文章目录
- 前言
- 一、class文件初始化过程
- 1、概述
- 2、初始化过程-案例1
- a、代码T001_ClassLoadingProcedure 类加载过程
- b、解析
- 3、初始化过程-案例2
- a、代码
- b、解析
- 二、单例模式-双重检查
- 三、硬件层数据一致性
- 1、硬件层的并发优化基础知识
- b、Intel 的缓存一致性协议:MESI
- 四、缓存行(面试可能会被问道)-伪共享
- 1、定义
- 2、案例
- a、T01_CacheLinePadding
- b、T02_CacheLinePadding
- c、解析
- 五、指令乱序执行问题
- 1、乱序执行指令(并行)
- 2、合并写操作
- 3、合并写案例:WriteCombining
- 六、指令乱序执行证明
- 1、指令案例:T04_Disorder
- 2、如何保证特定情况下不乱序
- a、硬件内存屏障 Intel X86
- b、JVM级别如何规范(JSR133)
- 3、volatile的实现细节
- a、字节码层面
- b、JVM层面
- c、OS和硬件层面
- 4、synchronized实现细节
- a. 字节码层面
- i、小案例
- ii、解析
- b. JVM层面
- c. OS和硬件层面
前言
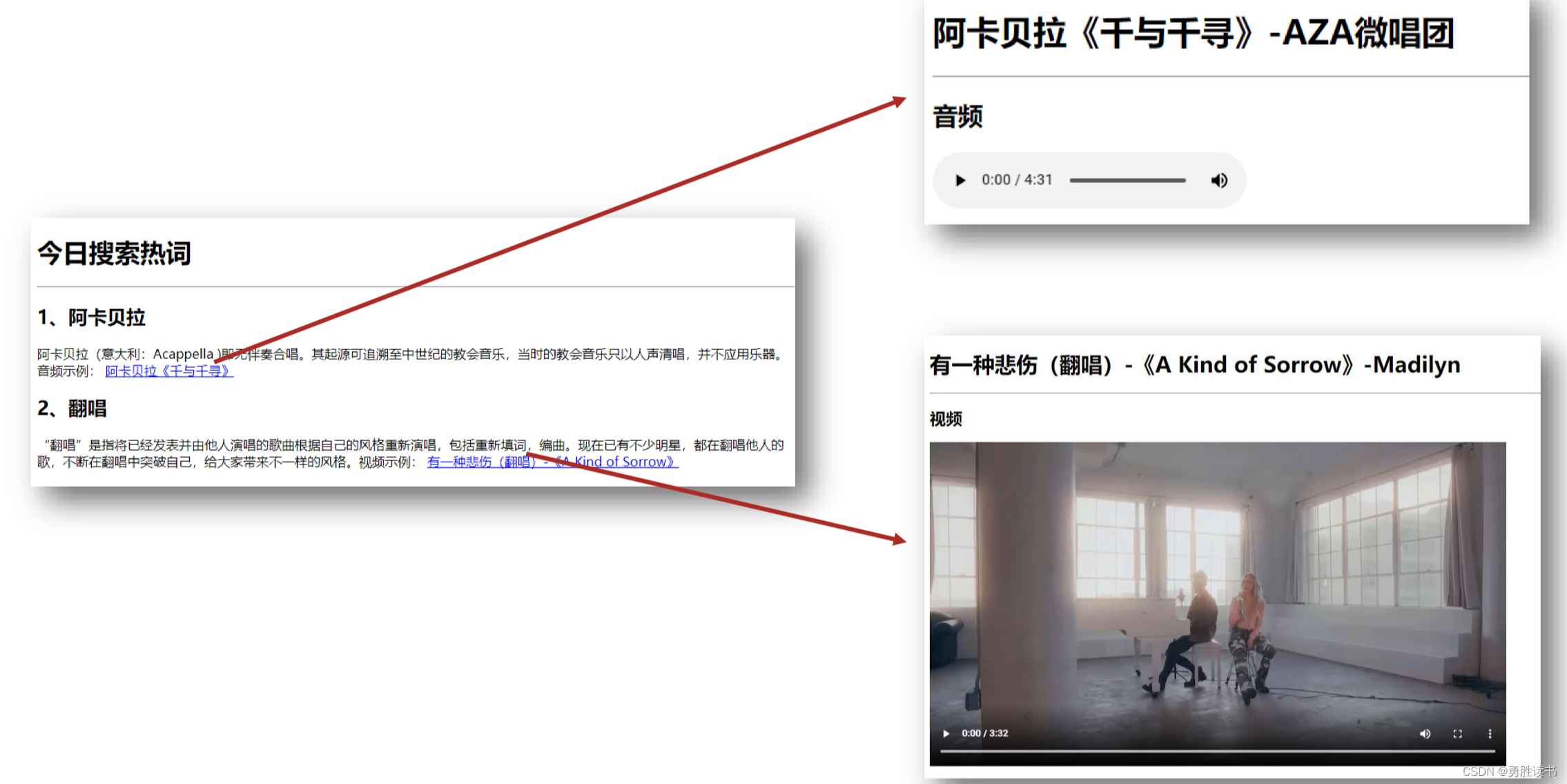
一、class文件初始化过程
1、概述
上一篇博文主要讲的类初始化的类加载过程,也就是loading。
这里就说一下其他部分,通过案例进行讲解。
- loading ,class文件加载到内存
- linking,包括三部分,上过博文也说过了
- initializing,初始化部分
2、初始化过程-案例1
a、代码T001_ClassLoadingProcedure 类加载过程
package com.mashibing.jvm.c2_classloader;
public class T001_ClassLoadingProcedure {
public static void main(String[] args) {
System.out.println(T.count);
}
}
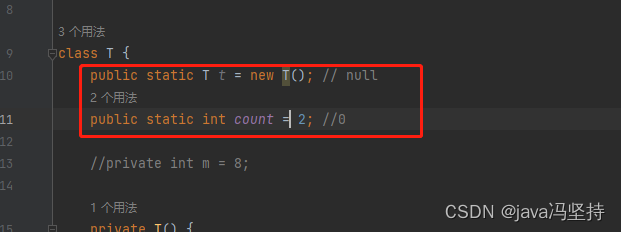
class T {
public static int count = 2; //0
public static T t = new T(); // null
//private int m = 8;
private T() {
count ++;
//System.out.println("--" + count);
}
}
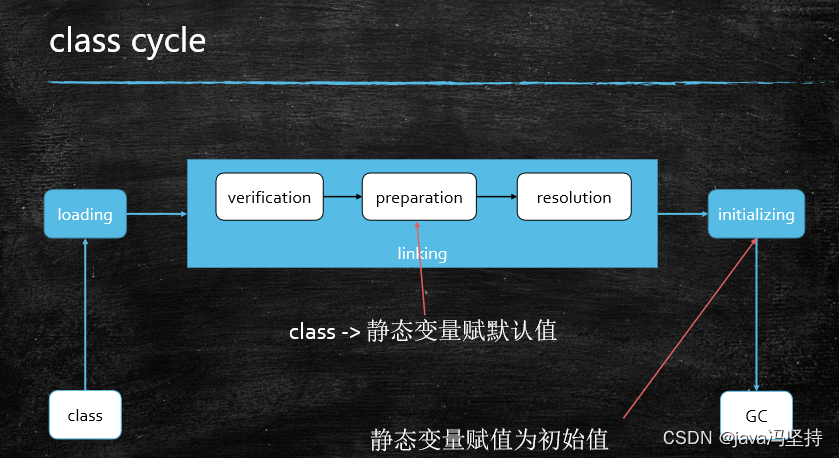
