目录
一、本周计划
二、DD-Net整体介绍
三、DDNet的体系结构
四、损失函数
五、课程学习
六、实验环境
A. SEG盐数据集
B. OpenFWI数据集
C. 训练和前沿设置(未完)
七、结论
八、跑代码——对比试验结果(CBAM)
1. InversionNet对比实验:数据集curvefault-a
2. InversionNet对比实验:数据集flatvel
九、存在的主要问题
十、下一步计划
一、本周计划
阅读师兄的论文《DD-Net》,使用OpenFWI中的不同数据集跑代码
二、DD-Net整体介绍
- 标题:Dual decoder network with curriculumlearning for full waveform inversion——DD-Net:具有课程学习的双解码器网络用于全波形反演
- 期刊:IEEE TRANSACTIONS ON GEOSCIENCE AND REMOTE SENSING——IEEE《地球科学与遥感汇刊》
- 代码:github.com/fansmale/ddnet
基于深度学习的全波形反演(DL-FWI)作为一种数据驱动方法,有几个关键问题。例如,需要设计有效的深度网络,需要控制训练过程,需要增强泛化能力。在论文中,提出了一个具有课程学习的双解码器网络(DDNet)来处理这些问题。
- 对于网络设计,我们使用基于U-Net架构的双解码器,以掌握速度模型的速度值和地层边界信息。这些解码器的反馈将在编码器处组合以增强边缘空间信息的编码。第一解码器专注于重建速度值的分布,该体系结构与FCNVMB的体系结构相似。第二解码器被用作辅助以加强层边界。边缘解码器已证明其在某些领域作为分支任务的有效性,如医学中的肿瘤识别。论文的结构利用了多任务学习中的硬参数共享机制。这种主要/辅助任务的参数和性能共享确保了对原始任务的更好概述。最后,设置均方误差和交叉熵的联合损失函数来控制输出。
- 关于训练过程,通过组织三个难度级别的数据,将课程学习引入网络训练。从易到难的训练过程增强了网络的数据拟合。在课程学习中,客观评估网络输入的难度水平并非易事。通过对FCNVMB中不同炮的研究,我们推断出基于单炮到多炮的难度测量器。训练调度器会将这些具有不同难度级别的数据安排在不同的批次中。
- 为了增强网络设计的适应性,我们通过预网络降维器将网络应用于低分辨率地震观测。这可以作为一个通用的设计思想,而不会破坏原有的网络特性。在野外采集时,时间采样点和检波器的数量可能有很大不同,这将导致共炮点道集图像纵横比过大。尽管插值等传统方法可以处理这个问题,但在一些分辨率较低的地震观测中,这可能会导致不可避免的信息丢失。因此,我们通过由多个卷积组成的降维结构来压缩时间维度。它可以用作在不同时间采样的采集几何图形的通用设计组件。
