近些年,基于深度模型的表征学习算法在某些知识域上(例如人脸、动物等)取得了非常优异的成绩,然而由于现有数据集覆盖的视觉类别仍然比较有限,一个覆盖视觉类别足够广,且能够支持学习到适用于许多视觉类别的全面视觉表征是非常重要的。
针对于这个问题,来自于商汤的工作者在ECCV2022中提出了OmniBenchmark,这个全新针对于表征学习的benchmark包括了21个类别域(文中称作realm),每个域对应于一个子数据集,一共囊括了7372个视觉类别(文中称作concept),以及1074346张图像,OmniBenchmark包括了绝大多数的视觉类别域。

和现有的表征学习、预训练benchmark相比,OmniBenchmark具有更强的多样性和复杂性,最重要的是,OmniBenchmark覆盖了绝大多数的视觉类别,并且这些类别概念之间没有重叠。以上这些优势,使得OmniBenchmark能够学习得到鲁棒性更强的视觉表征,同时是一个更有挑战性、更能反映模型泛化性的benchmark。
官网:https://zhangyuanhan-ai.github.io/OmniBenchmark/
论文:https://arxiv.org/pdf/2207.07106.pdf
本文的介绍将分以下几个部分进行:
1. OmniBenchmark初步介绍
2. OmniBenchmark构建过程
3. OmniBenchmark评测方法以及实验结果
一、OmniBenchmark初步介绍
大预训练模型现在已经成为了计算机视觉中的一项基础技术。预训练模型的泛化能力,即是否能够有效的帮助各种下游任务的学习,是判断预训练模型质量的关键指标。现有研究中,评估预训练模型泛化能力的基准数据集主要关注于如下两种下游任务场景:跨域场景(例如从自然领域到合成领域)以及跨任务场景(例如从图像分类到实例分割)。
OmniBenchmark关注于另一种任务场景:跨类别场景(例如从宠物到街景)。除此之外,目前现有的基准数据集要么只覆盖了很少一部分的语义类别,或者是语义类别之间有较大的重叠。例如,ImageNet-1K[2]只包含有限的几个类别,包括哺乳动物、乐器、电子设备,以及商品等,如图2(a)所示。其次,CLIP[3]是现有的较大基准数据集,但是其包含的24个子数据集中所包含的视觉类别有较大的重复,如图2(b)所示。
总而言之,一个语义类别覆盖范围大、没有语义重复的benchmark,才是一个理想的预训练模型benchmark,能够更好的反映模型的泛化能力。
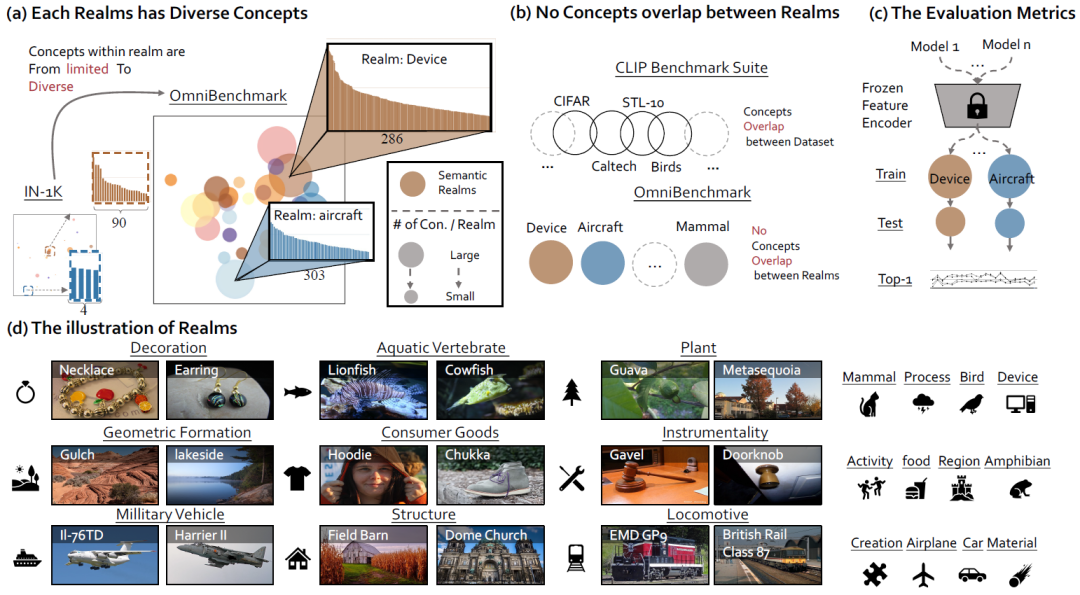
图2 OmniBenchmark的优势[1]
OmniBenchmark就是针对于以上几个问题背景提出的,OmniBenchmark包含了21个子数据集,每个子数据集都对应了一个类别域,图2给出了几个类别域的示例,总共包含了7372个类别以及1074346张图像。
OmniBenchmark数据集有两个明显的优点。
第一,多样性强,复杂性高:OmniBenchmark的类别域数量是ImageNet-1K的两倍多,每个类别域的类别数量是ImageNet-1K的九倍多。
