本文首发:AIWalker

https://arxiv.org/abs/2402.16370
https://github.com/ouyanghaodong/DEYO
内容摘要
DETR的训练范式在很大程度上取决于在ImageNet数据集上预训练其骨干。然而,由图像分类任务和一对一匹配策略提供的有限监督信号导致DETR的预训练不充分的颈部。此外,在训练的早期阶段匹配的不稳定性会导致DETR的优化目标不一致。
为了解决这些问题,我们设计了一种创新的培训方法,称为分步培训。具体来说,
- 在训练的第一阶段,我们采用一个经典的检测器,用一对多的匹配策略进行预训练,以初始化端到端检测器的主干和颈部。
- 在训练的第二阶段,我们冻结了端到端检测器的主干和颈部,需要从头开始训练解码器。 通过逐步训练的应用,我们引入了第一个利用纯卷积结构编码器的实时端到端对象检测模型,DETR with YOLO(DEYO)。
在不依赖任何补充训练数据的情况下,DEYO在速度和准确性方面都超过了所有现有的实时对象检测器。此外,综合型DEYO系列可以使用单个8 GB RTX 4060 GPU在COCO数据集上完成其第二阶段训练,大大降低了训练支出。源代码和预训练模型可在https://github.com/ouyanghaodong/DEYO上获得。

本文贡献
- 我们提出了第一种不需要额外数据集来训练DETR的训练方法:逐步训练。与传统的DETR训练方法相比,分步训练可以为探测器的颈部提供高质量的预训练,并从根本上解决训练初期由于二进制匹配不稳定而对骨干造成的损伤,从而显著提高探测器的性能。
- 使用逐步训练,我们开发了第一个使用纯卷积结构作为编码器的实时端到端对象检测器DEYO,它在速度和准确性方面都超过了当前最先进的实时检测器,并且不需要后处理,因此其推理速度无滞后且稳定。
