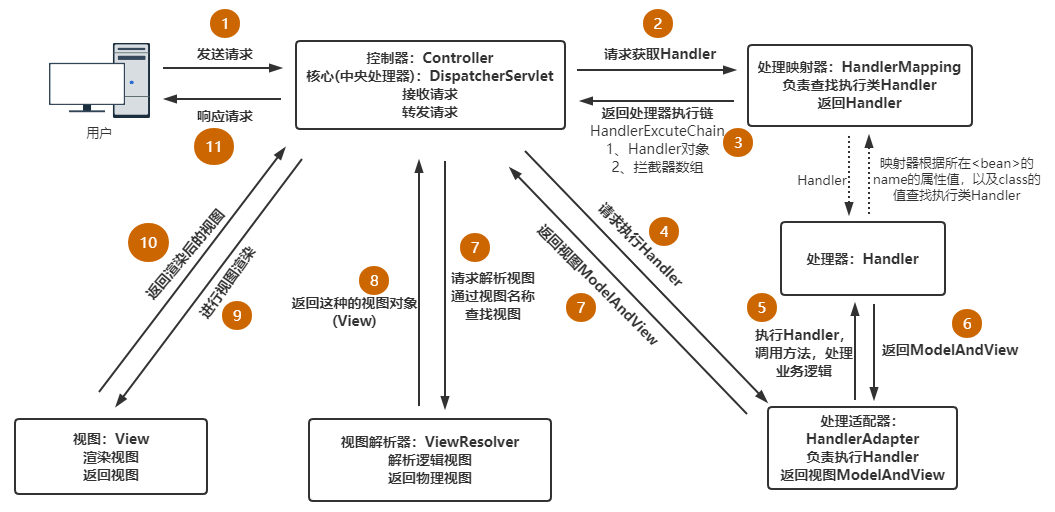
它主要包括三个部分:CLIP,先验模块prior和img decoder。其中CLIP又包含text encoder和img encoder。(在看DALL·E2之前强烈建议先搞懂CLIP模型的训练和运作机制,之前发过CLIP博客)
论文地址:https://cdn.openai.com/papers/dall-e-2.pdf
代码地址:https://github.com/lucidrains/DALLE2-pytorch
1、简介
DALLE2提出了一个两阶段模型,利用类似CLIP的对比模型学习到的图像表示。第一阶段是一个先验模型,根据文本描述生成CLIP图像嵌入;第二阶段是一个解码器,根据图像嵌入生成相应的图像。我们发现,通过明确生成图像表示,可以提高图像多样性,同时最小程度地损失真实感和描述相似性。我们的解码器在图像表示的条件下,能够产生保留其语义和风格的图像变体,同时变化了图像表示中缺少的非关键细节。此外,CLIP的联合嵌入空间使得可以通过语言引导图像操作,实现零-shot学习。我们采用扩散模型进行解码,并尝试了自回归和扩散模型作为先验模型,结果显示后者在计算上更高效且生成的样本质量更高。
2、模型介绍
DALLE2模型的工作原理很简单,它接受文本描述并通过CLIP将其编码成向量表示,然后通过先验模块生成与文本相关的图像表示,最后,图像解码器将该表示解码成一张具体的图像,实现了根据文本生成对应图像的任务。(在看DALLE2之前强烈建议先搞懂前面引言中的CLIP模型的训练和运作机制)下图中,虚线上方:训练CLIP过程;虚线下方:由文本生成图像过程

3、训练过程
- 训练CLIP,使其能够编码文本和对应图像
这一步是与CLIP模型的训练方式完全一样的,目的是能够得到训练好的text encoder和img encoder。这么一来,文本和图像都可以被编码到相应的特征空间。对应上图中的虚线以上部分。
- 训练prior,使文本编码可以转换为图像编码
![]()
将CLIP中训练好的text encoder拿出来,输入文本y,得到文本编码Zt。同样的,将CLIP中训练好的img encoder拿出来,输入图像x得到图像编码Zx。我们希望prior能从Zt获取相对应的Zt。假设Zt经过prior输出的特征为Zi',那么我们自然希望Zi与Zi'越接近越好,这样来更新我们的prior模块。最终训练好的prior,将与CLIP的text encoder串联起来,它们可以根据我们的输入文本y生成对应的图像编码特征Zi了。关于具体如何训练prior,有兴趣的小伙伴可以精读一下论文,作者使用了主成分分析法PCA来提升训练的稳定性。(下图借鉴了一篇知乎的博客的图片)
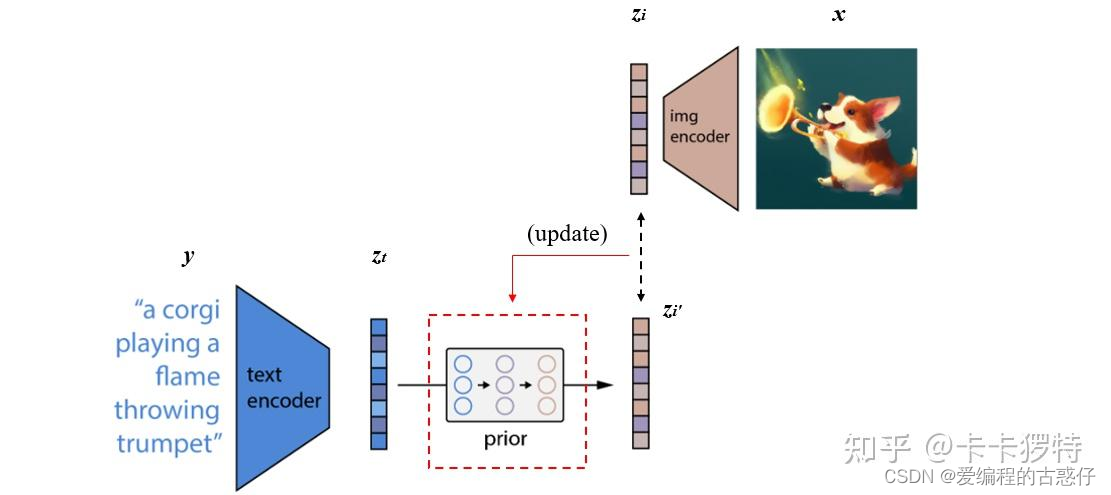
作者团队尝试了两种先验模型:自回归式Autoregressive (AR) prior 和扩散模型Diffusion prior 。实验效果上发现两种模型的性能相似,而因为扩散模型效率较高,因此最终选择了扩散模型作为prior模块。
