1.谬论
很多非一手的资料特别是中文资料其实并不可靠 因为很多作者都是直接通过转载他人的作品 也不管他人作品真与假 而且有一部分的作品中的言论和官方描述相去甚远 有的则是翻译的过程中出现了问题
比如sizeof很多人认为是一个函数 其实他并不是一个函数 而是一个运算符 是一个一元运算符
而且就算官方也有出错的时候 这就要求我们具有辨别的能力了
2.建议
首选官方资料(手册、官网……)
英文资料 > 中文资料
具备验证知识点正确性的能力(有关编程语言知识点的正确性 掌握汇编语言是最靠谱的检验手段)
3.汇编的好处
1.可以检验知识点的正确性
2.可以进行破解
3.可以制作外挂
4.代码本质挖掘
1.sizeof本质
sizeof本质上不是一个函数 而是一个运算符
在汇编语言中 函数利用了call完成调用操作 而在sizeof的底层汇编中 压根没有call的影子 说明根本就不是所谓的函数
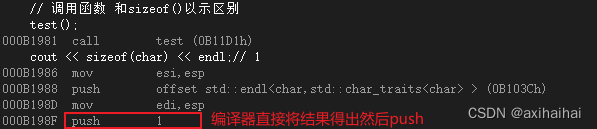
从另外一个方面也可以看出sizeof不是一个函数
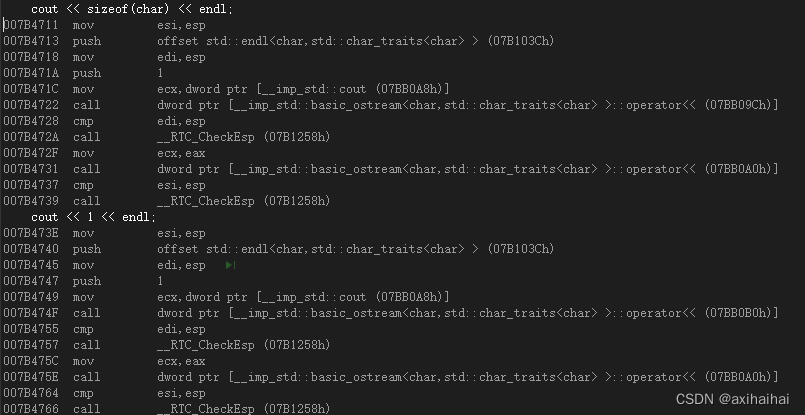
我们可以看到直接打印sizeof(char)的结果和打印sizeof(char)的底层汇编所执行的操作是一模一样的 说明编译器在编译阶段是直接可以识别出sizeof()的结果并且替换成相应的结果(因此sizeof也被称为编译时特性) 既然如此 更能说明sizeof不是一个函数
2.a++和++a的区别
3.if-else和switch的效率比较
4.程序的内存布局
5.多态的实现原理
5.程序的本质
