目录
摘要
原理
总体结构图
RCS模块原理
代码实现
RCS-Based One-Shot Aggregation
代码实现
检测头改进
手动计算anchor代码
yaml文件
已详细修改的代码
程序启动命令
可论文指导 +V ------------> jiabei-545
往期推荐
摘要
凭借速度和准确性之间的出色平衡,尖端的 YOLO 框架已成为最有效的目标检测算法之一。然而, YOLO 网络的性能还有提升的空间。我们提出了 RCS 和 RCS 的一次聚合(RCS-OSA),它将特征级联和计算效率联系起来,以提取更丰富的信息并减少时间消耗。所提出的模型在速度和准确性上超越了YOLOv6、YOLOv7和YOLOv8。值得注意的是,与YOLOv7相比,RCS-YOLO的精度提高了1%,推理速度提高了60%,每秒检测到114.8张图像(FPS)。
原理
1、首先通过将 RepVGG/RepConv 与 ShuffleNet 相结合来开发 RepVGG/RepConv ShuffleNet (RCS),它受益于重新参数化,可以在训练阶段提供更多特征信息并减少推理时间。然后,我们构建了一个基于 RCS 的一次性聚合(RCSOSA)模块,该模块不仅允许低成本的内存消耗,而且还允许语义信息提取。
2、通过将开发的 RCS-OSA 和 RepVGG/RepConv 与路径聚合相结合,设计了 YOLO 架构的新骨干和颈部网络,以缩短特征预测层之间的信息路径。这促进了准确的定位信息快速传播到骨干网络和颈部网络中的特征层次结构。
总体结构图
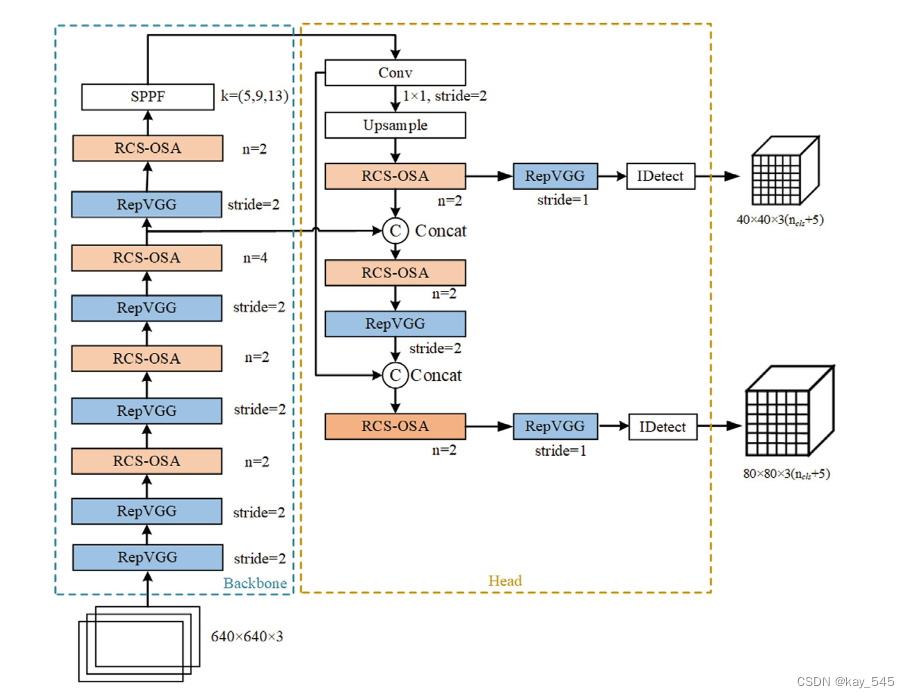
RCS模块原理
受ShuffleNet的启发,设计了一种基于通道shuffle的结构重参数化卷积。下图为RCS的结构示意图。
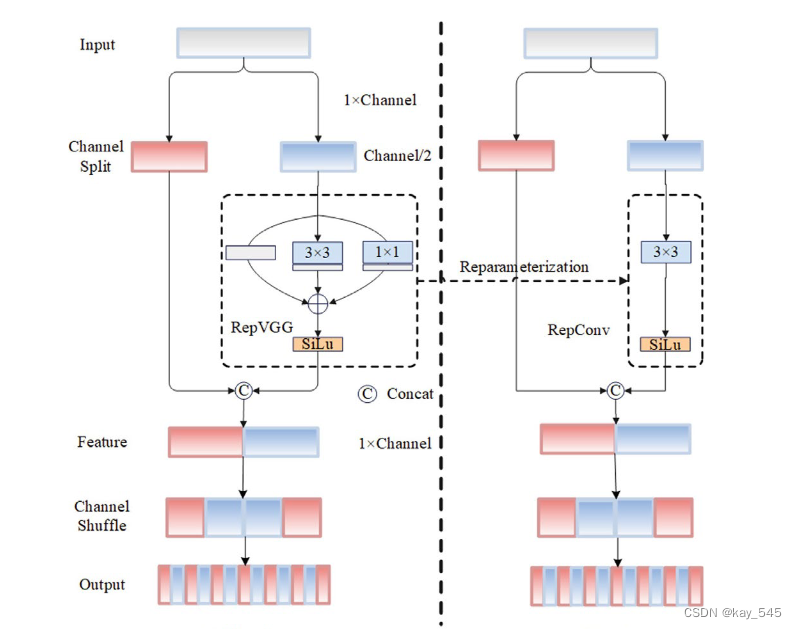
假设输入张量的特征维度为 C×H×W ,在通道分割算子之后,它被分为两个不同的通道张量,其维度相同C×H×W 。对于其中一个张量,我们使用恒等分支、1×1 卷积和 3×3 卷积来构造训练时 RCS。在推理阶段,使用结构重参数化将恒等分支、1×1 卷积和3×3 卷积转换为3×3 RepConv。多分支拓扑架构可以在训练时学习丰富的特征信息,简化的单分支架构可以节省推理时的内存消耗,实现快速推理。对其中一个张量进行多分支训练后,它以通道方式连接到另一个张量。通道混洗算子还用于增强两个张量之间的信息融合,从而可以以较低的计算复杂度实现输入的不同通道特征之间的深度测量。
代码实现
class RepVGG(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=3,
stride=1, padding=1, dilation=1, groups=1, padding_mode='zeros', deploy=False, use_se=False):
super(RepVGG, self).__init__()
self.deploy = deploy
self.groups = groups
self.in_channels = in_channels
padding_11 = padding - kernel_size // 2
self.nonlinearity = nn.SiLU()
# self.nonlinearity = nn.ReLU()
if use_se:
self.se = SEBlock(out_channels, internal_neurons=out_channels // 16)
else:
self.se = nn.Identity()
if deploy:
self.rbr_reparam = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,