b、解析
- loading过程:代码执行到
main方法打印语句时,先加载T.class类到内存中。 - verification: 检测过程
- preparation :
静态变量赋默认值过程,此时count = 0, t = null。 - resolution :解析过程
- initializing:初始化过程,此时
count = 2,t = new T(),执行无参构造函数,然后count自加为3。所以输出3。
3、初始化过程-案例2
a、代码
还是上面案例1 的代码,改成两个静态变量的顺序,如下:
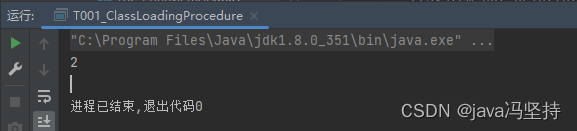
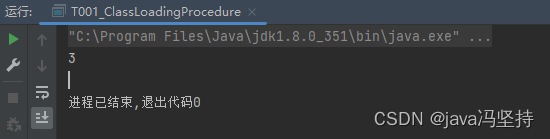
打印的结果为2,这是为啥呢。
b、解析
调换顺序,打印的数据就变成了2,还是初始化的过程,解说如下
-
loading,类加载过程
-
verification ,校验过程
-
preparation ,静态变量赋默认值,此时
t=null,count = 0, -
resolution ,解析过程
-
initializing,赋值过程,此时
t=new T() 执行无参构造函数,此时 count 自加后为1,然后执行第二行,count = 2,则覆盖了第一次的count 的自加操作,所以为2。 -
也说明类初始化过程中的重要性 以及 代码顺序的重要性。
-
当然,一般不会这么赋初值的,一般会用静态代码块或者在构造函数里进行 赋初值。都是为了面试而准备的,当然也是说明类初始化的顺序
二、单例模式-双重检查
DCL 单例,要加 volicate 关键字
三、硬件层数据一致性
JMM :java memory mode。java内存模型。
1、硬件层的并发优化基础知识
- 存储器的层次结构 (深入理解计算机系统 原书第三版 P421)
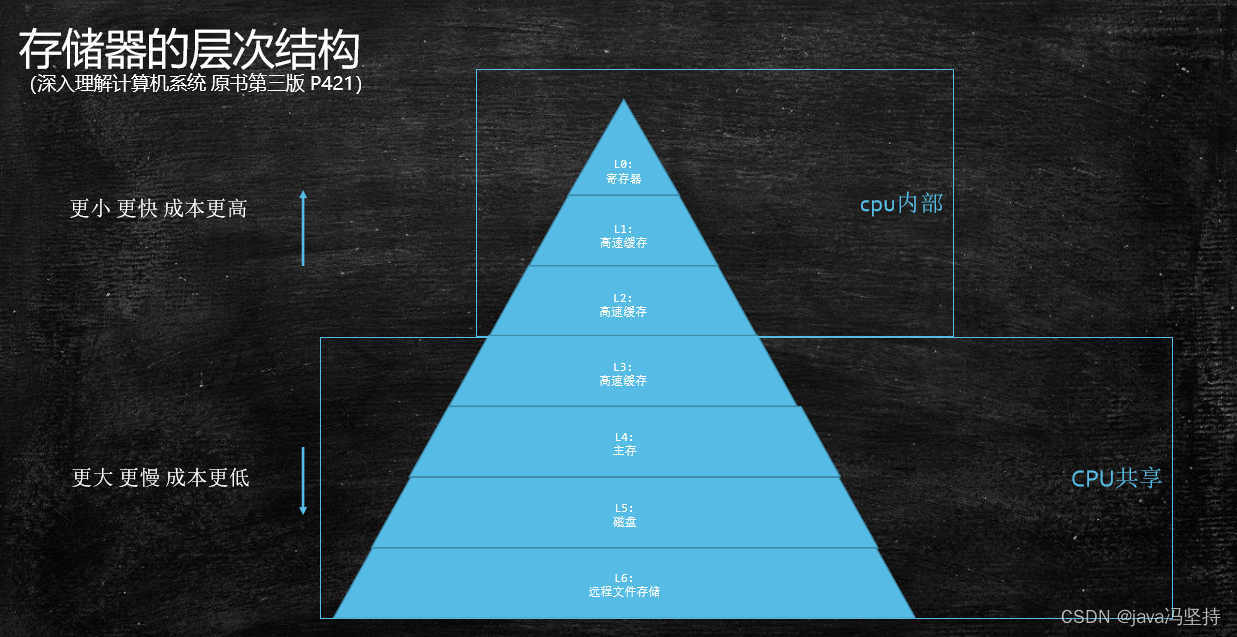
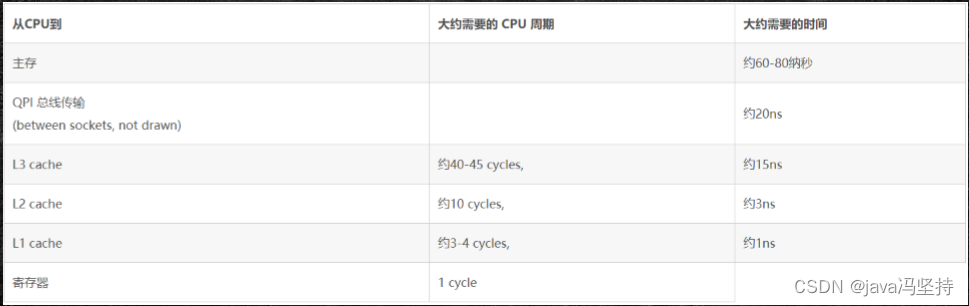
计算机模型CPU-内存模型:从下面这张图中可以看出,CPU 到内存直接还有多缓存(L1_cache、L2_cache、L3_cache),速度也是逐级递减(L1_cache基本能和cpu持平,其他的均明显低于cpu,L2_cache的速度大约比cpu慢20-30倍),L1_cache 和 L2_cache 是与CPU的内核在一块儿的,L3_cache 是共享的。
- 总线锁会锁住总线,使得其他CPU甚至不能访问内存中其他的地址,因而效率较低

b、Intel 的缓存一致性协议:MESI
协议很多,Intel 的Cache(缓存)一致性协议:MESI。
