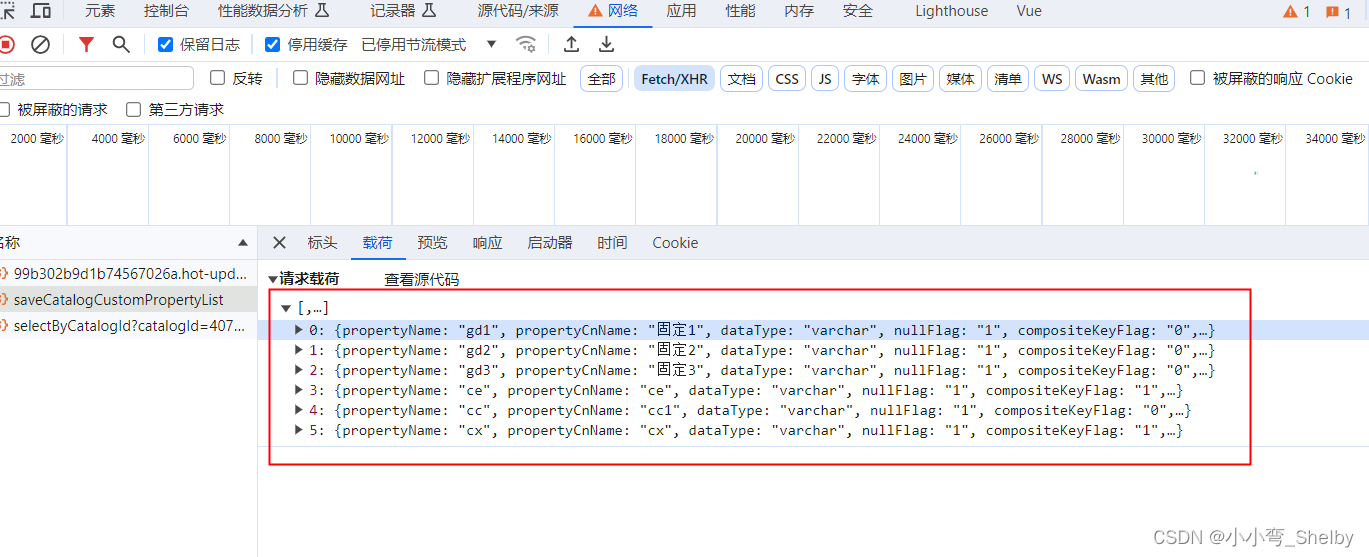
关键词搜索(Keyword Search)是文本搜索种一种常用的技术,很多知名的应用app比如Spotify、YouTube 或 Google map等都会使用关键词搜索的算法来实现用户的搜索任务,关键词搜索是构建搜索系统最常用的方法,最常用的搜索算法是Okapi BM25,简称BM25。在信息检索中,Okapi BM25(BM是最佳匹配的缩写)是搜索引擎用来估计文档与给定搜索查询的相关性的排名函数。它基于Stephen E. Robertson、Karen Spärck Jones等人 在 20 世纪 70 年代和 80 年代开发的概率检索框架。今天我们会教大家使用Cohere的API来调用BM25算法搜索维基百科的数据库。
一、环境配置
我们需要安装如下的python包:
pip install cohere
pip install weaviate-client这里简单介绍一下cohere是一家从事大模型应用开发的公司,而weaviate是一个开源的向量数据库,本次实验我们会用到weaviate-client这个包。接下来我们需要导入一些基础配置,这些基础配置主要包含cohere和weaviate的相关的api_key:
import os
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file接下来我们来创建一个weaviate的client,它将会允许我们连接一个在线数据库。
import weaviate
#创weaviate建验证配置
auth_config = weaviate.auth.AuthApiKey(
api_key=os.environ['WEAVIATE_API_KEY'])
#创建weaviate client
client = weaviate.Client(
url=os.environ['WEAVIATE_API_URL'],
auth_client_secret=auth_config,
additional_headers={
"X-Cohere-Api-Key": os.environ['COHERE_API_KEY'],
}
)
#测试client连接
client.is_ready() 这里需要说明的是Weaviate 是一个开源的向量数据库。 它具有关键字搜索功能,同时还具有基于大语言模型(LLM)的向量搜索功能。 我们在这里使用的 API key是公共的,它是公共Demo的一部分,因此它是公开的,您可以使用它通过一个url地址来访问在线Demo数据库。 另外需要说明的是这个在线数据库是一个公共数据库,包含1000万条自维基百科的数据记录。数据库中的每一行记录表示维基百科文章的一个段落。这 1000 万条记录来自 10 种不同的语言。 因此,其中一百万是英语,另外九百万对应其他9种不同语言。 我们在执行查询时可以设置不同的语言。这种语言包括:en, de, fr, es, it, ja, ar, zh, ko, hi
