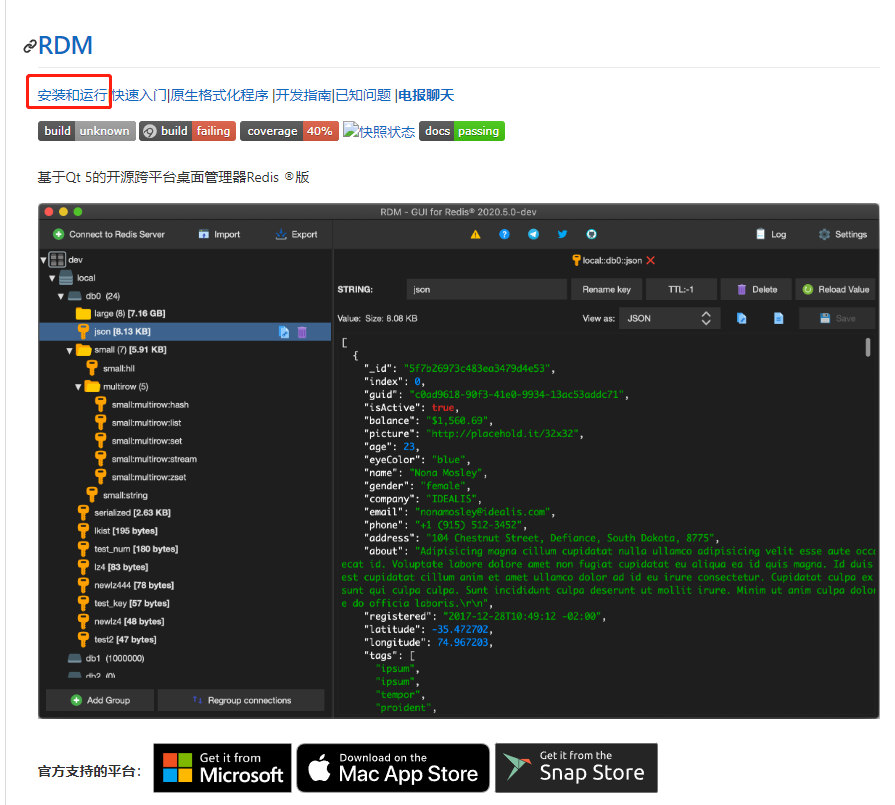

Redis常用基础命令
常用命令不需要记忆,需要的时候查询手册即可
Redis通用命令
通用的命令常见的有
- KEYS:查看符合模板的所有key
- DEL:删除一个指定的key
- EXISTS:判断key是否存在
- EXPIRE:给一个key设置有效期,有效期到期时该key会被自动删除
- TTL:查看一个KEY的剩余有效期
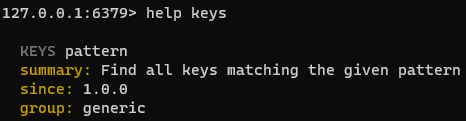
通过 help 命令帮助这些命令的使用
String类型
String字符串是Redis最简单的存储类型。
根据字符串格式不同,可以分为3类
- String:普通字符串
- int:整形,可自增、自减操作
- float:整形,可自增、自减操作
不管是哪种格式,底层都是字节数组形式存储,只不过是编码方式不同。字符串类型的最大空间不能超过512MB
| KEY | VALUE |
|---|---|
| name | 张三 |
| num | 1 |
| price | 1.1 |
常用语法
| 语法 | 含义 |
|---|---|
| SET | 添加/修改 已经存在的一个String 类型的键值对 |
| GET | 根据 KEY 获取 VALUE |
| MSET | 批量添加多个 String 类型键值对 |
| MGET | 根据多个 KEY 获取多个 String 类型的 VALUE |
| INCR | 让一个整形的 KEY 自增/自减 |
| INCRBY | 让一个整形的 KEY 自增指定大小【INCRBY num -2:num -= 2】 |
| INCRBYFLOAT | 让一个浮点型数据自增 |
| SETNX | 添加一个 String 类型键值对,前提是这个 KEY 不存在,否则不执行 |
| SETEX | 添加一个 String 类型键值对,并且指定有效期 |
KEY 结构
Redis没有MySQL中Table表的概念。如何区分不同类型的 KEY 呢?
比如存储一个ID都为1的用户数据和文章数据,那么 SET ID 1 就会冲突。解决方案是:多个单词之间用 : 分隔开,格式如下:
项目名:业务名:类型:id
user相关的key:BlogSystem:user:1
文章相关的key:BlogSystem:article:1
如果VALUE是一个对象,则可以将对象序列化为JSON字符串后存储
| KEY | VALUE |
|---|---|
| BlogSystem:user:1 | {“id”:1, “name”: “张三”, “age”:13} |
| BlogSystem:article:1 | “id”:1, “title”: “Redis快速入门”, “updateTime”: “2022-12-23” |

Hash类型
String结构将对象序列化为JSON格式存储后,当需要修改某个字段是很不方便。