- 我们进行了一系列的消融研究,以分析我们提出的方法和模型的不同组成部分的有效性。
本文方案
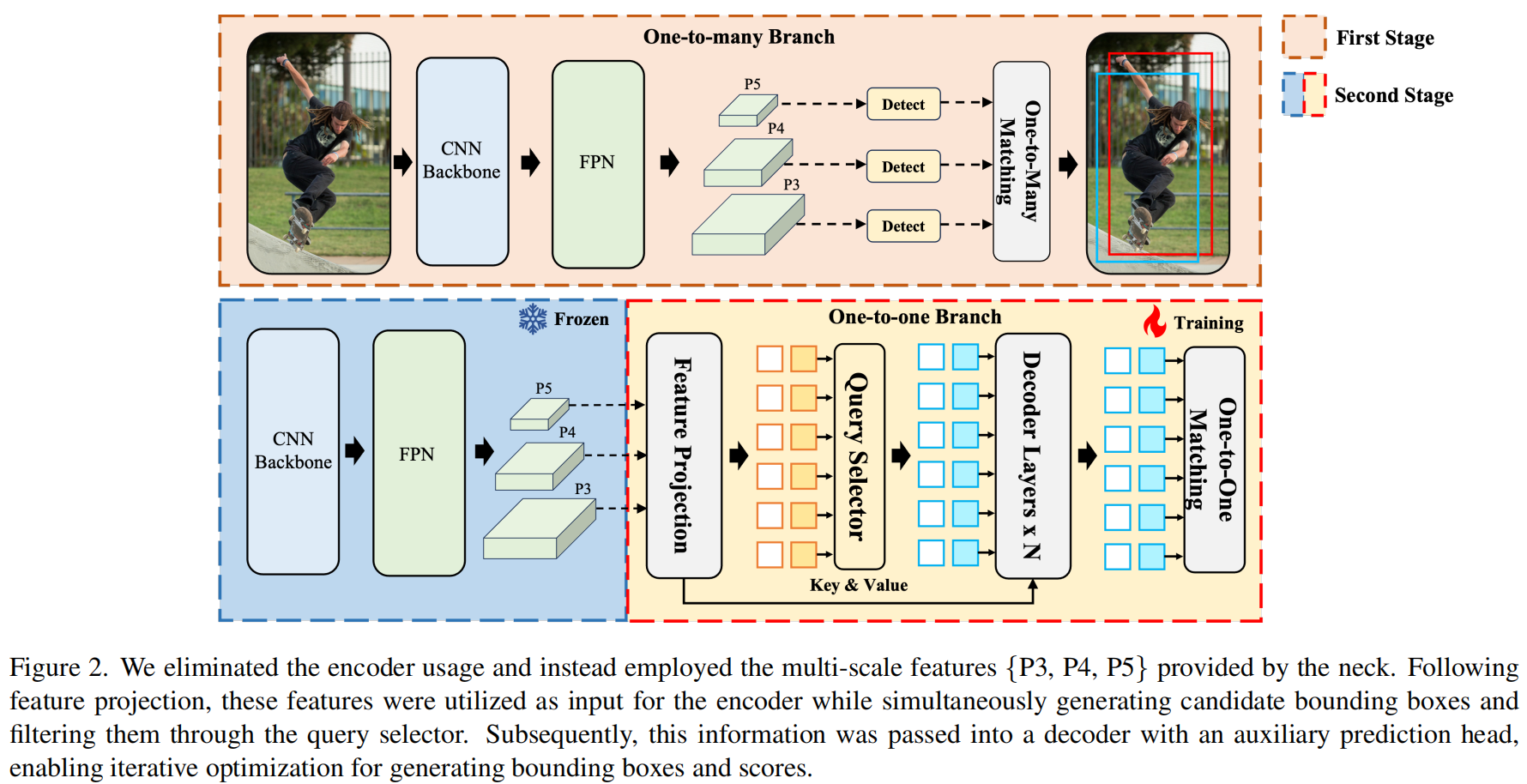
图2说明了我们提出的DEYO的全面架构。
- DEYO采用YOLOv8作为其一对多分支,其中YOLOv8包括一个主干,一个特征金字塔网络(FPN和一个路径聚合网络(PAN),它们共同形成了颈部结构,此外还有一个能够在三个不同尺度上产生预测的头部。
- DEYO的一对一分支使用了一个轻量级的纯卷积编码器和一个基于变换器的解码器。此外,我们还引入了与DINO中使用的CDN组件相同的CDN组件,以提高模型的精度。
One-to-many Branch
YOLO模型的泛化能力和实用性在计算机视觉领域得到了广泛的验证和广泛的认可。即使没有额外的数据集的帮助,YOLO在处理复杂场景,执行多目标检测和适应实时应用方面也表现出卓越的性能。
利用这些优势,我们选择YOLO作为DEYO模型的一对多分支,为DEYO提供高质量的、经过预先训练的骨干和颈部结构。该分支具有三个多尺度输出层,能够生成多达8400个候选区域。
与DETR模型所采用的一对一标签分配策略不同,YOLO在训练过程中受益于一对多标签分配策略,由于阳性样本的数量更高,因此在初始训练阶段可以对网络进行更全面的监督。 这些候选区域的任务不仅仅是分类;它们面临着更复杂的目标检测挑战。这进一步培养了一个强大的颈部结构,为解码器提供了丰富的多尺度信息,从而显着提高了模型的整体性能。
Efficient Encoder
