本文为 「茶桁的 AI 秘籍 - BI 篇 第 16 篇」

文章目录
- 对 MovieLens 进行电影推荐
Hi,你好。我是茶桁。
前面两节课的内容中,我们从矩阵分解到 ALS 原理,依次给大家讲解了推荐系统中的一个核心概念。
矩阵分解中拆矩阵的背后其实是聚类。就说 k 等于几是人工设定的,所以跟聚类概念很像。就是要把人群划分成几类,把电影划成几类。k 等于 3 是自己去设定的,也可以把它拆成 k 等于 4、k 等于 5,都是一样的,是要完成聚类任务。
聚类不需要操心到底有哪些类型,它会自动的聚成这几类。这也是为什么把它称为隐分类。
「隐」就是我们知道它聚成了三种类型,但是不太清楚这三种类型具体的名称应该叫什么。所以它确实用了聚类的概念,至于为什么用了聚类概念,是因为最后学出来的类型是在 3 个维度上打分的,一个用户有 3 个维度的评分,一个商品也有 3 个维度评分。其实就相当于是把用户聚成了三类,商品聚成了三类。
或者换个角度,可以看一下
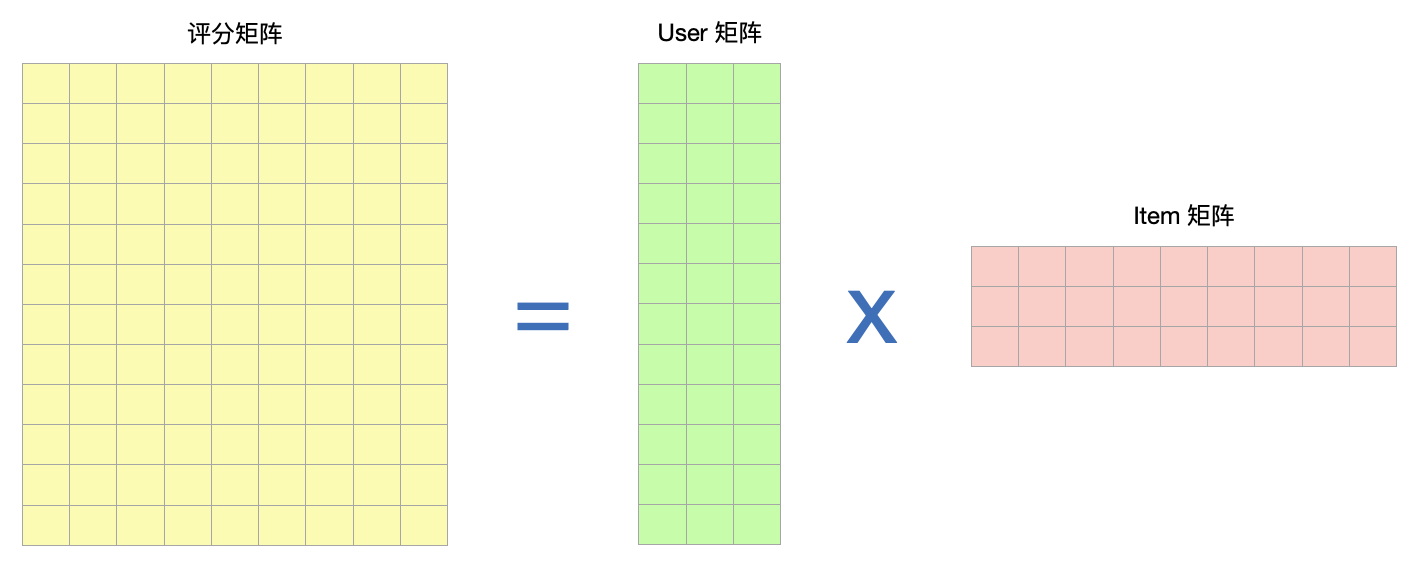
还是用之前的 12 * 9 的矩阵,以前一个用户的向量有 9 个维度,9 个维度还是比较多的,有可能每个维度不全。现在我们要把 9 个维度做成 3 个维度(k=3),这 3 个维度就变成了更稠密的压缩的维度,这个小的维度就是个降维。
所以用户要降成 3 个维度,商品也要降成相同的 3 个维度,它的概念都是一样的,大家都是在这个维度上面做一个抽象,这是为什么最开始我们给它画这个场景。用户商品中间这个隐分类我们把它称为 interest。
或者这个 k 就是个聚类方式。用户聚成了几种兴趣,那么商品也是聚成了相同的几种兴趣,大家都是在相同的这样的 3 个属性的维度上面去打分。用户的打分如果在 3 个属性上高那就代表你喜欢,商品上面高就代表这个类型的很强。
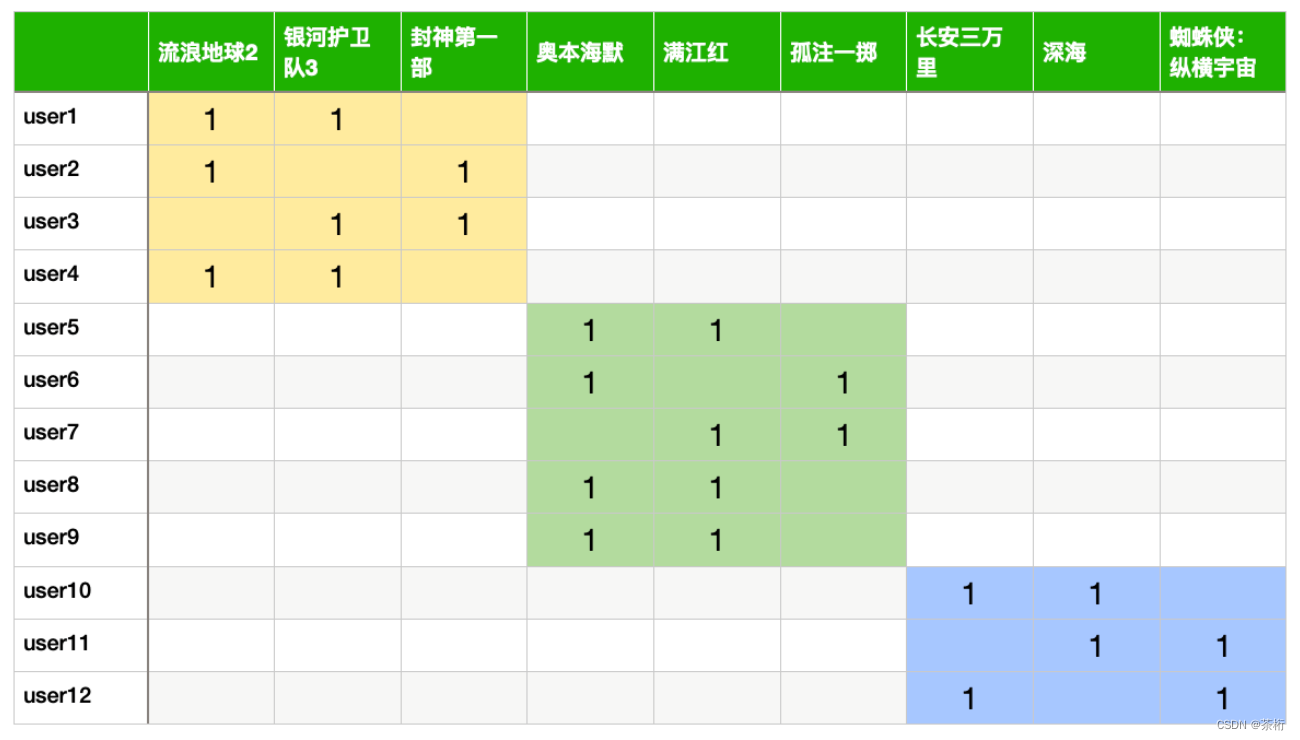
咱们来举个例子:一个用户的特效片是高的,封神第一部它在特效片上也是高的,剧情片和动画片它没有分吗?并不是,它也有分,也会有相关的一个分数。这样我们再进行计算的时候就更好的来进行计算了,就相当于把一个大维度降成了小维度。