可参考此网址:https://www.cnblogs.com/z00377750/p/9180644.html
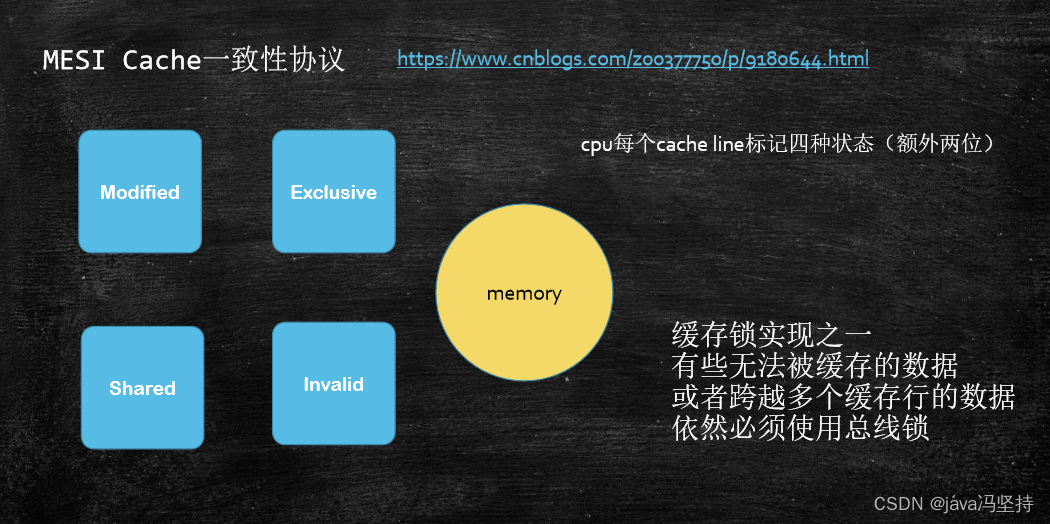
- MESI:modified、Exclusive、Shared、Invalid
- 现代CPU的数据一致性实现 = 缓存锁(MESI …) + 总线锁
四、缓存行(面试可能会被问道)-伪共享
1、定义
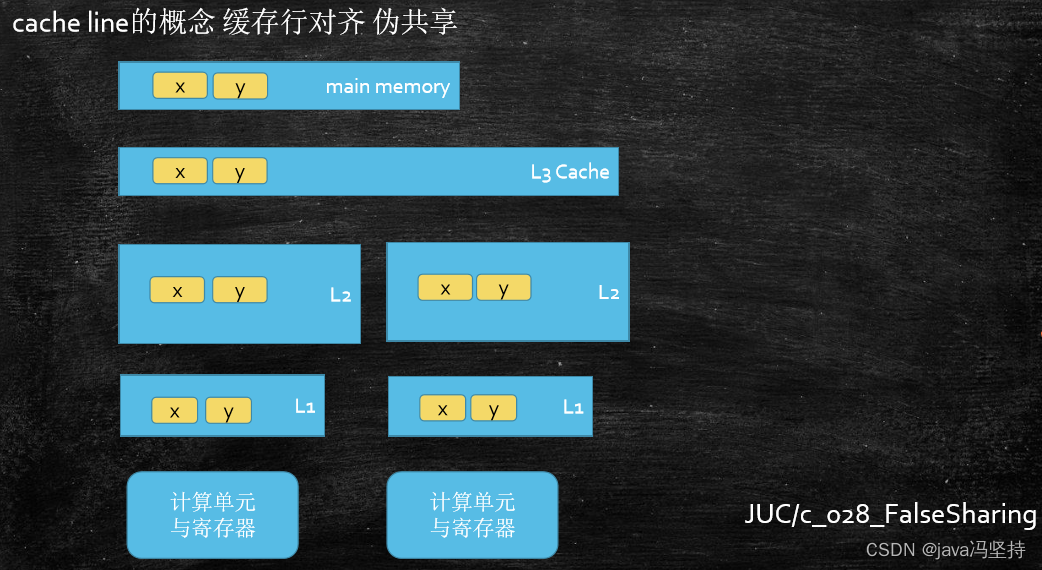
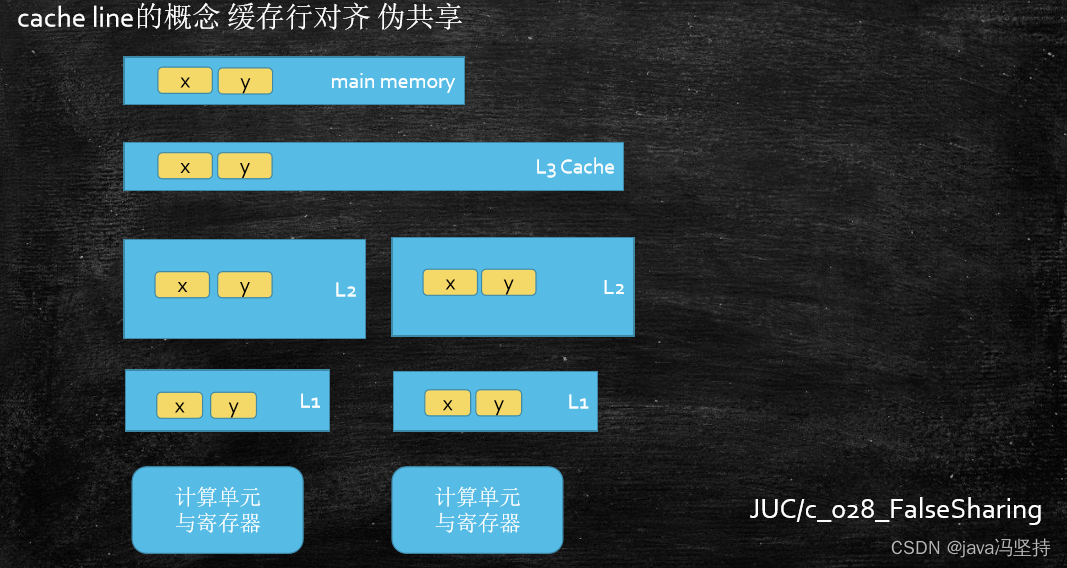
-
缓存行:当我们要把内存里面的某一些数据放到CPU自己的缓存时,不会只把这一个数据放进去,比如一个int型数据 12 ,只有 4 个字节,读缓存时不会只把这4个字节的数据读入到缓存,而且为了提高效率,把4个字节后面的一块儿内容全部读进去,读一个内容把一块儿内容全都读进去,这一块儿内容是一个基本的缓存单位,就是 缓存行,读取缓存以cache line为基本单位,目前64bytes。
-
伪共享问题: 位于同一
缓存行的两个不同数据,被两个不同CPU锁定,产生互相影响的伪共享问题 -
使用
缓存行的对齐能够提高效率 。
2、案例
a、T01_CacheLinePadding
- 案例中, 数组开辟的两个数值的地址,应该在同一个缓存行。
- 通过两个线程去频繁的改变他们数值。
- 两个变量在
一个缓存行,两个线程应该在两个CPU内核,那么会涉及到数据共享问题(上面说过Intel 的CPU 会用 MESI 缓存协议一致性) - 因为涉及到缓存一致性,所以会导致时间会比较长
package com.mashibing.juc.c_001_02_FalseSharing;
public class T01_CacheLinePadding {
public static long COUNT = 10_0000_0000L;
private static class T {
public long x = 0L; //8bytes
}
public static T[] arr = new T[2];
static {
arr[0] = new T();
arr[1] = new T();
}
public static void main(String[] args) throws Exception {
Thread t1 = new Thread(() -> {
for (long i = 0; i < COUNT; i++) {
arr[0].x = i;
}
});
Thread t2 = new Thread(() -> {
for (long i = 0; i < COUNT; i++) {
arr[1].x = i;
}
});