stride=stride,
padding=padding, dilation=dilation, groups=groups, bias=True,
padding_mode=padding_mode)
else:
self.rbr_identity = nn.BatchNorm2d(
num_features=in_channels) if out_channels == in_channels and stride == 1 else None
self.rbr_dense = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,
stride=stride, padding=padding, groups=groups)
self.rbr_1x1 = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=stride,
padding=padding_11, groups=groups)
# print('RepVGG Block, identity = ', self.rbr_identity)
def get_equivalent_kernel_bias(self):
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)
kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)
return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
def _pad_1x1_to_3x3_tensor(self, kernel1x1):
if kernel1x1 is None:
return 0
else:
return torch.nn.functional.pad(kernel1x1, [1, 1, 1, 1])
def _fuse_bn_tensor(self, branch):
if branch is None:
return 0, 0
if isinstance(branch, nn.Sequential):
kernel = branch.conv.weight
running_mean = branch.bn.running_mean
running_var = branch.bn.running_var
gamma = branch.bn.weight
beta = branch.bn.bias
eps = branch.bn.eps
else:
assert isinstance(branch, nn.BatchNorm2d)
if not hasattr(self, 'id_tensor'):
input_dim = self.in_channels // self.groups
kernel_value = np.zeros((self.in_channels, input_dim, 3, 3), dtype=np.float32)
for i in range(self.in_channels):
kernel_value[i, i % input_dim, 1, 1] = 1
self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std
def forward(self, inputs):
if hasattr(self, 'rbr_reparam'):
return self.nonlinearity(self.se(self.rbr_reparam(inputs)))
if self.rbr_identity is None:
id_out = 0
else:
id_out = self.rbr_identity(inputs)