实验在SEG盐数据集和OpenFWI的四个合成数据集上进行,有四个指标包括MSE、MAE、UIQ和LPIPS。同时,将FCNVMB和InversionNet两个DL-FWI网络与DDNet网络进行了比较。结果表明:
1)DDNet在不同的数据集中都优于同类网络;
2)课程学习与DL-FWI的融合提高了网络学习能力;
3)双解码器便于重建速度模型中的边缘细节;
4)DDNet对各种数据具有良好的泛化能力。
论文的其余部分组织如下。在第二节中,介绍了DL-FWI中的两种主要方法。在第三节中,详细描述了该方法的网络结构、课程学习和损失函数。在第四节中,描述了数据集和训练细节。在第五节中,给出了我们的网络在两个数据集上的实验结果。在第六节中,讨论了第五节中的实验结果,并补充了网络的一些特性分析。最后,在第七节中,提供了一个结论。
三、DDNet的体系结构
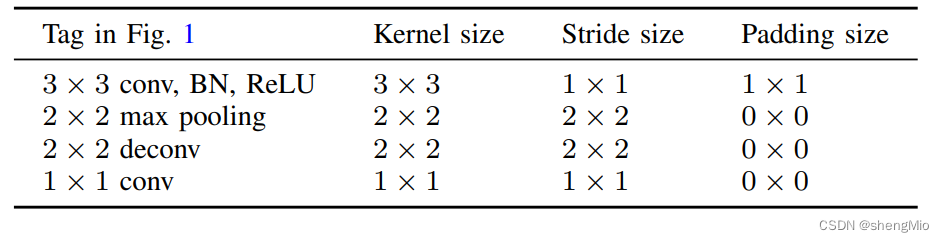
图1显示了DDNet的体系结构,其基本思想取自U-Net,在此基础上使用了两个解码器,使整体结构呈Y形。
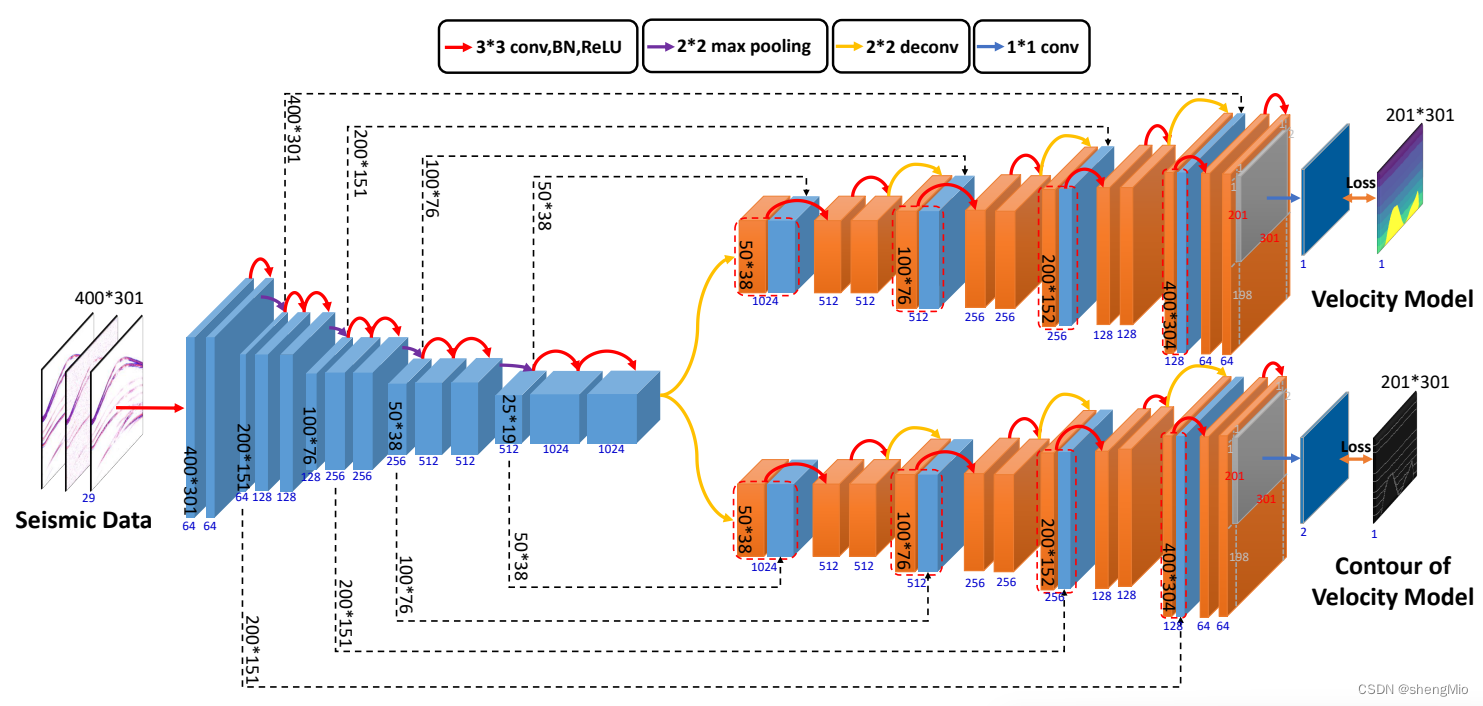
图1:用于反演的DD-Net的深度网络架构。
图解如下:蓝色立方体表示编码器的信息,橙色立方体表示解码器。每个立方体的宽度表示图像中通道的数量(立方体下方用蓝色标记)。黑色数字表示当前网络层的图像大小(例如,400×301输入)。红色箭头表示三个连续的固定操作,即卷积、BN(批归一化)和ReLU。紫色箭头代表池化操作。黄色箭头代表反卷积操作。蓝色箭头代表1*1卷积操作。红色虚线框表示由两部分组成的通道的串联操作。黑色虚线箭头指示输入到解码器的特征的来源,在此期间扩展原始解码器维度。
左侧的编码器组件负责地震数据的压缩过程。它将29次地震观测记录进一步压缩为1024维的抽象结构化信息。
传统的U-Net在处理图像分割时仍然存在轮廓粗糙和不连续的问题。然而,多解码器为我们提供了一种非常有趣的方法来解决这些缺陷。不同的解码器将U-Net变成一个多任务学习环境。特定任务的专门解码器解决了U-Net的固有缺点。子任务解码器还可以为主任务或后续任务提供参数上下文。考虑到这一点,我们应用额外的轮廓解码器来确保分割预测的平滑性。
右边的两个解码器使用不同的思想来解释高维抽象信息。第一个解码器的目标是传统的速度模型,它专注于速度值的精确拟合。它将成为预测的主要解码器。然后,提取轮廓后的二进制速度模型被进一步用作第二解码器的拟合目标。该解码器将用作训练轮廓信息的辅助解码器。
网络中有两种基本操作,即卷积和反卷积,分别用于编码器和解码器。
