B-Tree索引
(本文为《PostgreSQL数据库内核分析》一书的总结笔记,需要电子版的可私信我)
B+树特点:
- 非叶子节点含一个或多个关键字值和子节点指针,不指向实际数据的存储位置
- 所有关键字都是叶子节点,每个叶子节点指向实际数据,所有叶子构成了一个顺序链表

组织结构
B-Tree索引的页面组织结构:

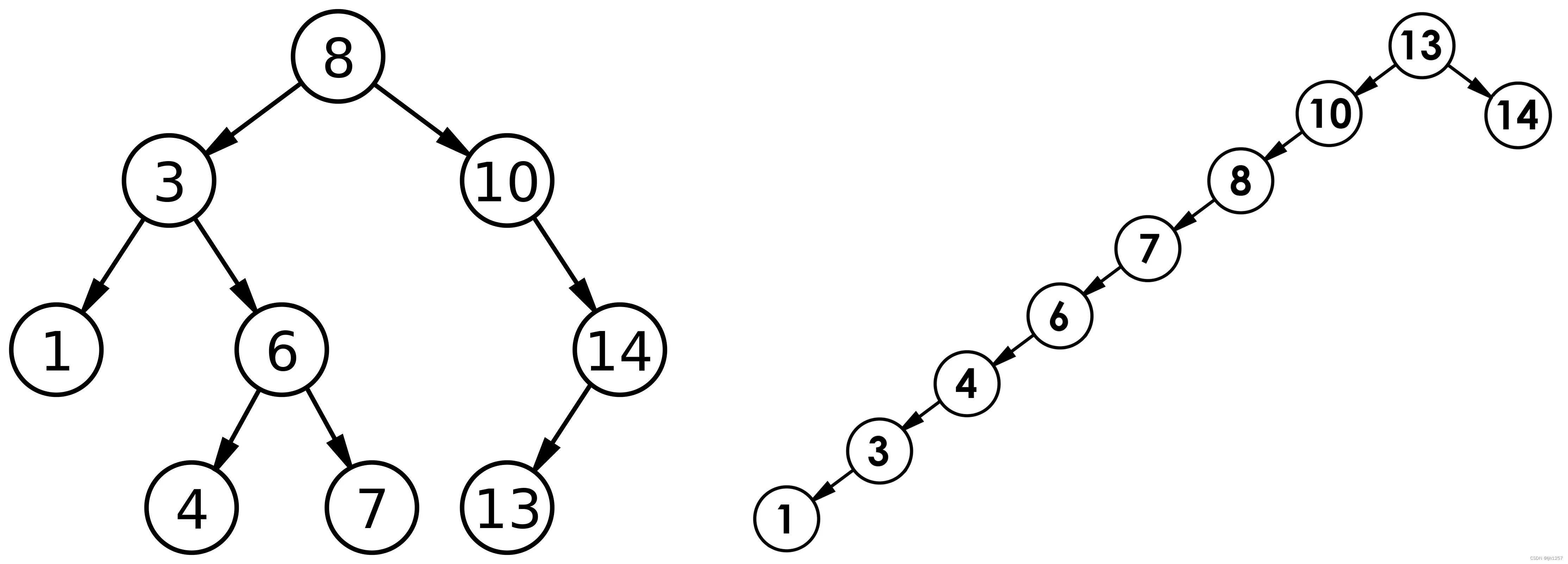
图中的itup1、itup2、itup3等都是索引元组,它们是有序的。在页面的“Page header”结构之后,是linp1、linp2…,它们存储了各个索引元组在页面内的实际位置,通过linp可以快速访问到索引元组。
根据B^link-Tree的要求,在每层非最右节点中,需要一个最大关键字(High-key),High-key并非一个真正的关键字,它只不过是给出该节点中的索引关键字的范围,在节点中的索引关键字都应小于等于其High-key。所以,如果要插入的关键字大于High-key,就需要向右边的节点移动来寻找合适的插入节点。
当构建一个索引页面完成后,需要设置该值。图4-3可以理解为在索引创建过程中的结构,当填充完成一个页面后,会进行【调整】。最右节点和非最右节点的结构是不一样的。每一个页面的“Page header”结构中保存了linp0(如图4-3,图中的linp0实际是包含在page header中的,为了描述方便,这里把它单独画出来),在填充页面过程中,linp0并没有赋值。
当页面填充完成后,根据节点类型进行以下两种不同的**【调整】**操作(这里假设一个页面填充了3个元组即不再允许插入新的元组,此时页面中有linp1 、 linp2、linp3分别指向itup1、itup2、itup3):
- 若该节点不为本层最右节点:
- 首先将itup3(节点中值最大的索引元组)复制到该节点的右兄弟节点中,然后将linp0指向itup3(页面中的High-key)。
- 然后去掉linp3。也就是说,使用linp0来指向页面中的High-key,由于High-key(linp0)只是作为一个索引节点中键值的范围,并不是指向实际元组(itup3),所以去掉指向itup3的链接linp3。
- 若该节点是本层的最右节点:由于最右节点不需要High-key,所以 linp0不需要用于保存High-key,则将所有的linp都递减一个位置,linp3同样不再使用。

按照图4-2的要求,在每个节点都有一个指针指向其右侧的兄弟节点,而PostgreSQL在实现时,使用了两个指针,分别指向左右兄弟节点。这两个指针是由页面尾部的一块称为Special的特殊区域保存的,其中存放了一个由BTPageOpaqueData结构表示的数据,该结构记录了该节点在树结构中的左右兄弟节点的指针以及页面类型等信息。
BTPageOpaqueData结构

页面类型btpo_flags:
BTP_LEAF:叶子页面,没有该标志则表示非叶子页面。BTP_ROOT:根页面(根页面没有父节点)。BTP_DELETED:页面已经从树中删除。BTP_META:元页面。BTP_HALF_DEAD:空页面,但是还保留在树中。BTP_SPLIT_END:在一次页面的分裂中,待分裂的最右一个页面。BTP_HAS_GARBAGE:页面中含有LP_DEAD元组。当对索引页面中某些元组进行了删除后,该索引页面并没有立即从物理上删除这些元组,这些元组仍然保留在索引页面中,只是对这些元组进行了标记,同时索引页面中其他有效的元组保持不变。
btpo_cycleid字段:
若页面发生分裂,btpo_cycleid字段记录了当前页面最新的**“Vacuum cycle ID”**,该值可用于确定哪些页面需要进行VACUUM。
比如,现在有页面“A←→B”,当页面A发生分裂后,得到“A←→C←→B”,此时页面A和C中的元组发生了更改,其btpo_cycleid字段会重新分配值,而与B的值不同,当运行VACUUM时,由于B页面中的元组并未改变,因此不需要进行回收,这就可以通过比较页面的btpo_cycleid字段来实现。
上面分别介绍了索引页面的内部结构和兄弟节点的连接,那么一个完整的索引组织结构如图4-5所示。可以看到,左侧叶子节点的itup3(该节点的"High-key")和其右侧兄弟节点的itup1(该节点的最小值)都指向相同的堆元组,这正是在上面介绍“High-key"时的操作决定的。

