参数高效微调目的
PEFT技术旨在通过最小化微调参数的数量和计算复杂度,来提高预训练模型在新任务上的性能,从而缓解大型预训练模型的训练成本。这样一来,即使计算资源受限,也可以利用预训练模型的知识来迅速适应新任务,实现高效的迁移学习。
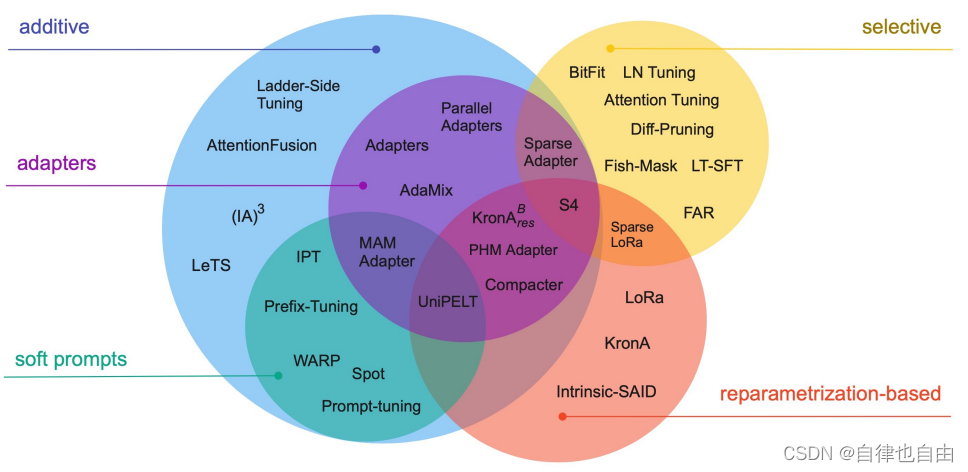
参数高效微调方法主要有如下几类:
- 增加额外参数,如:Prefix Tuning、Prompt Tuning、Adapter Tuning及其变体。
- 选取一部分参数更新,如:BitFit。
- 引入重参数化,如:LoRA、AdaLoRA、QLoRA。
- 混合高效微调,如:MAM Adapter、UniPELT。
高效微调(PEFT)
BitFit
- 是一种稀疏的微调方法,它训练时只更新bias的参数或者部分bias参数。
- 涉及到的bias参数有attention模块中计算query,key,value跟合并多个attention结果时涉及到的bias,MLP层中的bias,Layernormalization层的bias参数。
- 特点:
- 训练参数量极小(约0.1%)。
- 在大部分任务上效果会差于LoRA、Adapter等方法。
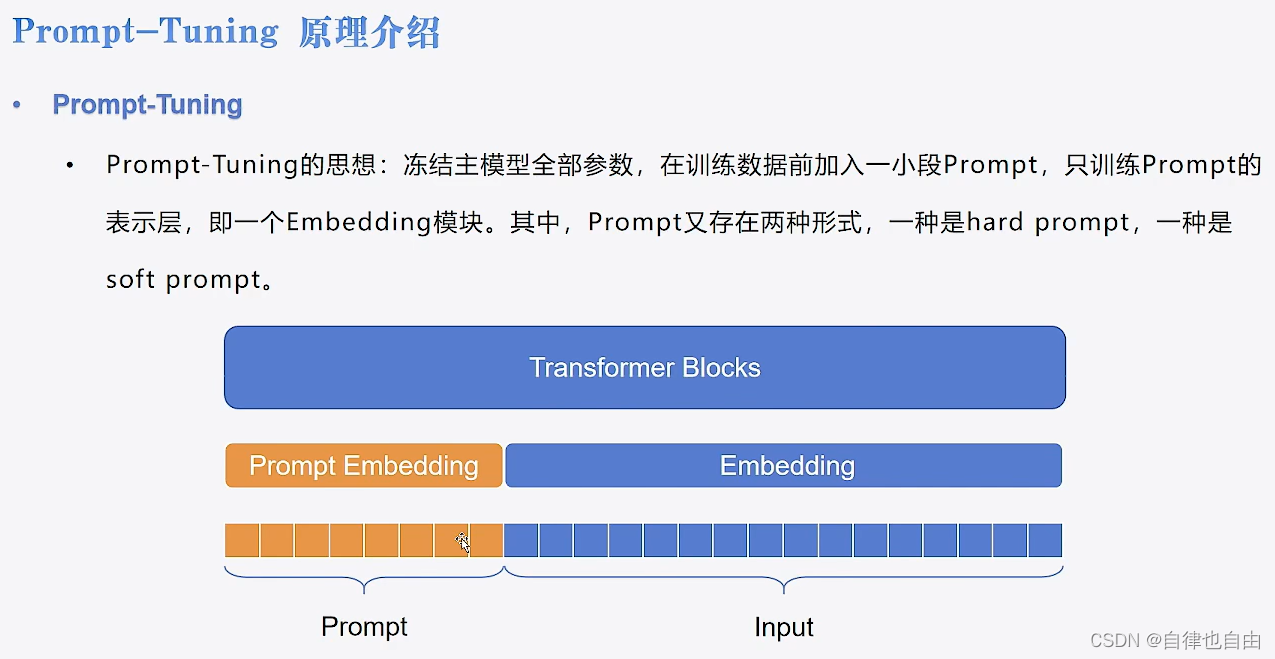
Prompt-Tuning
- 冻结主模型全部参数,在训练数据前加入一小段Prompt,只训练Prompt的表示层,即一个Embedding模块。
- 其中,Prompt又存在两种形式,一种是hard prompt,一种是soft prompt.