小辉问:详细说说自回归式Autoregressive (AR) prior 和扩散模型Diffusion prior
小G答:自回归式(Autoregressive,AR)先验模型和扩散模型(Diffusion Model)是两种不同的先验模型,用于生成图像。
自回归式(Autoregressive)先验模型:
- 工作原理:自回归式先验模型将图像的生成过程建模为一个序列生成任务。在每个时间步,模型会根据之前生成的内容和输入的条件,预测下一个像素点的取值。生成过程从图像的某个起始位置开始,逐渐生成整张图像。
- 特点:自回归式先验模型通常使用递归神经网络(RNN)或变换器(Transformer)等结构来建模生成过程。由于生成过程是逐步进行的,因此生成的图像往往具有较高的清晰度和连续性。然而,这种逐步生成的方法可能会导致较慢的生成速度,并且难以处理全局一致性。
- 优点与局限:自回归式先验模型适用于需要考虑图像局部信息和序列相关性的任务,但由于生成过程是顺序执行的,因此可能受限于生成速度和全局一致性。
扩散模型(Diffusion Model)先验模型:
- 工作原理:扩散模型先验模型的核心思想是逐步“扩散”图像中的随机噪声,从而生成最终的图像。生成过程从一个随机初始化的图像开始,然后通过一系列步骤逐渐减小噪声,生成越来越清晰的图像。
- 特点:扩散模型先验模型通常利用马尔可夫链蒙特卡洛(MCMC)方法来建模生成过程,每个步骤都会根据当前图像状态和噪声水平生成下一个图像状态。这种逐步“扩散”的方法能够生成具有较高质量和全局一致性的图像,同时也具有较快的生成速度。
- 优点与局限:扩散模型先验模型在处理全局一致性和生成速度方面表现出色,但可能在捕捉局部细节和序列相关性方面稍显不足。
综上所述,自回归式(Autoregressive)先验模型和扩散模型(Diffusion Model)都是常用的先验模型,各自具有不同的特点和适用场景。选择合适的先验模型取决于具体的任务需求和性能要求。
- 训练decoder生成最终的图像

也就是说我们要训练decoder模块,从图像特征Zi还原出真实的图像 x,如下图左边所示。这个过程与自编码器类似,从中间特征层还原出输入图像,但又不完全一样。我们需要生成出的图像,只需要保持原始图像的显著特征就可以了,这样以便于多样化生成,例如下图。图像经过img encoder再经decoder得到重建图像。顶部图像为输入。

DALLE2使用的是改进的GLIDE模型。这个模型可以根据CLIP图像编码的Zi,还原出具有相同与x有相同语义,而又不是与x完全一致的图像。
4、推理过程(由文本生成图像过程)
经过以上三个步骤的训练,已经可以完成DALLE2预训练模型的搭建了。我们这时候丢掉CLIP中的img encoder,留下CLIP中的text encoder,以及新训练好的prior和decoder。这么一来流程自然很清晰了。由text encoder将文本进行编码,再由prior将文本编码转换为图像编码,最后由decoder进行解码生成图像。如下图(借鉴的知乎的博客)