在图4-5中,虚线上方的表示索引结构,虚线下方的为表元组。在叶子节点层,索引元组的指针指向表元组。
每一个索引节点对应一个索引页面,内部节点(包括根节点)与叶子节点的内部结构是一致的,不同的是:
- 内部节点指向下一层的指针是指向索引节点
- 叶子节点是指向物理存储的某个位置(也就是实际存放元组的位置)。
B-Tree索引的操作
按照pg_am系统表的规定,B-Tree索引所对应的统一接口调用的函数为:btbuild、btinsert、btbeginscan、btgettuple、btgetbitmap、btrescan、btendscan、btmarkpos、btrestrpos、btbulkdelete、btvacuumcleanup、btcostestimate和btoptions。
这些函数都在sre/backend /access/nbtree目录中实现,nbtree目录中的其他函数都直接或间接为以上13个函数服务,下面将选取其中一些重要的函数进行详细分析,对其他的函数只作功能上的简单说明。
索引的创建
PostgreSQL系统创建B-Tree索引时,首先将对每一个需要索引的表元组生成对应的索引元组,然后调用tuplesort函数对所有的索引元组进行排序,最后创建索引。
索引元组是一个索引结构的基本单位,由IndexTupleData表示。B-Tree索引和Hash索引的索引元组结构都是一样的,都是由IndexTupleData进行存储,该结构包括了该索引元组所指向的表元组以及一些索引元组的信息。
IndexTupleData索引元组结构

t_tid属性
/*
* ItemPointer:
*
* This is a pointer to an item within a disk page of a known file
* (for example, a cross-link from an index to its parent table).
* blkid tells us which block, posid tells us which entry in the linp
* (ItemIdData) array we want.
*/
typedef struct ItemPointerData
{
BlockIdData ip_blkid;
OffsetNumber ip_posid;
}
t_info属性(16位数字)
- 第15位:该元组是否为null。
- 第14位:是否有可变长度的属性。
- 第13位:未使用。
- 第12位至第0位:索引元组的大小。
在将表元组封装成索引元组(索引项)的过程中,会生成一个 BTBuildState 结构用于保存索引元组,其结构如数据结构4.4所示。
BTBuildState保存全部索引元组

BTBuildState结构保存了两个BTSpool类型:spool和spool2。
spool2只是在创建唯一索引时才需要使用。
由于从PostgreSQL 8.3开始使用HOT 链,在扫描表元组时,获取到的元组可能是“deadtuple”(实际更新后的表元组可以通过HOT链找到),对于这样的表元组,会将封装得到的索引元组放在spool2里。由于spool2里面的索引元组都不是最新的,那么对于唯一索引,就没有必要检查这些元组是否唯一,可以直接插入到索引结构中。(deadtuple也是索引结构的一部分)
元页metadataPage
每个B-Tree索引都有一个元页(metadataPage),它主要说明该B-Tree 的版本、根节点位置(块号)以及根节点在树中的层次等信息,元页始终位于B-Tree索引的第一页(编号为0)。
由于元页相关的信息只有在索引创建完成后才能够获得,因此元页会预留,一直等到索引创建完成后,才会生成元页并赋值。
元页用BTMetaPageData结构表示,该结构主要是用来保存B-Tree的根节点(root)以及有效根节点(fastroot)的相关信息,主要包括根节点、有效根节点所在的磁盘块号以及有效根节点所在的层次。

magic号标识是B-Tree的一个编号,这个值在所有的B-Tree里都是一样的,用于完整性检查和辅助调试,确定该结构确实是B-Tree的元页。fastroot是有效根节点。由于大量的删除操作可能导致根节点下面出现单节点层(所谓单节点是指从根节点到子节点之间其实只有唯一的一条路径),用fastroot记录索引中最底层的单节点层(叶子层为最底层),对B-Tree的操作(查找、插入等)均从fastroot开始,这样可提升效率。下面以一个简单的 B-Tree 结构来说明root和fastroot,如图4-6所示。root为实际的根节点,但root只有一个子节点。所以对该树进行查找时,可直接从fastroot节点开始查找,从而加快速度。

BTWriteState结构
创建一个B-Tree索引,首先会生成一个BTWriteState结构,它用于记录整个索引创建过程中的信息,如数据结构4.6所示。

btws_pages_alloced:在创建索引的过程中,随着不断添加索引元组,索引关系所占用的页面也会不断增加。根据分配的先后顺序,索引结构的页面编号(块号)依次递增,btws_pages_alloced字段记录的正是分配给下一次申请的page 的块号。btws_pages_written:在创建索引时,若一个页面(节点)已填充满,后面的元组则会填充到新申请的页面中,这时就会把填满的页面写入文件中,该页面中的内容就不再改变,btws_pages_written字段正是记录了当前已写入文件的块号。btws_zeropage:若当前需要写入的页面块号大于btws_pages_written,则位于二者中间的页面需要填充为“0”。可能的一种情况是:由于元页都位于索引结构中的第一页(编号为0),但元页是在整个索引结构创建完成后才写入的(预留),所以最开始分配给索引的块号是1,当去写块号为1的页面到文件中时,会发现块号为0的页面还没有写入,就会对0号页面填充“0”值。
BTPageState索引树层结构
在创建B-Tree索引时,对于树结构中的每一层都会生成一个结构BTPageState,如数据结构4.7所示。