(a)在编码器中,重复卷积充分利用了地震波形中的连续信息。BN对卷积后输入网络的数据子集进行归一化,从而提高收敛性。ReLU激活函数通过去除一些网络节点来保证层到层的非线性。同时通过多个ReLU的非线性叠加,该深度网络可以近似波动方程的映射。
(b)在解码器中,反卷积操作可以将高度压缩的信息扩展到更高分辨率的图像中,同时保留尽可能多的信息。跳跃连接用于获得更高分辨率的编码器功能。此外,较浅的卷积层保留了不同炮之间的细粒度差异。因此,作为附加通道的较浅层的特征图可以进一步指导解码器描述重叠检测区域的边界信息。表1列出了神经网络的一些详细参数设置。
表1:DDNet网络层详细配置
共炮点道集(common-shot-gather)通常与极大的纵横比相关联。对于一些使用少量检波器的低分辨率观测,直接使用插值进行下采样可能会导致一些信息丢失。因此,作者为1000×70的低分辨率观测建立了一个具有降维器的DDNet的修改版本。我们根据检波器的数量将其命名为DD-Net70。
在图2中,DD-Net70其结构与DD-Net类似(如图1所示)。不同之处在于在网络前面扩展了一个预网络降维器(降到70*70)。同时,引入了一个非平方卷积来压缩时间维度(图像高度),确保地震数据被约束到与速度模型相同的大小。降维器将使用多个卷积进行协调,以防止一次卷积压缩造成的信息丢失。这个设置类似于InversionNet的设置,但我们将其推广到U-Net结构。然后,网络的输入和输出大小分别变为1000×70和70×70。
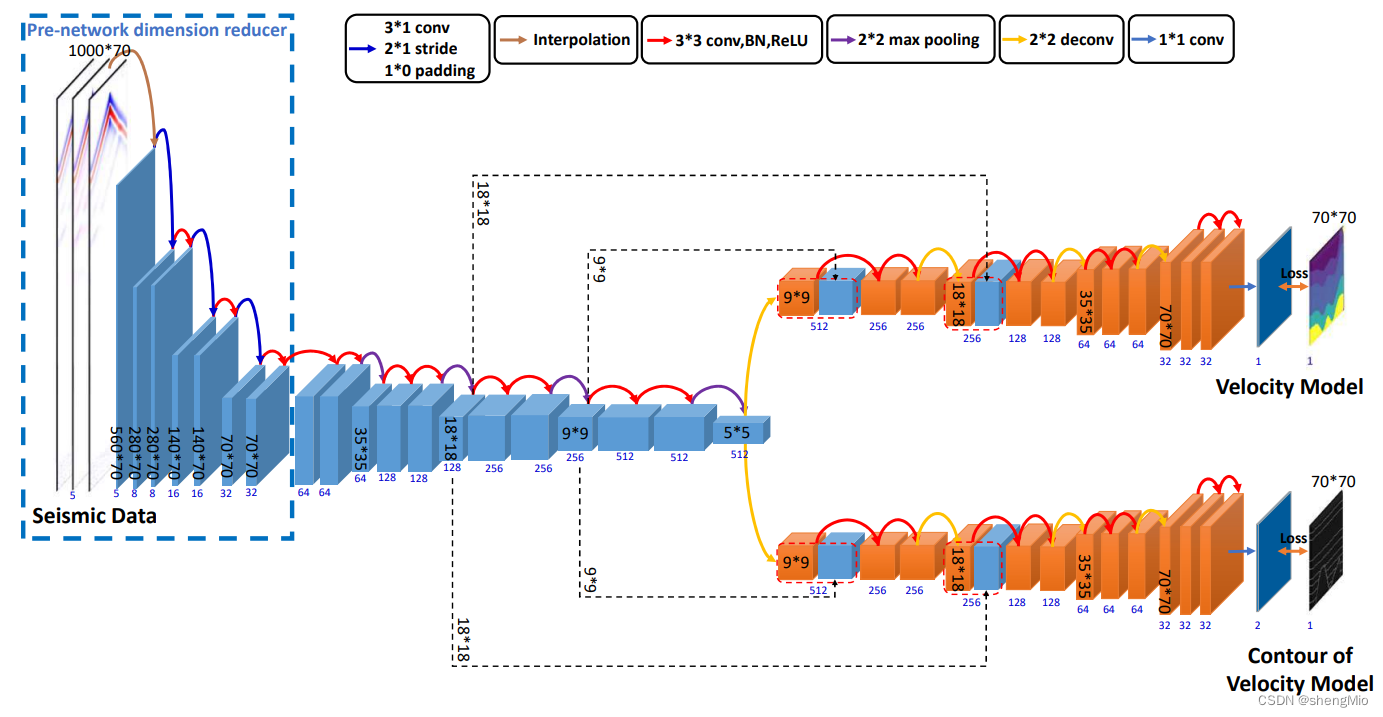
图2:用于反演的DD-Net70的深度网络架构。
四、损失函数
为了处理不同解码器的不同任务,我们为网络架构提出了一种新的联合损失函数。该损失函数由均方误差(MSE)和交叉熵损失函数组成。
- 第一解码器直接输出单通道图像。它与地面实况速度模型进行一对一的像素差损失计算。
- 第二解码器输出双通道图像。这两个通道相互作用以模拟速度模型的轮廓信息。事实上,相关研究已经证明了交叉熵损失服务于速度重建中二进制分类子任务的可行性。
首先MSE损失函数是用于描述颜色相似性的常见损失函数:
(1)
其中m表示输出速度模型的像素数。b表示每次迭代中同时要训练的数据数量,即批量大小。和
分别表示地震数据及其相应的地面真实速度模型。N(·)表示地震数据
到预测速度模型
的网络确定的映射。此外,
表示第k个解码器输出中的预测速度模型的第j个通道。因此,
是由地震数据
预测的速度模型与实际速度模型之间的残差。
第二,交叉熵损失函数提供了与差异损失相反的轮廓拟合思想:
(2)
其中是通过对第二解码器的两个通道执行softmax而获得的:
(3)
在等式中(2)是速度模型
的轮廓结构。图3(a)和图3(b)分别表示了
和
的结构。
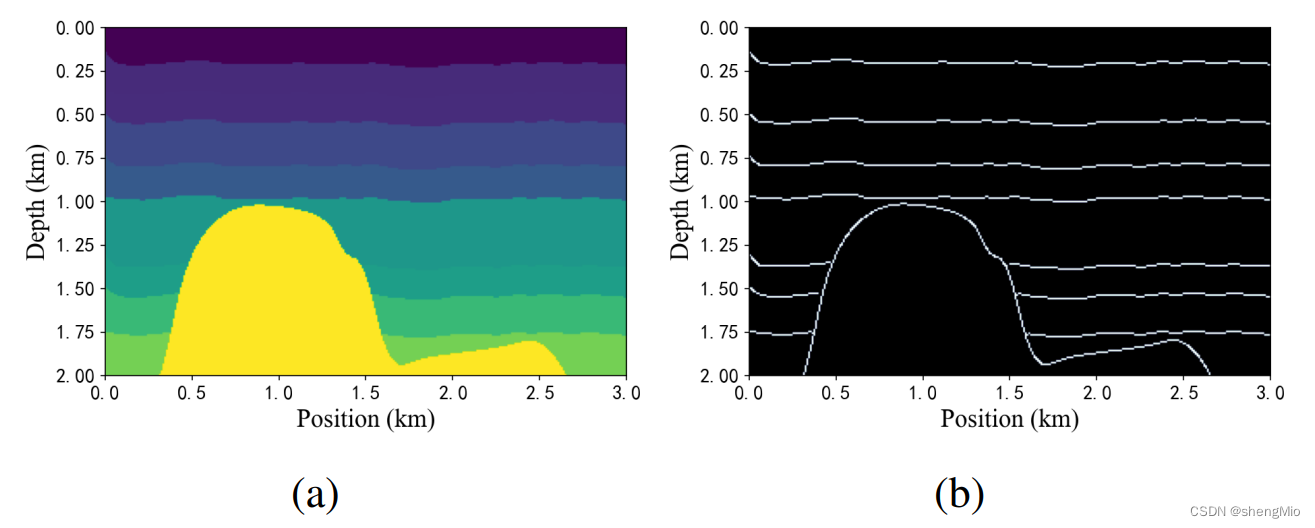