Hash结构可以将对象字段单独存储,方便修改
| KEY | FILED | VALUE |
|---|---|---|
| BlogSystem:user:1 | name | “张三” |
| BlogSystem:user:1 | age | 13 |
| BlogSystem:user:2 | name | “李四” |
| BlogSystem:user:2 | age | 14 |
Hash常用语法
| 语法 | 含义 |
|---|---|
| HSET key field value | 添加或者修改hash类型key的field的值 |
| HGET key field | 获取一个hash类型key的value |
| HMSET | 批量添加多个hash类型key的field的值 |
| HMGET | 批量获取多个hash类型key的field的值 |
| HGETALL | 获取一个hash类型的key中的所有的field和value |
| HKEYS | 获取一个hash类型的key中所有的field |
| HINCRBY | 让一个hash类型key的value自增指定步长 |
| HSETNX | 添加一个hash类型的key的field之,前提是这个field不存在否则不执行 |
List类型
Redis中的List类型与Java中的LinkedList类似,可以看作是一个双向链表结构。既可以支持正向检索也支持反向检索。
特征与LinkedList类似:
- 有序
- 元素可以重复
- 插入和删除快
- 查询一般
用来存储一个有序数据。例如:朋友圈点赞列表,评论列表
常用语法
| 语法 | 含义 |
|---|---|
| LPUSH key element | 在列表左侧插入一个或多个元素 |
| RPUSH key element | 向列表右侧插入一个或多个元素 |
| LPOP key | 移除并返回列表左侧的第一个元素,没有则返回nil |
| RPOP key | 移除并返回列表右侧的第一个元素,没有则返回nil |
| BLPOP和BRPOP | 与LPOP和RPOP类似,只不过在没有元素时等待指定时间而不是直接返回nil |
| LRANGE key star end | 返回一段表范围内的所有元素【0下标开始计算】 |
Set类型
Redis的Set结构与Java中的HashSet类似,可以看作是一个value为null的HashMap。
- 无序
- 不可重复
- 查找快
- 支持交并补查询
Set常用语法
| 语法 | 含义 |
|---|---|
| SADD key member | 向set中添加一个或多个元素 |
| SREM key element | 移除set中的指定元素 |
| SCARD key | 返回set中元素的个数 |
| SISMEMBER key member | 判断一个元素是否存在于set中 |
| SMEMBERS | 获取set中所有元素 |