在BTPageState结构中,使用btps_next指针来指向父节点(我的理解是下一层)的目的是:
- 当该节点中关键字变化导致需要调整父节点中的关键字时,可通过该指针快速定位到父节点。
- 当所有索引元组都插入到索引结构中后,需要调整每一层最右节点,就会用到这个指针,在后面讲解函数**_bt_uppershutdown**时会分析。
在创建索引的过程中,对于每一个层次的所有页面,只有一个BTPageState结构。当一个页面填充满后,会申请一个新的页面,这时 BTPageState 结构(page 信息、minkey 等)随即更新为新页面中的信息(就是说记录了该层最右节点的信息)。
上面介绍了在创建索引过程中使用到的主要数据结构,下面将使用这些结构来完成对索引的创建。
- 首先将待索引的表元组封装为索引元组,并对索引元组进行排序。
- 然后将排好序的索引元组填充到当前叶子节点中,若当前叶子节点填充满,则新申请一个叶子节点作为当前叶子节点的右兄弟节点,
- 然后在父节点中添加指向新叶子节点的指针(没有父节点则创建父节点),
- 接下来把新申请的节点作为当前叶子节点。
- 重复这个过程,直到添加完成所有的索引元组为止。
创建索引的入口函数btbuild
其流程如图所示:

btbuild函数首先调用IndexBuildHeapScan函数对表进行扫描,将每一个表元组都封装成索引元组,在扫描的过程中判断表元组是否为“dead tuple”,然后将得到的索引元组插入到不同的spool中。
Datum
btbuild(PG_FUNCTION_ARGS)
{
Relation heap = (Relation) PG_GETARG_POINTER(0);
Relation index = (Relation) PG_GETARG_POINTER(1);
IndexInfo *indexInfo = (IndexInfo *) PG_GETARG_POINTER(2);
IndexBuildResult *result;
double reltuples;
BTBuildState buildstate;
// 初始化BTBuildState结构
buildstate.isUnique = indexInfo->ii_Unique;
buildstate.haveDead = false;
buildstate.heapRel = heap;
buildstate.spool = NULL;
buildstate.spool2 = NULL;
buildstate.indtuples = 0;
#ifdef BTREE_BUILD_STATS
if (log_btree_build_stats)
ResetUsage();
#endif /* BTREE_BUILD_STATS */
/*
* We expect to be called exactly once for any index relation. If that's
* not the case, big trouble's what we have.
*/
if (RelationGetNumberOfBlocks(index) != 0)
elog(ERROR, "index \"%s\" already contains data",
RelationGetRelationName(index));
buildstate.spool = _bt_spoolinit(index, indexInfo->ii_Unique, false);
/*
* If building a unique index, put dead tuples in a second spool to keep
* them out of the uniqueness check.
*/
if (indexInfo->ii_Unique)
buildstate.spool2 = _bt_spoolinit(index, false, true);
/* do the heap scan */ // <--<--
reltuples = IndexBuildHeapScan(heap, index, indexInfo, true,
btbuildCallback, (void *) &buildstate);
/* okay, all heap tuples are indexed */
if (buildstate.spool2 && !buildstate.haveDead)
{
/* spool2 turns out to be unnecessary */
_bt_spooldestroy(buildstate.spool2);
buildstate.spool2 = NULL;
}
/*
* Finish the build by (1) completing the sort of the spool file, (2)
* inserting the sorted tuples into btree pages and (3) building the upper
* levels.
*/
_bt_leafbuild(buildstate.spool, buildstate.spool2);// <--<--
_bt_spooldestroy(buildstate.spool);
if (buildstate.spool2)
_bt_spooldestroy(buildstate.spool2);
#ifdef BTREE_BUILD_STATS
if (log_btree_build_stats)
{
ShowUsage("BTREE BUILD STATS");
ResetUsage();
}
#endif /* BTREE_BUILD_STATS */
/*
* If we are reindexing a pre-existing index, it is critical to send out a
* relcache invalidation SI message to ensure all backends re-read the
* index metapage. We expect that the caller will ensure that happens
* (typically as a side effect of updating index stats, but it must happen
* even if the stats don't change!)
*/
/*
* Return statistics
*/
result = (IndexBuildResult *) palloc(sizeof(IndexBuildResult));
result->heap_tuples = reltuples;
result->index_tuples = buildstate.indtuples;
PG_RETURN_POINTER(result);
}
IndexBuildHeapScan封装、扫描函数

IndexBuildHeapScan会传入一个回调函数,然后通过调用callback(indexRelation, &rootTuple, values, isnull, tupleIsAlive,callback_state);去将索引元组插入到不同的spool中。
具体callback函数是btbuildCallback、传入的callback_state是buildstate
static void
btbuildCallback(Relation index,
HeapTuple htup,
Datum *values,
bool *isnull,
bool tupleIsAlive,
void *state)
{
BTBuildState *buildstate = (BTBuildState *) state;
IndexTuple itup;
/* form an index tuple and point it at the heap tuple */
itup = index_form_tuple(RelationGetDescr(index), values, isnull);
itup->t_tid = htup->t_self;
/*
* insert the index tuple into the appropriate spool file for subsequent
* processing
*/
if (tupleIsAlive || buildstate->spool2 == NULL)
_bt_spool(itup, buildstate->spool);
else
{
/* dead tuples are put into spool2 */
buildstate->haveDead = true;
_bt_spool(itup, buildstate->spool2);
}
buildstate->indtuples += 1;
pfree(itup);
}
_bt_leafbuild函数
执行完对表元组的扫描后,即调用_bt_leafbuild函数。
- 该函数首先定义创建索引结构需要的BTWriteState结构,然后调用排序函数对spool(和spoo2)中的索引元组进行排序。
- 若为唯一索引,在排序时会进行检查是否有重复的元组。
- 排序完成后,会调用**_bt_load函数顺序读取出spool中的元组(已经排序)。对每个索引元组调用_bt_buildadd**函数(将索引元组添加到索引结构中,会处理分裂等情况)。
- 若spool2不为空,则在添加索引元组到索引结构中时会使用归并的方法:按照索引元组的偏序关系,从小到大把 spool和 spool2 中的索引元组添加到索引结构中。
- 当所有索引元组添加完成后,调用_bt_uppershutdown函数完善索引结构,并写入元页的信息(在前面讲到,元页信息是在索引结构创建完成后才写入的)。
总的来说,_bt_leafbuild函数扫描有序的索引元组,并构建出索引的树结构,其流程如图所示。