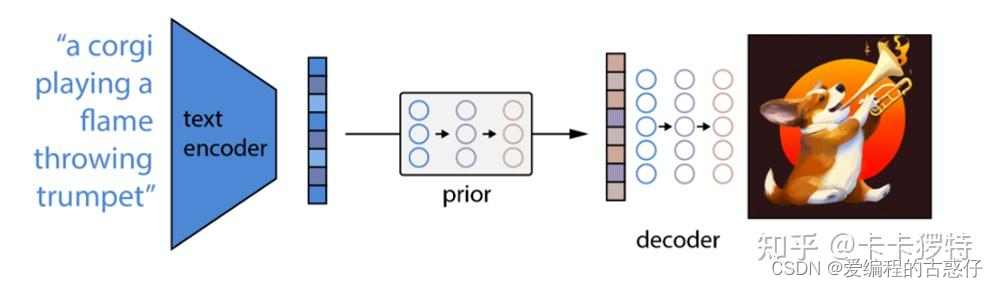
5、实验demo理解
5.1、训练CLIP模型
首先初始化一个CLIP模型,然后打印了其结构。接着,在一个循环中,生成了一些虚拟的文本和图像数据,并用于训练CLIP模型。在每一轮训练中,打印了生成的文本和图像数据,以及训练过程中的对比损失,并执行了梯度计算。
import torch
from dalle2_pytorch.x_clip import CLIP
# 初始化CLIP模型
clip = CLIP(
dim_text = 512, # 文本编码维度
dim_image = 512, # 图像编码维度
dim_latent = 512, # 潜在特征维度
num_text_tokens = 49408, # 文本token数量
text_enc_depth = 1, # 文本编码器深度
text_seq_len = 256, # 文本序列长度
text_heads = 8, # 文本编码器头数
visual_enc_depth = 1, # 图像编码器深度
visual_image_size = 256, # 图像输入尺寸
visual_patch_size = 32, # 图像切片尺寸
visual_heads = 8, # 图像编码器头数
use_all_token_embeds = True, # 是否使用细粒度对比学习(FILIP)
decoupled_contrastive_learning = True, # 使用解耦的对比学习(DCL)目标函数,从InfoNCE损失的分母中删除正对比对(CLOOB + DCL)
extra_latent_projection = True, # 是否为文本到图像和图像到文本的比较使用单独的投影(CLOOB)
use_visual_ssl = True, # 是否对图像进行自监督学习
visual_ssl_type = 'simclr', # 可以是'simclr'或'simsiam',取决于使用DeCLIP还是SLIP
use_mlm = False, # 是否在文本上使用遮蔽语言学习(MLM)(DeCLIP)
text_ssl_loss_weight = 0.05, # 文本MLM损失权重
image_ssl_loss_weight = 0.05 # 图像自监督学习损失权重
).cuda()
# 打印模型结构
print(clip)
# 模拟数据
for i in range(1):
text = torch.randint(0, 49408, (4, 256)).cuda() # 随机生成文本数据,shape为(4, 256)
images = torch.randn(4, 3, 256, 256).cuda() # 随机生成图像数据,shape为(4, 3, 256, 256)
print(f"\n--- 第 {i+1} 轮训练 ---")
print("随机生成的文本数据:")
print(text)
print("\n随机生成的图像数据:")
print(images)
# 训练
loss = clip(
