简介
LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS,直接翻译过来就是大模型的低秩适配
2021年微软提出的LoRA,它的灵感来自于 Li和 Aghajanyan等人的一些关于内在维度(intrinsic dimension)的发现:模型是过参数化的,它们有更小的内在维度(low intrinsic dimension)。于是假设模型在任务适配过程中权重的改变量是低秩(low “intrinsic rank”)的,由此提出LoRA方法。LoRA 允许我们通过优化适应过程中密集层变化的秩分解矩阵,来间接训练神经网络中的一些密集层,同时保持预先训练的权重不变。
补充知识
矩阵的秩:秩的定义是矩阵中的线性无关行或列的最大数量。
矩阵的秩的度量其实就是矩阵的行列之间的相关性。如果矩阵的各行或列是线性无关的,矩阵就是满秩的。
低秩矩阵 指矩阵的秩相对矩阵的行数或列数而言很小。
低秩(Low-rank)的意义 低秩矩阵的每行或者每列都可以用其他的行或者列线性表示,这说明这个矩阵包含了大量的冗余信息。
LoRA原理
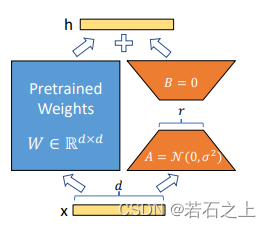
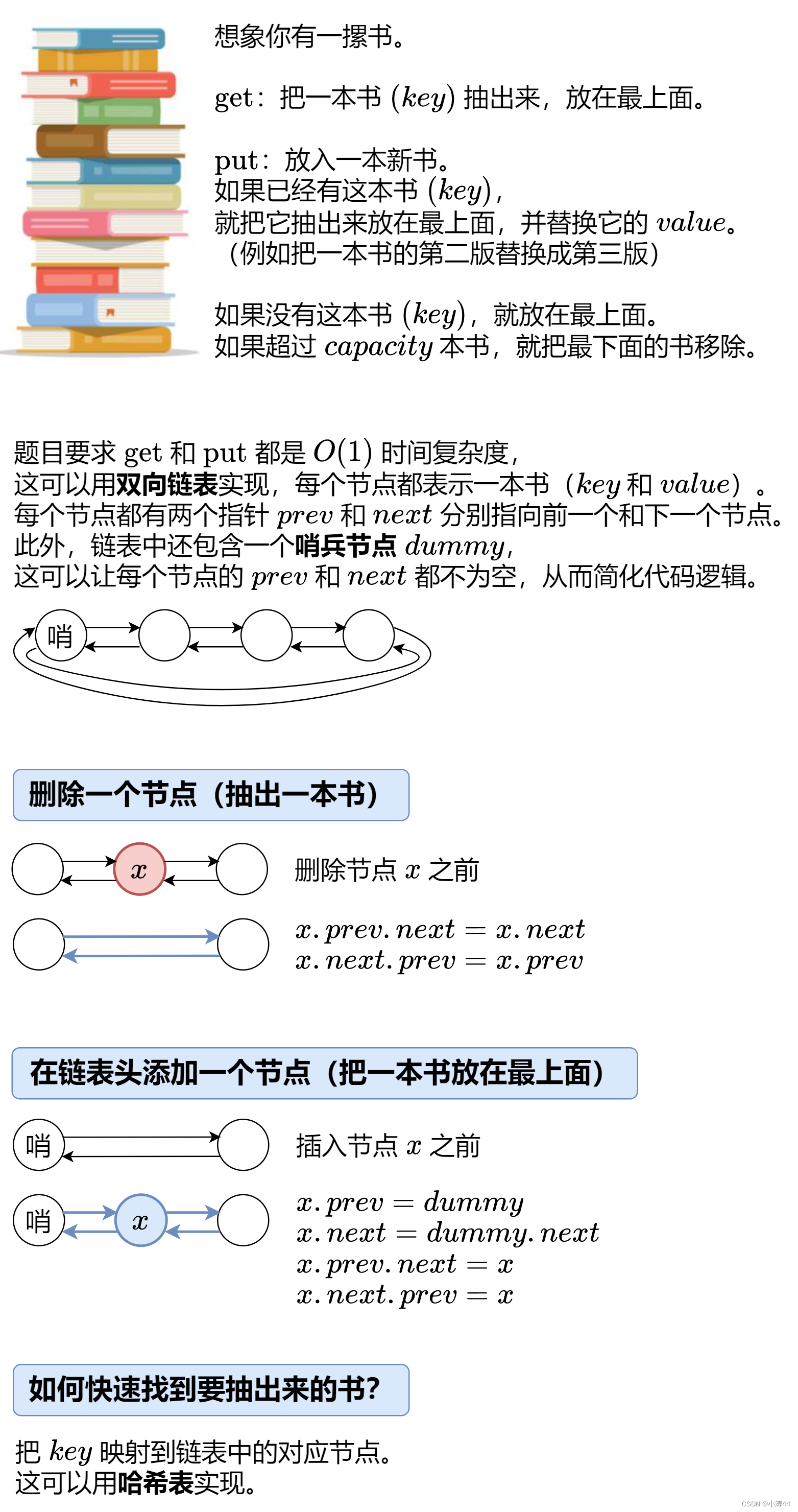
参考上图,LoRA 的思想很简单:
- 在原始 PLM (Pre-trained Language Model) 旁边增加一个旁路,做一个降维再升维的操作,来模拟所谓的
intrinsic rank。 - 训练的时候固定 PLM 的参数,只训练降维矩阵A 与升维矩阵 B 。而模型的输入输出维度不变,输出时将BA与 PLM 的参数叠加。
- 用随机高斯分布初始化 A ,用 0 矩阵初始化 B ,保证训练的开始此旁路矩阵依然是 0 矩阵。
假设要在下游任务微调一个预训练语言模型(如 GPT-3),则需要更新预训练模型参数,公式表示如下:
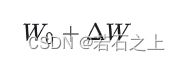
W0是预训练模型初始化的参数, ΔW 就是需要更新的参数。如果是全参数微调,则它的参数量 =W0 (如果是 GPT-3,则 ΔW≈175B )。从这可以看出要全参数微调大语言模型,代价是非常高的。
而对于 LORA 来说,只需要微调 ΔW 。
具体来看,假设预训练的矩阵为 W0∈Rd×d ,它的更新可表示为:
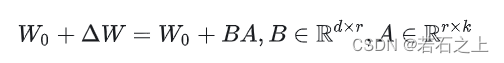
其中秩 r≪min(d,k) 。
在 LoRA 的训练过程中, W0 是固定不变的,只有A 和 B 是训练参数。
在前向过程中, W0 与 ΔW都会乘以相同的输入 x ,最后相加: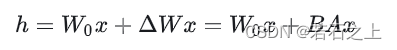
LORA 的这种思想有点类似于残差连接,同时使用这个旁路的更新来模拟 Full Fine-Tuning的过程。并且,Full Fine-Tuning可以被看做是 LoRA 的特例(当 r 等于 k 时)。
在推理过程中,LoRA 也几乎未引入额外的推理延迟,只需要计算 W=W0+ΔW 即可。
LoRA 与 Transformer 的结合也很简单,仅在 QKV Attention 的计算中增加一个旁路。
LoRA 微调方法的主要优势