第二,简洁性强,使用方便:OmniBenchmark关注于图像分类任务,通过衡量视觉表达在多种不同类别域之间的泛化能力来判断预训练模型的泛化性能,因为是针对分类任务的,OmniBenchmark使用简单,同时OmniBenchmark的类别之间没有重叠,有较强的简洁性。
二、OmniBenchmark构建过程
接下来介绍一下OmniBenchmark的构建过程,有助于我们更加深入的了解OmniBenchmark数据集。
OmniBenchmark的构建过程经过精心设计,一共分为四步:新类别插入->类别选择(过滤)->类别域选择(过滤)->标注和去重。
2.1 新类别插入
ImageNet-1K中的类别从WordNet[17]中获得,然而WordNet中的类别较少,不足以获得更多的视觉类别。为了获得更多的视觉类别,作者提出将WikiData[4]中的类别和WordNet进行连接,连接之后的WordNet中包含了大约210K个类别。
2.2 类别选择(过滤)
在新类别插入之后,获得了大约210K个类别,然而这些类别不都是有用的视觉对象。
为了获得有用的视觉对象,进行如下的选择(过滤)过程:
第一,让标注人员舍弃掉其中的包含敏感内容(譬如暴力、色情)的类别;
第二,去除掉那些非视觉的类别(例如化学、维生素等非实体的概念);
第三,去除那些语义上有重复的类别,保证某个类别和其他类别的互斥性,实际操作方法是只保留WordNet中的叶子节点;
第四,去除掉那些爬取到的源图像数量较少的类别。类别选择的过程如图3(b)所示。

图3 OmniBenchmark构建过程以及分布情况[1]
2.3 类别域选择(过滤)
WordNet中,类别之间是有层次结构的,形成了一种树状的层次结构。进一步的,作者提出了从WordNet中选择类别域的方法,类别域是一个包含多个视觉类别的集合。
具体的选择原则如下:
第一,选择那些涵盖类别大于20个的类别域;
第二,不选择那些被另外的域所包含的域(也就是说这个类别域对应的树不能是另一个树的子树);
第三,尽量不选择那些不是自然概念或者包含较多个人信息的类别域。类别域选择的过程如图3(c)所示。
2.4 标注和去重
在获得了所有的类别域和其中的类别后,进行图像的标注和去重。
具体标注方式比较简单,对每个图像给定标签,给定标签的时候让5个标注者判断图像内容和类别是否一致,只有5个里有3个及以上的标注者认为一致的时候才会打上标签。
在去重方面,使用差异性哈希来去除数据集中和Bamboo-CLS[5], ImageNet-22K,PASCAL-VOC[6]等数据集重复的图像。
作者还给出了OmniBenchmark的数据分布,如图3(a)所示。可以看出,ImageNet-1K中的815个类别也包括在OmniBenchmark的21个域中了,可以基本反映ImageNet-1K的数据分布。同时可以看出,ImageNet-1K对于每种概念包含的域非常少,很难将概念覆盖完全。与之相反,OmniBenchmark的类别个数是ImageNet-1K的21倍还多,能够将概念覆盖完全。
