如有错误,恳请指出。
文章目录
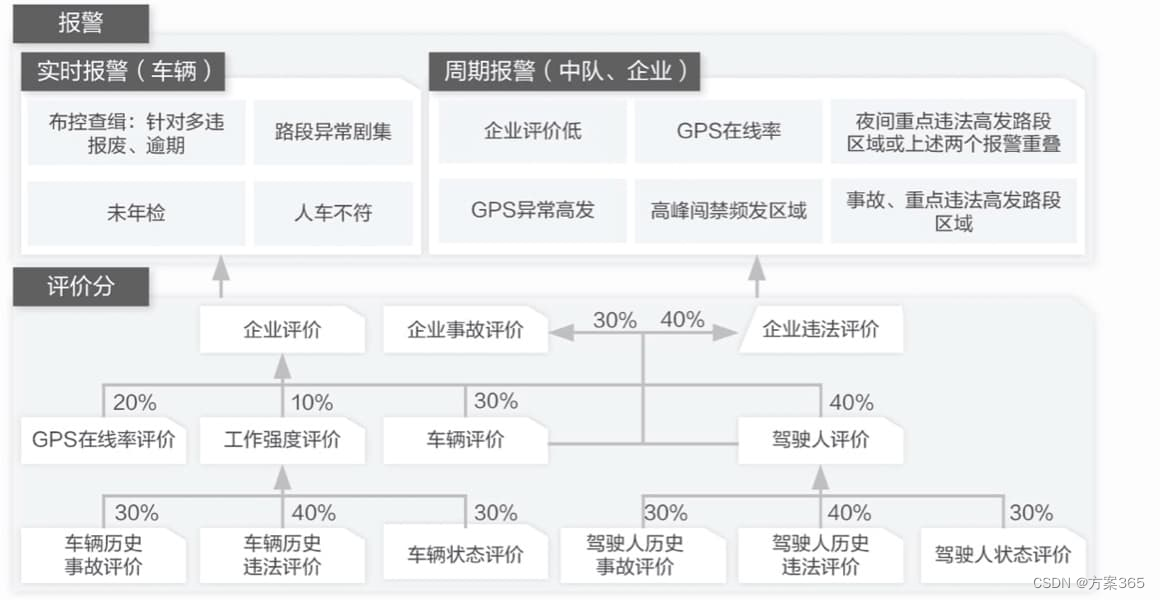
- 1. 背景
- 2. 网络结构
- 2.1 提案投影网络
- 2.2 区域融合网络
- 3. 实验结果
paper:《Multi-View 3D Object Detection Network for Autonomous Driving》
1. 背景
激光雷达可以提供物体的深度信息,而摄像头可以提供物体的细节语义信息,利用Lidar+Image两种模态理应可以获得更好的检测效果。一般来说,基于LIDAR点云的方法通常可以获得更准确的3D位置,而基于图像的方法在2D框评估方面具有更高的准确性,如何有效的利用来自与Lidar和Imgae两种模态获得更好的3d检测效果设计模型结构是MV3D的出发点,并启发于FractalNet和Deeply-Fused Net两个工作进行网络设计。
此外,在Related Work中有些比较有趣的工作,比如利用体素和点云的多视图表示来进行3d物体分类任务,利用图像和深度信息以及光流的组合进行2d行人检测,不过这种利用多模态进行自动驾驶的研究还比较少。
2. 网络结构
网络的大体思路是利用点云的鸟瞰图生成3d候选框,再投影回去图像、点云、鸟瞰图模态上获取区域特征(region feature map),再将这些来自不同模态的区域特征进行深度融合用于后续的分类和边界框回归。结构图如下,下面内容会介绍一下网络细节。
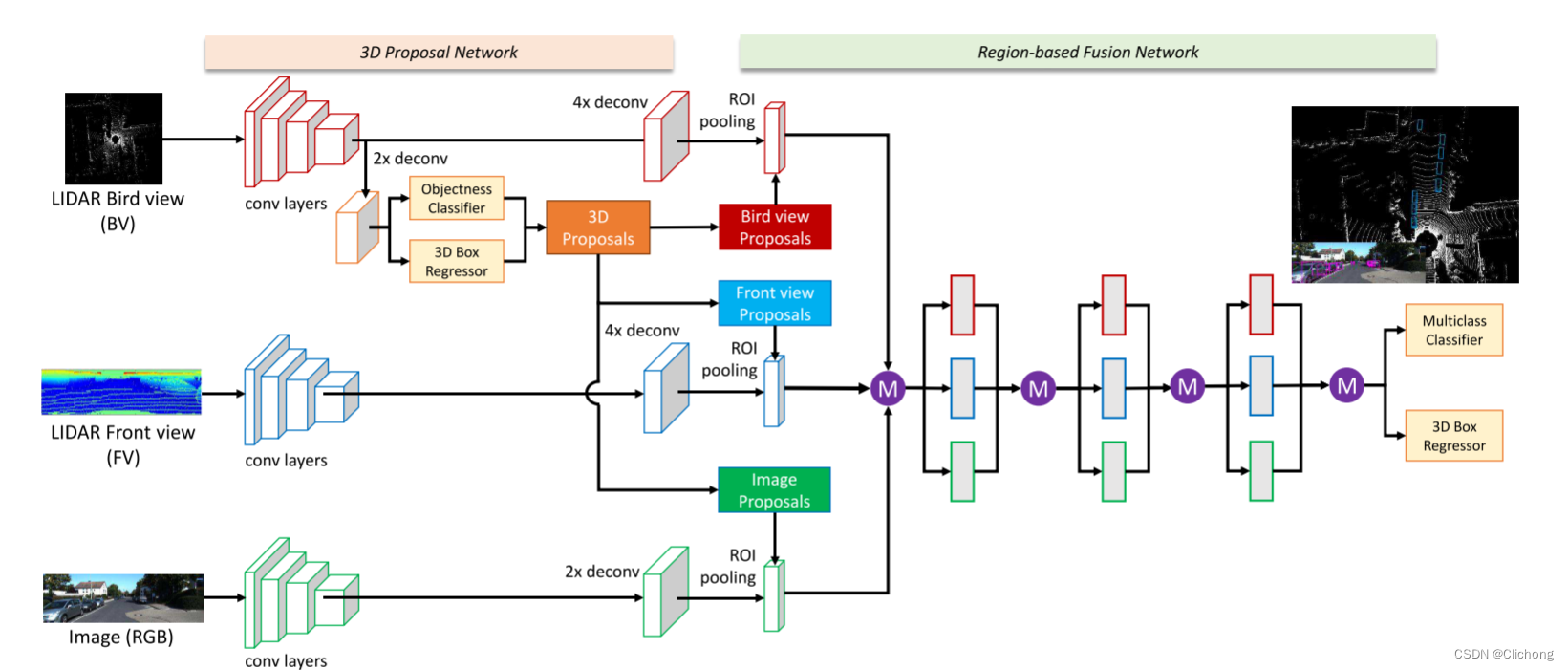
2.1 提案投影网络
MV3D的核心思路是采用多模态的输入数据,对候选框进行联合表征。那么,首先要处理的问题就是如何根据点云提取多模态的数据,这里的多模态数据包含鸟瞰图、前视图和原始RGB图像数据。