text,
images,
return_loss = True # 需要设置为True以返回对比损失
)
print("\n训练过程中的对比损失:")
print(loss.item())
loss.backward()
print("\n梯度计算完毕。")
# 在循环中尽可能多地使用文本和图像来执行以上操作5.2、训练解码器
使用一个训练好的CLIP模型来辅助生成。首先,加载了训练好的CLIP模型,并创建了用于解码器的Unet模型。然后,创建了解码器,其中包含Unet模型和CLIP模型。接着,生成了一些虚拟图片数据,并将其输入解码器进行训练。最后,通过反向传播更新解码器的参数,重复这个过程多次,直到模型学会根据CLIP图像嵌入生成图片。
import torch
from dalle2_pytorch import Unet, Decoder, CLIP
# 加载训练好的 CLIP 模型
clip = CLIP(
dim_text = 512,
dim_image = 512,
dim_latent = 512,
num_text_tokens = 49408,
text_enc_depth = 1,
text_seq_len = 256,
text_heads = 8,
visual_enc_depth = 1,
visual_image_size = 256,
visual_patch_size = 32,
visual_heads = 8
).cuda()
# 创建用于解码器的 Unet 模型
unet = Unet(
dim = 128,
image_embed_dim = 512,
cond_dim = 128,
channels = 3,
dim_mults=(1, 2, 4, 8)
).cuda()
# 创建解码器,包含 Unet 和 CLIP
decoder = Decoder(
unet = unet,
clip = clip,
timesteps = 100,
image_cond_drop_prob = 0.1,
text_cond_drop_prob = 0.5
).cuda()
# 打印模型结构
print("CLIP Model Architecture:")
print(clip)
print("\nUnet Model Architecture:")
print(unet)
print("\nDecoder Model Architecture:")
print(decoder)
# 创建虚拟图片数据(获取大量数据)
images = torch.randn(4, 3, 256, 256).cuda()
# 循环训练
for epoch in range(10): # 假设训练10个epoch
# 输入数据并进行训练
loss = decoder(images)
loss.backward()
# 输出训练信息
print(f"Epoch [{epoch+1}/10], Loss: {loss.item()}")
# 训练完成
print("Training completed.")