return self.nonlinearity(self.se(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out))
def fusevggforward(self, x):
return self.nonlinearity(self.rbr_dense(x))RCS-Based One-Shot Aggregation
此外,还设计了单次聚合(OSA)模块来克服 DenseNet 中密集连接的低效率,通过用多感受野表示多样化特征并在最后的特征图中仅聚合所有特征一次。 VoVNet V1 [14 ] 和 V2 [15 ] 在其架构中使用 OSA 模块来构建轻量级和大规模目标检测器,其性能优于广泛使用的 ResNet 主干网络,具有更快的速度和更好的能源效率。
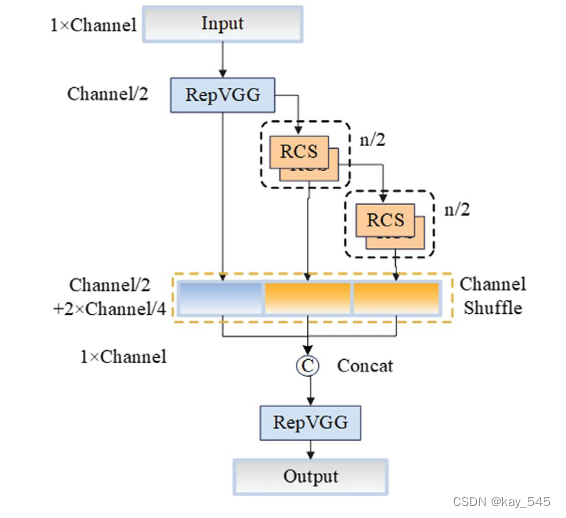
代码实现
class RCSOSA(nn.Module):
# VoVNet with Res Shuffle RepVGG
def __init__(self, c1, c2, n=1, se=False, e=0.5, stackrep=True):
super().__init__()
n_ = n // 2
c_ = make_divisible(int(c1 * e), 8)
# self.conv1 = Conv(c1, c_)
self.conv1 = RepVGG(c1, c_)
self.conv3 = RepVGG(int(c_ * 3), c2)
self.sr1 = nn.Sequential(*[SR(c_, c_) for _ in range(n_)])
self.sr2 = nn.Sequential(*[SR(c_, c_) for _ in range(n_)])
self.se = None
if se:
self.se = SEBlock(c2)
def forward(self, x):
x1 = self.conv1(x)
x2 = self.sr1(x1)
x3 = self.sr2(x2)
x = torch.cat((x1, x2, x3), 1)
return self.conv3(x) if self.se is None else self.se(self.conv3(x))检测头改进
为了进一步减少推理时间,我们将 RepVGG 和 Detect 组成的检测头数量从 3 个减少到 2 个。YOLOv5、YOLOv6、YOLOv7 和 YOLOv8 有 3 个检测头。然而,我们只使用两个特征层进行预测,将原来九个不同尺度的anchor数量减少到四个,并使用K-means无监督聚类方法重新生成不同尺度的anchor。这不仅减少了RCS-YOLO的卷积层数和计算复杂度,而且减少了推理阶段网络的整体计算要求和后处理非极大值抑制的计算时间。
Yolov5的检测目标分别从检测输出17,20,23
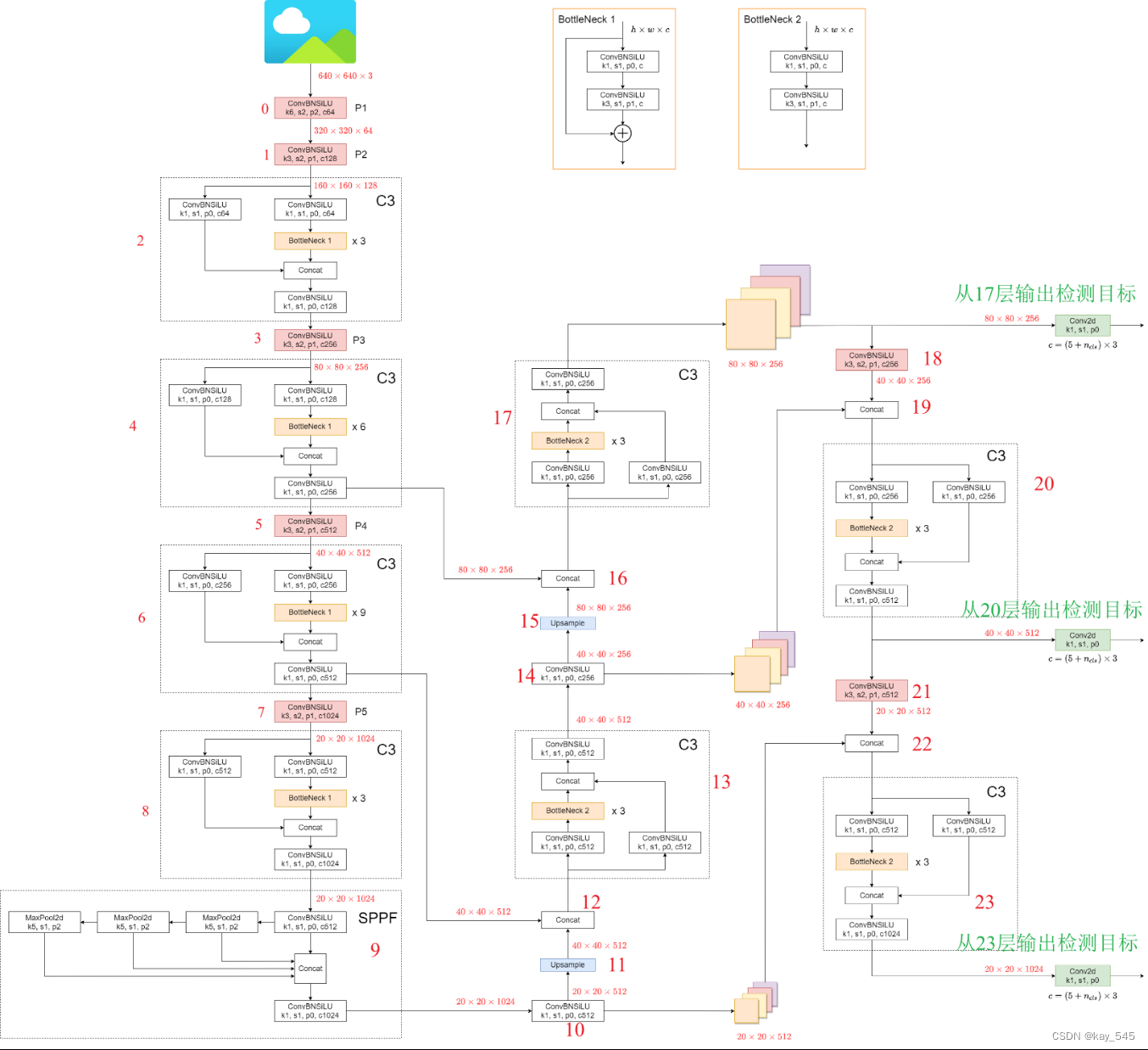
手动计算anchor代码
YOLO 手动计算anchor的值-CSDN博客不需要运行 kmeans.py,运行 clauculate_anchors.py 即可。创建程序两个程序 kmeans.py 以及 clauculate_anchors.py。会调用 kmeans.py 聚类生成新anchors的文件。kmeans.py 程序如下:这不需要运行,也不需要更改。如果报错,可以查看第 13 行内容。会生成anchors文件。https://blog.csdn.net/m0_67647321/article/details/136315355?spm=1001.2014.3001.5501
yaml文件