鸟瞰图模态数据的获取,首先需要对点云数据在俯视图上进行量化,划分为一个个精度为0.1m的网格,对这些网格提取最大高度点的反射强度作为Intensity特征;提取网格点数作为Density特征;同时沿高度方向将点云切分为M片,对切分出来的每一片提取每片网格的最大高度作为其Height特征,这里的Height特征会有M个(因为对每一片进行提取)。在量化过程中,由于是量化的是一个局部的特征描述值,所以损失是在所难免的。此时鸟瞰图特征就有1个channel的Intensity特征,1个channel的Density特征以及M个channels的Height特征拼接组成,故鸟瞰图特征图具有(M+2)个通道。
对于前视图的量化处理,这里采用类似VeloFCN的前视图投影方法。将整个点云场景看成是一组柱坐标系上的点集,将其量化投影到一个二维的特征图位置上。具体的计算方法是根据点的水平方向以及垂直方向的角度来确定其二维特征图上的位置,计算公式为: c = [ a r c t a n ( y / x ) / ∆ θ ] , r = [ a r c t a n ( z / ( s q r t ( x 2 + y 2 ) ) ) / ∆ φ ] c=[arctan(y/x)/∆θ],r=[arctan(z/(sqrt(x^2+y^2)))/∆φ] c=[arctan(y/x)/∆θ],r=[arctan(z/(sqrt(x2+y2)))/∆φ]。这里和VeloFCN的投影公式稍有不同,但是本质上是一样的,利用的是相同的角度。在确定了点集在二维特征上的投影位置后,就需要对相应位置进行属性值填充。这里填充的是点的高度,深度以及反射强度。那么,对于整个二维特征图的channels本质上就是点云的高度图,深度图以及反射强度图。这里只有位置投影是量化处理,具体的特征值填充不涉及量化过程,因为是直接根据点属性进行填充的。所以,对于来着前视图的投影特征通道是3,分别是Height、Distance、Intensity。