- 预训练模型参数可以被共享,用于为不同的任务构建许多小的 LoRA 模块。冻结共享模型,并通过替换矩阵 A 和 B 可以有效地切换任务,从而显著降低存储需求和多个任务切换的成本,当使用HF的peft模块编码的时候,可以随时进行切换。
- 当使用自适应优化器时,由于不需要计算梯度以及保存太多模型参数,LoRA 使得微调效果更好,并将微调的硬件门槛降低了 3 倍。
- 低秩分解采用线性设计的方式使得在部署时能够将可训练的参数矩阵与冻结的参数矩阵合并,与完全微调的方法相比,不引入推理延迟。
- LoRA 与其它多种微调方法不冲突,可以与其它微调方法相结合,比如前缀调优方法等。
LoRA在HF的peft中的实现
from peft import LoraConfig, get_peft_model
config = LoraConfig(
r=16,
lora_alpha=16,
target_modules=["query", "value"],
lora_dropout=0.1,
bias="none",
modules_to_save=["classifier"],
)
lora_model = get_peft_model(model, config)
print_trainable_parameters(lora_model)
trainer = Trainer(
lora_model,
args,
train_dataset=train_ds,
eval_dataset=val_ds,
tokenizer=image_processor,
compute_metrics=compute_metrics,
data_collator=collate_fn,
)
train_results = trainer.train()
def print_trainable_parameters(model):
trainable_params = 0
all_param = 0
for _, param in model.named_parameters():
all_param += param.numel()
if param.requires_grad:
trainable_params += param.numel()
print(
f"trainable params: {trainable_params} || all params: {all_param} || trainable%: {100 * trainable_params / all_param:.2f}"
)我们可以把模型的参数和LoRA微调的参数打印出来,输出的结果如下:
"trainable params: 667493 || all params: 86466149 || trainable%: 0.77"我们可以看到需要训练的参数占比还不到1%
LORA 轻量级微调实验效果
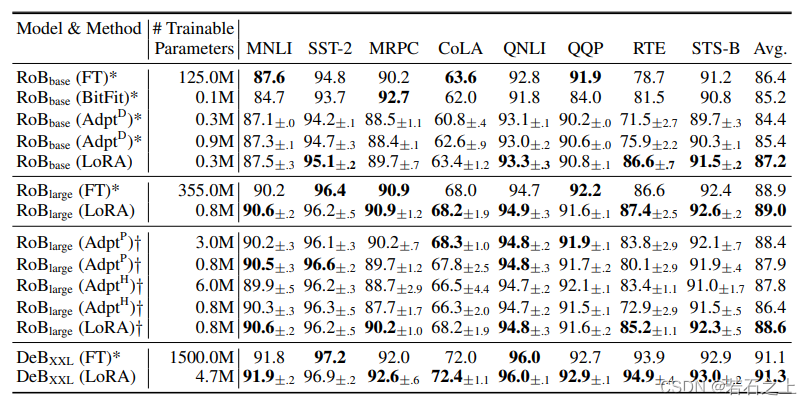
结论:
- 参数量较全参数微调(Fine-Tuning)显著降低,参数量和现有高效参数微调方法持平或更低。
- 性能优于其它参数高效微调方法,和全参数微调(Fine-Tuning)基本持平甚至更高。
![[HTML]Web前端开发技术27(HTML5、CSS3、JavaScript )JavaScript基础——喵喵画网页](https://img-blog.csdnimg.cn/direct/52c0c5fe6b45486095dede020d9194cb.png)