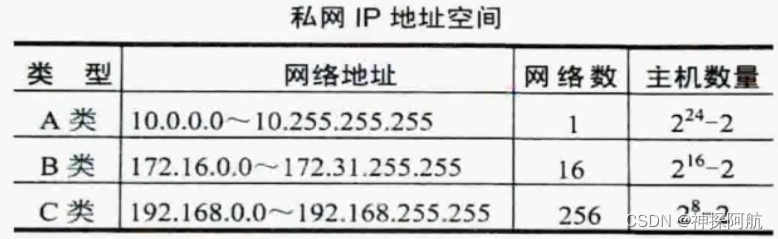
树
定义
树(Tree)是 n (n >= 0) 个结点的有限集
若 n == 0,称为空树
若 n > 0,则它满足如下两个条件:
- 有且仅有一个特定的称为根(Root)的结点
- 其余结点可分为 m(m>=0) 个互不相交的有限集 T1,T2,T3,…Tm,其中每一个集合本身又是一棵树,称为根的子树(SubTree)

术语
结点:数据元素
结点的度:结点拥有的子树数目
树的度:树内各结点的度的最大值
叶子结点(终端结点):度为0的结点
结点的子树的根称为该结点的孩子,该结点称为孩子的双亲
层次:结点在树结构中的层(一般定义根为1层)
树的深度:树中结点的最大层次
有序树:树中结点的各子树从左至右有次序(最左边为第一个孩子)
无序树:树中结点的各子树无次序
森林:m(m>=0) 棵互不相交的树的集合
二叉树
定义
二叉树是 n(n>=0) 个结点的有限集,它或者是空集(n = 0),或者由一个根结点及两棵互不相交的分别称作这个根的左子树和右子树的二叉树组成
特点
- 每个结点最多只有两棵子树
- 子树有左右之分,其次序不能颠倒,即使只有一棵子树时,也必须分清左右
- 二叉树可以是空集合,根可以有空的左子树或空的右子树
性质
性质1
一个非空二叉树的第 i 层上至多有2i-1个结点(i >= 1)

性质2
深度为 k 的二叉树至多有2k - 1个结点( k >= 1)
∑
i
=
1
k
(
第
i
层上的最大结点数
)
=
∑
i
=
1
k
2
i
−
1
=
2
0
+
2
1
+
.
.
.
.
.
.
+
2
k
−
1
=
2
0
−
2
k
−
1
×
2
1
−
2
(
等比公式求和
)
=
1
−
2
k
−
1
=
2
k
−
1
\begin{align} \sum_{i=1}^k(第i层上的最大结点数)&=\sum_{i=1}^k{2^{i-1}}\\ &=2^0+2^1+......+2^{k-1}\\ &=\frac{2^0-2^{k-1}\times 2}{1-2}(等比公式求和)\\ &=\frac{1-2^k}{-1}\\ &=2^k-1 \end{align}
i=1∑k(第i层上的最大结点数)=i=1∑k2i−1=20+21+......+2k−1=1−220−2k−1×2(等比公式求和)=−11−2k=2k−1
性质3
对任何一棵二叉树 T,如果其叶子数为 n0,度为2的结点数为 n2,则 n0 = n2 + 1
设 B 为二叉树的总边数,n 为二叉树的总结点数,n1 为度为1的结点数

则有:
B
=
n
−
1
=
n
2
×
2
+
n
1
×
1
n
=
n
2
+
n
1
+
n
0
\begin{align} B &= n-1 = n_2\times 2+n_1\times1 \tag{1}\\ n &= n_2+n_1+n_0 \tag{2}\\ \end{align}
Bn=n−1=n2×2+n1×1=n2+n1+n0(1)(2)
公式(1)(2)联立得:
n
0
=
n
2
+
1
n_0 = n_2 + 1
n0=n2+1
特殊二叉树
满二叉树
一棵深度为 k 且有 2k-1 个结点的二叉树称为满二叉树
特点
- 每一层上的结点数都是最大结点数
- 叶子结点全在最底层