图3:速度模型及其轮廓的示例。(a) 是模拟的速度模型;(b)获得的该速度模型的轮廓结构,双阈值分别设置为10和15。
是
的反转颜色,一致地将
和
表示为二元掩码算子
。同时,
和
表示为预测的灰度图像
,使用
从
中提取注意信息。在条件概率方面,在等式(2)中方程中的
作为:
(4)
轮廓越明显,越大。为了确保此时的损失较小,交叉熵损失引入了负熵。因此,公式(4)经常被替换为:
(5)
对于具有较大边际偏差的样本,交叉熵损失受到的惩罚更大。这确保了拟合损失可以集中在轮廓上,而不是全局计算残差。同时,图像中轮廓的像素比例较小,这可能导致轮廓图像中像素的不平衡分布。
与MSE相比,交叉熵损失用于考虑不同类别的差异,保证了对轮廓和背景信息的更公平考虑。这种类似的轮廓损失函数的设计已经在图像分割领域进行了实践。
最后,我们通过超参数和
将两个损失函数组合起来:
(6)
这两个参数的比例可以根据不同的情况进行调整。为了预测准确的速度模型,可以使用非归一化的速度模型进行训练和预测一些网络。此时,两个解码器的损耗的数量级差异可能非常大。例如,当SEG盐模型未归一化时,被设置为
,但对于归一化的OpenFWI模型,该值通常被设置为10或
。
五、课程学习
许多网络训练思想试图模仿人类的思维过程。课程学习是对人类渐进认知的模拟。
1) FWI的课程学习:在传统的机器学习中,呈现给网络的数据集的难度属性往往是随机的。因此,它的复杂性和网络的当前学习状态被忽略了。然而,课程学习以阶段性适应的理念改变了这一不足,并在许多领域取得了可观的成果。它试图逐渐增加训练数据集的难度,以确保有效的拟合。具体来说,在一开始,我们从一个相对简单的数据集开始训练网络,这有助于网络快速收敛,防止局部最优解陷入困境。然后,随着网络达到一定的性能水平,我们逐渐引入更复杂的数据集。
如果仅使用单个炮点,则网络获得的地下信息是波覆盖的局部区域。因此,本论文使用多个炮点反馈的地震波反射记录来联合预测整个地下区域。然而,在一些深度学习策略中,单次数据也可以用于实现一定的预测效果。这意味着网络可以通过学习构建从局部波形和频率到整个速度模型的记忆映射。尽管从物理角度来看,这种映射并不优美,但它可以作为网络学习的试点。它引导网络从时域波形到速度模型留下基本的风格印象。这一过程符合课程学习的理念。
2) 地震数据的预定义课程学习:网络中课程学习技术的使用必须指定这两个组成部分的细节。
- 难度测量器:难度测量者告诉我们哪些数据是困难的。换句话说,它可以决定不同数据的优先级。
- 训练调度器:训练计划器告诉我们何时以及哪些难度数据需要训练。同时,它还告诉网络所选数据的训练参数,包括epoch数和学习率。
目前,根据测量器和调度器是定制的还是数据驱动的,课程学习可以细分为预定义课程学习和自动课程学习。鉴于缺乏描述地震数据难度的先验理论,我们使用预定义的课程学习。我们在课程的具体设置中采用了三个阶段。