| SINTER key1 key2 | key1 和 key2 交集 |
| SDIFF key1 key2 | key1 和 key2 差集集 |
SortedSet类型
Redis的SortedSet是一个可排序的Set集合。与Java中的TreeSet类似,但底层数据结构差异很大。SortedSet中的每个元素都带有score属性,可以基于score属性对元素排序,底层是一个调表(SkipList)+Hash表
- 可排序
- 不可重复
- 查询快
因为SortedSet可排序特性,经常用来实现排行榜这样的功能
SortedSet常用语法
| 语法 | 含义 |
|---|---|
| ZADD key score member | 添加一个或多个元素到SortedSet,如果已经存在则更新其score值 |
| ZREM key member | 删除SortedSet中指定元素的score值 |
| ZSCORE key member | 获取SortedSet中指定元素的score值 |
| ZRANK key member | 获取SortedSet中指定元素排名【升序】 |
| ZREVRANK key member | 获取SortedSet中指定元素排名【降序】 |
| ZCOUNT key min max | 统计score值在给定范围内的所有元素的个数 |
| ZINCRBY key increment member | 让SortedSet中指定元素自增,步长为指定的increment值 |
| ZRANGE key min max | 按照score排序后,获取指定排名范围内的元素 |
| ZRANGEBYSCORE key min max | 按照score排序后,获取指定score范围内的元素 |
| ZINTER,ZUNION,ZDIFF | 交并差 |
Redis的Java客户端
Jedis快速入门
- Jedis和Lettuce:这两个主要是提供了Redis命令对应的API,方便操作Redis。而SpringDataRedis又针对这两种做了抽象和封装
- Jedis:语法和Redis类似,优点是使用快捷缺点是多线程环境下会出现不安全
- Lettuce:依靠opsForXxx进行操作Redis数据库,可解决多线程不安全情况
- Redisson:是在Redis基础上实现了分布式的可伸缩的Java数据结构。例如Map、Queue等。而且支持跨进程的同步机制:Lock、Semaphore等待,比较适合用来实现特殊功能需求
创建一个Maven项目,引入需要的依赖
Jedis官网
<!-- redis依赖 -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>4.3.1</version>
</dependency>
<!-- 测试依赖 -->
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter</artifactId>