final long start = System.nanoTime();
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println((System.nanoTime() - start) / 100_0000);
}
}
b、T02_CacheLinePadding
- 案例中, 和上面的案例不同的是,一个数组。这里的是两个缓存行(两个缓存快),因为一个 Long 占 8个字节, 7个变量(p1-p7)就是 7*8 = 56个字节,在加一个 long 类型 变量x 正好是64个字节,缓存行的默认大小是 64个字节。
- 通过两个线程去频繁的改变他们数值。
- 两个变量在
两个缓存行,两个线程应该在两个CPU内核,那么不会涉及到数据共享问题(上面说过Intel 的CPU 会用 MESI 缓存协议一致性) - 因为涉及到缓存一致性,所以会导致时间会比较慢
package com.mashibing.juc.c_001_02_FalseSharing;
public class T02_CacheLinePadding {
public static long COUNT = 10_0000_0000L;
private static class Padding {
private volatile long p1, p2, p3, p4, p5, p6, p7; // 7*8=56个字节
}
private static class T extends Padding {
public volatile long x = 0L; //8bytes 8+56 = 64 个字节,所以 一个 T 就是一个缓存行
}
public static T[] arr = new T[2];
static {
arr[0] = new T();
arr[1] = new T();
}
public static void main(String[] args) throws Exception {
Thread t1 = new Thread(() -> {
for (long i = 0; i < COUNT; i++) {
arr[0].x = i;
}
});
Thread t2 = new Thread(() -> {
for (long i = 0; i < COUNT; i++) {
arr[1].x = i;
}
});
final long start = System.nanoTime();
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println((System.nanoTime() - start) / 100_0000);
}
}
c、解析