至此完成了点云在鸟瞰图和前视图的二维特征量化处理,就利用卷积网络进行特征提取(MV3D这里使用的是VGG作为特征提取的Backbone)。具体来说,对于每个模态的特征,都用VGG网络进行8倍下采样提取特征,再经过4倍上采样获取ROI处理前的特征图。
MV3D是一个Two-Stage的网络结构,采样来自鸟瞰图的特征来进行候选框的生成。使用鸟瞰图进行候选框的提取相比图像和前视图具有几个优势:1)保留了长宽尺寸;2)避免视图中的遮挡问题;3)垂直位置变化不大。在候选框的生成中,主要回归的参数中心点位置与边框尺寸(x,y,z,l,w,h),为了简化处理流程先忽视方向的回归。而MV3D采用的是基于anchor的方法(anchor-based),需要对先验框(prior boxes)进行设计,这里对(l,w)取 {(3.9,1.6),(1.0,0.6)} 中的值,并且高度h被设置为1.56m,(x,y) 是鸟瞰特征图中变化的位置,z可以根据相机高度和物体高度计算,并设置0°与90°两个方向,所以对于每个特征点拥有4种先验框,进行这种简化的方法对候选框进行回归(其中回归的是xyz的偏移量以及lwh的相对尺寸)可以让训练更加容易。
尽管如此,量化得到的二维鸟瞰图中目标框的像素太小。一个方法是提高输入的分辨率但是会占用较大的计算量;另外一种方法是对VGG提取出来的特征进行2倍上采样处理。利用pixel-wise的特征分别进行分类与边界框回归,获取预测的3d候选框,这里就是一个经典的RPN操作,与2d检测算法Faster RCNN是一样的(鸟瞰图上的2d iou>0.7设置为正样本,<0.5设置为负样本,在两者之间则丢弃)。但由于点云数据比较稀疏,这里的pixel-wise特征会产生较多的空anchor,MV3D这里通过点占用图上计算积分图像来删除这些空锚(empty anchor)来减少计算量。随后进行鸟瞰图上的2d nms处理提取top 2k个候选框,这里需要注意一下虽然是在2d上进行nms筛选,但是候选框还是3d的,至此完成了候选框的生成。