- 特点:
- 相对于Prefix Tuning,参与训练的参数量和改变的参数量更小,更节省显存。
- 对一些简单的NLU 任务还不错,但对硬序列标记任务(即序列标注)表现欠佳。
P-Tuning
- 在Prompt-Tuning的基础上,对Prompt部分进行进一步的编码计算,加速收敛
- 具体来说,PEFT中支持两种编码方式,一种是LSTM,一种是MLP。
- 与Prompt-Tuning不同的是Prompt的形式只有Soft Prompt。
- 特点:
- 引入一个prompt encoder(由一个双向的LSTM+两层MLP组成)来建模virtual token的相互依赖会收敛更快,效果更好。
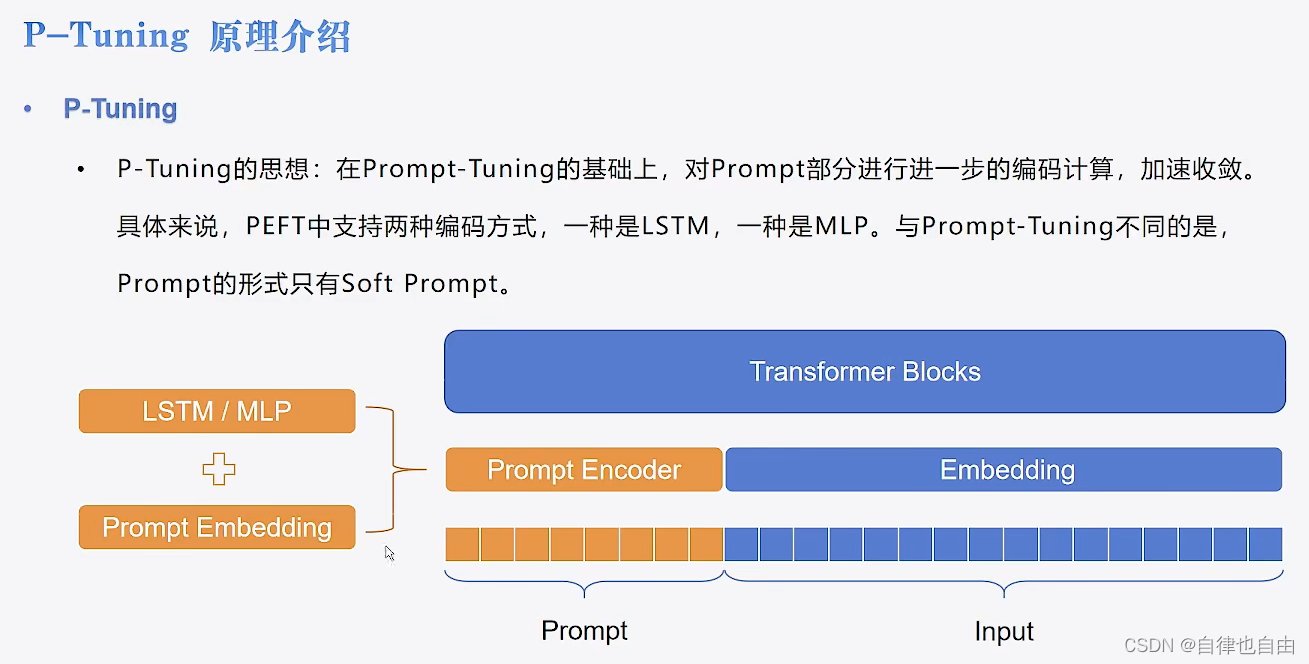
- 引入一个prompt encoder(由一个双向的LSTM+两层MLP组成)来建模virtual token的相互依赖会收敛更快,效果更好。
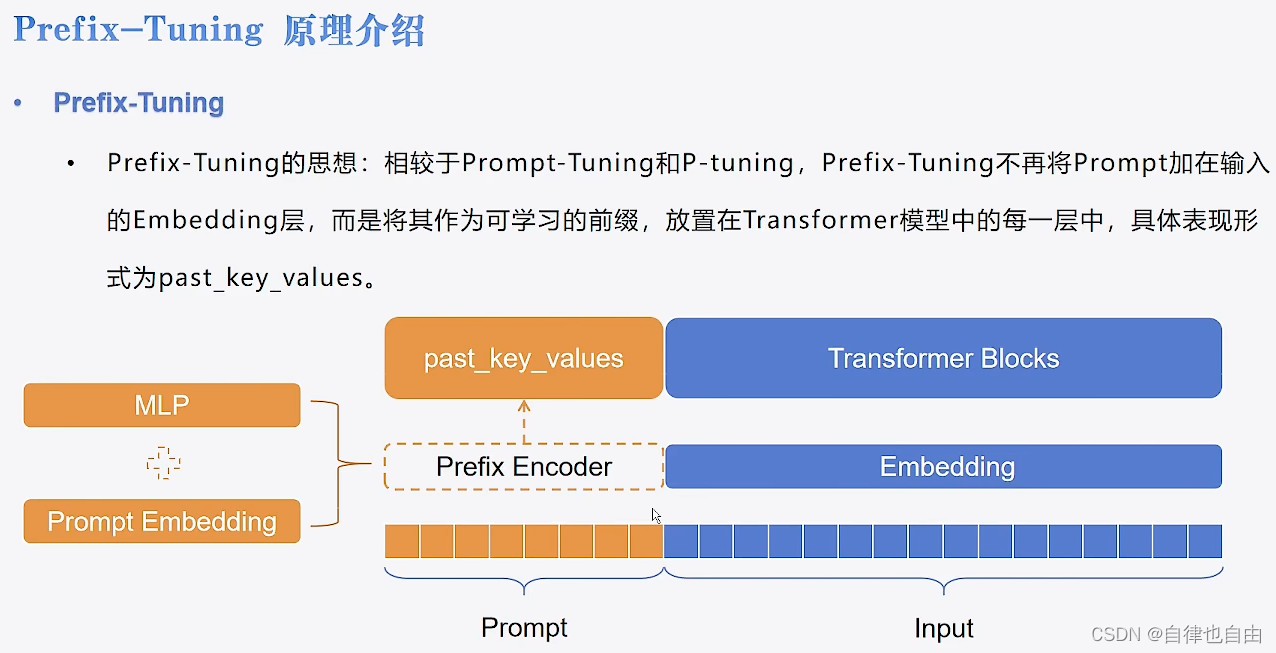
Prefix-Tuning
- 相较于Prompt-Tuning和P-tuning,Prefix-Tuning不再将Prompt加在输入的Embedding层,而是将其作为可学习的前缀,放置在Transformer模型中的每一层中,具体表现形式为past key values。
- 特点:
- 前缀Token会占用序列长度,有一定的额外计算开销。
- Prefix Tuning的线性插值是比较复杂的。