/*
* given a spool loaded by successive calls to _bt_spool,
* create an entire btree.
*/
void
_bt_leafbuild(BTSpool *btspool, BTSpool *btspool2)
{
BTWriteState wstate;//该函数首先定义创建索引结构需要的BTWriteState结构
#ifdef BTREE_BUILD_STATS
if (log_btree_build_stats)
{
ShowUsage("BTREE BUILD (Spool) STATISTICS");
ResetUsage();
}
#endif /* BTREE_BUILD_STATS */
// 然后调用排序函数对spool(和spoo2)中的索引元组进行排序。
tuplesort_performsort(btspool->sortstate);
// 若spool2不为空,则在添加索引元组到索引结构中时会使用归并的方法:按照索引元组的偏序关系,从小到大把 spool和 spool2 中的索引元组添加到索引结构中。
if (btspool2)
tuplesort_performsort(btspool2->sortstate);
wstate.index = btspool->index;
/*
* We need to log index creation in WAL iff WAL archiving is enabled AND
* it's not a temp index.
*/
wstate.btws_use_wal = XLogArchivingActive() && !wstate.index->rd_istemp;
/* reserve the metapage */
wstate.btws_pages_alloced = BTREE_METAPAGE + 1;
wstate.btws_pages_written = 0;
wstate.btws_zeropage = NULL; /* until needed */c
// 排序完成后,会调用**_bt_load**函数顺序读取出spool中的元组(已经排序)。
// 对每个索引元组调用**_bt_buildadd**函数
// 按照索引元组的偏序关系,从小到大把spool和spool2中的索引元组添加到索引结构中;会处理分裂等情况。
_bt_load(&wstate, btspool, btspool2);
}

在调用**_bt_buildadd**函数时,spool(spoo2)中所有的索引元组都已经有序,则依次取出 spool中的索引元组,将其添加到索引结构中,_bt_buildadd函数正是完成将一个索引元组插入到索引结构的工作。
_bt_buildadd函数不会去检查插入的索引元组与节点中已有元组的偏序关系,而是直接插入。
- 若插入时,发现该节点的空闲空间不够,则会申请一个页面作为右兄弟节点(新节点),然后设置旧节点的“High-key”。
- 接着通过当前层次的BTPageState.btps_next 查找其父节点(若没有父节点则创建一个),将旧节点的min key(最小键值)插入到父节点中(还是调用**_bt_buildadd**函数,这种递归调用实现了向上层调整索引结构),然后设置新旧节点的兄弟关系(左右指针链接)。
- 由于旧节点已完成填充不会再修改,因此调用**_bt_blwritepage**函数将旧节点的信息写入索引文件,同时修改索引的BTWriteState结构。
- 最后调用**_bt_sortaddtup**函数将待插入的索引元组插入节点(若一开始检查节点有足够的空间则直接跳到这一步),并更新该层的BTPageState结构(若申请了新页面,则以后插入节点都是对新页面进行操作)。
_bt_buildadd函数
执行流程:

在图4-9中,给出了一个插入过程中索引结构变化的例子,这里假设一个节点里最多存放两个元组。图4-9a到图4-9d反映了索引结构的变化。图中数字的第一位表示层数,第二位表示该节点是该层第几个节点。可以看出,当申请一个新的最右节点时,它与左兄弟节点的链接关系会立即构建,但与父节点的链接关系并没有设定。
static void
_bt_buildadd(BTWriteState *wstate, BTPageState *state, IndexTuple itup)
{
Page npage;
BlockNumber nblkno;
OffsetNumber last_off;
Size pgspc;
Size itupsz;
/*
* This is a handy place to check for cancel interrupts during the btree
* load phase of index creation.
*/
CHECK_FOR_INTERRUPTS();
npage = state->btps_page;
nblkno = state->btps_blkno;
last_off = state->btps_lastoff;
pgspc = PageGetFreeSpace(npage);
itupsz = IndexTupleDSize(*itup);
itupsz = MAXALIGN(itupsz);
if (itupsz > BTMaxItemSize(npage))
ereport(ERROR,
(errcode(ERRCODE_PROGRAM_LIMIT_EXCEEDED),
errmsg("index row size %lu exceeds btree maximum, %lu",
(unsigned long) itupsz,
(unsigned long) BTMaxItemSize(npage)),
errhint("Values larger than 1/3 of a buffer page cannot be indexed.\img\n"
"Consider a function index of an MD5 hash of the value, "
"or use full text indexing.")));
/*
* Check to see if page is "full". It's definitely full if the item won't
* fit. Otherwise, compare to the target freespace derived from the
* fillfactor. However, we must put at least two items on each page, so
* disregard fillfactor if we don't have that many.
申请一个页面作为右兄弟节点(新节点),然后设置旧节点的“High-key”。
*/
if (pgspc < itupsz || (pgspc < state->btps_full && last_off > P_FIRSTKEY))
{
/*
* Finish off the page and write it out.
*/
Page opage = npage;
BlockNumber oblkno = nblkno;
ItemId ii;
ItemId hii;
IndexTuple oitup;
/* Create new page of same level */
npage = _bt_blnewpage(state->btps_level);
/* and assign it a page position */
nblkno = wstate->btws_pages_alloced++;
Assert(last_off > P_FIRSTKEY);
ii = PageGetItemId(opage, last_off);
oitup = (IndexTuple) PageGetItem(opage, ii);
_bt_sortaddtup(npage, ItemIdGetLength(ii), oitup, P_FIRSTKEY);
/*
* Move 'last' into the high key position on opage
设置旧节点的“High-key”
*/
hii = PageGetItemId(opage, P_HIKEY);//#define P_HIKEY ((OffsetNumber) 1)
/*
#define PageGetItemId(page, offsetNumber) \
((ItemId) (&((PageHeader) (page))->pd_linp[(offsetNumber) - 1]))
*/
*hii = *ii;
ItemIdSetUnused(ii); /* redundant */
((PageHeader) opage)->pd_lower -= sizeof(ItemIdData);
/*
* Link the old page into its parent, using its minimum key. If we
* don't have a parent, we have to create one; this adds a new btree
* level.
通过当前层次的BTPageState.btps_next 查找其父节点(若没有父节点则创建一个),
*/
if (state->btps_next == NULL)
state->btps_next = _bt_pagestate(wstate, state->btps_level + 1);
Assert(state->btps_minkey != NULL);
// 将旧节点的minkey(最小键值)插入到父节点中
//(还是调用_bt_buildadd函数,这种递归调用实现了向上层调整索引结构)。
ItemPointerSet(&(state->btps_minkey->t_tid), oblkno, P_HIKEY);
_bt_buildadd(wstate, state->btps_next, state->btps_minkey);
pfree(state->btps_minkey);
/*
* Save a copy of the minimum key for the new page. We have to copy
* it off the old page, not the new one, in case we are not at leaf
* level.
*/
state->btps_minkey = CopyIndexTuple(oitup);
/*
* Set the sibling links for both pages.
然后设置新旧节点的兄弟关系(左右指针链接)
*/
{
BTPageOpaque oopaque = (BTPageOpaque) PageGetSpecialPointer(opage);
BTPageOpaque nopaque = (BTPageOpaque) PageGetSpecialPointer(npage);
oopaque->btpo_next = nblkno;
nopaque->btpo_prev = oblkno;
nopaque->btpo_next = P_NONE; /* redundant */
}
/*
* Write out the old page. We never need to touch it again, so we can
* free the opage workspace too.
调用_bt_blwritepage函数将旧节点的信息写入索引文件,同时修改索引的BTWriteState结构。
*/
_bt_blwritepage(wstate, opage, oblkno);
/*
* Reset last_off to point to new page
*/
last_off = P_FIRSTKEY;
}
/*
* 【If the new item is the first for its page】, stash a copy for later. Note
* this will only happen for the first item on a level; on later pages,
* the first item for a page is copied from the prior page in the code
* above.
*/
if (last_off == P_HIKEY)// hikey其实就是新page的第一个元组(它们底层指向相同的物理元组)
{
Assert(state->btps_minkey == NULL);
state->btps_minkey = CopyIndexTuple(itup);// 将待插入元组复制了一份(内存空间是新分配的,但存的东西一样)
}
/*
* Add the new item into the current page.
最后调用_bt_sortaddtup函数将待插入的索引元组插入节点(若一开始检查节点有足够的空间则直接跳到这一步),并更新该层的BTPageState结构(若申请了新页面,则以后插入节点都是对新页面进行操作)
*/
last_off = OffsetNumberNext(last_off);
_bt_sortaddtup(npage, itupsz, itup, last_off);
state->btps_page = npage;
state->btps_blkno = nblkno;
state->btps_lastoff = last_off;
}
当所有索引节点插入完成后,每一层的最右节点的链接关系是由函数**_bt_uppershutdown**来完成的。
当读取完成spool结构中的索引元组后,得到了初步的索引结构,但结构中每层最右节点与父节点的指针链接还没有构建,这需要调用函数_bt_uppershutdown 来完成。之前讲解BTPageState结构时提到,该结构内有一个指针指向上一层的BTPageState结构,可以把这个结构理解为一个“栈”,在调整最右节点时,依次出栈,设置子节点和父节点的链接关系,直到“栈”为空则调整完毕,索引结构构建完成。
_bt _uppershutdown函数的流程如图4-10所示。
_bt_uppershutdown函数