<version>5.9.1</version>
<scope>test</scope>
</dependency>
一个redis小测试
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import redis.clients.jedis.Jedis;
import java.util.Map;
public class JedisTest {
private Jedis jedis;
@BeforeEach
void setUp() {
// 1.建立连接
jedis = new Jedis("127.0.0.1", 6379);
// jedis = JedisConnectionFactory.getJedis();
// 2.设置密码
jedis.auth("123456");
// 3.选择数据库
jedis.select(0);
}
@AfterEach
void close() {
if (jedis != null) {
jedis.close();
}
}
@Test
void testString() {
// 存数据
String result = jedis.set("name", "张三");
System.out.println("result = " + result);
// 取数据
String name = jedis.get("name");
System.out.println("name = " + name);
}
@Test
void testHash() {
jedis.hset("user:1", "name", "张三");
jedis.hset("user:1", "age", "13");
jedis.hset("user:1", "sex", "male");
Map<String, String> map = jedis.hgetAll("user:1");
System.out.println(map);
}
}
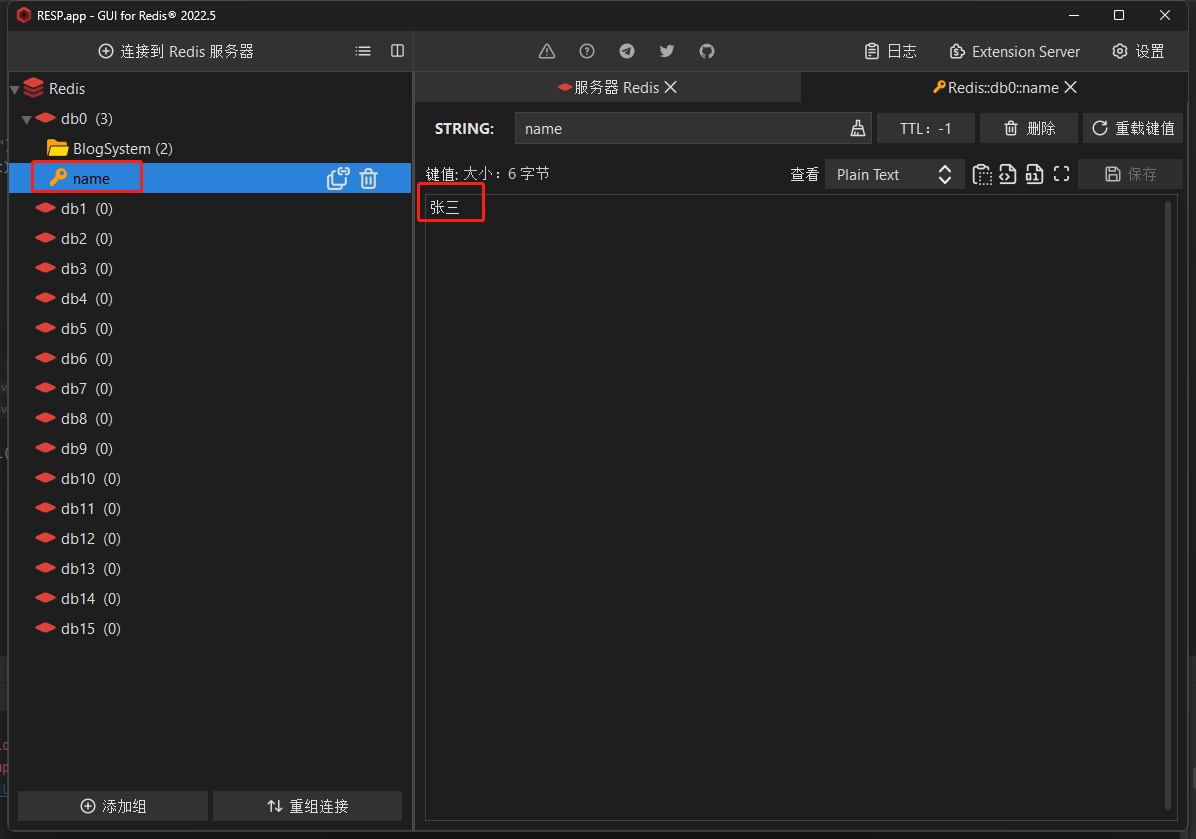
打开客户端可以看到已经成功插入String和Hash类型的数据
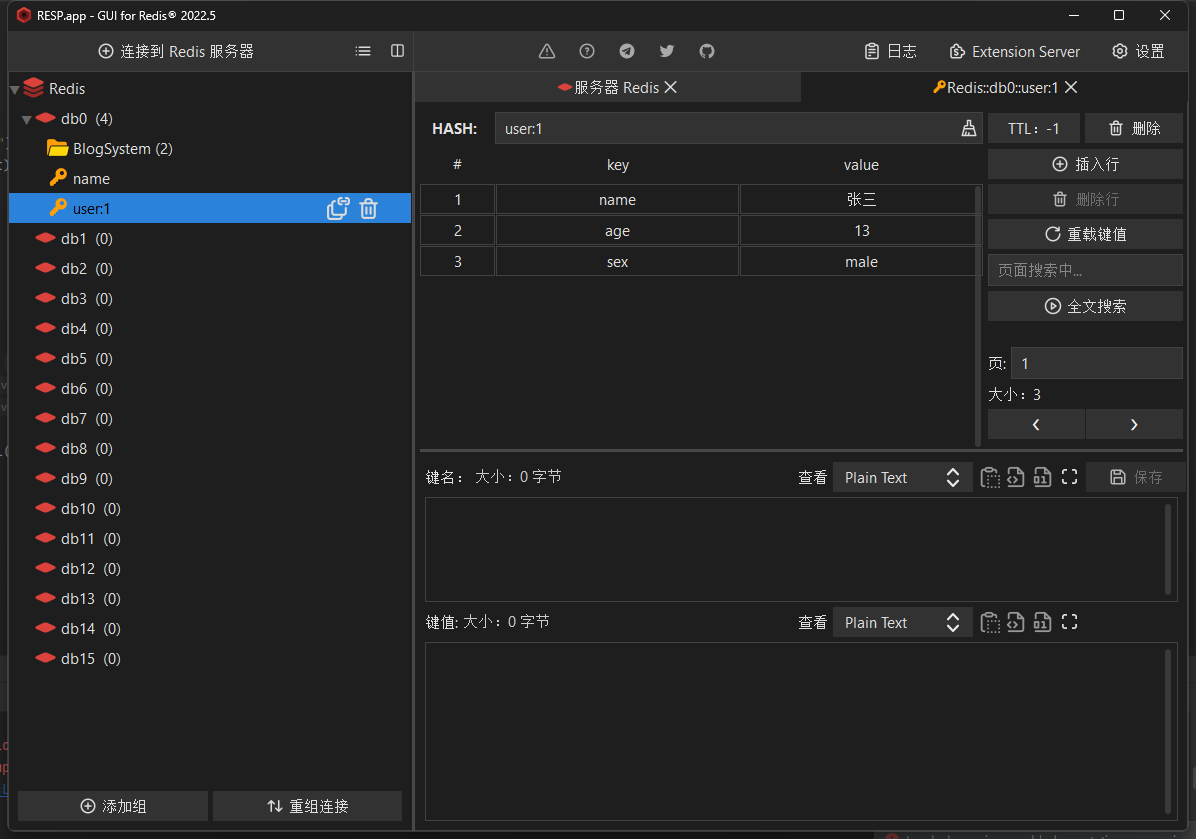
由于经常的断开连接,建立连接会有消耗。所以以创建一个连接池
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
public class JedisConnectionFactory {
private static final JedisPool jedisPool;
static {
// 配置连接池
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
// 最大连接数
jedisPoolConfig.setMaxTotal(10);
// 最大空闲连接
jedisPoolConfig.setMaxIdle(10);