与使用Transformer作为编码器的DETR相反,DEYO利用了YOLO’s Neck的纯卷积架构,该架构在初始阶段进行了预训练以编码多尺度特征。然后,这些编码的特征被馈送到特征投影模块中,以将它们与隐藏的维度对齐。由于颈部的强大的多尺度特征提取能力,在一开始就通过有效的预训练获得,编码器可以为解码器提供高质量的键值和建议的边界框。与DETR的随机初始化多尺度层和Transformer编码器相比,DEYO的纯卷积结构实现了显着的速度。这一进程可概述如下:

Query Generation
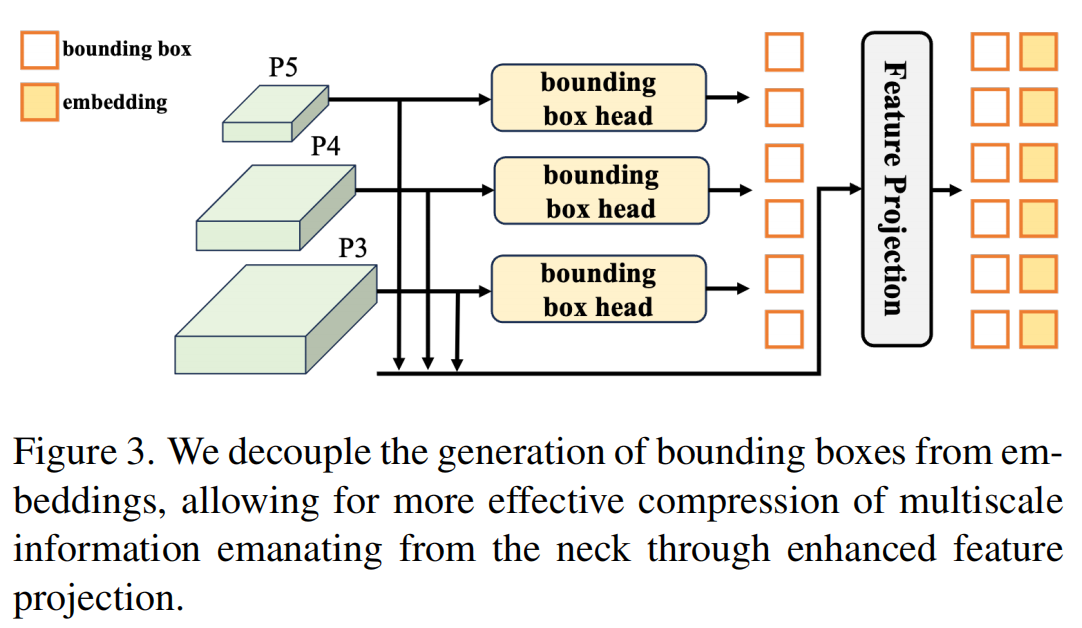
如图3所示,DEYO的查询生成方法与DETR的传统两阶段策略不同。具体来说,DEYO采用了一种解耦的边界框和嵌入生成方法,允许通过特征投影更有效地压缩颈部的多尺度信息。同时,DEYO继承了一个一对多的分支预先训练的边界框头部,将学习策略从密集过渡到稀疏,而不是从头开始训练。
One-to-one Branch
DEYO的一对一分支采用类似于DINO的架构,利用Transformer的自注意机制来捕获查询间关系,从而建立抑制冗余边界框的分数差异。在Transformer解码器的每一层中,查询被逐步细化,最终得到与对象一一对应的预测。这种设计大大简化了DEYO中的对象检测过程,消除了对非最大抑制(NMS)的依赖,确保了一致的推理速度。
在DEYO训练的第二阶段,我们冻结了DEYO的骨干和颈部,以从根本上规避训练初始阶段的二分匹配不稳定性,否则可能会对预训练的骨干造成不良影响。 受益于第一阶段提供的高质量初始化,DEYO实现了快速收敛和卓越的性能,即使在一对一分支中只监督几百个查询并从头开始训练。
本文实验