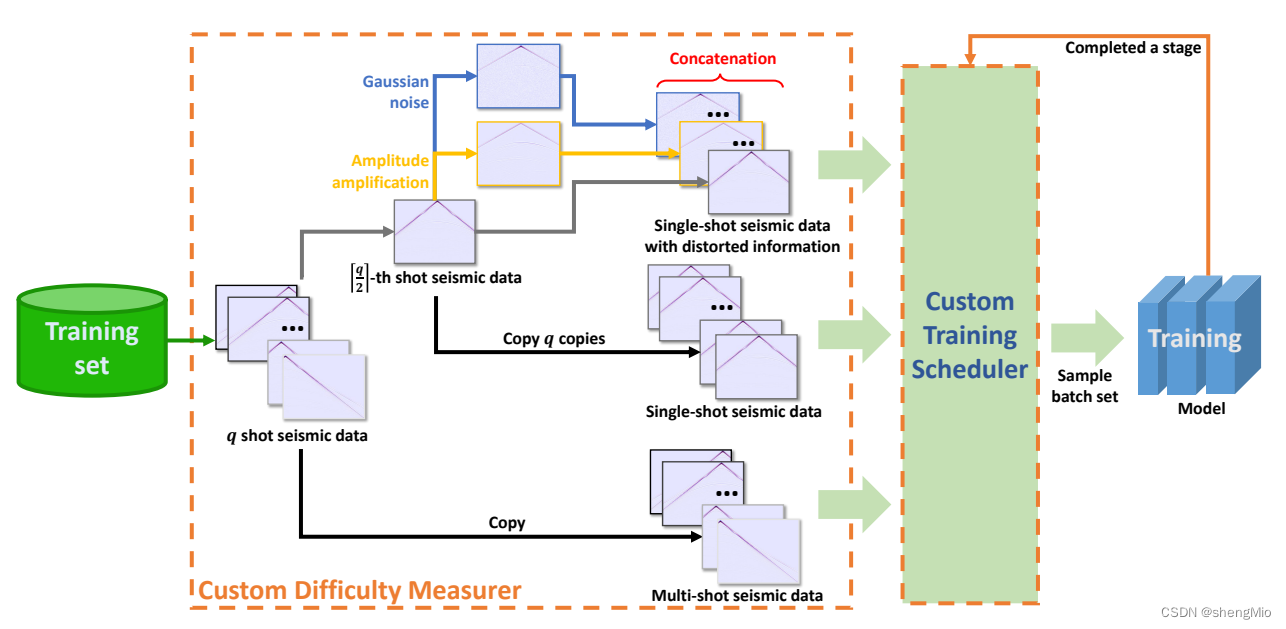
图4:基于FWI的预定义课程流程。
图解:中间的橙色区域演示了如何将地震数据处理为三级数据。橙色框中不同颜色的箭头表示不同的操作。蓝色和黄色箭头分别表示添加噪声和放大幅度。q表示模拟检测期间的震源数量,也相当于网络的输入通道数量。右侧显示了我们如何将三阶段数据排列到网络中。橙色和绿色箭头形成的圆圈表示训练过程中一个阶段的迭代。此迭代将执行三次。一次迭代将为多个批次提供训练。
(a)具有失真信息的单次激发数据:地震观测记录由个共炮点道集组成,从中获得了第
个记录。首先,对该记录进行噪声放大和振幅放大,得到两个畸变记录。第二,复制每个失真记录的
个副本和原始记录的
个副本。最后,将这三者连接起来,以获得
个观察记录的组合。
(b)单炮数据:我们获取了地震观测记录中的第个记录。然后,我们获得该记录的
个副本。这些副本作为一个整体通过串联用作此阶段的数据。
(c)多炮数据:直接使用个炮点的地震观测记录作为本阶段的数据。由于网络的输入端口是确定的,所以每个阶段的课程数据总是携带
个通道。
在多炮数据之前放置单炮数据有两个注意事项:
- 一方面,单炮数据在多个副本之后被馈送到网络中。彼此不同的输入层的信道越少,网络捕获输入之间的差异所需的训练样本就越少。因此,与多炮数据相比,单炮数据具有更快的拟合能力。
- 另一方面,尽管单炮数据检测到的地层区域是有限的,但它可以作为多炮数据训练的风格指南。通过不完全信息和短期训练,将首先建立从波形到速度模型的初始认知网络。此外,在单次激发数据之前设置失真信息的动机类似于数据增强。通过预训练原始数据的混合噪声版本来确保网络的鲁棒性。
我们的自定义训练调度器为不同阶段设置不同的训练时期:
首先,调度器将按顺序集向网络提供数据。同时,提供给网络的数据将独立进行训练。其次,当训练时期的数量达到预定义的上限时,执行新一轮调度。不同数据集中的数据分布存在显著差异。因此,网络对三阶段数据的适应性也存在明显差距。出于这个原因,不同的调度信息可以在第四节中的不同数据集的实验设置中使用。
六、实验环境
在本研究中使用的两种类型的数据集:
1) SEG盐及其模拟数据将用于训练DDNet。目的是探索我们网络的迁移学习能力。
2)OpenFWI数据集将用于训练DD-Net70。目的是探索我们的网络对不同地下结构的适应性。然后,我们将讨论训练和前锋设置。最后,我们将重点介绍我们使用的四个评估指标中的两个。
A. SEG盐数据集
SEG盐数据集主要由两部分组成:盐数据及其模拟合成数据。
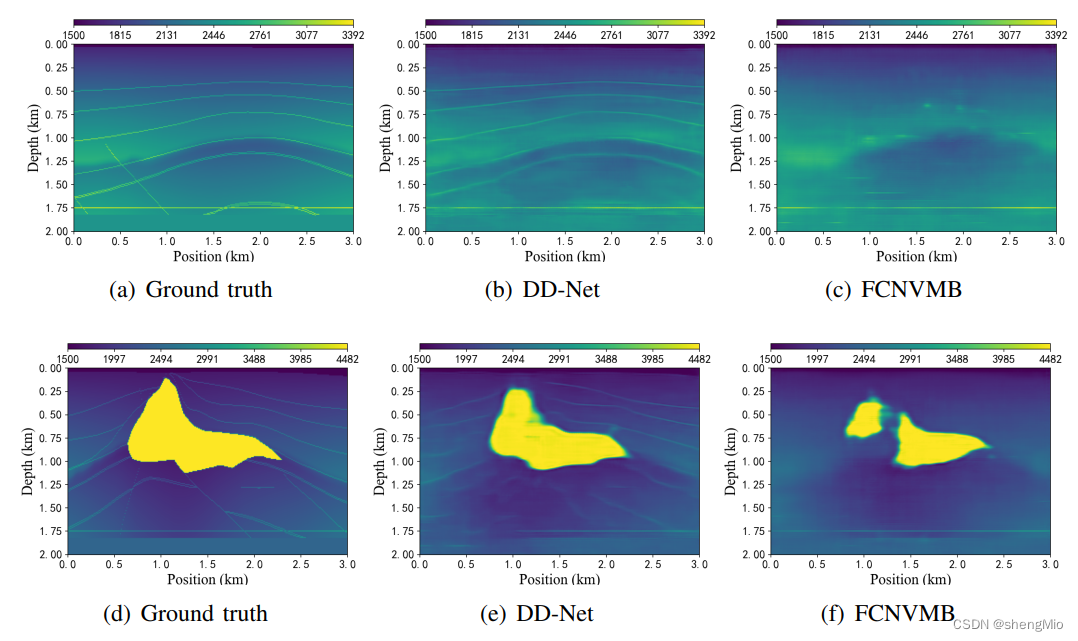
