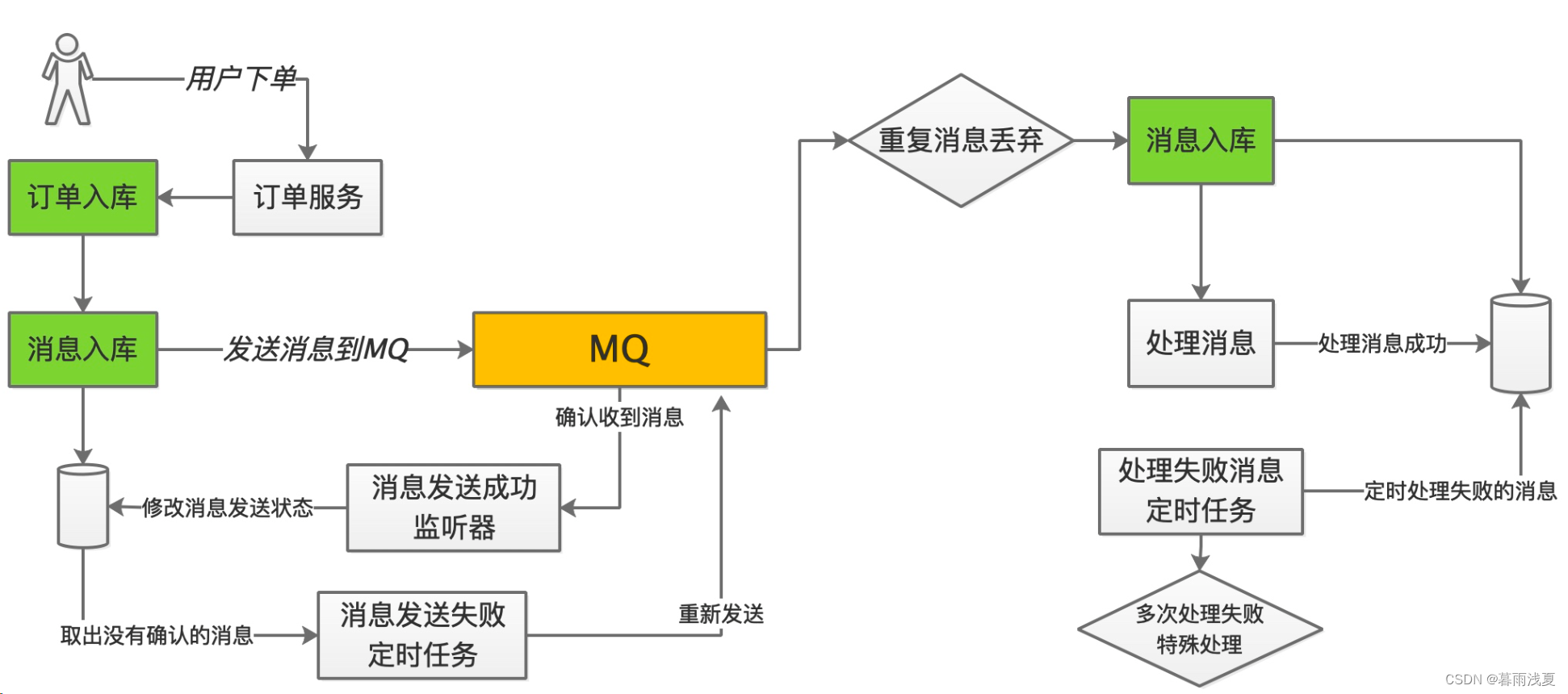
一、Kafka整体架构图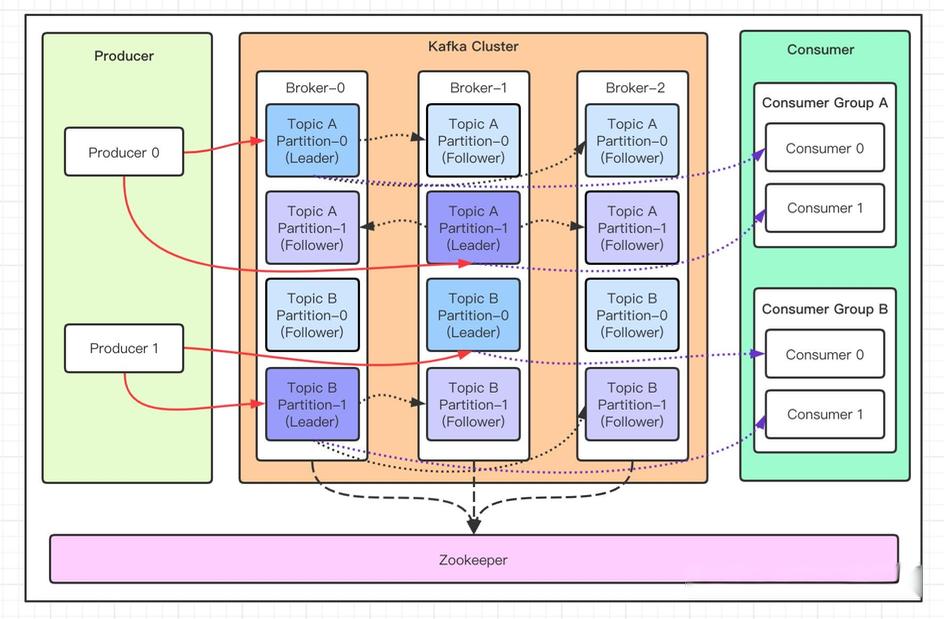
二、Kafka原题回答
Kafka集群有主从模式吗?