- 按照正常的设想,按照视频的教学,确实代码1要比代码2 的时间要长一些,因为涉及到了缓存一致性的问题。
- 但是我这里测试的确实代码1要比代码2的时间要短很多。可能会涉及到电脑类型、CPU内核数等等相关才照成这个问题的。
五、指令乱序执行问题
1、乱序执行指令(并行)
- CPU为了提高指令执行效率,会在一条指令执行过程中(比如去内存读数据(去内存读数据要比CPU执行指令慢100倍)),去同时执行另一条指令,前提是,两条指令没有依赖关系
- 参考资料:https://www.cnblogs.com/liushaodong/p/4777308.html
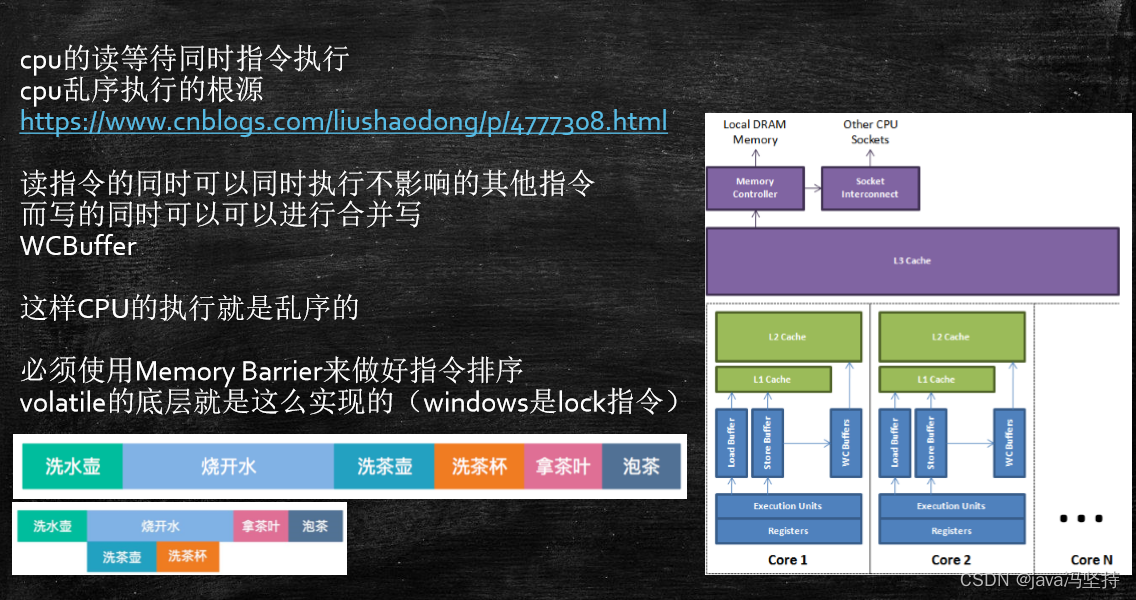
2、合并写操作
- 参考资料: https://www.cnblogs.com/liushaodong/p/4777308.html
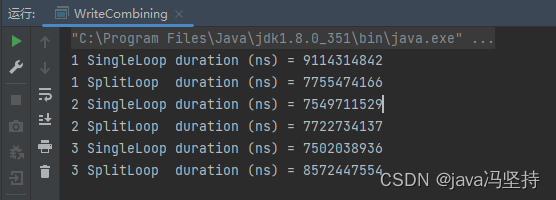
3、合并写案例:WriteCombining
该案例说明:合并写的速度快。
package com.mashibing.juc.c_029_WriteCombining;
/**
* 原封不动老外的代码:合并写案例
*/
public final class WriteCombining {
private static final int ITERATIONS = Integer.MAX_VALUE;
private static final int ITEMS = 1 << 24;
private static final int MASK = ITEMS - 1;
private static final byte[] arrayA = new byte[ITEMS];
private static final byte[] arrayB = new byte[ITEMS];
private static final byte[] arrayC = new byte[ITEMS];
private static final byte[] arrayD = new byte[ITEMS];
private static final byte[] arrayE = new byte[ITEMS];
private static final byte[] arrayF = new byte[ITEMS];
public static void main(final String[] args) {
for (int i = 1; i <= 3; i++) {
System.out.println(i + " SingleLoop duration (ns) = " + runCaseOne());