二、关于API KEY
这里我们会用到3个配置参数:COHERE_API_KEY、 WEAVIATE_API_KEY、WEAVIATE_API_URL。其中COHERE_API_KEY我们需要去cohere的网站自己注册一个cohere账号然后自己创建一个自己的api_key, 而WEAVIATE_API_KEY和WEAVIATE_API_URL我们使用的是对外公开的api_key和url":
- weaviate_api_key: "76320a90-53d8-42bc-b41d-678647c6672e"
- weaviate_api_url: "https://cohere-demo.weaviate.network/"
三、关键词搜索(keyword Search)
Keyword Search在基本原理是它会比较问题和文档中的相同词汇的数量,从而找出和问题最相关的文档,如下图所示:

在上图中Query表示用户的问题,而Responses表示根据问题检索到的结果,Number of words in common表示query和responses中出现重复单词的数量,在这个例子中我们的问题是:“what color is the grass?” 与结果中第二个结果 “The grass is green” 重复的单词数量最多,因此第二个结果是最优的结果。
下面我们来定义一个关键词搜索函数:
def keyword_search(query,
results_lang='en',
properties = ["title","url","text"],
num_results=3):
where_filter = {
"path": ["lang"],
"operator": "Equal",
"valueString": results_lang
}
response = (
client.query.get("Articles", properties)
.with_bm25(
query=query
)
.with_where(where_filter)
.with_limit(num_results)
.do()
)
result = response['data']['Get']['Articles']
return result这里在定义keyword_search函数时设置了如下四个参数
- query: 用户的问题
- results_lang:使用的语言,默认使用英语。
- properties :结果的组成结构。
- num_results:结果的数量,默认3个结果。
由于该在在线数据库中的数据由10种不同的语言组成,其中包括:en, de, fr, es, it, ja, ar, zh, ko, hi。因此我们可以在查询时设置不同的语言来进行查询。另外在该函数中我们还指定了BM25算法(“with_bm25”)来实现关键词搜索,下面我们就来使用默认的英文来进行关键词搜索:
query = "Who is Donald Trump?"