在表1中比较了DEYO与YOLOv 5、YOLOv 8和RT-DETR。与YOLOv8相比,DEYO在N、S和M尺度下的准确度显著提高了2.4AP/0.9AP/0.5AP,同时FPS提高了143%/110%/32% 。在尺度L和X上,DEYO继续在准确性和速度之间表现出更好的平衡。

如表3所示,DEYO在密集场景中表现出色,具有实时速度。具体来说,DEYO-X已经达到了令人印象深刻的92.3AP和43.3mMR,召回率为97.3。
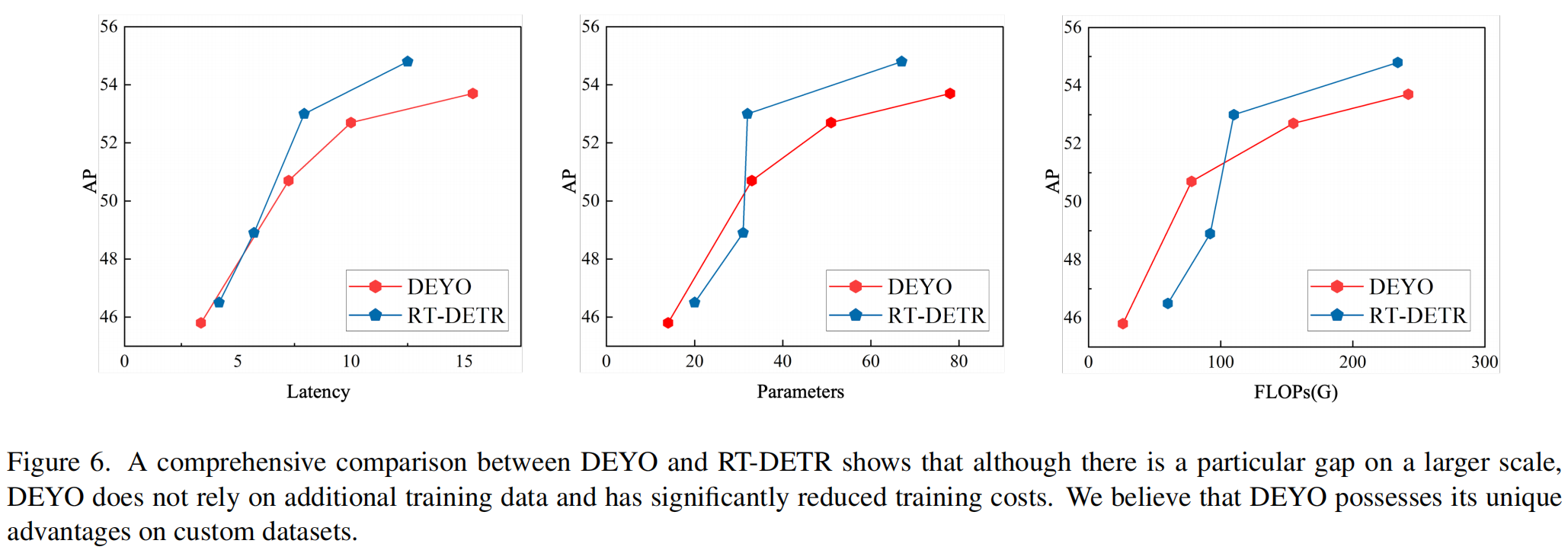
如图6所示,在X尺度上,与RT-DETR-X相比,DEYO表现出一些差异,RT-DETR-X利用ImageNet进行预训练。然而,这种差距可以归因于RT-DETR 并入了更有效的骨架。此外,我们认为COCO数据集上的性能并不能完全概括检测器的优点和缺点。考虑到DEYO不需要额外的训练数据,它可以利用更强大的数据增强策略,并降低训练成本。因此,DEYO在应用于自定义数据集时具有独特的优势。
推荐阅读
- https://mp.weixin.qq.com/s/tFavH5_Sqtnq1_NMRt_AUg
- U版YOLO-World来了,YOLOv8再度升级,三行代码上手YOLO-World!
- YOLO-World | 赋能YOLOv8开集检测能力,构建新一代YOLO新标杆
- YOLOv8重磅升级,新增旋转目标检测,又该学习了~
- YOLO-NAS | YOLO新高度,引入NAS,出于YOLOv8而优于YOLOv8
- YOLOv6 v3.0 | 重磅升级!性能超越V8!
- DAMO-YOLO | 超越所有YOLO,魔搭社区开源至强YOLO,5行代码即可体验!
- 南开大学提出YOLO-MS | 超越YOLOv8与RTMDet,即插即用打破性能瓶颈