System.out.println(i + " SplitLoop duration (ns) = " + runCaseTwo());
}
}
public static long runCaseOne() {
long start = System.nanoTime();
int i = ITERATIONS;
while (--i != 0) {
int slot = i & MASK;
byte b = (byte) i;
arrayA[slot] = b;
arrayB[slot] = b;
arrayC[slot] = b;
arrayD[slot] = b;
arrayE[slot] = b;
arrayF[slot] = b;
}
return System.nanoTime() - start;
}
public static long runCaseTwo() {
long start = System.nanoTime();
int i = ITERATIONS;
while (--i != 0) {
int slot = i & MASK;
byte b = (byte) i;
arrayA[slot] = b;
arrayB[slot] = b;
arrayC[slot] = b;
}
i = ITERATIONS;
while (--i != 0) {
int slot = i & MASK;
byte b = (byte) i;
arrayD[slot] = b;
arrayE[slot] = b;
arrayF[slot] = b;
}
return System.nanoTime() - start;
}
}
六、指令乱序执行证明
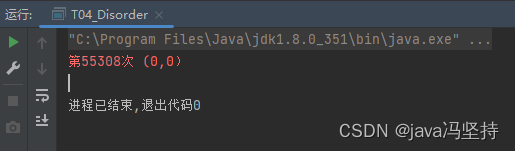
1、指令案例:T04_Disorder
x,y的值可能的取值:(1,0)(0,1)(1,1)
一旦出现了(0,0)说明出现了指令乱序执行。
package com.mashibing.jvm.c3_jmm;
public class T04_Disorder {
private static int x = 0, y = 0;
private static int a = 0, b =0;
public static void main(String[] args) throws InterruptedException {
int i = 0;
for(;;) {
i++;
x = 0; y = 0;
a = 0; b = 0;
Thread one = new Thread(new Runnable() {
public void run() {
//由于线程one先启动,下面这句话让它等一等线程two. 读着可根据自己电脑的实际性能适当调整等待时间.