那之前这些整个的就是给大家讲解的矩阵分解原理,原理还是要明白的。虽然最后工作的时候大部分内容都是调包,但是在这之前还是很有必要去了解一下它的原理。有些时候有可能一是面试的时候问,第二你调包的时候更知道它为什么要用到这个包,这个包背后逻辑是什么逻辑。
那这个包怎么调?有两种方式来调,一种就是大数据的方法,用 Spark。
Spark 是个大数据的一个平台,在 Spark 里面我们默认它是使用了一个 ALS。Spark 如果你未来感兴趣可以看一看,它有两个机器学习的库,一个叫 mllib 库,一个叫 ml 库。建议大家直接用 ml 库,也是官方推荐的。
mllib 库已经废弃掉了,3.0 版本之后不再维护了。所以大家直接用 ml 这个工具箱就 OK 了。两个一个很大的区别就是 ml 主要操作的是 DataFrame, mllib 操作的是 RDD,两个面向的数据集是不一样的。相较而言,ml 在 DataFrame 上的抽象级别更高,数据和操作耦合度更低。
第二点它使用起来已经做了更好的封装,就更像 sklearn。机器学习中大家都习惯用 sklearn,最开始进入机器学习也是调这个包,所以它就更像 sklearn 的接口使用起来衔接起来更顺畅一点。
如果你用 Python 代码,那也该大家找了一个在 Github 上的,有一个 ALS 类,可以直接引用这个类:
https://github.com/tushushu/imylu/blob/master/imylu/recommend/als.py
对 MovieLens 进行电影推荐
来看一下下面这个例子,数据集是 MovieLens,可以在这里去下载:https://www.kaggle.com/jneupane12/movielens/download
MovieLens 是一个电影的评分网站,上面有几十万的电影和很多的人的一些打分。
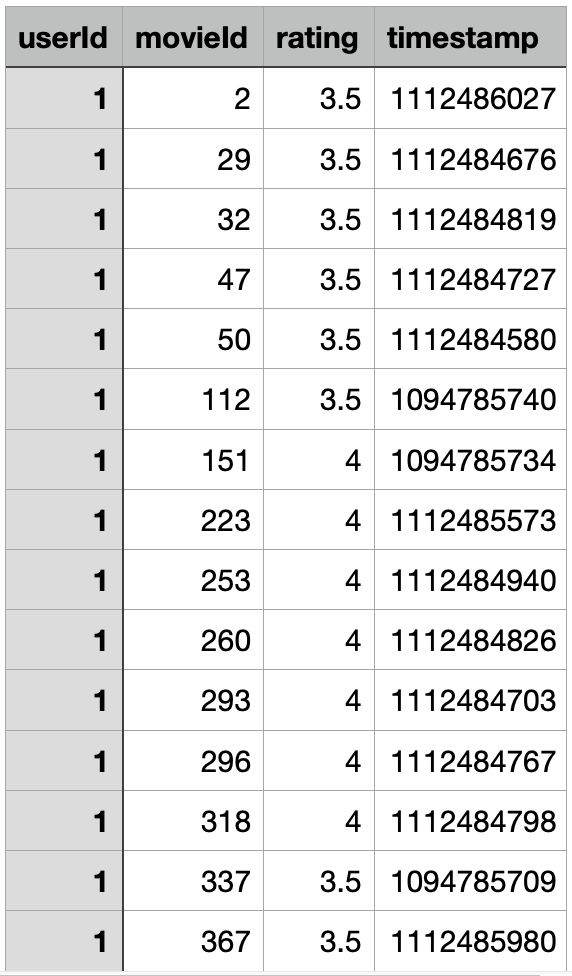
我们以其中一个人为例,他给这么多电影打了一些分数。整个数据集叫readings.csv,有四个字段,userId, movieId, rating 和 timestamp。