2.2 区域融合网络
对这里来自Lidar坐标系下预测的3d候选框,可以投影回去鸟瞰图、前视图以及RGB图像上的2d位置,获得对应模态上的2d候选框,这里我认为是MV3D中最重要的一步。本质上就是3d候选框在鸟瞰图、前视图、RGB图像中的2d位置表示,这一步是可以做到的。那么接下来就是Two-stage的roi操作了,在不同模态中根据投影映射的2d候选框在上采样4x的特征图(feature map)中找到对应映射关系的每一个特征矩阵,将这些对应2d候选框相应位置的特征矩阵进行ROI pooling统一池化成相同大小(尺度一致),至此就获得了相同候选框在不同模态上的roi pooling特征表示。ps:对Faster RCNN详细介绍
对相同候选框在多个模态上的roi特征表示进行融合有多种方法,如下所示。这里MV3D采用阶段式融合的方法,来获取最后的候选框特征(proposal featue)。通过一下的数学公式描述的比较清楚:f0 =fBV ⊕ fFV ⊕ fRGB; fl =H^BV_l (fl−1) ⊕H^FV_l(fl−1) ⊕H^RGB_l(fl−1), ∀l = 1, · · · , L。
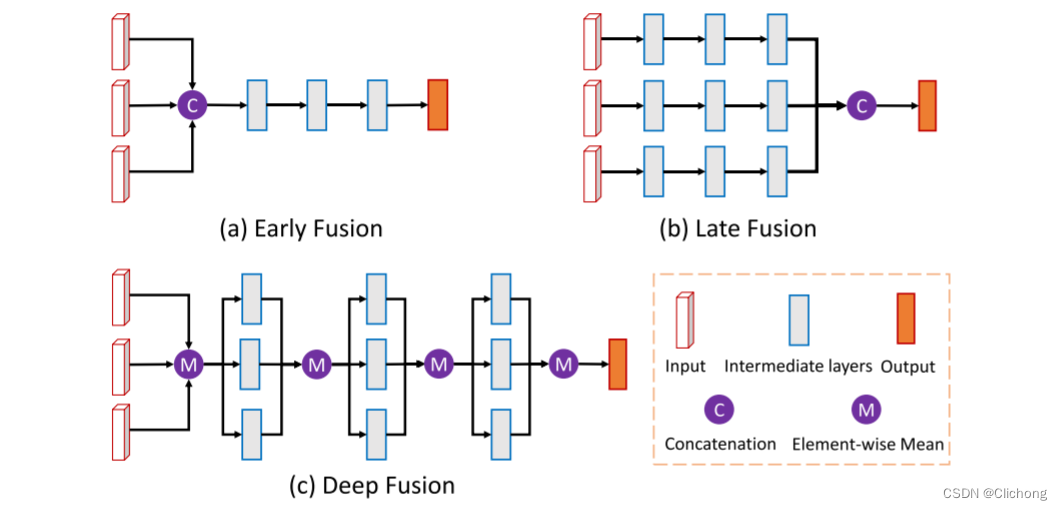
对来自多模态的roi特征进行阶段性融合后,就可以进行最后的边界框预测。MV3D对ground truth的回归目标是8个角点: t = (∆x0, · · · ,∆x7,∆y0, · · · ,∆y7,∆z0, · · · ,∆z7)。这24维度vector编码通过对角线长度归一化进行角偏移。但是很显然,利用24维度信息来预测8个角点时存在信息冗余(很显然通过两个对角点就可以表示一个3d框,所以信息是冗余的),但是在实验中发现这种编码方法比中心和大小编码方法效果更好,而且8个角点包含了方向信息,可以通过8个角点来计算方向。