// 最小空闲连接
jedisPoolConfig.setMinIdle(0);
// 等待空闲时间[ms]
jedisPoolConfig.setMaxWaitMillis(100);
// 创建连接池对象,参数:连接池配置,服务端IP,服务端接口,超时时间,密码
jedisPool = new JedisPool(jedisPoolConfig, "127.0.0.1", 6379, 100, "123456");
}
public static Jedis getJedis() {
return jedisPool.getResource();
}
}
SpringDataRedis客户端
SpringDataRedis官网简介
可以看到Redis的支持

创建一个Spring项目,添加如下依赖
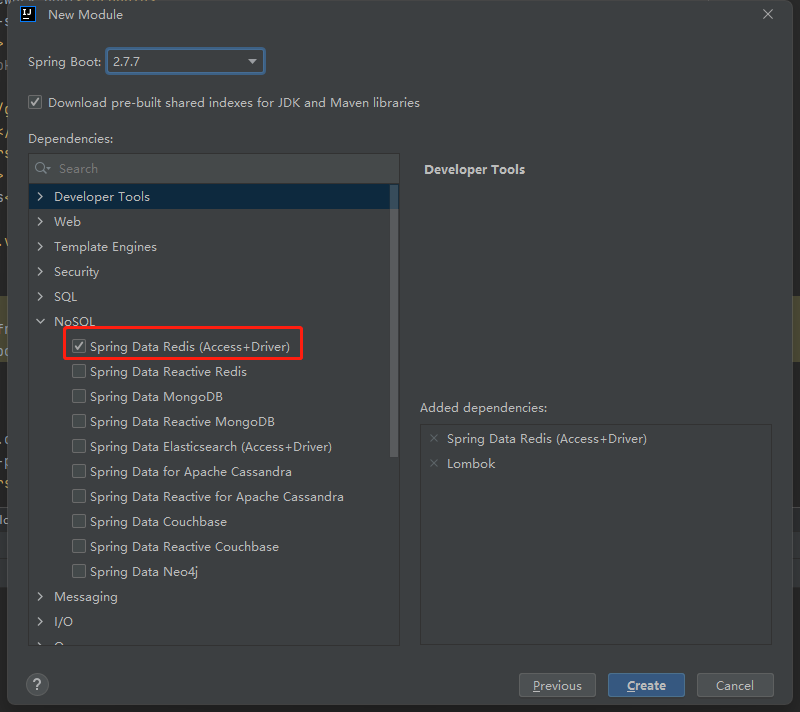
yml配置如下
spring:
redis:
host: 127.0.0.1
port: 6379
password: Cxf@19307193096
lettuce:
pool:
max-active: 8 #最大连接数
max-idle: 8 #最大空闲连接
min-idle: 0 #最小空闲连接
max-wait: 1000ms #超时时间
测试代码如下
package app;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.RedisTemplate;
@SpringBootTest
class TestRedisTemplate {
private RedisTemplate redisTemplate;
@Autowired
public TestRedisTemplate(RedisTemplate redisTemplate) {
this.redisTemplate = redisTemplate;
}
@Test
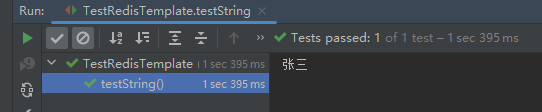
public void testString() {
// 写入一条 String 数据
redisTemplate.opsForValue().set("name", "张三");
// 获取一条 String 数据
Object name = redisTemplate.opsForValue().get("name");
System.out.println(name);
}
}

会发现已经是乱码,可读性很差,因此需要用到Redis的序列化。那么问题出现在哪儿呢?我们顺着RedisTemplate 部分源码阅读一下
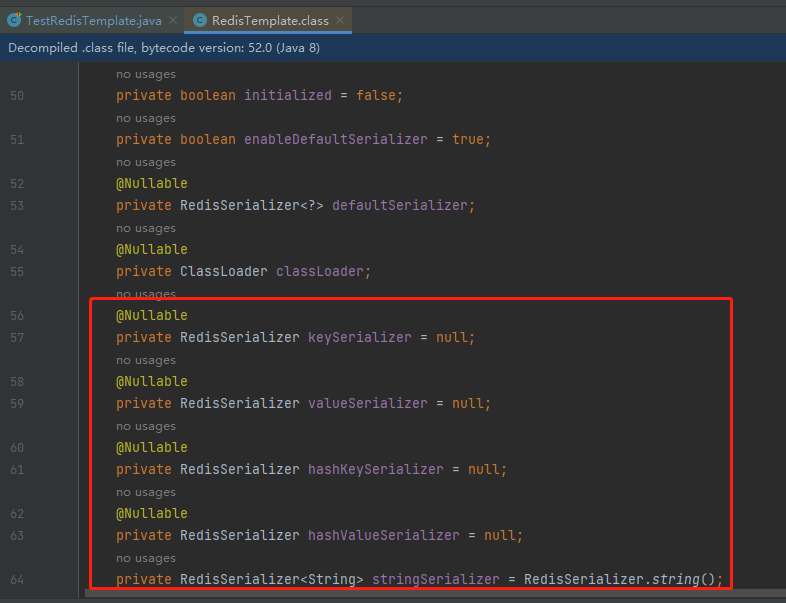
主要是 key和value 的序列化。redis中key一般用的都是字符串类型,因此使用的是String类型的序列化
程序会先通过 afterPropertiesSet 确定序列化方式
