一个 EfficientNet 模型首先作为教师模型在标记图像上进行训练,为 300M 未标记图像生成伪标签。然后将相同或更大的 EfficientNet 作为学生模型并结合标记图像和伪标签图像进行训练。学生网络训练完成后变为教师再次训练下一个学生网络,并迭代重复此过程。
Abstract
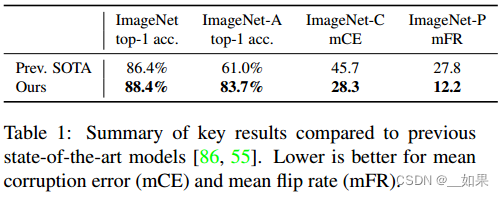
We present Noisy Student Training, a semi-supervised learning approach that works well even when labeled data is abundant. Noisy Student Training achieves 88.4% top1 accuracy on ImageNet, which is 2.0% better than the state-of-the-art model that requires 3.5B weakly labeled Instagram images. On robustness test sets, it improves ImageNet-A top-1 accuracy from 61.0% to 83.7%, reduces ImageNet-C mean corruption error from 45.7 to 28.3, and reduces ImageNet-P mean flip rate from 27.8 to 12.2.
Noisy Student Training extends the idea of self-training and distillation with the use of equal-or-larger student models and noise added to the student during learning. On ImageNet, we first train an EfficientNet model on labeled images and use it as a teacher to generate pseudo labels for 300M unlabeled images. We then train a larger EfficientNet as a student model on the combination of labeled and pseudo labeled images. We iterate this process by putting back the student as the teacher. During the learning of the student, we inject noise such as dropout, stochastic depth, and data augmentation via RandAugment to the student so that the student generalizes better than the teacher.
翻译:
我们提出了Noisy Student训练,这是一种半监督学习方法,即使在标记数据丰富的情况下也能很好地工作。Noisy Student训练在ImageNet上达到了88.4%的top1准确率,比最先进的模型(需要3.5B张弱标记的Instagram图像)高2.0%。在鲁棒性测试集上,它将ImageNet-A top-1的准确率从61.0%提高到83.7%,将ImageNet-C的平均损坏误差从45.7降低到28.3,将ImageNet-P的平均翻转率从27.8降低到12.2。
通过使用相等或更大的学生模型和在学生学习过程中添加的噪声,Noisy Student Training扩展了自我训练和蒸馏的思想。在ImageNet上,我们首先在标记的图像上训练一个efficientnet模型,并将其用作教师,为300万张未标记的图像生成伪标签。然后,我们训练一个更大的efficientnet作为一个学生模型,该模型基于标记和伪标记图像的组合。我们通过让学生重新成为老师来重复这个过程。在学生学习过程中,我们通过RandAugment向学生注入dropout、stochastic depth、data augmentation等噪声,使学生的泛化能力优于老师
Introduction
Deep learning has shown remarkable successes in image recognition in recent years [45, 80, 75, 30, 83]. However state-of-the-art (SOTA) vision models are still trained with supervised learning which requires a large corpus of labeled images to work well. By showing the models only labeled images, we limit ourselves from making use of unlabeled images available in much larger quantities to improve accuracy and robustness of SOTA models
Here, we use unlabeled images to improve the SOTA ImageNet accuracy and show that the accuracy gain has an outsized impact on robustness (out-of-distribution generalization). For this purpose, we use a much larger corpus of unlabeled images, where a large fraction of images do not belong to ImageNet training set distribution (i.e., they do not belong to any category in ImageNet). We train our model with Noisy Student Training, a semi-supervised learning approach, which has three main steps: (1) train a teacher model on labeled images, (2) use the teacher to generate pseudo labels on unlabeled images, and (3) train a student model on the combination of labeled images and pseudo labeled images. We iterate this algorithm a few times by treating the student as a teacher to relabel the unlabeled data and training a new student
翻译:
近年来,深度学习在图像识别方面取得了显著的成功[45,80,75,30,83]。然而,最先进的(SOTA)视觉模型仍然使用监督学习进行训练,这需要大量标记图像的语料库才能正常工作。通过仅显示标记图像的模型,我们限制了自己使用大量未标记的图像来提高SOTA模型的准确性和鲁棒性
在这里,我们使用未标记的图像来提高SOTA ImageNet的精度,并表明精度增益对鲁棒性(分布外泛化)有巨大的影响。为此,我们使用更大的未标记图像语料库,其中很大一部分图像不属于ImageNet训练集分布(即,它们不属于ImageNet中的任何类别)。我们使用半监督学习方法“Noisy Student”来训练我们的模型,该方法有三个主要步骤:(1)在标记图像上训练教师模型,(2)使用教师在未标记图像上生成伪标签,(3)在标记图像和伪标记图像的组合上训练学生模型。我们通过将学生视为老师来重新标记未标记的数据并训练新学生来迭代该算法几次
总结:
利用未标记数据非常重要,引入了未标记数据训练Noisy Student
Noisy Student Training improves self-training and distillation in two ways. First, it makes the student larger than, or at least equal to, the teacher so the student can better learn from a larger dataset. Second, it adds noise to the student so the noised student is forced to learn harder from the pseudo labels. To noise the student, we use input noise such as RandAugment data augmentation [18] and model noise such as dropout [76] and stochastic depth [37] during training.