我们现在看一看这个矩阵,一个人打了这么多电影分数,那你觉得如果把它看成一个非常大的一个矩阵的话,这个矩阵是稀疏的还是稠密的呢?
虽然用户 1 给这么多电影打分,但实际上要知道电影其实会很多,可能有 10 万部,而你只打了 1,000 部,所以它还是个稀疏的。我们就需要猜出来那些没有打分的,比如说中间那些 id 为 3、4、28,这些都没有打分。
怎么做呢?我们来看看代码。这里就是封装好的一个类,它是一个矩阵的概念。里面具体代码大家可以去我的代码仓库里去查看源码。
它就是做了一个矩阵的相乘,还有矩阵的转质啊等等。中间都封装好了矩阵的乘法,封装了 ALS 类,后面使用过程中我们就直接调包就好了。
class Matrix(object):
def __init__(self, data):
self.data = data
self.shape = (len(data), len(data[0]))
def row(self, row_no):
return Matrix([self.data[row_no]])
def col(self, col_no):
m = self.shape[0]
return Matrix([[self.data[i][col_no]] for i in range(m)])
@property
def is_square(self):
return self.shape[0] == self.shape[1]
@property
def transpose(self):
data = list(map(list, zip(*self.data)))
return Matrix(data)
def _eye(self, n):
return [[0 if i != j else 1 for j in range(n)] for i in range(n)]
@property
def eye(self):
assert self.is_square, "The matrix has to be square!"