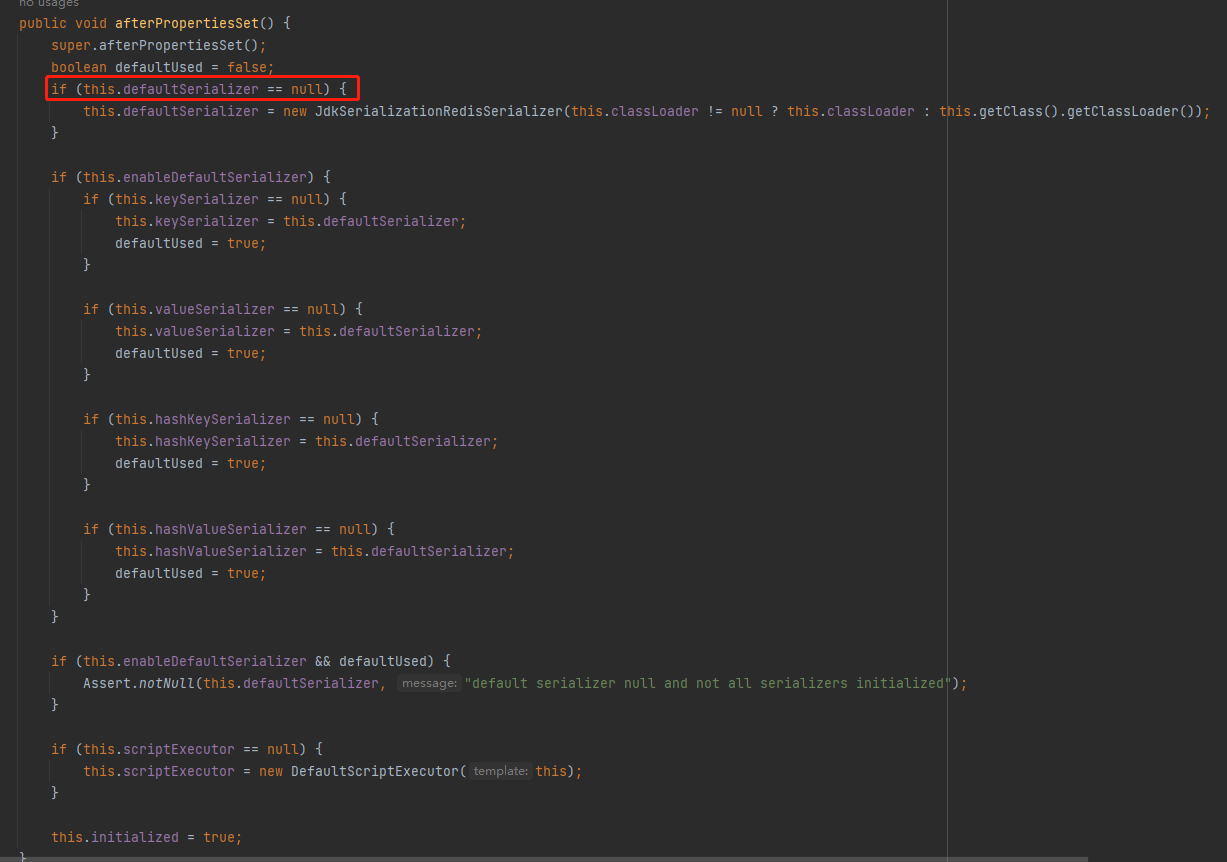
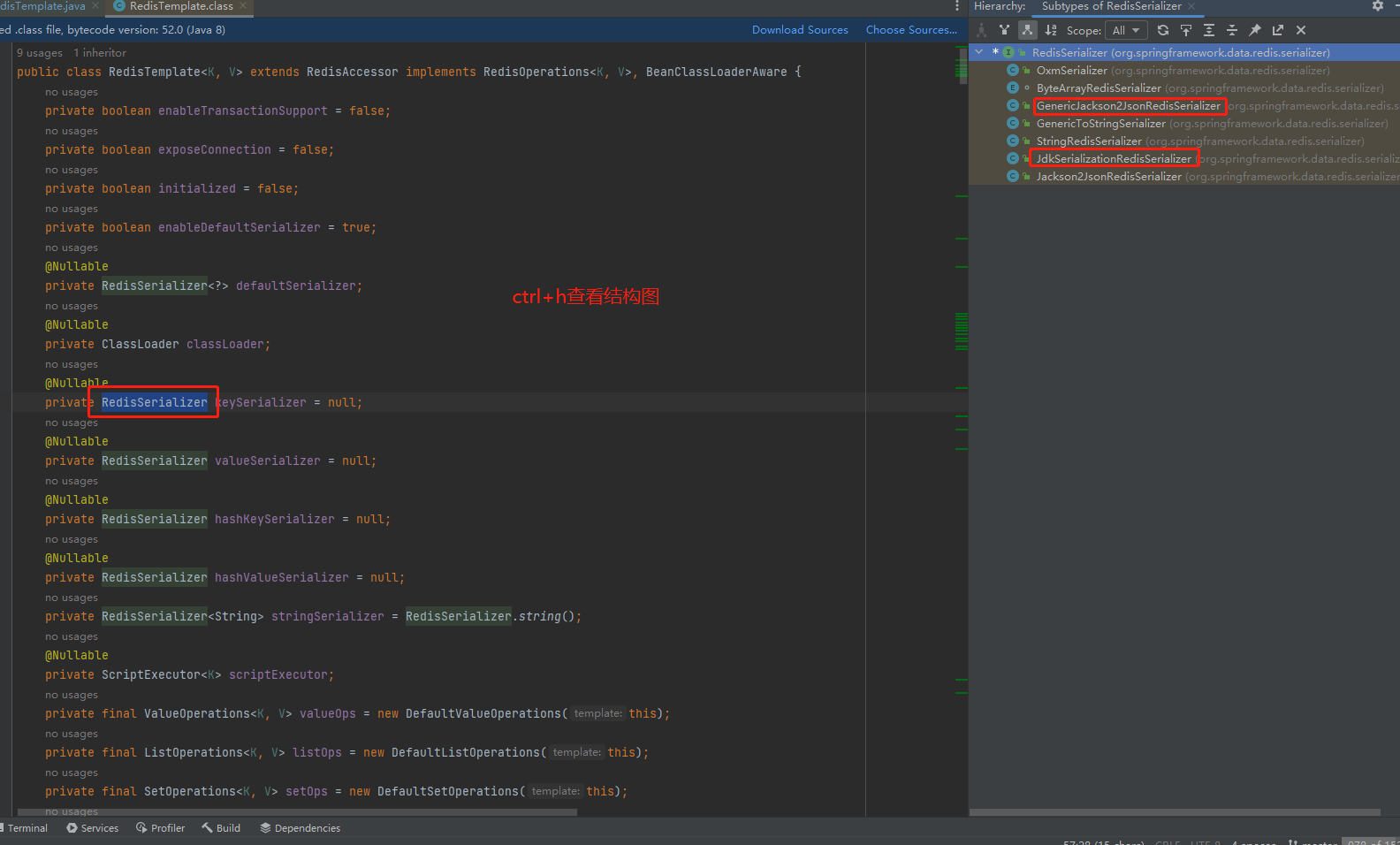
查看默认的 defaultSerializer 的属性如下所示,是一个 null 。所以会使用默认的 JDK序列化工具
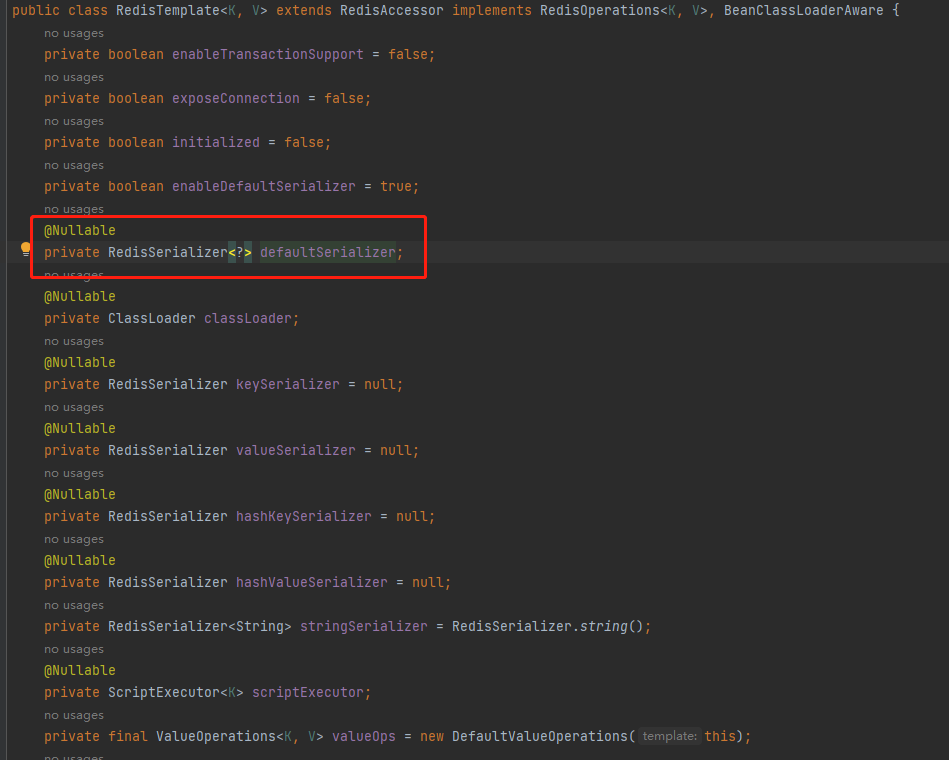
我们再看 this.defaultSerializer = new JdkSerializationRedisSerializer(this.classLoader != null ? this.classLoader : this.getClass().getClassLoader()); 方法
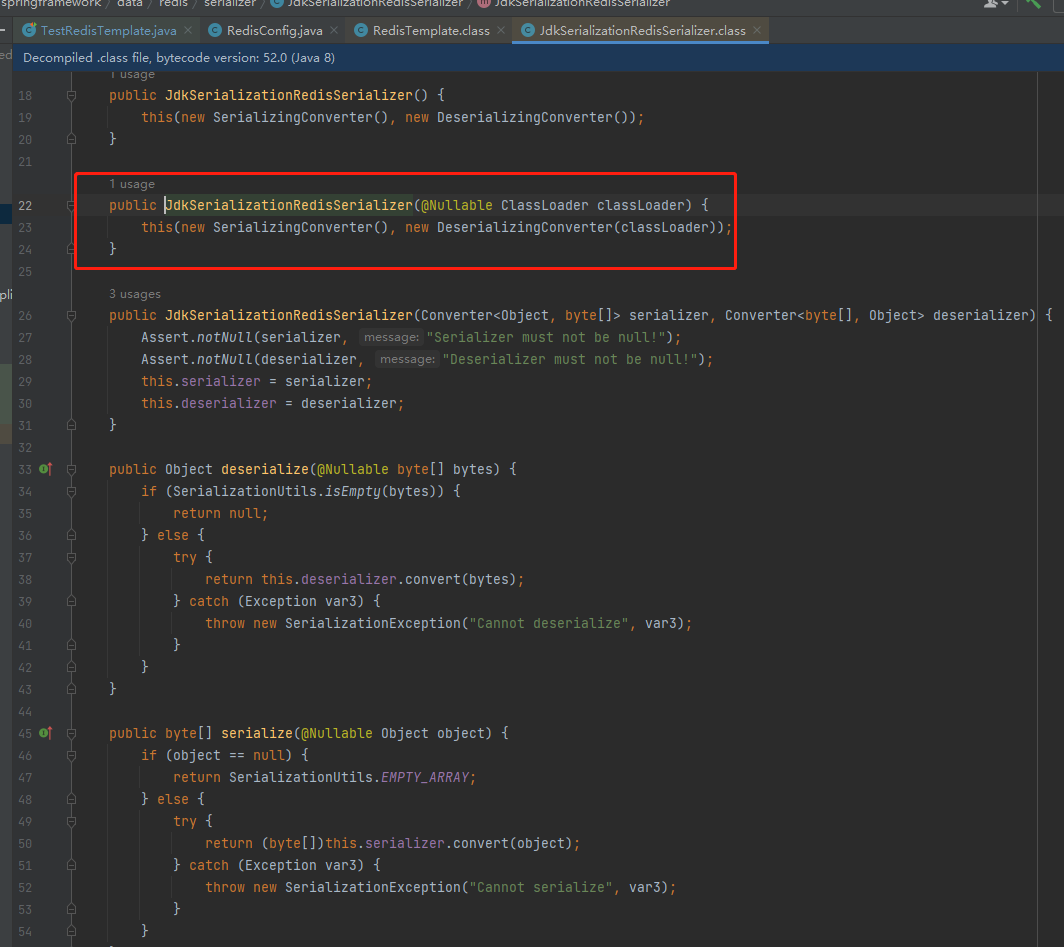
再看 (new SerializingConverter() 代码
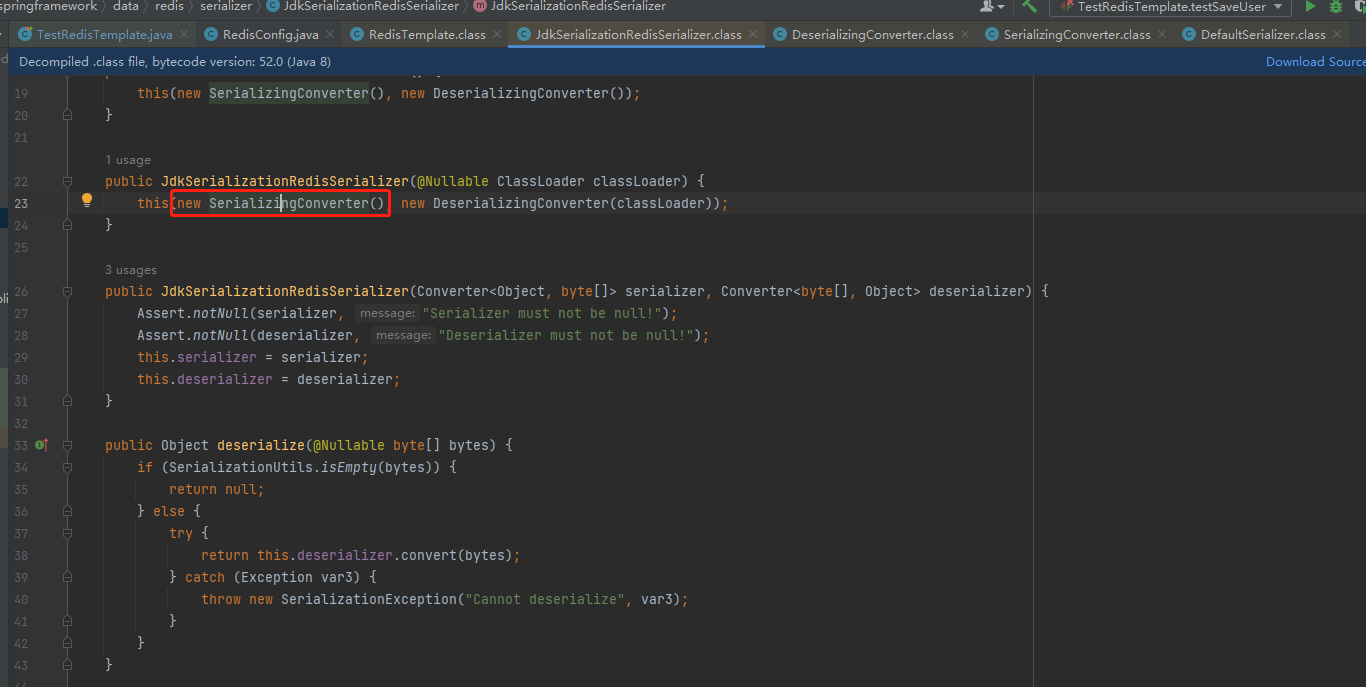
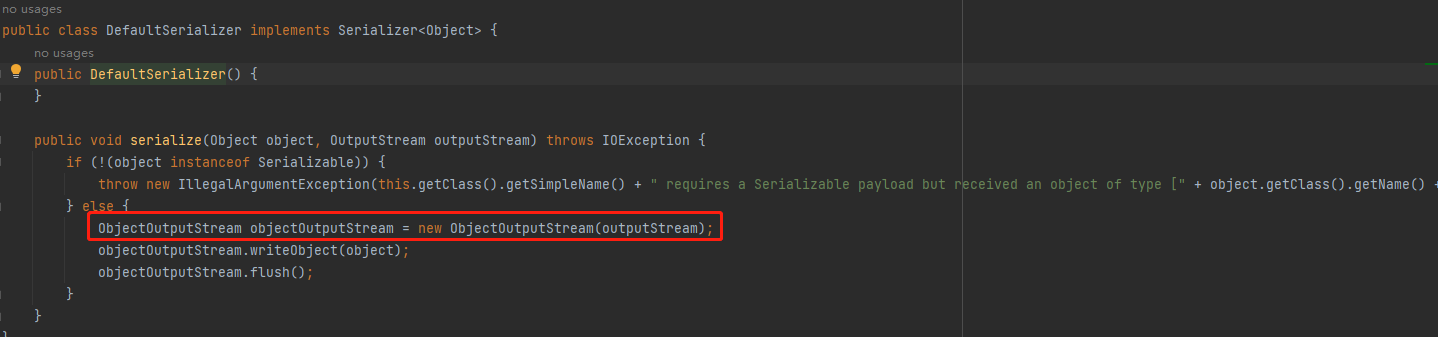
再看 new DefaultSerializer() 代码
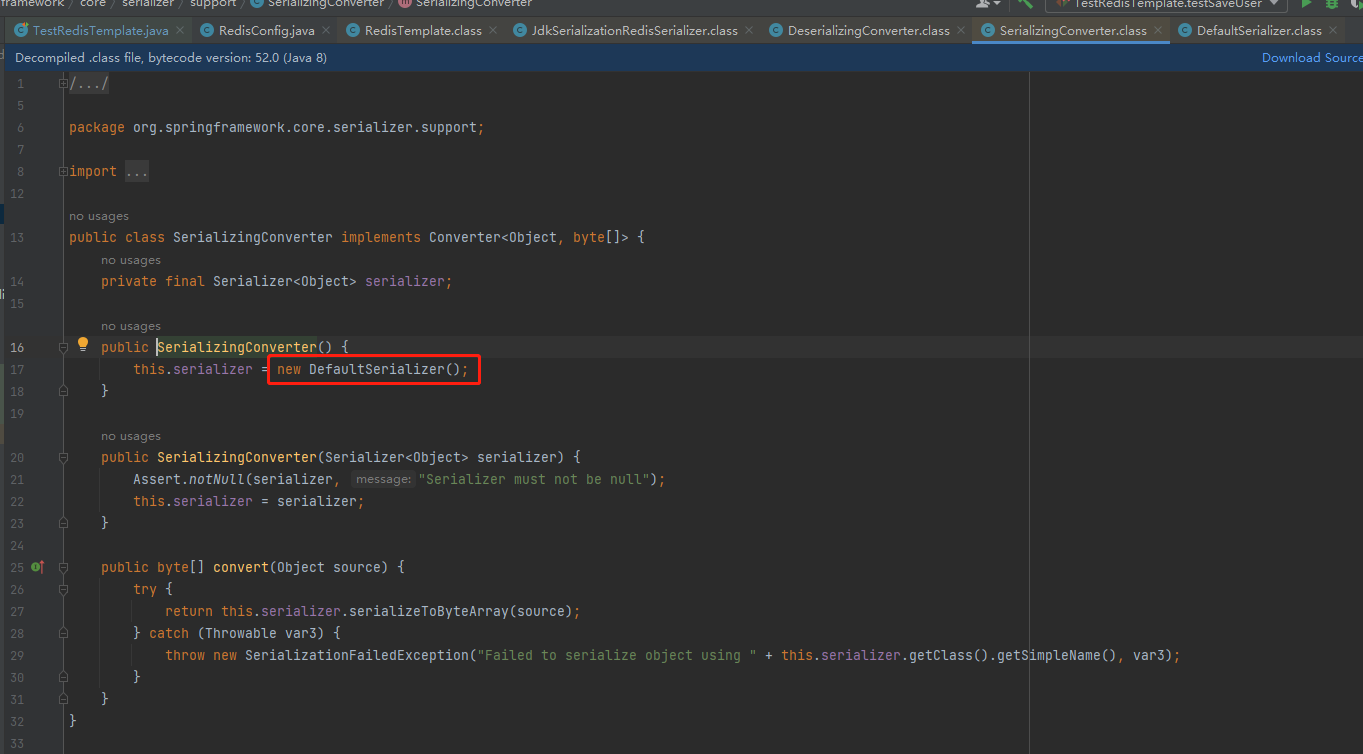
再看 serialize() 用的是 ObjectOutPutStream 序列化
上面了解了 JDK的序列化方式,SpringDataRedis集成了众多序列化工具,默认使用的是JDK序列化方式,对于普通对象而言使用则会出现一定乱码问题,SpringDataRedis更推荐使用大名鼎鼎的 Jackson 进行对对象序列化
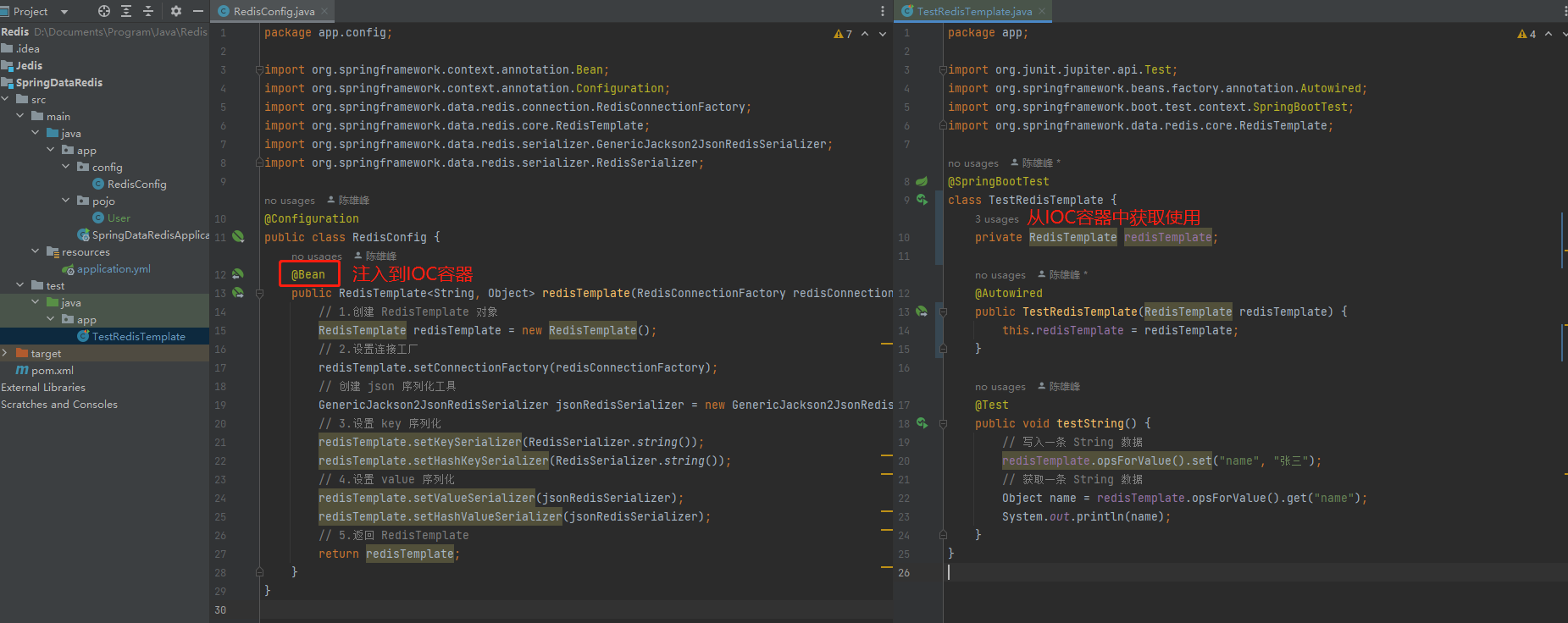
自定义 Redis 的序列化器
package app.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.RedisSerializer;
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
// 1.创建 RedisTemplate 对象
RedisTemplate redisTemplate = new RedisTemplate();
// 2.设置连接工厂
redisTemplate.setConnectionFactory(redisConnectionFactory);
// 创建 json 序列化工具
GenericJackson2JsonRedisSerializer jsonRedisSerializer = new GenericJackson2JsonRedisSerializer();
// 3.设置 key 序列化
redisTemplate.setKeySerializer(RedisSerializer.string());
redisTemplate.setHashKeySerializer(RedisSerializer.string());