static void
_bt_uppershutdown(BTWriteState *wstate, BTPageState *state)//每一层一个BTPageState结构
{
BTPageState *s;
BlockNumber rootblkno = P_NONE;
uint32 rootlevel = 0;
Page metapage;
/*
* Each iteration of this loop completes one more level of the tree.
*/
for (s = state; s != NULL; s = s->btps_next)// btps_next指向父节点,去到上一层
{
BlockNumber blkno;
BTPageOpaque opaque;
blkno = s->btps_blkno;
opaque = (BTPageOpaque) PageGetSpecialPointer(s->btps_page);
if (s->btps_next == NULL)// 根节点
{
opaque->btpo_flags |= BTP_ROOT;
rootblkno = blkno;
rootlevel = s->btps_level;
}
else
{
Assert(s->btps_minkey != NULL);
ItemPointerSet(&(s->btps_minkey->t_tid), blkno, P_HIKEY);
// 将索引元组添加到索引结构中
_bt_buildadd(wstate, s->btps_next, s->btps_minkey);
pfree(s->btps_minkey);
s->btps_minkey = NULL;
}
/*
* This is the rightmost page, so the ItemId array needs to be slid
* back one slot. Then we can dump out the page.
*/
_bt_slideleft(s->btps_page);
_bt_blwritepage(wstate, s->btps_page, s->btps_blkno);
s->btps_page = NULL; /* writepage freed the workspace */
}
// 写入元页的信息
metapage = (Page) palloc(BLCKSZ);
_bt_initmetapage(metapage, rootblkno, rootlevel);
_bt_blwritepage(wstate, metapage, BTREE_METAPAGE);
}
通过上面讲解的函数调用流程,函数_bt_uppershutdown执行完成后,就得到完整的索引结构,也设置了索引结构的元页信息,最后再释放内存,整个索引即创建完毕。
索引的插入
若对一个表中的某个属性创建了索引,当表中有新的元组插入时,索引也需要进行相应的更新,也就是将新插入的元组封装成索引元组并插入到索引中,这个过程由btinsert函数完成。
btinsert函数
- 首先将表元组封装为索引元组
- 然后沿着B-Tree往下找到合适的插入节点
- 找到正确的节点后,若该索引关系是唯一索引,则会在节点中验证待插入的元组是否已存在,
- 若存在则报错结束
- 如果索引不是唯一索引或者没有重复元组,则将索引元组插入到索引中。
- 在从根节点往下查找合适的节点过程中,会使用结构BTStackData来保存查找过程中的父节点,即保存查找路径。当插入后需要分裂叶子节点时,可以根据栈中存储的对应关系找到所有的父节点,并根据情况依次对父节点进行调整。
BTStackData结构的定义如数据结构4.8所示:

在插入过程中还应考虑插入元组后节点的分裂问题。如果该节点需要进行分裂,则需要在该节点中找到合适的分裂位置。在PostgreSQL中规定,如果该节点为该层中的最右节点,那么分裂后产生的右节点的剩余空间最好应该是分裂产生的左节点剩余空间的2倍;否则分裂产生的两个节点的剩余空间最好应该相等。
当需要分裂节点时,会生成FindSplitData结构,它用来记录寻找节点分裂位置时的相关信息,特别是【节点的最佳分裂位置】以及【待插入的新元组】的相关信息。
其结构的定义如数据结构4.9所示。