data = self._eye(self.shape[0])
return Matrix(data)
def _gaussian_elimination(self, aug_matrix):
n = len(aug_matrix)
m = len(aug_matrix[0])
# From top to bottom.
for col_idx in range(n):
# Check if element on the diagonal is zero.
if aug_matrix[col_idx][col_idx] == 0:
row_idx = col_idx
# Find a row whose element has same column index with
# the element on the diagonal is not zero.
while row_idx < n and aug_matrix[row_idx][col_idx] == 0:
row_idx += 1
# Add this row to the row of the element on the diagonal.
for i in range(col_idx, m):
aug_matrix[col_idx][i] += aug_matrix[row_idx][i]
# Elimiate the non-zero element.
for i in range(col_idx + 1, n):
# Skip the zero element.
if aug_matrix[i][col_idx] == 0:
continue
# Elimiate the non-zero element.
k = aug_matrix[i][col_idx] / aug_matrix[col_idx][col_idx]
for j in range(col_idx, m):
aug_matrix[i][j] -= k * aug_matrix[col_idx][j]
# From bottom to top.
for col_idx in range(n - 1, -1, -1):
# Elimiate the non-zero element.
for i in range(col_idx):
# Skip the zero element.
if aug_matrix[i][col_idx] == 0:
continue
# Elimiate the non-zero element.
k = aug_matrix[i][col_idx] / aug_matrix[col_idx][col_idx]
for j in chain(range(i, col_idx + 1), range(n, m)):
aug_matrix[i][j] -= k * aug_matrix[col_idx][j]
# Iterate the element on the diagonal.
for i in range(n):
k = 1 / aug_matrix[i][i]
aug_matrix[i][i] *= k
for j in range(n, m):
aug_matrix[i][j] *= k
return aug_matrix
def _inverse(self, data):
n = len(data)
unit_matrix = self._eye(n)
aug_matrix = [a + b for a, b in zip(self.data, unit_matrix)]
ret = self._gaussian_elimination(aug_matrix)
return list(map(lambda x: x[n:], ret))
@property
def inverse(self):
assert self.is_square, "The matrix has to be square!"
data = self._inverse(self.data)
return Matrix(data)
def _row_mul(self, row_A, row_B):
return sum(x[0] * x[1] for x in zip(row_A, row_B))
def _mat_mul(self, row_A, B):
row_pairs = product([row_A], B.transpose.data)
return [self._row_mul(*row_pair) for row_pair in row_pairs]
def mat_mul(self, B):
error_msg = "A's column count does not match B's row count!"
assert self.shape[1] == B.shape[0], error_msg
return Matrix([self._mat_mul(row_A, B) for row_A in self.data])
def _mean(self, data):
m = len(data)
n = len(data[0])
ret = [0 for _ in range(n)]
for row in data:
for j in range(n):
ret[j] += row[j] / m
return ret
def mean(self):
return Matrix(self._mean(self.data))
def scala_mul(self, scala):
m, n = self.shape
data = deepcopy(self.data)
for i in range(m):
for j in range(n):
data[i][j] *= scala