图7:在SEGSalt测试数据集中重新训练后,DD-Net和FCNVMB反演结果的比较示例。
1) 盐数据:盐数据是SEG研究委员会的开源3D数据集。在现有的研究中,从三维模型中提取了140个截面的二维数据,并进行了相关实验。这些横断面数据可以从GitHub 1下载。盐数据描述了地下约2km×3km的区域,像素大小为201×301。波的传播速度从1500米/秒到4842米/秒不等。图7(a)和7(d)显示了该数据集的两个样本。我们将此数据集称为“SEGSalt”。

图6:DD Net和FCNVMB在SEG模拟测试数据集中预训练后反演结果的比较示例。
2) 合成数据:考虑到SEGSalt的不足,我们需要提前用模拟数据对网络进行预训练。在我们的实验中,我们采用了FCNVMB[1]使用的合成数据集。图6(d)和6(a)显示了该数据集的两个样本。这个模拟数据集有1700个与SEGSalt数据大小相同的合成速度模型。这些速度模型中的地层数量从5层到12层不等。在每个速度模型中都有一个不规则的盐丘。同时,模拟数据的地层速度波动也控制在2000米/秒到4500米/秒之间。我们将此数据集称为“SEG模拟”。
B. OpenFWI数据集
OpenFWI是一个开源数据集,包含大量合成地震数据。它包括界面、断层、CO2储层、三维地下结构和其他地层数据类型。在我们的实验中,我们专注于识别地下界面和断层。因此,我们主要使用四个OpenFWI数据集:FlatVelA、FlatFaultA、CurveVelA和CurveFaultA。图8、10、9和11分别显示了这四个数据集的示例。这些数据集中的每一个都描述了一个0.7公里×0.7公里的地下区域,像素大小为70×70。波的传播速度大致在1500米/秒到4500米/秒之间。
此外,OpenFWI还提供了速度模型复杂性的分析。介绍了用于测量速度模型复杂性的三个度量,即空间信息、梯度稀疏性指数和香农熵。表II显示了我们在这些度量下选择的四个数据集的复杂性的数值结果。我们发现断层和曲线数据比非断层和平面数据更难。
最后,比较这些数据集也是可行的。FlatVelA和CurveVelA数据集反映了具有清晰界面的平坦和弯曲地下地层。FlatFaultA和CurveFaultA数据集反映了由岩层位移引起的地下断层结构。断层地层可以捕获流体碳氢化合物,因此是非常好的储层。同时,提供准确的断层描述将有助于进行储层特征描述和油井布置。
C. 训练和前沿设置(未完)
表IV:DD Net和DD-Net70的训练配置。第五列表示第III-C小节中三项任务的训练时期比例。
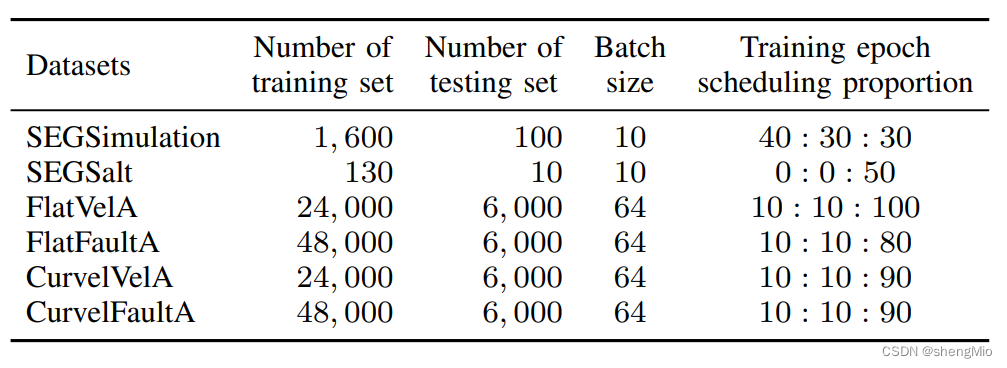