编号规则:从根结点开始,自上而下,自左而右

完全二叉树
深度为 k 且有 n 个结点的二叉树,当且仅当其每一个结点都与深度为 k 的满二叉树中编号为 1~n 的结点一一对应时,称为完全二叉树

特点:
- 叶子只可能分布在层次最大的两层上
- 对任一结点,如果其右子树的最大层次为 i,则其左子树的最大层次必为 i 或 i+1
性质
-
具有 n 个结点的完全二叉树的深度为 ⌊ l o g 2 n ⌋ + 1 \lfloor log_2{n} \rfloor + 1 ⌊log2n⌋+1
-
对于一棵有 n 个结点的完全二叉树,按序编号后,对于任一结点 i(1 <= i <= n),有:
-
如果 i = 1,则结点 i 是二叉树的根,如果 i > 1,则其双亲是结点 ⌊ i / 2 ⌋ \lfloor i/2 \rfloor ⌊i/2⌋
-
如果 2*i > n,则结点 i 为叶子结点,如果 2*i <= n,则其左孩子为 2*i,其右孩子可能有可能没有
-
如果 2*i + 1 > n,则结点 i 必无右孩子,如果 2*i + 1 <= n,则其左孩子为 2*i,右孩子为 2*i + 1
满二叉树和完全二叉树的关系:
满二叉树一定是完全二叉树,完全二叉树不一定是满二叉树
存储结构
二叉树的存储结构可以分为顺序存储结构和链式存储结构,其中,链式存储结构又可分为二叉链表和三叉链表
顺序存储结构
用一个数组来存放二叉树上各结点的数据,需要对二叉树上各个结点进行编号,各个结点的编号等同于该二叉树补全为对应的满二叉树后的编号

特点:
-
结点间的关系蕴含在其存储位置中
-
浪费空间,适于存满二叉树和完全二叉树
链式存储结构
二叉链表
typedef struct BiNode
{
int data;
struct BiNode* lchild, * rchild;
}BiNode, * BiTree;
对于 n 个结点的二叉链表,有 n + 1 个空指针域
因为:n 个结点的二叉链表,有 2n 个指针域,每个指针域指向一个结点,没有指针域指向根结点
所以有 2n - (n+1) = n + 1 个空指针域
(以下代码都是基于二叉链表的结构实现的)
三叉链表
typedef struct TriNode
{
int data;
struct BiNode* lchild, * parent, * rchild;
}TriNode, * TriTree;
遍历
定义
顺着某一条搜索路径寻访二叉树中的结点,使每个结点均被访问一次,而且仅被访问一次
目的
得到树中所有结点的一个线性排列
用途
它是树结构插入、删除、修改、查找和排序运算的前提,是二叉树一切运算的基础和核心
遍历方法

设
L 表示遍历左子树
D 表示访问根结点
R 表示遍历右子树
则有 DLR、LDR、LRD、DRL、RDL、RLD 六种遍历方案
若规定先左后右的遍历方法
则只有前三种情况
- DLR(先序遍历)
- LDR(中序遍历)
- LRD(后序遍历)
例:

由遍历序列确定二叉树
已知二叉树的先序序列和中序序列,可以唯一确定一棵二叉树。
已知二叉树的后序序列和中序序列,可以唯一确定一棵二叉树。
已知二叉树的先序序列和后序序列,不能唯一确定一棵二叉树。
方法:根据先/后序遍历确定根,根据中序遍历确定左右
例
对于整棵树
先序DLR:ABCDEFGHIJ
中序LDR:CDBFEAIHGJ
由先序序列得树的根结点为 A
由中序序列得出,根结点 A 的左子树为 CDBFE,右子树为 IHGJ
对于根结点 A 的左子树
先序:BCDEF
中序:CDBFE
由先序序列得出其根结点为 B
由中序序列得出,根结点 B 的左子树为 CD,
对于根结点 B 的左子树
先序:CD
中序:CD
由先序序列得出,根结点为 C
由中序序列得出,根结点 C 无左子树,右子树为 D
如此反复,即可确定一棵树
该序列的树为

