今天,Google 发布了一系列最新的开放式大型语言模型 —— Gemma!Google 正在加强其对开源人工智能的支持,我们也非常有幸能够帮助全力支持这次发布,并与 Hugging Face 生态完美集成。
Gemma 提供两种规模的模型:7B 参数模型,针对消费级 GPU 和 TPU 设计,确保高效部署和开发;2B 参数模型则适用于 CPU 和移动设备。每种规模的模型都包含基础版本和经过指令调优的版本。
我们与 Google 紧密合作,确保 Gemma 能够无缝集成到 Hugging Face 的生态系统中。在 Hub 上,你可以找到这四个公开可访问的模型(包括两个基础模型和两个经过调优的模型)。此次发布的亮点包括:
Hub 上的模型,包括模型说明和授权信息
🤗 Transformers 的集成
与 Google Cloud 的深度集成
与推理端点 (Inference Endpoints) 的集成
使用 🤗 TRL 在单个 GPU 上对 Gemma 进行微调的示例
Gemma 是什么?
Gemma 是 Google 基于 Gemini 技术推出的四款新型大型语言模型(LLM),提供了 2B 和 7B 两种不同规模的版本,每种都包含了预训练基础版本和经过指令优化的版本。所有版本均可在各类消费级硬件上运行,无需数据量化处理,拥有高达 8K tokens 的处理能力:
gemma-7b:7B 参数的基础模型。
gemma-7b-it:7B 参数的指令优化版本。
gemma-2b:2B 参数的基础模型。
gemma-2b-it:2B 参数的指令优化版本。

Gemma 模型的性能如何?以下是其基础版本与其他开放模型在 LLM 排行榜 上的比较(得分越高越好):
| 模型 | 许可证 | 商业使用 | 预训练大小 [tokens] | 排行榜分数 ⬇️ |
|---|---|---|---|---|
| LLama 2 70B Chat (参考) | Llama 2 许可证 | ✅ | 2T | 67.87 |
| Gemma-7B | Gemma 许可证 | ✅ | 6T | 63.75 |
| DeciLM-7B | Apache 2.0 | ✅ | 未知 | 61.55 |
| PHI-2 (2.7B) | MIT | ✅ | 1.4T | 61.33 |
| Mistral-7B-v0.1 | Apache 2.0 | ✅ | 未知 | 60.97 |
| Llama 2 7B | Llama 2 许可证 | ✅ | 2T | 54.32 |
| Gemma 2B | Gemma 许可证 | ✅ | 2T | 46.51 |
在 7B 参数级别,Gemma 表现出色,与市场上最佳模型如 Mistral 7B 不相上下。而 2B 版本的 Gemma 虽然规模较小,但在其类别中的表现也颇具竞争力,尽管在排行榜上的得分并未超越类似规模的顶尖模型,例如 Phi 2。我们期待社区对这些模型的真实使用反馈,以进一步优化和调整。
需要浅浅再强调一下:LLM 排行榜特别适用于衡量预训练模型的质量,而不太适用于聊天模型。我们鼓励对聊天模型运行其他基准测试,如 MT Bench、EQ Bench 和 lmsys Arena。
Prompt 提示词格式
Gemma 的基础模型不限定特定的提示格式。如同其他基础模型,它们能够根据输入序列生成一个合理的续接内容,适用于零样本或少样本的推理任务。这些模型也为针对特定应用场景的微调提供了坚实的基础。指令优化版本则采用了一种极其简洁的对话结构:
<start_of_turn>user
knock knock<end_of_turn>
<start_of_turn>model
who is there<end_of_turn>
<start_of_turn>user
LaMDA<end_of_turn>
<start_of_turn>model
LaMDA who?<end_of_turn>要有效利用这一格式,必须严格按照上述结构进行对话。我们将演示如何利用 transformers 库中提供的聊天模板简化这一过程。
探索未知领域
尽管技术报告提供了关于基础模型训练和评估过程的信息,但关于数据集构成和预处理的具体细节则较为欠缺。据悉,这些模型是基于来自互联网文档、编程代码和数学文本等多种数据源训练而成,经过严格筛选,以排除含有敏感信息和不适内容的数据。
对于 Gemma 的指令优化模型,关于微调数据集以及与顺序微调技术(SFT)和 基于人类反馈的强化学习(RLHF)相关的超参数设置,细节同样未公开。
演示
现在,你可以在 Hugging Chat 上体验与 Gemma 指令模型的互动对话!点击此处访问:
https://hf.co/chat?model=google/gemma-7b-it
使用 🤗 Transformers
借助 Transformers 的 4.38 版本,你可以轻松地使用 Gemma 模型,并充分利用 Hugging Face 生态系统内的工具,包括:
训练和推理脚本及示例
安全文件格式(
safetensors)集成了诸如 bitsandbytes(4位量化)、PEFT(参数效率微调)和 Flash Attention 2 等工具
辅助工具和帮助器,以便使用模型进行生成
导出模型以便部署的机制
另外,Gemma 模型支持 torch.compile() 与 CUDA 图的结合使用,在推理时可实现约 4 倍的速度提升!