说明:
-
best_delta:是根据页面的空闲空间除以16得到的一个参考值,用于确定分裂位置。 -
fillfactor:一个索引的填充因子,它是一个百分比,表示创建索引时每个索引页的数据填充率。对于B-Tree来说,在创建索引时节点将按照此百分比填充数据,在右侧(最大的键值)扩展索引时同样也按照此百分比填充数据。如果后来某个页被完全填满,那么该页将被分裂,从而导致索引性能退化。(填充因子越小,创建索引时节点数越多,节点位置上空闲位置越多,后续插入时就可以减少分裂)B-Tree默认的填充因子是90,但是有效的取值范围是10 ~100。
- 对于静态的不会发生改变的表,最佳值100可以让索引的物理体积最小,但是对于不断增长的表,较小的填充因子更合适,因为这将尽可能减少对页的分裂。其他索引方法对填充因子的理解与此类似,但是其默认值各不相同。
- 如果有条件周期性地重建索引,那么建议使用较大的填充因子以减少索引的物理体积。用户可以在创建索引时指定fillfactor的值。
在实际构建B-Tree索引时,每个节点往往并没有按照该节点能够容纳关键字的个数完全填满,而是保留了一定的“空位”。这样虽然会带来一定空间的浪费,但可以避免在插入元组时过于频繁地分裂节点。
用户在创建索引时,可通过指定一个索引的填充因子(fillfactor),来设定创建索引时每个索引页面的数据填充率。若用户没有设定,则B-Tree索引默认的规定如下:
- 在叶子节点中加入的索引元组的总大小如果超过页面大小的90%就视为充满。
- 在内部节点中加入索引元组的总大小如果超过页面大小的70%就视为充满。
- 分裂节点时,如果该节点为该层的最右节点,必须保证分裂后的左节点的空闲空间为(100-fillfactor) %,否则应保持左右节点空闲空间相等。
如下面的语句将在表films 上的title属性上创建B-Tree索引,但不使用默认的fillfactor,设定为70:
CREATE INDEX stu_id_idx ON student (id) WITH (fillfactor =70) ;
在代码实现时,封装了多个函数来实现插入元组的功能,实现这些操作的入口函数是btinsert函数。
该函数首先将表元组封装成索引元组,然后调用_bt_doinsert函数将索引元组插入到索引,
_bt_doinsert函数
_bt_doinsert的流程如图4-11所示:

void
_bt_doinsert(Relation rel, IndexTuple itup,
bool index_is_unique, Relation heapRel)
{
int natts = rel->rd_rel->relnatts;
ScanKey itup_scankey;
BTStack stack;
Buffer buf;
OffsetNumber offset;
/* we need an insertion scan key to do our search, so build one
调用_bt_mkscankey函数计算元组的扫描键值scan key
*/
itup_scankey = _bt_mkscankey(rel, itup);
top:
/* 【find the first page containing this key】
调用_bt_search函数查找应该包含索引元组的页面
*/
stack = _bt_search(rel, natts, itup_scankey, false, &buf, BT_WRITE);
offset = InvalidOffsetNumber;
/* trade in our read lock for a write lock */
LockBuffer(buf, BUFFER_LOCK_UNLOCK);
LockBuffer(buf, BT_WRITE);
/*
* If the page was split between the time that we surrendered our read
* lock and acquired our write lock, then this page may no longer be the
* right place for the key we want to insert. In this case, we need to
* move right in the tree. See Lehman and Yao for an excruciatingly
* precise description.
考虑到并发性,调用_bt_moveright函数
*/
buf = _bt_moveright(rel, buf, natts, itup_scankey, false, BT_WRITE);
/*
* If we're not allowing duplicates, make sure the key isn't already in
* the index.
如果是唯一索引则进行唯一性检查,没有则跳过
*/
if (index_is_unique)
{
TransactionId xwait;
offset = _bt_binsrch(rel, buf, natts, itup_scankey, false);
xwait = _bt_check_unique(rel, itup, heapRel, buf, offset, itup_scankey);
if (TransactionIdIsValid(xwait))
{
/* Have to wait for the other guy ... */
_bt_relbuf(rel, buf);
XactLockTableWait(xwait);
/* start over... */
_bt_freestack(stack);
goto top;
}
}
/* do the insertion
调用_bt_findinsertloc函数在当前页面查找到索引元组合适的插入位置
*/
_bt_findinsertloc(rel, &buf, &offset, natts, itup_scankey, itup);
// 调用_bt_insertonpg函数进行插入
_bt_insertonpg(rel, buf, stack, itup, offset, false);
/* be tidy */ //释放内存
_bt_freestack(stack);
_bt_freeskey(itup_scankey);
}
_bt_search函数
在图4-11中,首先调用_bt_search函数根据索引结构查找该索引元组应该存放的节点。这些节点都放在BTStackData栈中,这主要是考虑到后面插入索引元组时可能会导致节点分裂的情况。
_bt_search函数调用了 _bt_binsrch函数来实现当前页面的查找,根据查找节点的不同类型, _bt_binsrch函数的返回值可能为:
- 若当前节点为叶子节点,则返回当前节点中第一个满足“key >=scankey”的位置。
- 若当前节点为内部节点,则返回当前节点中最后一个满足“key <scankey”的位置。
若为内部节点,则根据查找到的位置的元组找到其指向的子节点,然后循环向下查找,越往下,key之间的粒度越细。