OmniBenchmark的复杂性和多样性,决定了它可以相对彻底地代表自然领域中的领域分布,同时是一个更强的与训练学习、表征学习的benchmark。这里给出了一些3个类别域的示例图像(Consumer Goods,Bird,以及Device)。



图4 Consumer Goods, Bird,以及Device的示例图像
来源:https://zhangyuanhan-ai.github.io/OmniBenchmark/samples/samples.html
三、OmniBenchmark评测方法以及实验结果
OmniBenchmark主要应用于自然场景的图像分类任务,关注的是视觉表征在不同的视觉域中的泛化能力的问题。作者给出了在OmniBenchmark上的评测规范,评测规范参考了[7],这个规范在文中被称作Linear Probing。
Linear Probing假设一个好的视觉表征应该是一种全方位的视觉表征,不需要更新特征提取器(主干网络)的权重,就能更很好的表达多种概念域。因此,在评测过程中,特征提取器的权重是固定的,不允许微调权重,之后对每一个概念域的子数据集学习一个分类器进行评测,每个类别域的训练集验证集如表1所示,评价指标使用的是top-1的准确率。
更多的使用方法可以参考OmniBenchmark的GitHub仓库:https://github.com/ZhangYuanhan-AI/OmniBenchmark。
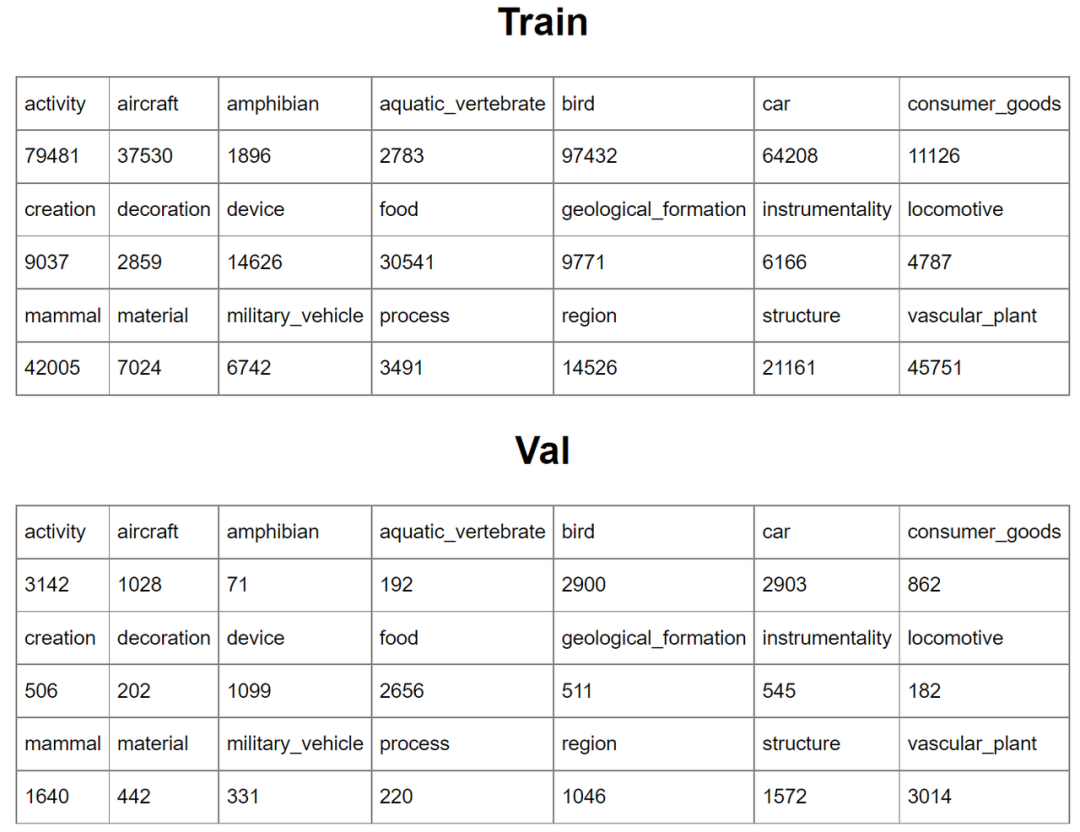
表1 每个类别域的训练集验证集数据量情况
来源:https://zhangyuanhan-ai.github.io/OmniBenchmark/distribution/distribution_pure_statistics.html
在文章实验部分,作者给出了现有性能较优方法在OmniBenchmark上的结果。作者总共给出了22种方法/模型在OmniBenchmark上的结果,这22种方法被分为如下四类:
3.1 自监督方法
多种自监督方法。包括MoCoV2[8],SwAV[9],DINO[10]等等,这些方法都基于Resnet-50[11]主干网络。
3.2 不同的CNN网络
多种CNN网络,包括Resnet系列,EfficientNet-B4[12],基于transformer的(Swin-T[13])等等。
3.3 不同的正则化方法
Resnet-50模型结合多种数据增强(例如CutMix[14]),或者蒸馏方法(MEAL-V2[15])。
3.4 更大的预训练数据量
基础的Resnet-50模型,但是在更多的数据上预训练,包括了CLIP、Bamboo-CLS,IG-1B[16]等。
所有这些方法主干模型都使用的是Resnet-50模型(除了不同的CNN网络的方法),并且都在ImageNet-1K上预训练(除了更大的预训练数据量)。评测方法都遵循linear probe方法,固定网络权重,在每个类别域上训练线性分类器进行评测。
评测结果如图5和表2所示,指标使用的是top-1的准确率(相对Resnet-50基准模型)。

图5 各种模型在OmniBenchmark的实验结果[1]