程序是以机器码(或称作CPU指令 即由0和1组成的)的形式储存在硬盘中的(在储存之前 是由编译器将其编译成机器码的) 当运行软件的时候 程序会被装载到内存之中 然后CPU会根据机器码的要求调用计算机的其他设备完成相关的需求(CPU只能识别机器码)
CPU由寄存器、运算器、控制器组成 其中寄存器也有和内存一样的储存功能 那么CPU在访问寄存器方面肯定是比内存要来的快的 原因在于寄存器更加接近CPU
6.寄存器和内存
通常情况下 CPU会先将内存中的数据储存到寄存器中 然后在对寄存器中的数据进行访问或者运算
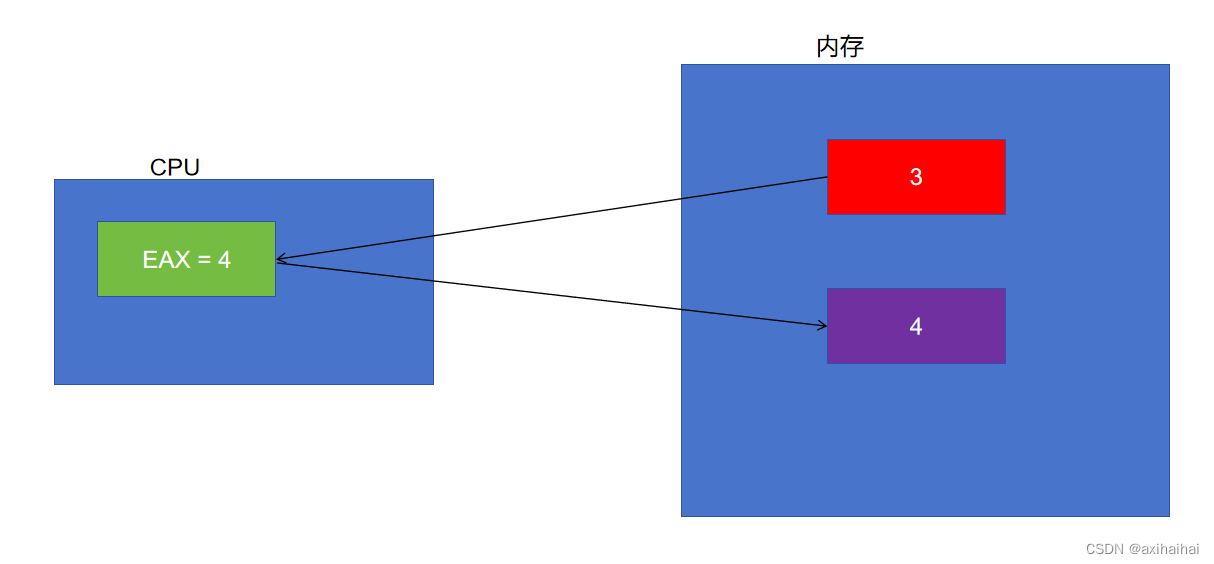
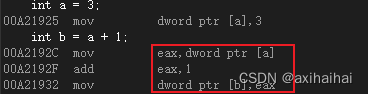
我的要求是对红色内存中的数据进行加一操作
其中 首先会将红色内存中的数据储存到eax寄存器中 即mov eax, 红色内存空间
接着让EAX的数据和1相加 即add eax, 1
最后会将结果储存到蓝色的内存空间中 即mov 蓝色内存空间, eax
从反汇编的角度也可以说明验证我的说法
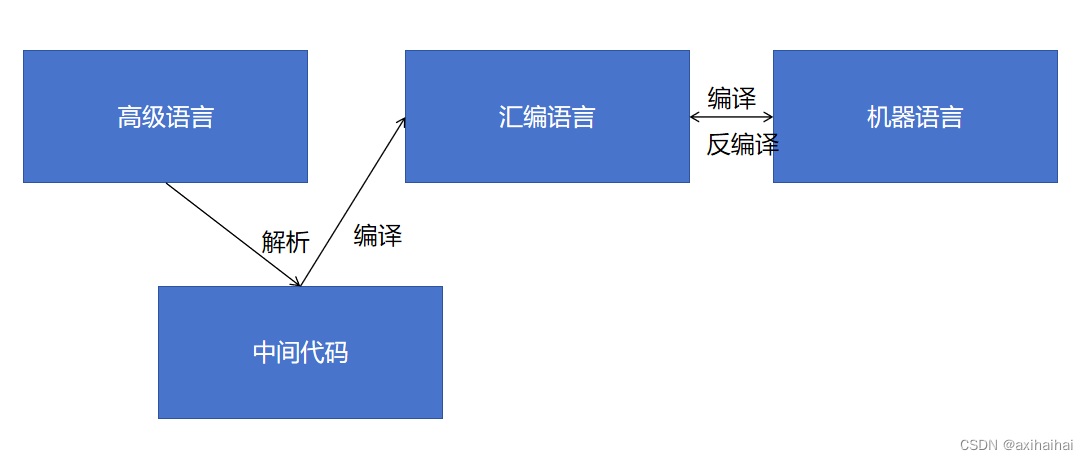
7.编程语言的发展
机器语言(由0和1组成) -> 汇编语言(用符号替代了0和1 可读性更强了) -> 高级语言(c/c++/java…… 接近人类自然语言 更具有可读性)
对于同一个操作 将寄存器ebx的内容传入到eax中(以下代码是伪代码)
机器语言:010100000001111011010
汇编语言:mov eax, ebx
高级语言:eax = ebx;