表四显示了训练过程中涉及的一些重要参数。在训练SEG-salt数据集之前,我们首先训练SEGSimulation以获得预训练的DD-Net网络。然后,我们只需要对SEGSalt进行少量训练即可获得转移的DD-Net网络。因此,我们不为SEGSalt设置课程学习。然而,OpenFWI数据集不需要迁移学习,因为它们的数据量很大。
七、结论
在本研究中,提出了一种基于课程学习的双解码器架构的新方法。双解码器允许网络在重建速度分布时考虑边缘结构,提高了反演的准确性。课程学习策略引导网络以渐进的方式学习地震数据,防止过度拟合并促进泛化。预网络降维器使网络结构能够适应一些低分辨率地震观测数据。我们的网络在SEG和OpenFWI数据集上都表现出了卓越的性能,消融分析进一步证实了我们提出的技术的有效性。接下来,我们计划探索以下改进领域:
1)地震输入数据的特征嵌入:我们旨在研究嵌入特征的集成,以捕获网络可能具有挑战性的信息。先前的研究已经显示了特征嵌入的潜力[9,10],但还需要进一步探索将其与复杂的网络架构相结合。
2) 丰富课程学习策略:我们打算结合更多的先验知识[52]来设计更全面的课程任务。此外,我们的目标是开发由这些先验知识驱动的自动难度测量器和训练调度器。
3) 推进物理先验知识和网络架构的集成:物理引导的DL-FWI有可能纠正网络中不合理或不现实的反演结果[3]。虽然这一领域已经引起了人们的极大研究兴趣[52,53],但由于其复杂性,它仍然具有挑战性。因此,我们计划将我们的网络架构进一步集成到这个具有挑战性和前景的领域。
八、跑代码——对比试验结果(CBAM)
1. InversionNet对比实验:数据集curvefault-a
epoch300,batchsize50,数据量1000,
- 未加入注意力机制
- 在解码器的最后一层ConvBlock_Tanh之前加入注意力机制CBAM
init处部分代码:
self.deconv6 = ConvBlock_Tanh(dim1, 1)
# 加入CBAM注意力模块
self.CBAM = CBAMBlock(dim1)forward处部分代码:
x = self.deconv5_2(x) # (None, 32, 80, 80)
x = self.CBAM(x)
x = F.pad(x, [-5, -5, -5, -5], mode="constant", value=0) # (None, 32, 70, 70) 125, 100
x = self.deconv6(x) # (None, 1, 70, 70)结果如下:
current best loss: 0.36993065774440764
current best epoch: 4