训练过程中同样利用的是鸟瞰图的iou重叠分配正负样本,如果iou>0.5则设置为正样本,反正就是负样本。在推理过程中,将3D框投影到鸟瞰图中以计算iou,设置iou阈值为0.05来去除冗余框,以确保对象在鸟瞰中不会占用相同的空间。
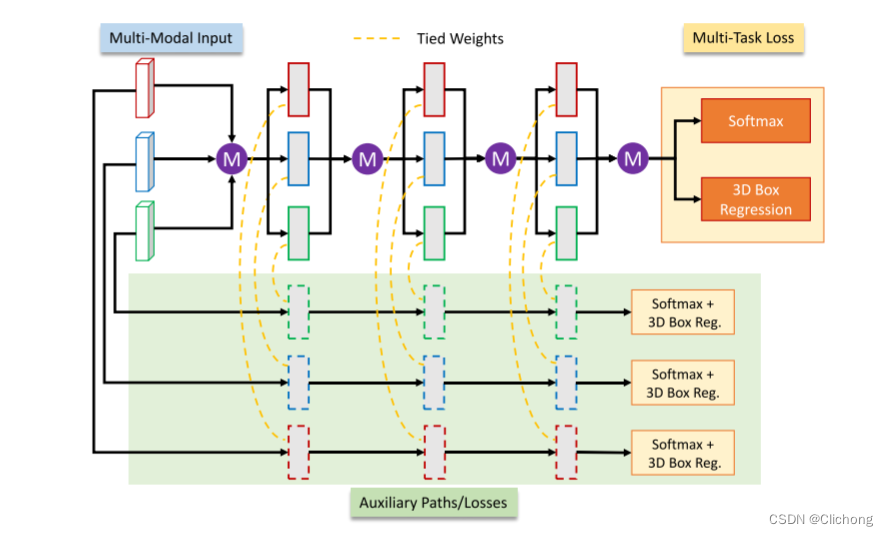
此外,MV3D还设置了两个正则化方法,分别是丢弃路径训练(drop-path training)和辅助损失训练(auxiliary losses)。其中的随机丢弃分为全局丢弃或者是局部丢弃,全局丢弃是在某一次训练中可能只训练单一模态;而局部丢弃是对每个模态的融合处理节点以一定概率丢弃,但起码会保留一个。在辅助损失中,层数一致结构一致且权重相同但取消了融合模块,独立进行结果的推理,最后损失结构与主网络进行加权平均,结构如下图所示。
3. 实验结果
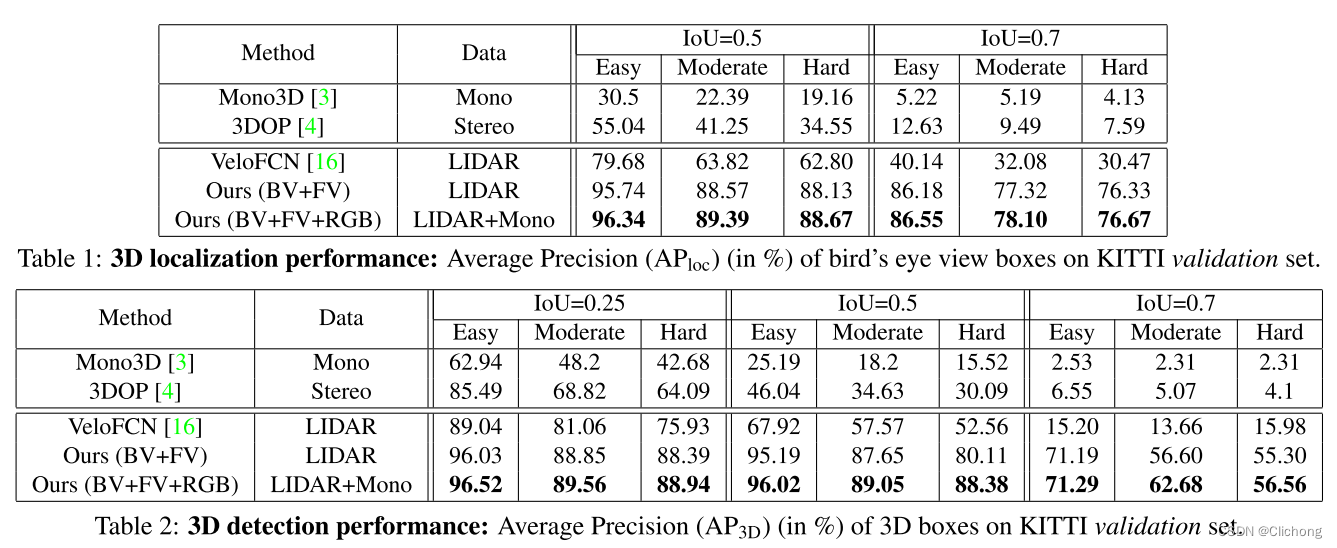
在MV3D的实验结果中可以看出VeloFCN的预测框其实置信度不会太高,在iou设定为0.7后出现了性能崩塌的情况,MV3D相比之下性能鲁棒一点。无论是鸟瞰图上的2d检测还是点云上的3d检测在当时都达到的不错的性能。
通过消融实验,也证实了BEV+FV+RGB三中模态的融合在性能的提高上是最佳的,同时层级式的roi特征容易+辅助损失也带来了不错的提升,不过个人感觉这种层级式的elemnet-wise mean不是特别雅光,不知道利用concat是否会有更好的效果。同时,对于不同模态的特征量化存在一定的信息丢失,如何进一步减少信息的损失进行量化,会不会也能提升网络的精度。




![[附源码]SSM计算机毕业设计茶园文化交流平台论文JAVA](https://img-blog.csdnimg.cn/f1b00d03b89446a98832e89241035775.png)