Kafka集群实际上并没有严格意义上的主从模式。Kafka的设计是基于分布式的,每个Topic都会切分为多个Partition,每个Partition都有一个Leader和多个Follower。
所有的读写操作都是通过Leader来进行的,Follower则负责从Leader同步数据。如果Leader宕机,那么就会从Follower中选举一个新的Leader。
这种方式更类似于Leader-Follower模式,而不是传统意义上的主从模式,因为在Kafka中,每个Broker(Kafka的服务器节点)都可能成为某个Partition的Leader,也可能是Follower,这取决于你如何配置和使用你的Kafka集群。
Kafka集群故障时,主从如何切换的?
Kafka集群中的数据分片(Partition)有一个Leader和一个或多个Follower。所有的读写操作都通过Leader进行,Follower则负责从Leader同步数据。如果Leader发生故障,Kafka会自动从Follower中选举出新的Leader。
这个切换过程是由Kafka的Zookeeper组件进行协调的。Zookeeper是一个分布式协调服务,它可以监控Kafka集群中各个Broker(服务器节点)的状态,并在Leader宕机时触发新的Leader选举。
在选举新Leader的过程中,Zookeeper会考虑各个Follower的同步状态,优先选择数据最新、最完整的Follower作为新的Leader。这样可以尽量保证数据的一致性,避免数据丢失。
一旦新的Leader被选举出来,所有的读写请求就会被自动转发到新的Leader,对客户端来说,这个过程是透明的。这就是Kafka实现高可用和故障切换的方式。
Kafka如何实现消费者快速扩容?
Kafka通过消费者组(Consumer Group)来实现消费者的快速扩容。在一个消费者组中,可以有一个或多个消费者实例。这些消费者实例可以在同一个进程内,也可以分布在多个进程或者机器上。
当有新的消费者加入消费者组,或者已有的消费者离开消费者组时,Kafka会自动进行再平衡(Rebalance)操作,重新分配Partition到各个消费者。这样,消费者的数量可以根据实际的处理能力和负载情况进行动态调整。
具体来说,Kafka的每个Topic都会被分割成多个Partition,每个Partition可以被一个消费者组中的一个消费者消费。当消费者组中的消费者数量变化时,Kafka会自动将Partition重新分配给消费者,确保每个Partition都被消费,且只被消费一次。
需要注意的是,一个Partition在一个消费者组中,一次只能被一个消费者消费,所以消费者组中的消费者数量不能超过总的Partition数量,否则多余的消费者将会闲置。
在分区固定的情况下,如何快速扩容消费者个数?
在Kafka中,每个partition只能被一个消费者组中的一个消费者消费。因此,如果分区数量固定,消费者数量的上限就是分区的数量。这意味着,如果你想增加消费者的数量,但分区数量已经固定,那么你只能增加到分区数量的上限。如果消费者数量超过分区数量,那么多余的消费者将处于空闲状态,不会被用来消费消息。
为了解决这个问题,你可以在创建topic时预先设定一个较大的分区数量,以便于未来扩展消费者数量。另外,你也可以在需要时动态地增加topic的分区数量(尽管这可能会影响到消息的顺序)。
如果以上两种方法都无法满足需求,那么你可能需要考虑使用不同的消费者组,或者改变你的应用架构,以适应Kafka的这种限制。
Topic的分区数量能超过Kafka集群节点的数量吗
Topic的分区数量可以超过Kafka集群节点的数量。实际上,通常会建议设置的分区数量大于Broker(节点)数量,这样可以更好地利用集群的并发处理能力,并提高系统的吞吐量。
Kafka的设计使得它可以支持大量的分区。每个分区可以被任何Broker节点服务,无论这个节点是作为Leader还是Follower。当分区数量超过Broker数量时,一些Broker会服务多个分区。
需要注意的是,分区数量的增加可能会带来一些开销,例如更多的网络连接和线程,以及在进行Rebalance操作时更高的延迟。因此,在设置分区数量时,需要根据实际的应用需求和系统资源来进行权衡。
分区数量大于Broker(节点)数量有什么问题?
在Kafka中,一个Topic可以被分割成多个分区,每个分区都有一个Leader和多个Follower。分区数量大于Broker(节点)数量并没有本质的问题,事实上,这在很多大型Kafka部署中都是常见的。
然而,有几点需要注意:
资源使用:每个分区都会使用一定的内存和CPU资源,尤其是在进行消息复制和处理消费者请求时。如果Broker需要处理的分区数量太多,可能会导致资源紧张,影响性能。
Rebalance时间:当消费者组中的消费者数量发生变化时,Kafka会进行Rebalance操作,重新分配分区给消费者。如果分区数量过多,这个操作可能会花费更多的时间。
故障恢复:当一个Broker宕机时,其上的所有分区都需要在其他Broker上进行Leader选举和数据复制。如果分区数量过多,这个过程可能会花费更多的时间,从而延长系统的恢复时间。
因此,虽然分区数量可以大于Broker数量,但是在设置分区数量时,还需要考虑到上述因素,进行适当的权衡。
参考:https://www.bilibili.com/read/cv25391183