确保你使用的是最新版本的 transformers:
pip install -U "transformers==4.38.0" --upgrade以下代码片段展示了如何结合 transformers 使用 gemma-7b-it。运行此代码需大约 18 GB 的 RAM,适用于包括 3090 或 4090 在内的消费级 GPU。
from transformers import AutoTokenizer, pipeline
import torch
model = "google/gemma-7b-it"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = pipeline(
"text-generation",
model=model,
model_kwargs={"torch_dtype": torch.bfloat16},
device="cuda",
)
messages = [
{"role": "user", "content": "Who are you? Please, answer in pirate-speak."},
]
prompt = pipeline.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipeline(
prompt,
max_new_tokens=256,
add_special_tokens=True,
do_sample=True,
temperature=0.7,
top_k=50,
top_p=0.95
)
print(outputs[0]["generated_text"][len(prompt):])Avast me, me hearty. I am a pirate of the high seas, ready to pillage and plunder. Prepare for a tale of adventure and booty!
简单介绍一下这段代码:
代码段展示了如何利用
bfloat16数据类型进行模型推理,该数据类型是所有评估中使用的参考精度。如果你的硬件支持,使用float16可能会更快。你还可以将模型自动量化,以 8 位或 4 位模式加载。以 4 位模式加载模型大约需要 9 GB 的内存,使其适用于多种消费级显卡,包括 Google Colab 上的所有 GPU。以下是以 4 位加载生成 pipeline 的方法:
pipeline = pipeline(
"text-generation",
model=model,
model_kwargs={
"torch_dtype": torch.float16,
"quantization_config": {"load_in_4bit": True}
},
)更多关于如何使用 transformers 和模型的详情,请参阅 模型卡片。
JAX 权重
所有 Gemma 模型变种都可以用 PyTorch 或 JAX / Flax 使用。若要加载 Flax 权重,你需要按照以下方式使用仓库中的 flax 修订版本:
import jax.numpy as jnp