return Matrix(data)
然后我们来创建一个读取数据的方法:
def load_movie_ratings(file):
with open(file) as ff:
lines = iter(ff)
col_names = ", ".join(next(lines)[:-1].split(",")[:-1])
data = [[float(x) if i == 2 else int(x)
for i, x in enumerate(line[:-1].split(",")[:-1])]
for line in lines]
return data
接着,就是要写一个 ALS 的实现
class ALS(object):
def __init__(self):
self.user_ids = None
self.item_ids = None
self.user_ids_dict = None
self.item_ids_dict = None
self.user_matrix = None
self.item_matrix = None
self.user_items = None
self.shape = None
self.rmse = None
def _process_data(self, X):
self.user_ids = tuple((set(map(lambda x: x[0], X))))
self.user_ids_dict = dict(map(lambda x: x[::-1], enumerate(self.user_ids)))
self.item_ids = tuple((set(map(lambda x: x[1], X))))
self.item_ids_dict = dict(map(lambda x: x[::-1], enumerate(self.item_ids)))
self.shape = (len(self.user_ids), len(self.item_ids))
ratings = defaultdict(lambda: defaultdict(int))
ratings_T = defaultdict(lambda: defaultdict(int))
for row in X:
user_id, item_id, rating = row
ratings[user_id][item_id] = rating
ratings_T[item_id][user_id] = rating
err_msg = "Length of user_ids %d and ratings %d not match!" % (len(self.user_ids), len(ratings))
assert len(self.user_ids) == len(ratings), err_msg
err_msg = "Length of item_ids %d and ratings_T %d not match!" % (len(self.item_ids), len(ratings_T))
assert len(self.item_ids) == len(ratings_T), err_msg
return ratings, ratings_T
def _users_mul_ratings(self, users, ratings_T):
def f(users_row, item_id):
user_ids = iter(ratings_T[item_id].keys())
scores = iter(ratings_T[item_id].values())
col_nos = map(lambda x: self.user_ids_dict[x], user_ids)
_users_row = map(lambda x: users_row[x], col_nos)
return sum(a * b for a, b in zip(_users_row, scores))
ret = [[f(users_row, item_id) for item_id in self.item_ids] for users_row in users.data]
return Matrix(ret)
def _items_mul_ratings(self, items, ratings):
def f(items_row, user_id):
item_ids = iter(ratings[user_id].keys())
scores = iter(ratings[user_id].values())
col_nos = map(lambda x: self.item_ids_dict[x], item_ids)
_items_row = map(lambda x: items_row[x], col_nos)
return sum(a * b for a, b in zip(_items_row, scores))
ret = [[f(items_row, user_id) for user_id in self.user_ids] for items_row in items.data]
return Matrix(ret)
# 生成随机矩阵
def _gen_random_matrix(self, n_rows, n_colums):
data = np.random.rand(n_rows, n_colums)
return Matrix(data)
# 计算 RMSE
def _get_rmse(self, ratings):
m, n = self.shape
mse = 0.0
n_elements = sum(map(len, ratings.values()))