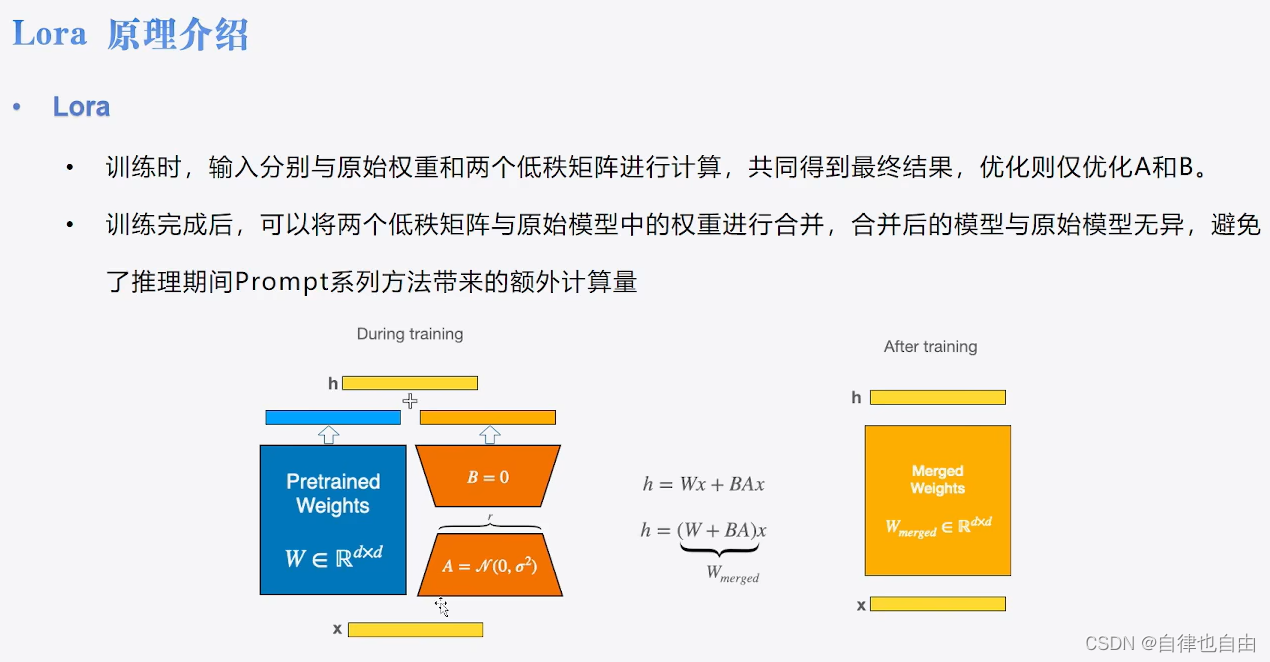
LoRA
- 基于大模型的内在低秩特性,增加旁路矩阵(一般是模型的q和v),冻结原参数,模拟全参数微调
- 工作步骤:
- 选择要调整的权重矩阵:在大型模型(如GPT)中,我们首先确定要微调的权重矩阵。通常,这些矩阵位于模型的多头自注意力(Multi-head Self-Attention)和前馈神经网络(Feed-Forward Neural Network)部分。
- 引入两个低秩矩阵:接着,我们引入两个低秩矩阵,记为A和B,这两个矩阵的维度比原始权重矩阵小得多,例如,如果原始矩阵的尺寸是dd,那么,A和B的尺寸可能是dr和r*d,其中r是一个远小于d的数。
- 计算低秩更新:通过计算这两个低秩矩阵的乘积,生成一个新的矩阵AB,这个新矩阵的秩(即r)远小于原始权重矩阵的秩。这个乘积实际上是一个低秩近似,可以视为对原始权重矩阵的一种调整。
- 结合原始权重:最后,这个新生成的低秩矩阵AB被加到原始的权重矩阵上。这样,原始的权重矩阵得到了微调,但大部分权重保持不变。这个过程可以用数学公式表示为:新权重 = 原始权重 + AB。
- 特点:
- 将BA加到W上可以消除推理延迟。
- 可以通过可插拔的形式切换到不同的任务。
- 设计的比较好,简单且效果好。
QLoRA
- QLORA微调的核心机制和思想,不降低训练效果下使用更少的GPU资源,使用一种新颖的高精度技术将预训练模型量化为 4 bit,然后添加一小组可学习的低秩适配器权重,这些权重通过量化权重的反向传播梯度进行微调。
- NF4量化+二次量化