from transformers import AutoTokenizer, FlaxGemmaForCausalLM
model_id = "google/gemma-2b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
tokenizer.padding_side = "left"
model, params = FlaxGemmaForCausalLM.from_pretrained(
model_id,
dtype=jnp.bfloat16,
revision="flax",
_do_init=False,
)
inputs = tokenizer("Valencia and Málaga are", return_tensors="np", padding=True)
output = model.generate(inputs, params=params, max_new_tokens=20, do_sample=False)
output_text = tokenizer.batch_decode(output.sequences, skip_special_tokens=True)
['Valencia and Málaga are two of the most popular tourist destinations in Spain. Both cities boast a rich history, vibrant culture,']
如果你在 TPU 或多个 GPU 设备上运行,可以利用 jit 和 pmap 来编译和并行执行推理任务。
与 Google Cloud 集成
你可以通过 Vertex AI 或 Google Kubernetes Engine (GKE) 在 Google Cloud 上部署和训练 Gemma,利用 文本生成推理 和 Transformers 实现。
要从 Hugging Face 部署 Gemma 模型,请访问模型页面并点击部署 -> Google Cloud。这将引导你进入 Google Cloud Console,在那里你可以通过 Vertex AI 或 GKE 一键部署 Gemma。文本生成推理为 Gemma 在 Google Cloud 上的部署提供支持,这是我们与 Google Cloud 合作伙伴关系的初步成果。
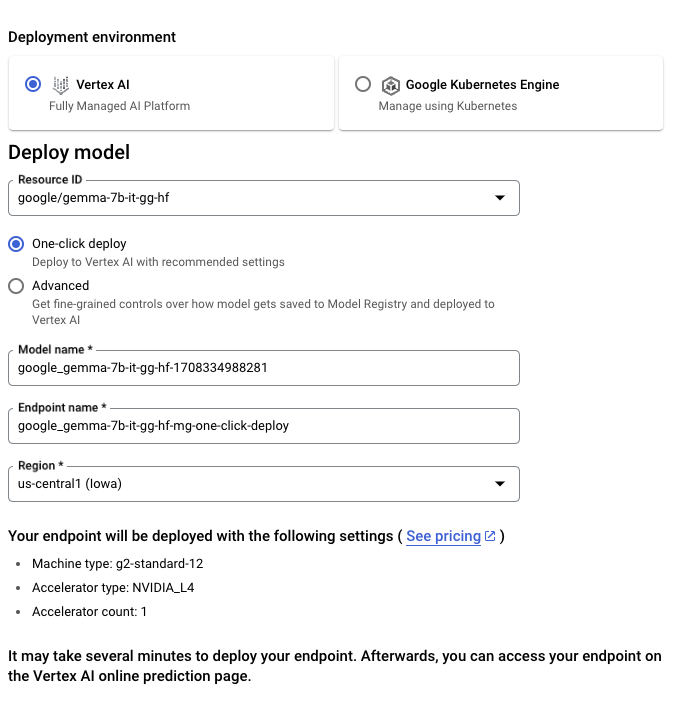
你也可以通过 Vertex AI Model Garden 直接访问 Gemma。
要在 Hugging Face 上微调 Gemma 模型,请访问 模型页面 并点击 训练 -> Google Cloud。这将引导你进入 Google Cloud Console,在那里你可以在 Vertex AI 或 GKE 上访问笔记本,以在这些平台上微调 Gemma。
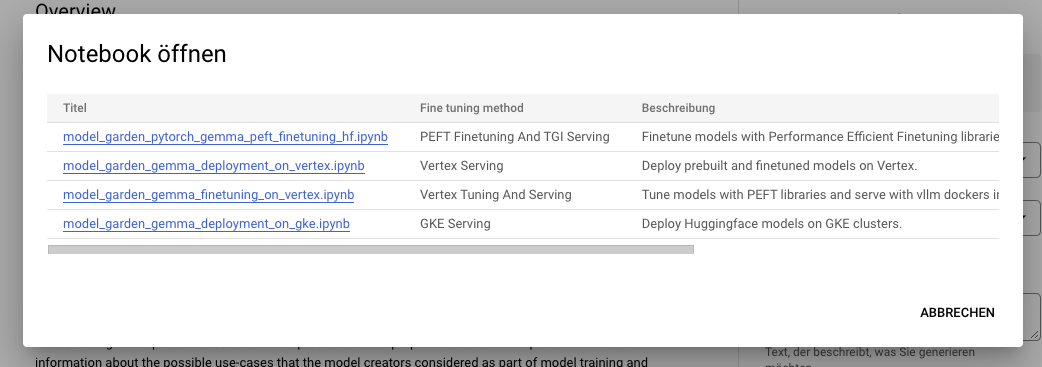
这些集成是我们 与 Google 合作伙伴关系成果的一部分,未来还会有更多精彩内容发布,敬请期待!