// 4.设置 value 序列化
redisTemplate.setValueSerializer(jsonRedisSerializer);
redisTemplate.setHashValueSerializer(jsonRedisSerializer);
// 5.返回 RedisTemplate
return redisTemplate;
}
}
测试结果如下所示
我们再测试一下对象的存储结果
再去redis数据库中查看
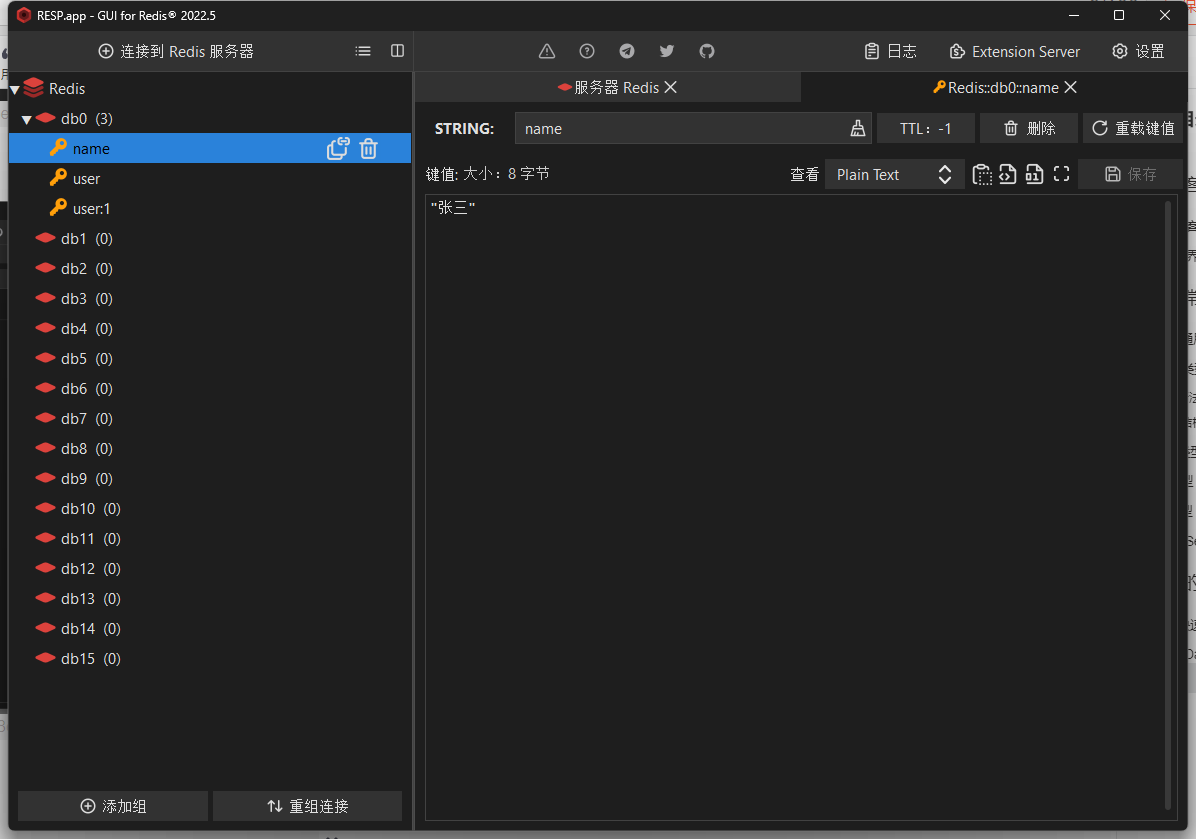
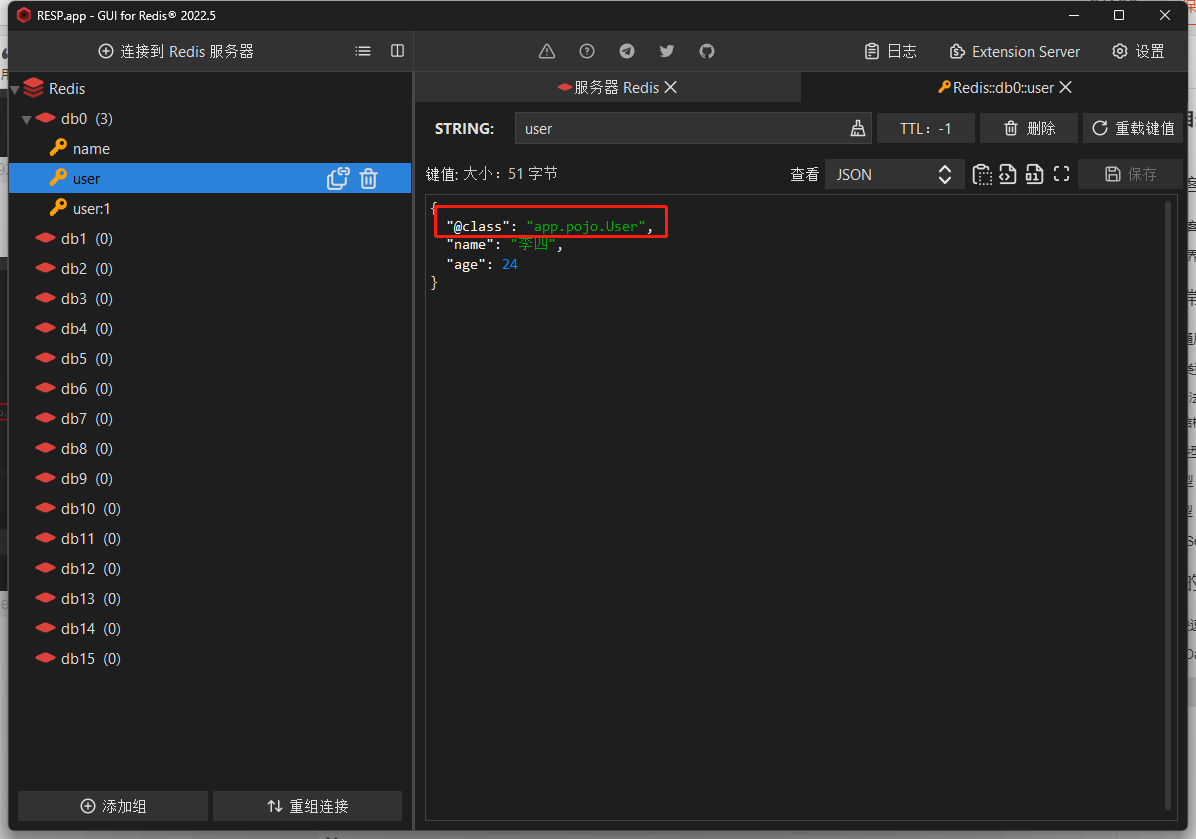
说明:对于普通字符串 “张三” 直接按照String类型存入到了redis中;而对于 User 对象则被 Jackson 序列化为了为了 json 类型的数据,为了能够方便通过 json 数据返回序列化出 User 对象还会多存入一条属性 "@class": "app.pojo.User"。然而这样虽然反序列化方便了,但是数据量堆叠起来之后会给redis带了额外的内存开销
StringRedisTemplate 使用String序列化器
因此为了节省内存,一般并不会使用JSON序列化器,而是统一使用String序列化器,要求之存储String类型的key和value。当需要的时候在手动序列化或反序列化。

主要利用jackson的 ObjectMapper 类来实现手动的序列化和反序列化而不是通过Redis自带的JSON序列化工具
读写String
package app;
import app.pojo.User;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.StringRedisTemplate;
@SpringBootTest
public class TestStringRedisTemplate {
private StringRedisTemplate stringRedisTemplate;
private static final ObjectMapper mapper = new ObjectMapper();
@Autowired
public TestStringRedisTemplate(StringRedisTemplate stringRedisTemplate) {
this.stringRedisTemplate = stringRedisTemplate;
}
@Test
public void testString() {
// 写入 String 数据
stringRedisTemplate.opsForValue().set("name", "张三");
// 读取 String 数据
String name = stringRedisTemplate.opsForValue().get("name");
System.out.println(name);