- 减少数据存储
- 精度并未下降优于BF16
- 微调中数据质量比数据量更重要
- NF4存储,BF16计算
- NF4 Quantization
- 考虑了模型权重真实分布为正态分布,采用分位数量化
- 一共15个点,将范围切分为16个区间再映射到0-1区间(原始参数->原始参数的【0-1】->16分位的【0-1】->16分位)
- Double Quantization
- 将反量化时用到的量化常数absmax化成8bit
- Paged optimizers
- 当显存不足时,将优化器的参数转移到CPU内存上,再需要时再将其收回,防止显存峰值时OOM
- NF4量化+二次量化
Adapter Tuning
-
与 LoRA 类似,Adapter Tuning 的目标是在不改变预训练模型的原始参数的前提下,使模型能够适应新的任务。在 Adapter Tuning 中,会在模型的每个层或某些特定层之间插入小的神经网络模块,称为“adapters”。这些 adapters 是可以训练的,而原始模型的参数则保持不变。
-
Adapter Tuning 的关键原理和步骤:
- 预训练模型作为基础:开始时,我们有一个已经预训练好的大型模型,例如BERT或GPT。这个模型已经学习了大量的语言特征和模式。
- 插入适配器:在这个预训练模型的每一层或选定的层中,我们插入适配器。这些适配器是小型的神经网络,通常只包含几层,并且参数相对较少。
- 保持预训练参数不变:在微调过程中,原始预训练模型的参数保持不变。这意味着我们不直接调整这些参数,而是专注于训练适配器的参数。