# 重复以上步骤多次,让模型学会根据 CLIP 图像嵌入生成图片5.3、训练扩散先验网络
从给定的文本描述生成对应的图像嵌入。代码首先创建了一个包含文本和图像编码功能的CLIP模型,然后建立了一个包含自回归Transformer的先验网络,并将CLIP模型和先验网络结合在一起形成扩散先验网络。接着通过虚拟数据进行训练,在训练循环中反复迭代,使网络逐渐学习从文本到图像嵌入的映射关系。
import torch
from dalle2_pytorch import DiffusionPriorNetwork, DiffusionPrior, CLIP
# 从第一步获取训练好的 CLIP 模型
clip = CLIP(
dim_text=512, # 文本编码维度
dim_image=512, # 图像编码维度
dim_latent=512, # 潜在空间维度
num_text_tokens=49408, # 文本词汇表大小
text_enc_depth=6, # 文本编码器的深度
text_seq_len=256, # 文本序列长度
text_heads=8, # 文本注意力头数
visual_enc_depth=6, # 图像编码器的深度
visual_image_size=256, # 图像输入大小
visual_patch_size=32, # 图像分块大小
visual_heads=8, # 图像注意力头数
).cuda()
# 设置包含自回归 Transformer 的先验网络
prior_network = DiffusionPriorNetwork(
dim=512, # 输入维度
depth=6, # 网络深度
dim_head=64, # 注意力头维度
heads=8 # 注意力头数
).cuda()
# 创建扩散先验网络,其中包含上述的 CLIP 模型和网络(带有 Transformer)
diffusion_prior = DiffusionPrior(
net=prior_network, # 先验网络
clip=clip, # CLIP 模型
timesteps=100, # 时间步数
cond_drop_prob=0.2 # 条件丢失的概率
).cuda()
# 创建虚拟数据
text = torch.randint(0, 49408, (4, 256)).cuda() # 随机生成文本数据
images = torch.randn(4, 3, 256, 256).cuda() # 随机生成图像数据
# 打印一些数据信息
print("Text shape:", text.shape)
print("Images shape:", images.shape)
# 模拟训练循环
for step in range(10): # 循环10次
# 将文本和图像输入扩散先验网络
loss = diffusion_prior(text, images)
# 打印损失值
print(f"Step {step + 1}, Loss: {loss.item()}")
# 反向传播并更新参数
loss.backward()
# 清空梯度
diffusion_prior.zero_grad()
# 现在扩散先验网络可以从文本嵌入生成图像嵌入上面demo只是为了理解DALLE2的原理, 最后的效果很糟糕,下面我想用预训练模型推理一下,看看效果
6、测试结果
预训练模型地址:https://huggingface.co/laion/DALLE2-PyTorch
推理脚本
import torch
from torchvision.transforms import ToPILImage
from dalle2_pytorch import DALLE2
from dalle2_pytorch.train_configs import TrainDiffusionPriorConfig, TrainDecoderConfig
# 从预训练模型配置文件中加载 Diffusion Prior 模型配置
prior_config = TrainDiffusionPriorConfig.from_json_path("./weights/prior_config.json").prior
# 创建并加载 Diffusion Prior 模型
prior = prior_config.create().cuda()
# 加载预训练的 Diffusion Prior 模型参数
prior_model_state = torch.load("./weights/prior_latest.pth")
prior.load_state_dict(prior_model_state, strict=True)
# 从预训练模型配置文件中加载 Decoder 模型配置
decoder_config = TrainDecoderConfig.from_json_path("./weights/decoder_config.json").decoder
# 创建并加载 Decoder 模型
decoder = decoder_config.create().cuda()
# 加载预训练的 Decoder 模型参数
decoder_model_state = torch.load("./weights/decoder_latest.pth")["model"]
# 将预训练模型参数应用到 Decoder 的 CLIP 模型中
for k in decoder.clip.state_dict().keys():
decoder_model_state["clip." + k] = decoder.clip.state_dict()[k]
# 加载预训练的 Decoder 模型参数
decoder.load_state_dict(decoder_model_state, strict=True)
# 创建 DALL-E2 模型,将加载的 Diffusion Prior 和 Decoder 放在一起
dalle2 = DALLE2(prior=prior, decoder=decoder).cuda()
# 生成图像,你需要替换 ['your prompt here'] 为你的提示文本
images = dalle2(
['a red car'],
cond_scale = 2.
).cpu()
print(images.shape)
# 保存图像
for i, img in enumerate(images):
img_pil = ToPILImage()(img) # 将张量转换为 PIL 图像
img_pil.save(f'image_{i}.png') # 保存 PIL 图像为文件
在这个过程中会有一些报错,可以参考can not generate normal image with pretrained model · Issue #282 · lucidrains/DALLE2-pytorch · GitHub解决,首先我测试的预训练模型比较小,所以效果可能不是那么好,其次是模型生成的很慢.后续还要再研究研究看看,怎么训练