BTStack
_bt_search(Relation rel, int keysz, ScanKey scankey, bool nextkey,
Buffer *bufP, int access)
{
BTStack stack_in = NULL;
/* Get the root page to start with 获取索引结构的根节点(可能为fast root)*/
*bufP = _bt_getroot(rel, access);
/* If index is empty and access = BT_READ, no root page is created. */
if (!BufferIsValid(*bufP))
return (BTStack) NULL;
/* Loop iterates once per level descended in the tree */
for (;;)
{
Page page;
BTPageOpaque opaque;
OffsetNumber offnum;
ItemId itemid;
IndexTuple itup;
BlockNumber blkno;
BlockNumber par_blkno;
BTStack new_stack;
/*
* Race -- the page we just grabbed may have split since we read its
* pointer in the parent (or metapage). If it has, we may need to
* move right to its new sibling. Do that.
考虑到并发性,调用bt_moveright函数确保访问的是正确的节点
*/
*bufP = _bt_moveright(rel, *bufP, keysz, scankey, nextkey, BT_READ);
/* if this is a leaf page, we're done */
page = BufferGetPage(*bufP);
opaque = (BTPageOpaque) PageGetSpecialPointer(page);
if (P_ISLEAF(opaque))// 判断当前页面是否为叶子节点,是则终止查询
break;
/*
* Find the appropriate item on the internal page, and get the child
* page that it points to.
调用_bt_binsrch函数在当前页面找到合适的元组itup
*/
offnum = _bt_binsrch(rel, *bufP, keysz, scankey, nextkey);
itemid = PageGetItemId(page, offnum);
itup = (IndexTuple) PageGetItem(page, itemid);
blkno = ItemPointerGetBlockNumber(&(itup->t_tid));
par_blkno = BufferGetBlockNumber(*bufP);
/*
将当前页面的信息入栈BTStackData
* We need to save the location of the index entry we chose in the
* parent page on a stack. In case we split the tree, we'll use the
* stack to work back up to the parent page. We also save the actual
* downlink (TID) to uniquely identify the index entry, in case it
* moves right while we're working lower in the tree. See the paper
* by Lehman and Yao for how this is detected and handled. (We use the
* child link to disambiguate duplicate keys in the index -- Lehman
* and Yao disallow duplicate keys.)
*/
new_stack = (BTStack) palloc(sizeof(BTStackData));
new_stack->bts_blkno = par_blkno;
new_stack->bts_offset = offnum;
memcpy(&new_stack->bts_btentry, itup, sizeof(IndexTupleData));
// 将当前页面设置为itup指向的子节点
new_stack->bts_parent = stack_in;
/* drop the read lock on the parent page, acquire one on the child */
*bufP = _bt_relandgetbuf(rel, *bufP, blkno, BT_READ);
/* okay, all set to move down a level */
stack_in = new_stack;
}
return stack_in;
}
从图4-11中可以看到,_ bt_doinsert 函数和 _ bt_search 函数都调用了 _bt_moveright函数,该函数是根据Lehman 和Yao的论文中的要求而实现的。
在高并发的情况下进行当前查找操作的同时,可能有另一个操作正在分裂当前页面,那么当前获得的页面在分裂操作完成之后,可能不再是正确的页面(假如不是正确的,那么正确的页面只可能是在右兄弟页面),那么这个时候就要往右查找到正确的页面, _bt_moveright就是实现这个功能的,具体信息可以参考原论文。
函数_bt_search执行完成后,即得到了查找路径的栈结构及用于插入的叶子节点。若是唯一索引,则在待插人的叶子节点中进行唯一性检查,若检查到重复,则报错并结束。
否则接下来调用_bt_findinsertloc函数
_bt_findinsertloc函数
该函数实现在当前节点中查找到待插入元组合适的位置
_bt_findinsertloc函数查找的节点可能不会局限于当前的节点,还会到右兄弟节点中查找。
- 如果当前节点中的最大元组值和右兄弟节点中的最小节点值相等(即待插入的节点也是可以插入到右兄弟节点的),且当前节点中没有足够的剩余空间,则会再在右兄弟节点中查找
- 若右兄弟节点还是没有足够的空间,则结束查找并在后面具体进行插入操作时进行分裂操作。
查找到待插入的节点后,即调用**_bt_insertonpg函数**执行插入操作。
// _bt_insertonpg函数
/*
* Do we need to split the page to fit the item on it?
*
* Note: PageGetFreeSpace() subtracts sizeof(ItemIdData) from its result,
* so this comparison is correct even though we appear to be accounting
* only for the item and not for its line pointer.
*/
if (PageGetFreeSpace(page) < itemsz)
{
bool is_root = P_ISROOT(lpageop);
bool is_only = P_LEFTMOST(lpageop) && P_RIGHTMOST(lpageop);
bool newitemonleft;
Buffer rbuf;
/* Choose the split point */
firstright = _bt_findsplitloc(rel, page,
newitemoff, itemsz,
&newitemonleft);
/* split the buffer into left and right halves
找到合适的分裂点后,即调用函数_bt_split进行分裂操作。
该函数首先申请一个页面作为新的节点(右节点),
然后将页面中的元组根据分裂点元组确定是放入新节点还是旧节点(左节点)中,
最后将待插入的元组插入到节点中。*/
rbuf = _bt_split(rel, buf, firstright,
newitemoff, itemsz, itup, newitemonleft);
/*----------
* By here,
*
* + our target page has been split;
* + the original tuple has been inserted;
* + we have write locks on both the old (left half)
* and new (right half) buffers, after the split; and
* + we know the key we want to insert into the parent
* (it's the "high key" on the left child page).
*
* We're ready to do the parent insertion. We need to hold onto the
* locks for the child pages until we locate the parent, but we can
* release them before doing the actual insertion (see Lehman and Yao
* for the reasoning).
_bt_split函数执行完成后,得到的一个新的节点,需要将新节点作为一个元组插入到其父节点中,
插入到父节点中元组的键值是左节点的“High-key”,也就是右节点的最小值。
_bt_insert_parent 函数首先封装得到需要插入父节点的索引元组,然后调用_bt_insertonpg函数将元组插入到父节点中。在查找父节点时,就会使用到上面讲到的BTStackData栈结构。
*/
_bt_insert_parent(rel, buf, rbuf, stack, is_root, is_only);//stack查找父节点
}
该函数首先判断当前页面是否有足够的剩余空间,如果有则直接插入。如果没有则会调用**_bt_findsplitloc函数**遍历节点中的每个位置,检查其作为最佳分裂点的可行性,该查找过程有几个参数:
leftfree:分裂点为当前偏移量时,分裂后左节点的空闲空间(rightfree含义与此类似)。Delta:用于判断当前偏移量是否满足分裂条件,best_delta见数据结构4.8中FindSplitData的定义。
static OffsetNumber
_bt_findsplitloc(Relation rel,
Page page,
OffsetNumber newitemoff,
Size newitemsz,
bool *newitemonleft)
{
BTPageOpaque opaque;
OffsetNumber offnum;
OffsetNumber maxoff;
ItemId itemid;
FindSplitData state;
int leftspace,
rightspace,
goodenough,
olddataitemstotal,
olddataitemstoleft;
bool goodenoughfound;
opaque = (BTPageOpaque) PageGetSpecialPointer(page);
/* Passed-in newitemsz is MAXALIGNED but does not include line pointer */
newitemsz += sizeof(ItemIdData);
/* Total free space available on a btree page, after fixed overhead */
leftspace = rightspace =
PageGetPageSize(page) - SizeOfPageHeaderData -
MAXALIGN(sizeof(BTPageOpaqueData));
/* The right page will have the same high key as the old page */
if (!P_RIGHTMOST(opaque))
{
itemid = PageGetItemId(page, P_HIKEY);
rightspace -= (int) (MAXALIGN(ItemIdGetLength(itemid)) +
sizeof(ItemIdData));
}
/* Count up total space in data items without actually scanning 'em */
olddataitemstotal = rightspace - (int) PageGetExactFreeSpace(page);
state.newitemsz = newitemsz;
state.is_leaf = P_ISLEAF(opaque);
state.is_rightmost = P_RIGHTMOST(opaque);
state.have_split = false;
if (state.is_leaf)
state.fillfactor = RelationGetFillFactor(rel,
BTREE_DEFAULT_FILLFACTOR);
else
state.fillfactor = BTREE_NONLEAF_FILLFACTOR;
state.newitemonleft = false; /* these just to keep compiler quiet */
state.firstright = 0;
state.best_delta = 0;
state.leftspace = leftspace;
state.rightspace = rightspace;
state.olddataitemstotal = olddataitemstotal;
state.newitemoff = newitemoff;
/*
*/
goodenough = leftspace / 16;
/*
* Scan through the data items and calculate space usage for a split at
* each possible position.
*/
olddataitemstoleft = 0;
goodenoughfound = false;
maxoff = PageGetMaxOffsetNumber(page);
for (offnum = P_FIRSTDATAKEY(opaque);
offnum <= maxoff;
offnum = OffsetNumberNext(offnum))
{
Size itemsz;
itemid = PageGetItemId(page, offnum);
itemsz = MAXALIGN(ItemIdGetLength(itemid)) + sizeof(ItemIdData);
/*
* Will the new item go to left or right of split?
*/
if (offnum > newitemoff)
_bt_checksplitloc(&state, offnum, true,
olddataitemstoleft, itemsz);
else if (offnum < newitemoff)
_bt_checksplitloc(&state, offnum, false,
olddataitemstoleft, itemsz);
else
{
/* need to try it both ways! */
_bt_checksplitloc(&state, offnum, true,
olddataitemstoleft, itemsz);
_bt_checksplitloc(&state, offnum, false,
olddataitemstoleft, itemsz);
}
/* Abort scan once we find a good-enough choice */
if (state.have_split && state.best_delta <= goodenough)
{
goodenoughfound = true;
break;
}
olddataitemstoleft += itemsz;
}
/*
* If the new item goes as the last item, check for splitting so that all
* the old items go to the left page and the new item goes to the right
* page.
*/
if (newitemoff > maxoff && !goodenoughfound)
_bt_checksplitloc(&state, newitemoff, false, olddataitemstotal, 0);
/*
* I believe it is not possible to fail to find a feasible split, but just
* in case ...
*/
if (!state.have_split)
elog(ERROR, "could not find a feasible split point for index \"%s\"",
RelationGetRelationName(rel));
*newitemonleft = state.newitemonleft;
return state.firstright;
}
_bt_insertonpg函数
综上所述,_bt_insertonpg的执行流程如图4-12所示。