keyword_search_results = keyword_search(query)
print(keyword_search_results)
由于上面的多条结果混在一起看上去比较乱,因此我们可以定义一个整理结果的函数:
def print_result(result):
""" Print results with colorful formatting """
for i,item in enumerate(result):
print(f'item {i}')
for key in item.keys():
print(f"{key}:{item.get(key)}")
print()
print()
print_result(keyword_search_results)
这里我们看到了关键词搜索函数返回了3条包含“Donald Trump”的文档。接下来我们使用中文来进行搜索:
query = "安史之乱"
keyword_search_results = keyword_search(query, results_lang='zh')
print_result(keyword_search_results)
四、关键词搜索基本原理
这里我们需要解释一下该关键词搜索系统的基本原理,这里主要包含了查询(query)和搜索系统(Search System)两个主要的组件,搜索系统可以访问它预先处理过的文档数据,然后响应查询,系统最后为我们提供一个按与问题最相关的文档排序结果列表,如下图所示:

搜索系统(Search System)的内部结构
然而在搜索系统内部包含了2个主要的工作阶段, 第一个阶段通常是检索或搜索阶段,之后还有另一个阶段,称为重新排名即所谓的re-ranking。第一阶段通常使用 BM25 算法对文档集中的文档与问题进行评分,第一阶段检索的实现通常包含倒排索引的思想(inverted index)。第二阶段(re-ranking)则对评分结果进行排序后输出结果,如下图所示:

从上图种我们看到了在倒排序表中包含了2列,第一列时关键词,第二列是该关键词所在的文档的Id. 设计这样的倒排序表主要是为了优化搜索速度。 当您在搜索引擎中输入查询的问题时,系统便能在几毫秒内得到结果。另外在执行搜索任务时关键词对应的文档id出现的频率是评分的重要依据,在上图中的例子中“Color” 在804文档中出现,而“Sky”也在804文档中出现,因此804文档被命中的次数较多,所以会有较高的评分,最后它在检索结果中出现的位置会比较靠前。
五,关键词检索的局限性
我们知道关键词检索并非是根据关键词的语义来检索,而是根据问题和文档中出现的重复单词数量来进行检索,这就会带来一个棘手的问题,那就是如果文档和问题在语义相关,但是它们之间却没有重复的单词,那么就会照成关键词检索无法检索到相关的文档,如下图所示:

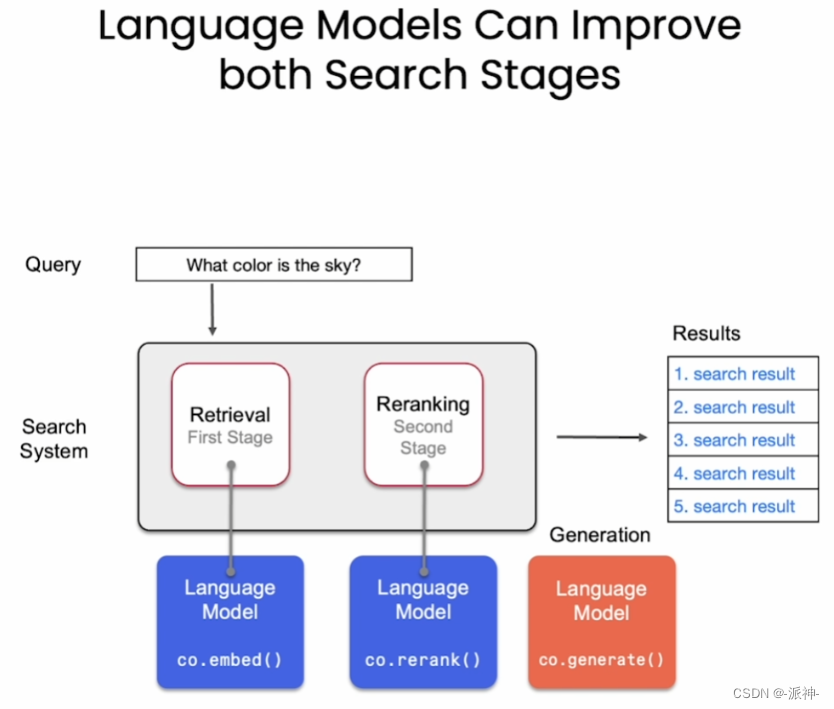
当文档与问题在语义上相关,但它们之间又没有出现重复词汇,此时关键词检索将会失效,它将无法检索到相关文档,当遇到这种情况时则需要借助语言模型来通过语义识别来进行检索。后续我们将会借助语言模型来改进关键词搜索的两个阶段,如下图所示:
参考资料
The Cohere Platform
Home | Weaviate - Vector Database
https://en.wikipedia.org/wiki/Okapi_BM25