很多语言都有高级语言编译成汇编语言、汇编语言编译成机器语言最终运行到计算机上的过程
其中汇编语言和机器语言是可以相互转换的 也就是说汇编可以编译成机器语言 机器语言也可以反编译成汇编语言 所以汇编语言和机器语言是一一对应的 每一条汇编语言都有与之对应的机器语言
然而高级语言虽然可以通过编译得到汇编/机器 但是汇编/机器几乎不能够反编译成高级语言

对比两张图片可以看到两个不同的高级语言底层的汇编/机器是一模一样的 更能说明汇编/机器几乎不能够还原成高级语言(因为一旦还原的话 会产生歧义)
不同的CPU架构(x86和arm)的机器指令是不一样的(CPU架构不一样 CPU就不一样 那么所处理的机器指令也就不一样)
8.一些编程语言的本质
1.编译型语言(不依赖虚拟机)
诸如C/C++/OC/Swift 轻易反汇编

2.脚本语言
诸如Python/PHP/JS 由脚本引擎(比如浏览器等)解析
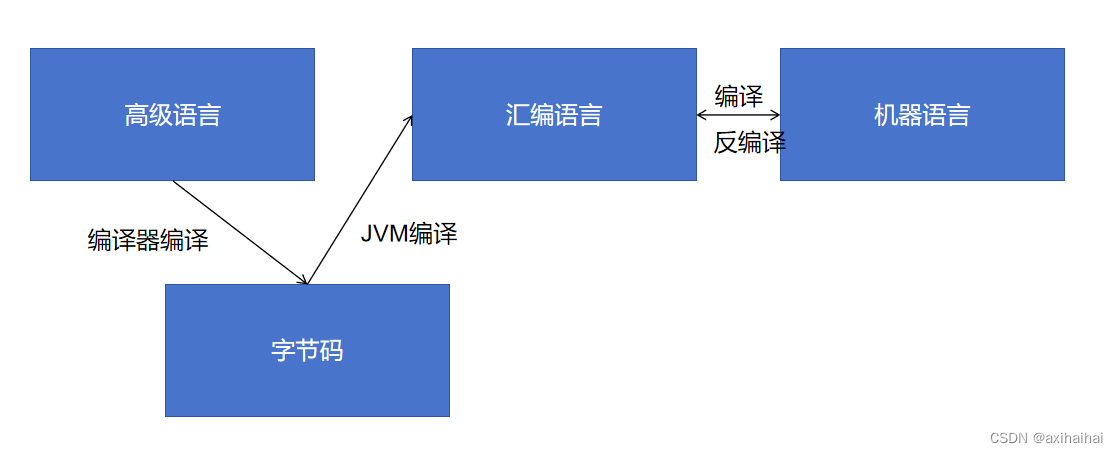
3.编译型语言(依赖虚拟机)
Java/Ruby 由JVM进行字节码的装载
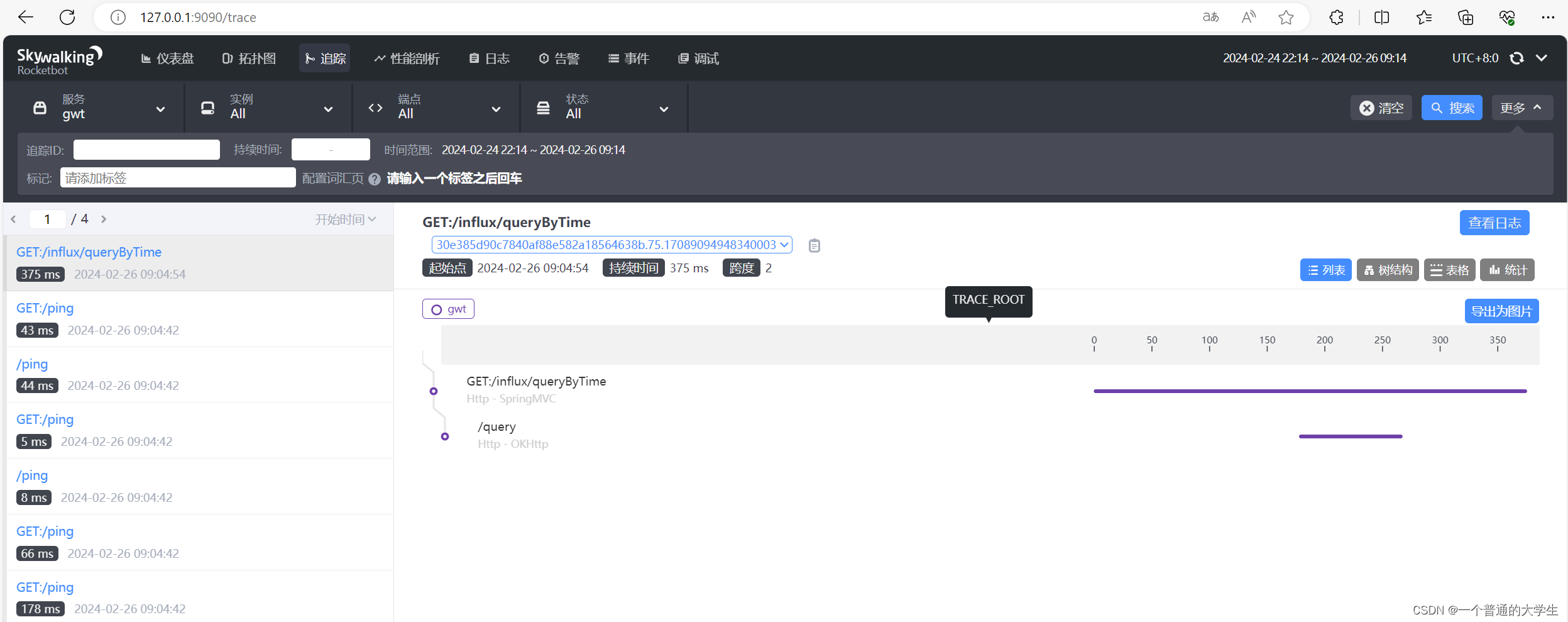
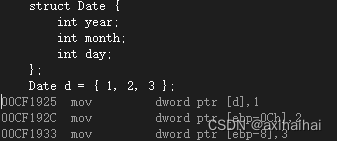
9.visual studio中的反汇编

从上图可见 反汇编中的每一行大致都是由三部分组成 第一部分是内存中用于标识机器码的位置的地址值 第二部分则是这段代码的机器码 第三部分则是这段代码的汇编代码

而且高级语言中的一行代码不一定对应着汇编/机器码中的一行 可能是多行