}
@Test
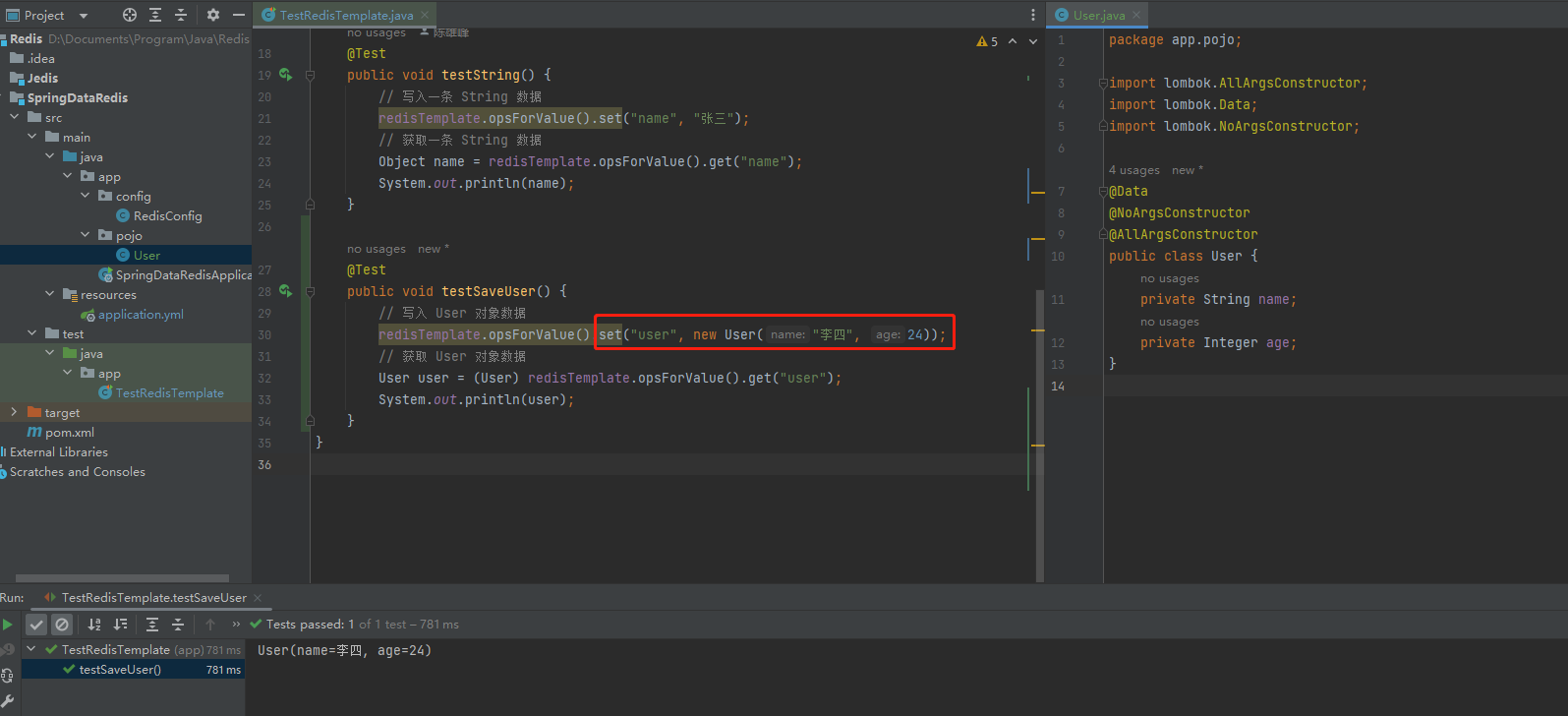
public void testSaveUser() throws JsonProcessingException {
// 创建对象
User user = new User("李四", 24);
// 手动序列化
String json = mapper.writeValueAsString(user);
// 写入 User 数据
stringRedisTemplate.opsForValue().set("user", json);
// 读取 User 数据
String jsonUser = stringRedisTemplate.opsForValue().get("user");
System.out.println("redis读取结果: " + jsonUser);
// 手动反序列化
user = mapper.readValue(jsonUser, User.class);
System.out.println("jsonUser反序列化: " + user);
}
}
会发现Redis在存储的时候已经消除掉多余的数据

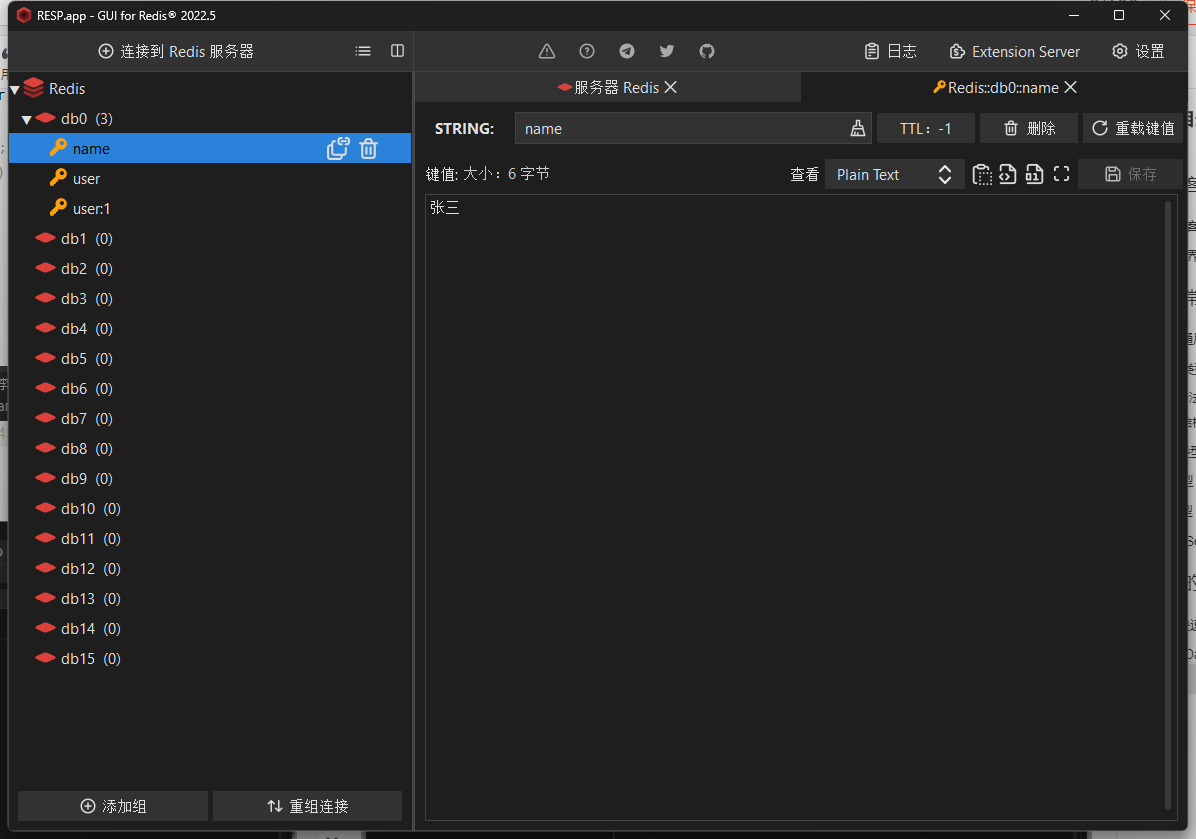
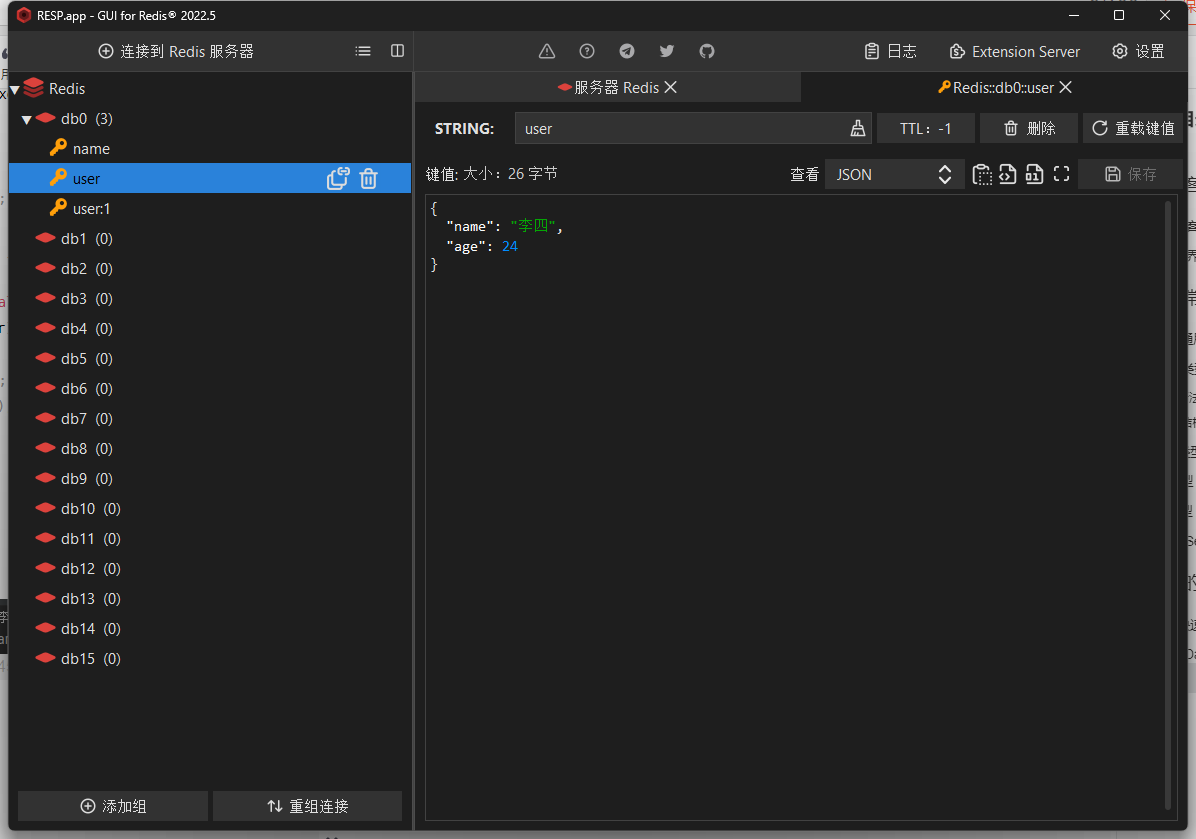
读写Hash
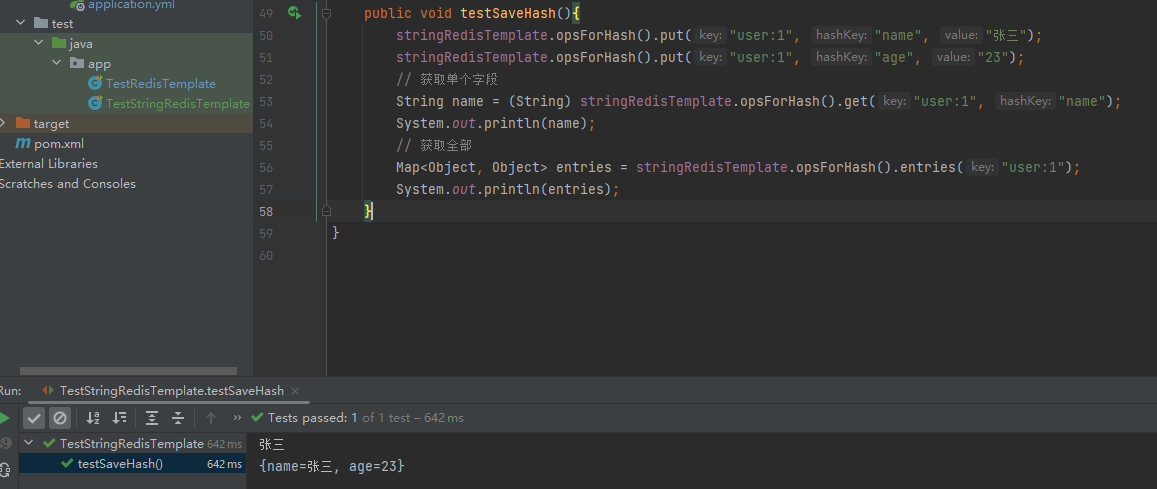
在处理 Hash 类型的时候,语法hset有些不同,更偏向于 Java 语法 put
@Test
public void testSaveHash(){
stringRedisTemplate.opsForHash().put("user:1", "name", "张三");
stringRedisTemplate.opsForHash().put("user:1", "age", "23");
// 获取单个字段
String name = (String) stringRedisTemplate.opsForHash().get("user:1", "name");
System.out.println(name);
// 获取全部
Map<Object, Object> entries = stringRedisTemplate.opsForHash().entries("user:1");
System.out.println(entries);
}
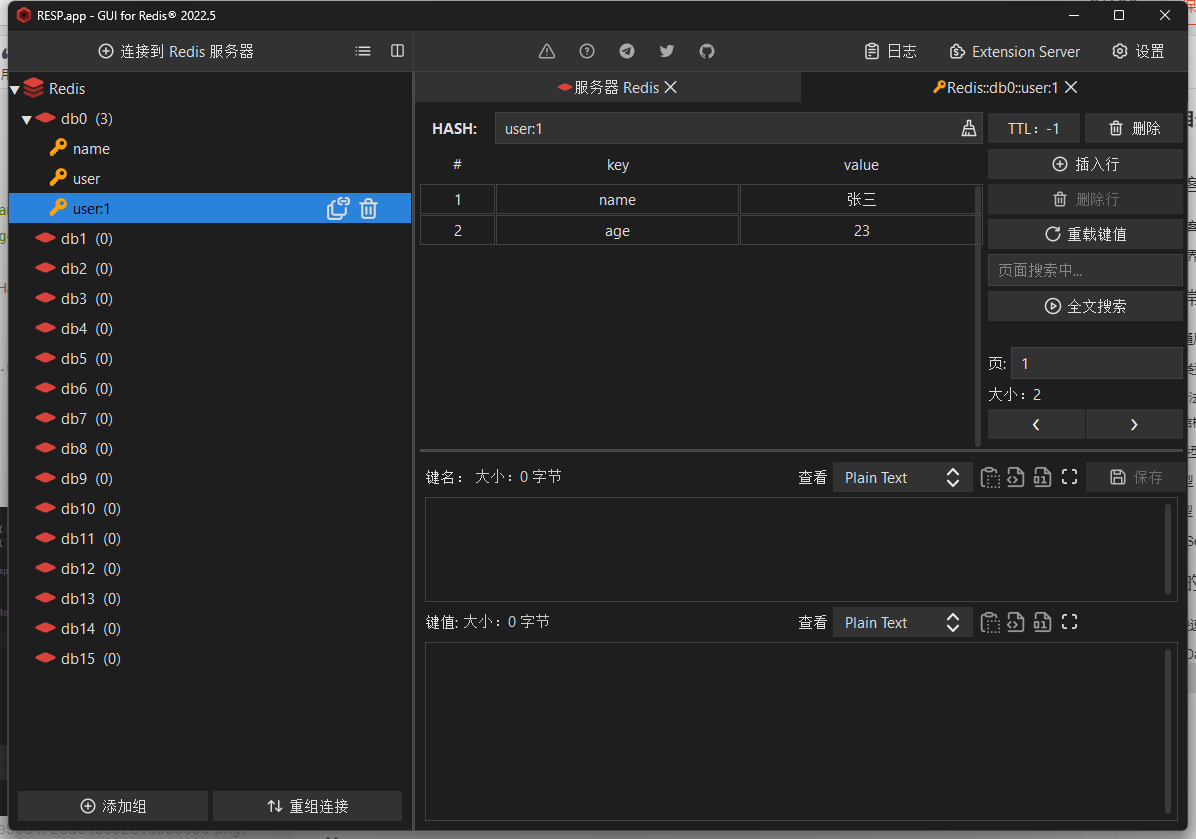
总结
方案一
- 自定义
RedisTemplate - 修改
RedisTemplate序列化器为GenericJackson2JsonRedisSerializer
方案二
- 使用
StringRedisTemplate - json序列化处理之后再写入redis
- 读取完redis之后再json反序列化成对象