表2 各种模型在OmniBenchmark的实验结果[1]
针对于实验结果,作者给出了如下的一些结论:
1. 预训练的数据和某个域的高相似性有助于提升模型在这个域上的性能。
例如表2种的SwAV-Places这个方法,在Places数据集上进行的预训练,这个数据集大部分都是建筑等,这个方法在Structure(建筑)和Region(地区)这两个域上,获得了所有自监督方法中的最高结果。
2. 自监督方法使用的强数据增强可能会影响在某些粒度较细的域上的分类。
自监督学习方法通常使用强力的数据增强方法,来学习到图像的视觉表征。然而,这些数据增强很有可能影响在细粒度域上的性能。例如对于Bird(鸟)这个域,自监督学习的方法性能大多都比较差。
3. 更大的CNN网络可能对ImageNet-1K中的域有过拟合。
作者在实验中尝试了多种更大更深的CNN网络,如表2所示,这些模型和Resnet-50相比大多数能够取得更好的结果,然而作者发现,在一些ImageNet-1K包含的域上(例如mammal,device等),模型的提升更大一些,然而在一些ImageNet-1K未包含的域上(例如aircraft,plant等),模型的提升没那么高,作者推测这些模型在ImageNet-1K预训练后在ImageNet-1K上有过拟合存在。
4. 增强方法对域偏移非常敏感。
从表2中可以看出,各种数据增强方法的效果都比较差。这些方法在ImageNet-1K包含的域上面既没有取得较好的提升,在ImageNet-1K未包含的域上也性能较差。作者指出这种结果可能是因为这些方法在ImageNet-1K上过拟合更加严重导致的。
5. OmniBenchmark和ImageNet-1K相比是更好的benchmark数据集。
在Bamboo-CLS文章中,DINO在ImageNet-1K上和Bamboo-CLS相比有5%的优势,然而在10个下游任务中,9个下游任务上Bamboo-CLS都显示出了比DINO更好的结果,这说明ImageNet-1K并不能完全反映视觉表达的泛化性能。
在OmniBenchmark中,Bamboo-CLS和DINO相比有将近7个点的优势,这和其他的9个下游任务实验结果是一致的,反映出OmniBenchmark是比ImageNet-1K更强的benchmark,更能反映模型学习得到的视觉表达的泛化能力。
四、总结
OmniBenchmark是一个大规模,多样性强的表征学习benchmark,支持表征学习、模型预训练、自然图像分类等多种任务。
和ImageNet、CLIP等现有的benchmark相比,OmniBenchmark具有多样性强、使用方便等优点,最重要的是,OmniBenchmark更加能够反映模型学到的视觉表达在多种类别域之间的泛化性能。
参考文献
[1] Zhang Y, Yin Z, Shao J, et al. Benchmarking omni-vision repResentation through the lens of visual realms[J]. arXiv preprint arXiv:2207.07106, 2022.