Epoch: [299] [ 0/20] eta: 0:01:39 lr: 0.0001 samples/s: 116.159 loss: 0.0211 (0.0211) loss_g1v: 0.0202 (0.0202) loss_g2v: 0.0009 (0.0009) time: 4.9847 data: 4.5543 max mem: 4909
Epoch: [299] Total time: 0:00:09
Test: [ 0/20] eta: 0:01:36 loss: 0.4246 (0.4246) loss_g1v: 0.2896 (0.2896) loss_g2v: 0.1350 (0.1350) time: 4.8129 data: 4.5144 max mem: 4909
Test: Total time: 0:00:07
* Loss 0.44716697
current best loss: 0.36993065774440764
current best epoch: 4
Training time 1:24:12
进程已结束,退出代码0整体来看未加入注意力机制效果会更好一点,轮廓会比加入CBAM后更清晰一点,与真实速度模型的大致形状会更加吻合一点。加入CBAM后其边界感会更模糊。
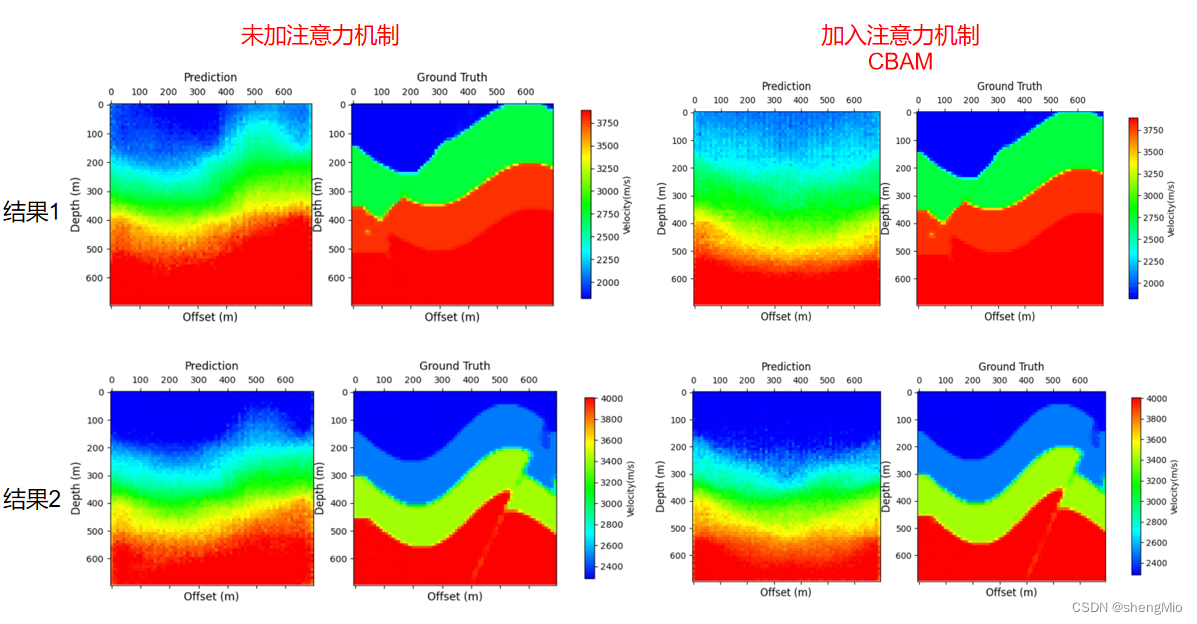
思考:后续考虑更改注意力模块的位置,或者加入其他注意力模块等
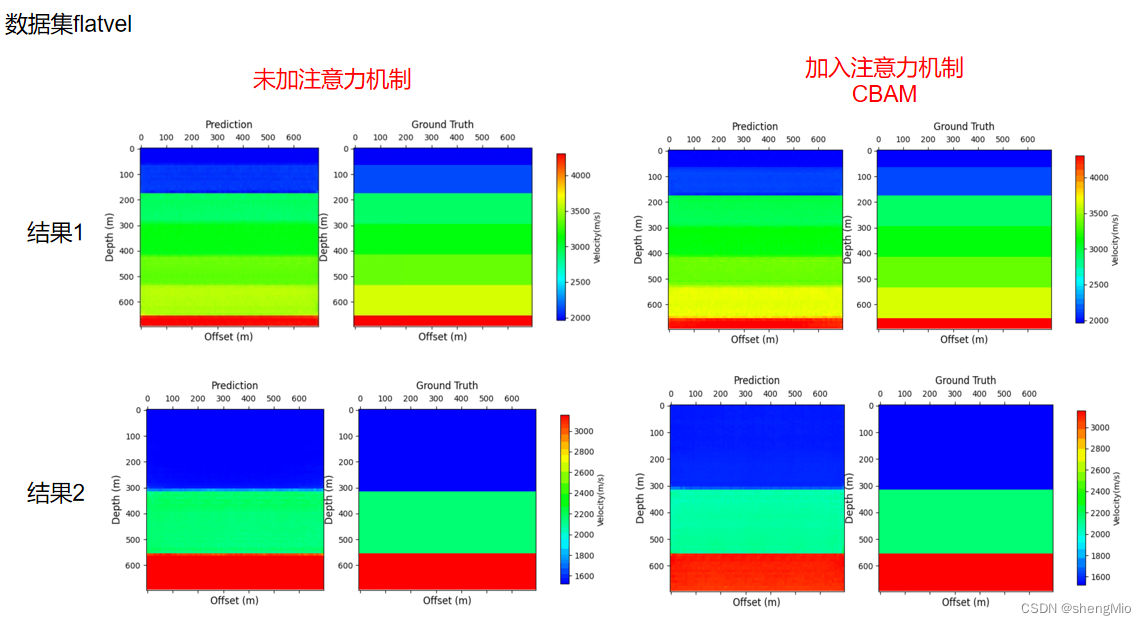
2. InversionNet对比实验:数据集flatvel
——断层数据目前效果不好,尝试使用更简单的数据集(平面)进行实验。
epoch180,batchsize50,数据量1000
- 未加入注意力机制
- 在解码器的最后一层ConvBlock_Tanh之前加入注意力机制CBAM
forward处部分代码:
x = F.pad(x, [-5, -5, -5, -5], mode="constant", value=0) # (None, 32, 70, 70) 125, 100
x = self.CBAM(x)
x = self.deconv6(x) # (None, 1, 70, 70)结果如下:
加入CBAM后:

使用较为简单的数据集后 两者整体效果都较好,加入CBAM后影响不大。
九、存在的主要问题
交叉熵损失函数没有看明白:查阅资料后补充。
使用curvefault-a数据集时,训练最好的epoch一直是刚开始的几个轮次,不太正常,是数据量的问题吗? 但是使用faltvel-a时,最好的epoch在训练过程中会逐渐下降。
十、下一步计划
完成论文余下部分以及代码






、WebDriverWait())](https://img-blog.csdnimg.cn/direct/e481880c43304632abcce5b1ec79eded.jpeg)