//shortWait(100000);
a = 1;
x = b;
}
});
Thread other = new Thread(new Runnable() {
public void run() {
b = 1;
y = a;
}
});
one.start();other.start();
one.join();other.join();
String result = "第" + i + "次 (" + x + "," + y + ")";
if(x == 0 && y == 0) {
System.err.println(result);
break;
} else {
//System.out.println(result);
}
}
}
public static void shortWait(long interval){
long start = System.nanoTime();
long end;
do{
end = System.nanoTime();
}while(start + interval >= end);
}
}
2、如何保证特定情况下不乱序
a、硬件内存屏障 Intel X86
-
加锁是肯定的可以的,但是在不同的CPU(很多CPU)都添加了
硬件内存屏障(CPU级别的内存屏障,和java的内存屏障无关系)* * -
Intel 设置的比较简单,只有三条指令。
sfence(save fence 存栅栏的意思): store| 在sfence指令前的写操作当必须在sfence指令后的写操作前完成。
lfence(load fence 读屏障):load | 在lfence指令前的读操作当必须在lfence指令后的读操作前完成。
mfence(二者之和):modify/mix | 在mfence指令前的读写操作当必须在mfence指令后的读写操作前完成。
intel lock汇编指令(java的),原子指令,如x86上的”lock …” 指令是一个Full Barrier,执行时会锁住内存子系统来确保执行顺序,甚至跨多个CPU。Software Locks通常使用了内存屏障或原子指令来实现变量可见性和保持程序顺序
b、JVM级别如何规范(JSR133)
-
LoadLoad屏障:
对于这样的语句Load1; LoadLoad; Load2,
在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕。 -
StoreStore屏障:
对于这样的语句Store1; StoreStore; Store2,
在Store2及后续写入操作执行前,保证Store1的写入操作对其它处理器可见。 -
LoadStore屏障:
对于这样的语句Load1; LoadStore; Store2,
在Store2及后续写入操作被刷出前,保证Load1要读取的数据被读取完毕。 -
StoreLoad屏障:
对于这样的语句Store1; StoreLoad; Load2,
在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见。 -
上面的JVM级别的四个指令屏障 都是依赖于 硬件去实现的,硬件的实现不是只有内存屏障能够实现JVM级别的内存屏障,即JVM的内存屏障或者交JVM级别的有序性,它的硬件级别的实现并不一定依赖于硬件级别的内存屏障,还依赖于硬件级别的
lock 指令。 -