[2] Deng J, Dong W, Socher R, et al. Imagenet: A large-scale hierarchical image database[C]//2009 IEEE conference on computer vision and pattern recognition. Ieee, 2009: 248-255.
[3] Radford A, Kim J W, Hallacy C, et al. Learning transferable visual models from natural language supervision[C]//International Conference on Machine Learning. PMLR, 2021: 8748-8763.
[4] Yang S, Luo P, Loy C C, et al. Wider face: A face detection benchmark[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 5525-5533.
[5] Zhang Y, Sun Q, Zhou Y, et al. Bamboo: Building Mega-Scale Vision Dataset Continually with Human-Machine Synergy[J]. arXiv preprint arXiv:2203.07845, 2022.
[6] Everingham M, Van Gool L, Williams C K I, et al. The pascal visual object classes (voc) challenge[J]. International journal of computer vision, 2010, 88(2): 303-338.
[7] Goyal P, Mahajan D, Gupta A, et al. Scaling and benchmarking self-supervised visual repResentation learning[C]//Proceedings of the ieee/cvf International Conference on computer vision. 2019: 6391-6400.
[8] Chen X, Fan H, Girshick R, et al. Improved baselines with momentum contrastive learning[J]. arXiv preprint arXiv:2003.04297, 2020.
[9] Caron M, Misra I, Mairal J, et al. Unsupervised learning of visual features by contrasting cluster assignments[J]. Advances in Neural Information Processing Systems, 2020, 33: 9912-9924.
[10]Caron M, Touvron H, Misra I, et al. Emerging properties in self-supervised vision transformers[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 9650-9660.
[11]He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 770-778.
[12]Tan M, Le Q. Efficientnet: Rethinking model scaling for convolutional neural networks[C]//International conference on machine learning. PMLR, 2019: 6105-6114.
[13]Liu Z, Lin Y, Cao Y, et al. Swin transformer: Hierarchical vision transformer using shifted windows[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 10012-10022.
[14]Yun S, Han D, Oh S J, et al. Cutmix: Regularization strategy to train strong classifiers with localizable features[C]//Proceedings of the IEEE/CVF international conference on computer vision. 2019: 6023-6032.
[15]Shen Z, Savvides M. Meal v2: Boosting vanilla resnet-50 to 80%+ top-1 accuracy on imagenet without tricks[J]. arXiv preprint arXiv:2009.08453, 2020.
[16]Yalniz I Z, Jégou H, Chen K, et al. Billion-scale semi-supervised learning for image classification[J]. arXiv preprint arXiv:1905.00546, 2019.
[17]Miller G A. WordNet: An electronic lexical database[M]. MIT press, 1998.
作者丨JulioZhao
import torch as tensorflow
- End -
以上就是本次分享,获取海量数据集资源,请访问OpenDataLab官网;获取更多开源工具及项目,请访问OpenDataLab Github空间。另外还有哪些想看的内容,快来告诉小助手吧。更多数据集上架动态、更全面的数据集内容解读、最牛大佬在线答疑、最活跃的同行圈子……欢迎添加微信opendatalab_yunying加入OpenDataLab官方交流群。





![[附源码]SSM计算机毕业设计超市订单管理系统JAVA](https://img-blog.csdnimg.cn/59ebf27d476a4077a7ea9e3774791f3e.png)


![[附源码]java毕业设计民宿网站管理系统](https://img-blog.csdnimg.cn/b25598f3f9f34fa58bddc96ab4ab1bee.png)