# RCS-YOLO v1.0 (Two heads)
# Parameters
nc: 1 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 0.75 # layer channel multiple
anchors:
- [87,90, 127,139] # P4/16
- [154,171, 191,240] # P5/32
# backbone
backbone: # 12462
# [from, number, module, args]
[[-1, 1, RepVGG, [64, 3, 2]], # 0-P1/2
[-1, 1, RepVGG, [128, 3, 2]], # 1-P2/4
[-1, 2, RCSOSA, [128]],
[-1, 1, RepVGG, [256, 3, 2]], # 3-P3/8
[-1, 2, RCSOSA, [256]],
[-1, 1, RepVGG, [512, 3, 2]], # 5-P4/16
[-1, 4, RCSOSA, [512, True]],
[-1, 1, RepVGG, [1024, 3, 2]], # 7-P5/32
[-1, 2, RCSOSA, [1024, True]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# head
head:
[[-1, 1, Conv, [512, 1, 1]], # 10
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[-1, 2, RCSOSA, [512]], # 12
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 2, RCSOSA, [512]], # 14
[-1, 1, RepVGG, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 2, RCSOSA, [768]], # 17
[14, 1, RepVGG, [512, 3, 1]],
[17, 1, RepVGG, [768, 3, 1]],
[[18, 19], 1, IDetect, [nc, anchors]], # Detect(P4, P5)
]
已详细修改的代码
链接: https://pan.baidu.com/s/1EOeZP5kJ92tVjZgFtM0Wdg?pwd=zk88 提取码: zk88
程序启动命令
单GPU
python train.py --workers 8 --device 0 --batch-size 32 --data data/br35h.yaml --img 640 640 --cfg cfg/training/rcs-yolo.yaml --weights '' --name rcs-yolo --hyp data/hyp_training.yaml多GPU
python -m torch.distributed.launch --nproc_per_node 4 --master_port 9527 train.py --workers 8 --device 0,1,2,3 --sync-bn --batch-size 128 --data data/br35h.yaml --img 640 640 --cfg cfg/training/rcs-yolo.yaml --weights '' --name rcs-yolo --hyp data/hyp_training.yaml可论文指导 +V ------------> jiabei-545
往期推荐
Yolov8有效涨点:YOLOv8-AM,添加多种注意力模块提高检测精度,含代码,超详细-CSDN博客
有效涨点,增强型 YOLOV8 与多尺度注意力特征融合,附代码,详细步骤-CSDN博客