代码实现(递归)
先序遍历
void Pre_Order_Traverse(BiTree T)
{
if (T == NULL)
{
return;
}
else
{
printf("%c", T->data); //这里可以是任何其他操作
Pre_Order_Traverse(T->lchild);
Pre_Order_Traverse(T->rchild);
}
}
中序遍历
void In_Order_Traverse(BiTree T)
{
if (T == NULL)
{
return;
}
else
{
In_Order_Traverse(T->lchild);
printf("%c", T->data);
In_Order_Traverse(T->rchild);
}
}
后序遍历
void Post_Order_Traverse(BiTree T)
{
if (T == NULL)
{
return;
}
else
{
Post_Order_Traverse(T->lchild);
Post_Order_Traverse(T->rchild);
printf("%c", T->data);
}
}
代码实现(非递归)
中序遍历非递归算法
思路:
p为指向根结点的指针,设立一个栈 S
当 p 非空时,将 p 指向结点的地址入栈,然后将 p 指向该结点的左子树
当 p 为空时,栈顶元素出栈,显示结点元素,将 p 指向该结点的右子树
重复以上步骤,直到栈空且 p 也为空
void In_Order_Traverse_2(BiTree T)
{
LinkStack S = NULL;
BiNode* p = T;
BiNode q;
while (p != NULL || isEmpty_LinkStack(S) != 1)
{
if (p != NULL)
{
S = push(S, p);
p = p->lchild;
}
else
{
S = pop(S, &q);
printf("%c", q.data);
p = q.rchild;
}
}
}
层次遍历
思路:
p为指向根结点的指针,设立一个队列 Q
-
将根结点入队
-
队不空时循环:
从队列中出列一个结点,访问它
若该结点有左孩子,将左孩子入队
若该结点有右孩子,将右孩子入队
void level_order(BiTree T)
{
BiNode* p = T;
LinkQueue Q;
init_LinkQueue(&Q);
in(&Q, p);
while (isEmpty_LinkQueue(&Q) != NULL)
{
p = out(&Q);
printf("%c ", p->data);
if (p->lchild != NULL)
{
in(&Q, p->lchild);
}
if (p->rchild != NULL)
{
in(&Q, p->rchild);
}
}
}
遍历应用
建立二叉树
按照先/中/后序遍历建立二叉树,以 ‘#’ 字符表示空结点
按照先序遍历建立二叉树的代码如下
BiNode* create_BiTree(BiNode* p)
{
char ch;
scanf("%c", &ch);
if (ch == '#')
{
p = NULL;
}
else
{
p = (BiNode*)malloc(sizeof(BiNode));
if (p == NULL)
{
printf("allocation failure!\n");
exit(0);
}
else
{
p->data = ch;
p->lchild = create_BiTree(p->lchild);
p->rchild = create_BiTree(p->rchild);
}
}
return p;
}
若想改为中/后序遍历建立二叉树,只需要改动如下代码即可
p->data = ch;
p->lchild = create_BiTree(p->lchild);
p->rchild = create_BiTree(p->rchild);
中序:
p->lchild = create_BiTree(p->lchild);
p->data = ch;
p->rchild = create_BiTree(p->rchild);
后序:
p->lchild = create_BiTree(p->lchild);
p->rchild = create_BiTree(p->rchild);
p->data = ch;
复制二叉树
BiTree copy_BiTree(BiTree T, BiTree newT)
{
if (T == NULL)
{
newT = NULL;
}
else
{
newT = (BiNode*)malloc(sizeof(BiNode));
if (newT == NULL)
{
printf("allocation failure!\n");
exit(0);
}
else
{
newT->data = T->data;
newT->lchild = NULL;
newT->rchild = NULL;
newT->lchild = copy_BiTree(T->lchild, newT->lchild);
newT->rchild = copy_BiTree(T->rchild, newT->rchild);
}
}
return newT;
}
计算二叉树深度
int get_BiTree_Depth(BiTree T)
{
if (T == NULL)
{
return 0;
}
else
{
int LeftDepth = get_BiTree_Depth(T->lchild);
int RightDepth = get_BiTree_Depth(T->rchild);
if (LeftDepth > RightDepth)
{
return LeftDepth + 1;
}
else
{
return RightDepth + 1;
}
}
}
计算二叉树结点总数
int count_BiTree_Node(BiTree T)
{
if (T == NULL)
{
return 0;
}
else
{
int LeftCount = count_BiTree_Node(T->lchild);
int RightCount = count_BiTree_Node(T->rchild);
int totalCount = LeftCount + RightCount + 1;
return totalCount;
}
}
计算二叉树叶子结点总数
int count_BiTree_LeafNode(BiTree T)
{
if (T == NULL)
{
return 0;
}
else
{
if (T->lchild == NULL && T->rchild == NULL)
{
return 1;
}
else
{
return count_BiTree_LeafNode(T->lchild) + count_BiTree_LeafNode(T->rchild);
}
}
}



![[极客挑战2019]HTTP](https://img-blog.csdnimg.cn/direct/86be3ad122b343f39c2b72ac4d9f0549.png)