硬件界别的和JVM级别不是一回事儿。
3、volatile的实现细节
volatile 的实现过程,分不同的层面,包含以下三个层面。
.java编译成字节码(byte code).class这是字节码层面。- 字节码 在JVM层级实现,这是
JVM层面。 - JVM 交付到 硬件 去执行,这是
OS硬件层面
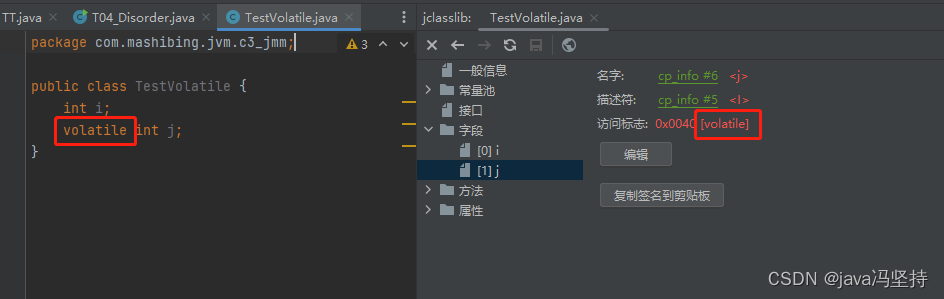
a、字节码层面
- ACC_VOLATILE
- 只需要一个
volatile关键字即可 - 访问标志(access flag):就是修饰符,比如 public、private、protect等。
b、JVM层面
到了JVM屏障,volatile内存区的读写 都加屏障
StoreStoreBarrier
volatile 写操作
StoreLoadBarrier
LoadLoadBarrier
volatile 读操作
LoadStoreBarrier
c、OS和硬件层面
https://blog.csdn.net/qq_26222859/article/details/52235930
hsdis 工具 - HotSpot Dis Assembler
在 windows 使用 lock 指令实现 | MESI 实现
4、synchronized实现细节
同 volatile 一样,也是三个层级。
- 字节码层面
- JVM层面
- OS 硬件层面
a. 字节码层面
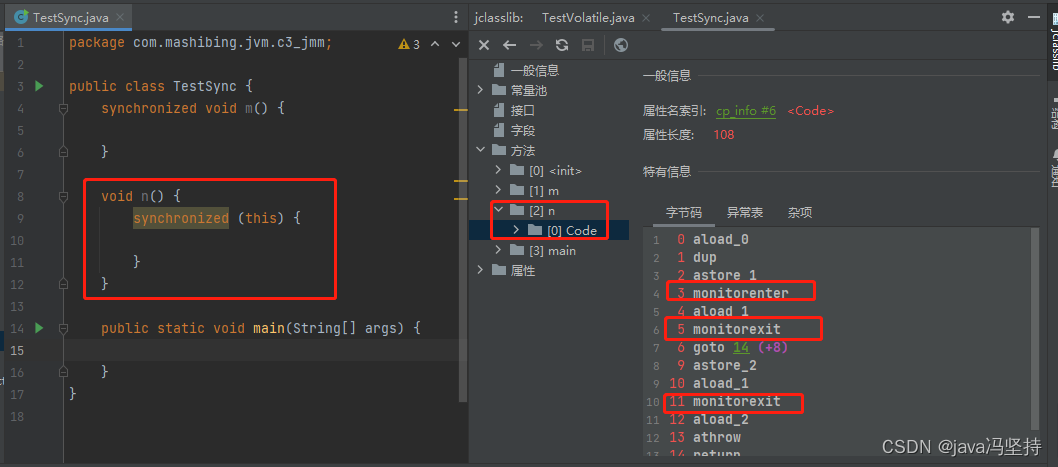
从下面截图中可以看出,使用的是 ACC_SYNCHRONIZED 修饰符。
monitorenter monitorexit
i、小案例
package com.mashibing.jvm.c3_jmm;
public class TestSync {
synchronized void m() {
}
void n() {
synchronized (this) {
}
}
public static void main(String[] args) {
}
}
从编译后的字节码看到如下图
ii、解析
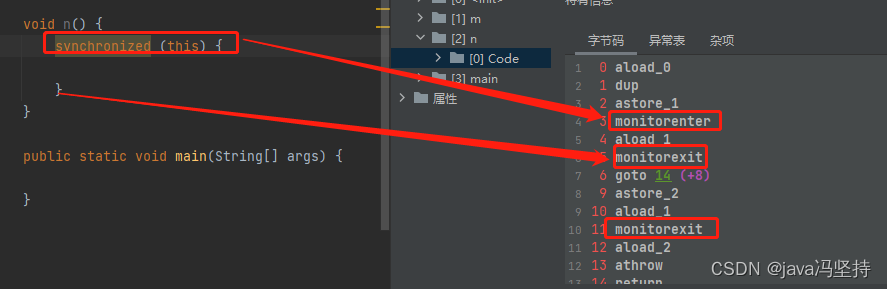
synchronized 块 中可以看出,有三个指令, monitorenter,monitorexit,monitorexit。后两个是一个指令。
为什么会三个,后两个是一样的呢,逻辑如下图,第三个指令是如果出现了异常进行捕捉,才用到第三个 monitorexit 指令。
b. JVM层面
是C 和 C++ 写的,则 C 和 C++ 调用了操作系统提供的同步机制。
c. OS和硬件层面
CPU Intel X86 : 使用 lock cmpxchg / xxx 等指令。
https://blog.csdn.net/21aspnet/article/details/88571740



![[多图,秒懂]如何训练一个“万亿大模型”?](https://img-blog.csdnimg.cn/img_convert/9227e1d92b838e14d6a10e28a20a01b9.png)
![[golang工作日记] for range 踩坑](https://img-blog.csdnimg.cn/59075971b33047fe8a7b6990f15e2d5b.png)