与推理端点集成
你可以在 Hugging Face 的 推理端点 上部署 Gemma,该端点使用文本生成推理作为后端。文本生成推理 是由 Hugging Face 开发的可用于生产环境的推理容器,旨在简化大型语言模型的部署。它支持连续批处理、令牌流式传输、多 GPU 张量并行加速推理,并提供生产就绪的日志记录和跟踪功能。
要部署 Gemma 模型,请访问 HF Hub 模型页面 并点击 部署 -> 推理端点。有关 使用 Hugging Face 推理端点部署 LLM的更多信息,请参阅我们之前的博客文章。推理端点通过文本生成推理支持 消息 API,使你可以通过简单地更换 URL 从其他封闭模型切换到开放模型。
from openai import OpenAI
# initialize the client but point it to TGI
client = OpenAI(
base_url="<ENDPOINT_URL>" + "/v1/", # replace with your endpoint url
api_key="<HF_API_TOKEN>", # replace with your token
)
chat_completion = client.chat.completions.create(
model="tgi",
messages=[
{"role": "user", "content": "Why is open-source software important?"},
],
stream=True,
max_tokens=500
)
# iterate and print stream
for message in chat_completion:
print(message.choices[0].delta.content, end="")使用 🤗 TRL 进行微调
在消费级 GPU 上训练大型语言模型既是技术上的挑战,也是计算上的挑战。本节将介绍 Hugging Face 生态系统中可用的工具,这些工具可以帮助你高效地在消费级 GPU 上训练 Gemma。
一个微调 Gemma 的示例命令如下。我们利用 4 位量化和 QLoRA(一种参数效率微调技术)来减少内存使用,目标是所有注意力块的线性层。值得注意的是,与密集型 Transformer 不同,MLP 层(多层感知器层)因其稀疏性不适合与 PEFT(参数效率微调)技术结合使用。
首先,安装 🤗 TRL 的最新版本并克隆仓库以获取 训练脚本:
pip install -U transformers
pip install git+https://github.com/huggingface/trl
git clone https://github.com/huggingface/trl
cd trl然后运行脚本:
accelerate launch --config_file examples/accelerate_configs/multi_gpu.yaml --num_processes=1 \
examples/scripts/sft.py \
--model_name google/gemma-7b \
--dataset_name OpenAssistant/oasst_top1_2023-08-25 \
--batch_size 2 \
--gradient_accumulation_steps 1 \
--learning_rate 2e-4 \
--save_steps 20_000 \
--use_peft \
--peft_lora_r 16 --peft_lora_alpha 32 \
--target_modules q_proj k_proj v_proj o_proj \
--load_in_4bit在单个 A10G GPU 上,这个训练过程大约需要 9 小时。通过调整 --num_processes 参数为你可用的 GPU 数量,可以实现并行化训练,从而缩短训练时间。
额外资源
Hub 上的模型
开放 LLM 排行榜
Hugging Chat 上的聊天演示
Gemma 官方博客
Gemma 产品页面
Vertex AI 模型花园链接
Google Notebook 教程
致谢
此次发布和在生态系统中的集成是由包括 Clémentine、Eleuther 评估工具(LLM 评估)、Olivier、David(文本生成推理支持)、Simon(在 Hugging Face 上开发新的访问控制特性)、Arthur、Younes、Sanchit(将 Gemma 集成到 transformers 中)、Morgan(将 Gemma 集成到 optimum-nvidia,即将推出)、Nathan、Victor、Mishig(使 Gemma 在 Hugging Chat 上可用)等众多社区成员的共同努力而成。
我们特别感谢 Google 团队发布 Gemma 并使其在开源 AI 社区中可用,为推动开放式人工智能发展做出了重要贡献。
查看本文链接,请点击阅读原文在 Hugging Face 博客上查看:
https://hf.co/blog/zh/gemma












![第十四章[面向对象]:14.9:定制类](https://img-blog.csdnimg.cn/img_convert/24185a6f8f5567accc7da3ae8eded796.jpeg)