- 训练适配器:适配器的参数会根据特定任务的数据进行训练。这样,适配器可以学习如何根据任务调整模型的行为。
- 任务特定的调整:通过这种方式,模型能够对每个特定任务做出微调,而不会影响到模型其他部分的通用性能。适配器可以帮助模型更好地理解和处理与特定任务相关的特殊模式和数据。
- 高效和灵活:由于只有一小部分参数被调整,这种方法比全模型微调更高效,同时也允许模型快速适应新任务。

LoRA和Adapter Tuning的区别:
LoRA:通过在模型的权重矩阵中引入低秩矩阵(通常是两个小的矩阵的乘积)来实现对模型的微调。这些低秩矩阵作为原有权重矩阵的修改项,使得原有的权重矩阵在实际计算时得到调整。
Adapter Tuning:通过在模型的各个层中添加小型神经网络模块,即“适配器”,来实现微调。这些适配器独立于模型的主体结构,只有它们的参数在微调过程中被更新,而模型的其他预训练参数保持不变。
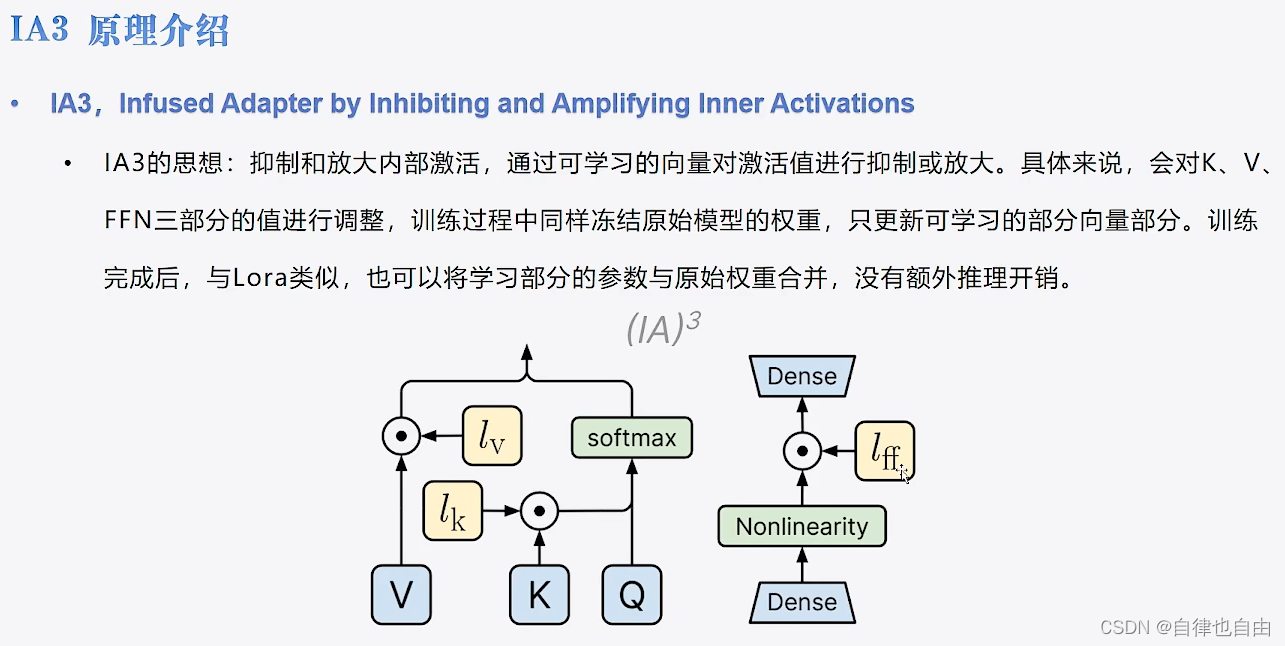
IA3
- 抑制和放大内部激活,通过可学习的向量对激活值进行抑制或放大。
- 具体来说,会对K、V、FFN三部分的值进行调整,训练过程中同样冻结原始模型的权重,只更新可学习的部分向量部分。训练完成后,与Lora类似,也可以将学习部分的参数与原始权重合并,没有额外推理开销.

![[力扣 Hot100]Day33 排序链表](https://img-blog.csdnimg.cn/direct/7b58508b39b248b98d490404718911b5.png)