for i in range(m):
for j in range(n):
user_id = self.user_ids[i]
item_id = self.item_ids[j]
rating = ratings[user_id][item_id]
if rating > 0:
user_row = self.user_matrix.col(i).transpose
item_col = self.item_matrix.col(j)
rating_hat = user_row.mat_mul(item_col).data[0][0]
square_error = (rating - rating_hat) ** 2
mse += square_error / n_elements
return mse ** 0.5
# 模型训练
def fit(self, X, k, max_iter=10):
ratings, ratings_T = self._process_data(X)
self.user_items = {k: set(v.keys()) for k, v in ratings.items()}
m, n = self.shape
error_msg = "Parameter k must be less than the rank of original matrix"
assert k < min(m, n), error_msg
self.user_matrix = self._gen_random_matrix(k, m)
for i in range(max_iter):
if i % 2:
items = self.item_matrix
self.user_matrix = self._items_mul_ratings(
items.mat_mul(items.transpose).inverse.mat_mul(items),
ratings
)
else:
users = self.user_matrix
self.item_matrix = self._users_mul_ratings(
users.mat_mul(users.transpose).inverse.mat_mul(users),
ratings_T
)
rmse = self._get_rmse(ratings)
print("Iterations: %d, RMSE: %.6f" % (i + 1, rmse))
self.rmse = rmse
# Top-n 推荐,用户列表:user_id, n_items: Top-n
def _predict(self, user_id, n_items):
users_col = self.user_matrix.col(self.user_ids_dict[user_id])
users_col = users_col.transpose
items_col = enumerate(users_col.mat_mul(self.item_matrix).data[0])
items_scores = map(lambda x: (self.item_ids[x[0]], x[1]), items_col)
viewed_items = self.user_items[user_id]
items_scores = filter(lambda x: x[0] not in viewed_items, items_scores)
return sorted(items_scores, key=lambda x: x[1], reverse=True)[:n_items]
# 预测多个用户
def predict(self, user_ids, n_items=10):
return [self._predict(user_id, n_items) for user_id in user_ids]
那接着就是写一个主函数来对方法进行调用,并且开始进行学习。第一个我们创建好这个 model
model = ALS()
然后进行加载数据
data = load_movie_ratings('./ratings.csv')
那load_movie_ratings是已经封装好的一个读取数据的方法。这个方法做的事情就是导入数据并返回一个矩阵。
然后就是进行 fit 原来加载好的数据
model.fit(data, k=3, max_iter=2)
k 等于 3 代表聚类个数,max_iter 设置的迭代次数很少,因为他计算的这个速度会比较慢,为了方便的话就只计算两轮。两轮之后就会有结果,把这个结果做一个预测,我们想要给用户 1 到 12 来做预测,推荐两个商品。predict 给用户 1 到 12 推两个商品,然后把商品结果打印出来。
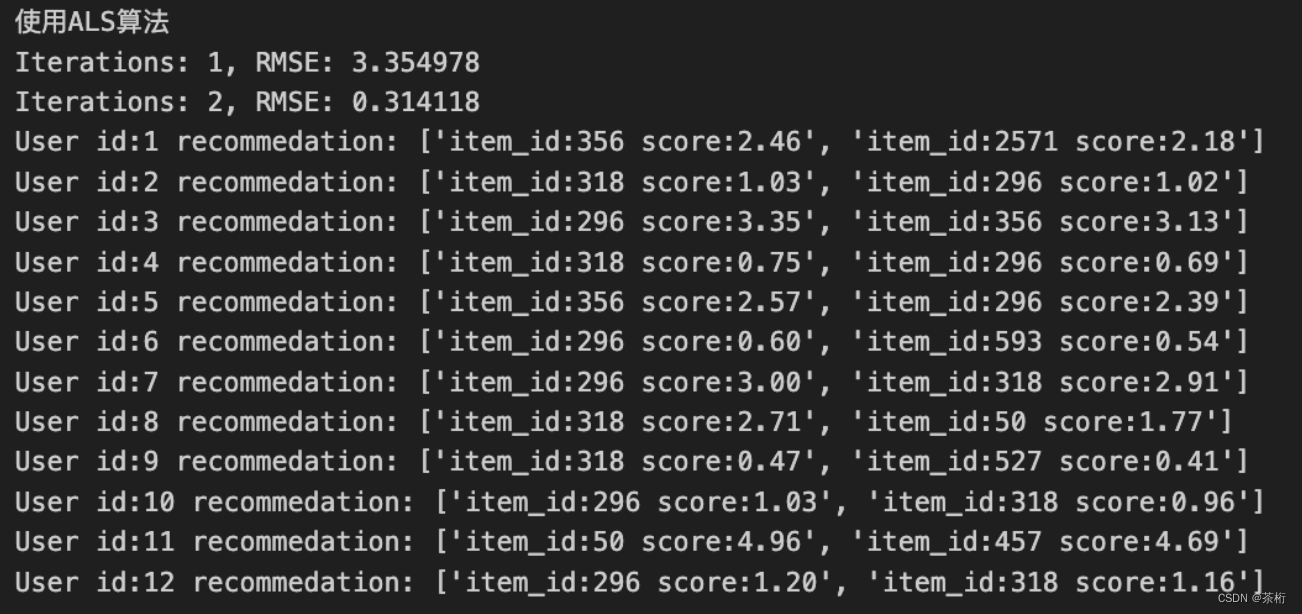
可以一起来看一看,我们的结果中第一轮和第二轮结果,MSE 结果都出来了。那这个 RMSE 代表什么含义?R 就是开了一个平方,所以它是在原有基础上开了根号。
第一轮我们得到 3.35, 一共学了两轮,学两轮基本上还没有学好,可以看一看第二轮 MSE 其实已经变得比较小了,为 0.31。整体的打分其实都不高,截图中是给用户推荐的一个结果,包含了商品 id。
这是第一个,我们用 ALS 可以去完成这样一个任务完成推荐,用 Python 包。还可以用 Spark,可以使用 ml 以及 mllib 去完成,大家可以安装一个 pyspark 来进行调用。
不过我的 M1 一直没有调好 Spark 环境,所以这一段演示也就暂时没办法拿给大家了,虽然代码在,但是因为没有环境跑过,所以可行性也不太清楚,就不放出来了,万一错了就是误导大家。
那下一节课呢,我会给大家再介绍一个方法,咱们下节课再见。