扫描索引
在利用索引进行查找等相关工作时需要使用扫描函数。使用B-Tree索引进行范围查询时,首先就要对索引进行扫描。在 PostgreSQL中,与扫描相关的函数主要有以下几个:
-
btgettuple函数:得到扫描中的下一个满足条件的索引元组。-
如果已经初始化了扫描信息(也就是说之前执行了扫描),只需要得到上一次的扫描位置,然后调用**_bt_next函数**根据扫描方向获取下一个满足扫描条件的索引元组;
-
如果没有初始化,就调用**_bt_first 函数**开始新的扫描。
该函数首先会预处理扫描信息,然后调用前面分析的**_bt_search函数**来实现扫描。最后将获取到的索引元组的TID返回。
-
-
btbeginscan函数:开始索引扫描。该函数根据需要扫描的索引的相关信息生成一个IndexScanDesc结构,该结构为指向IndexScanDescData的指针。IndexScanDescData结构中保存了扫描索引的相关信息,如扫描的键值、查找到的位置等,最后该函数返回IndexScanDesc结构。
-
btrescan函数:在某些情况下可能需要重新扫描索引,这时候就会调用btrescan函数,它的功能是重新开始一个索引扫描过程。 -
btendscan函数:此函数与btbeginscan函数成对出现,主要功能是释放进行一个索引扫描所占用的系统资源。 -
btmarkpos函数:当一个正在进行的索引扫描由于某种原因需要停止时,就需要调用btmarkpos函数,它将保存当前扫描位置的相关变量。 -
btrestrpos函数:与上面的btmarkpos 相对应,用btmarkpos中所存储的最后扫描位置信息,导入到当前扫描位置信息变量中,从而恢复到上次的扫描位置以后再开始扫描,这样可以节省扫描时间。
删除索引元组
在PostgreSQL中,删除B-Tree索引元组的函数主要有两个:
- 一个是查找需要删除的节点信息的函数btvacuumeleanup,该函数寻找可以删除的页面;
- 另一个是进行批量删除的函数btbulkdelete,该函数批量删除指向一个表元组集合所对应的所有索引元组。
在PostgreSQL中,若删除了基表中的一个元组,系统并不会立即删除该表元组对应的索引元组,而是在 VACUUM(清空)的时候删除。
删除操作从叶子节点开始查找,当删除索引元组后,需要根据叶子节点中索引元组的数量来决定是否对节点进行调整,具体操作如下:
If(删除后,节点仍有最小数目的关键字)// 不符合则说明该节点的节点数量小于最小限度
then 不做任何操作;
else if(同父相邻兄弟节点关键字个数大于最小限值)// 兄弟节点有足够数量节点的话,就从它上拿一个过来
then 从同父兄弟节点调剂关键字,并修改父节点中“键–指针”对;
else if(同父相邻兄弟节点关键字个数刚好等于最小限值)
then 与兄弟节点合并,并修改父节点中“键–指针”对。
如果删除父节点关键字导致其数目低于最小限值,则逐渐向上层做上述修改。
在B-Tree索引中,由函数btbulkdelete通过扫描索引确定基表中哪些元组被删除,而后逻辑上删除(标记删除)那些元组对应的索引元组,最后由VACUUM在物理上删除。