Using Noisy Student Training, together with 300M unlabeled images, we improve EfficientNet’s [83] ImageNet top-1 accuracy to 88.4%. This accuracy is 2.0% better than the previous SOTA results which requires 3.5B weakly labeled Instagram images. Not only our method improves standard ImageNet accuracy, it also improves classification robustness on much harder test sets by large margins: ImageNet-A [32] top-1 accuracy from 61.0% to 83.7%, ImageNet-C [31] mean corruption error (mCE) from 45.7 to 28.3 and ImageNet-P [31] mean flip rate (mFR) from 27.8 to 12.2. Our main results are shown in Table 1.
翻译:
Noisy Student Training从两个方面提高了自我训练和升华。首先,它使学生比老师更大,或者至少等于老师,这样学生就可以更好地从更大的数据集中学习。其次,它给学生增加了噪音,所以有噪音的学生被迫更努力地从伪标签中学习。为了给学生噪声,我们在训练过程中使用输入噪声如RandAugment数据增强[18]和模型噪声如dropout[76]和随机深度[37]。
使用Noisy Student Training,加上300万张未标记的图像,我们将EfficientNet的[83]ImageNet top-1准确率提高到88.4%。这个精度比之前的SOTA结果好2.0%,后者需要3.5B张弱标记的Instagram图像。我们的方法不仅提高了标准ImageNet的准确率,还在更困难的测试集上大幅提高了分类稳健性:ImageNet- a[32]顶级1的准确率从61.0%提高到83.7%,ImageNet- c[31]平均损坏误差(mCE)从45.7提高到28.3,ImageNet- p[31]平均翻转率(mFR)从27.8提高到12.2。我们的主要结果如表1所示。
总结:
对于输入噪声,使用 RandAugment [18] 进行数据增强。简而言之,RandAugment 包括增强:亮度、对比度和清晰度。
对于模型噪声,使用 Dropout [76] 和 Stochastic Depth [37]。
学生模型通常更大,从而能更好地学习更大的数据集
Noisy Student Training
Algorithm 1 gives an overview of Noisy Student Training. The inputs to the algorithm are both labeled and unlabeled images. We use the labeled images to train a teacher model using the standard cross entropy loss. We then use the teacher model to generate pseudo labels on unlabeled images. The pseudo labels can be soft (a continuous distribution) or hard (a one-hot distribution). We then train a student model which minimizes the combined cross entropy loss on both labeled images and unlabeled images.
Finally, we iterate the process by putting back the student as a teacher to generate new pseudo labels and train a new student. The algorithm is also illustrated in Figure 1.
翻译:
算法1给出了Noisy Student Training的概述。算法的输入是有标记和未标记的图像。我们使用标记的图像来训练一个使用标准交叉熵损失的教师模型。然后,我们使用教师模型在未标记的图像上生成伪标签。伪标签可以是软的(连续分布)或硬的(one-hot分布)。然后,我们训练一个学生模型,使标记图像和未标记图像的交叉熵损失最小化。
最后,我们迭代这个过程,把学生作为老师放回去,以生成新的伪标签并训练一个新的学生。该算法如图1所示。


总结:
第 1 步:学习教师模型θt*,它可以最大限度地减少标记图像上的交叉熵损失:
第 2 步:使用正常(即无噪声)教师模型为干净(即无失真)未标记图像生成伪标签;经过测试软伪标签(每个类的概率而不是具体分类)效果更好。
第 3 步:学习一个相等或更大的学生模型θs*,它可以最大限度地减少标记图像和未标记图像上的交叉熵损失,并将噪声添加到学生模型中
步骤 4:学生网络作为老师,从第2步开始进行迭代训练。
The algorithm is an improved version of self-training, a method in semi-supervised learning (e.g., [71, 96]), and distillation [33]. More discussions on how our method is related to prior works are included in Section 5.
Our key improvements lie in adding noise to the student and using student models that are not smaller than the teacher. This makes our method different from Knowledge Distillation [33] where 1) noise is often not used and 2) a smaller student model is often used to be faster than the teacher. One can think of our method as knowledge expansion in which we want the student to be better than the teacher by giving the student model enough capacity and difficult environments in terms of noise to learn through.
翻译:
该算法是自训练的改进版本,是半监督学习(例如,[71,96])和蒸馏[33]中的一种方法。关于我们的方法如何与以前的工作相关联的更多讨论包括在第5节中。
我们的主要改进在于给学生增加噪声,并使用不比老师小的学生模型。这使得我们的方法不同于Knowledge Distillation[33],后者1)通常不使用噪声,2)较小的学生模型通常比教师更快。人们可以把我们的方法看作是知识扩展,我们希望学生比老师做得更好,给学生模型足够的能力,让他们在嘈杂的困难环境中学习。
Noising Student
When the student is deliberately noised it is trained to be consistent to the teacher that is not noised when it generates pseudo labels. In our experiments, we use two types of noise: input noise and model noise. For input noise, we use data augmentation with RandAugment [18]. For model noise, we use dropout [76] and stochastic depth [37].
When applied to unlabeled data, noise has an important benefit of enforcing invariances in the decision function on both labeled and unlabeled data. First, data augmentation is an important noising method in Noisy Student Training because it forces the student to ensure prediction consistency across augmented versions of an image (similar to UDA [91]). Specifically, in our method, the teacher produces high-quality pseudo labels by reading in clean images, while the student is required to reproduce those labels with augmented images as input. For example, the student must ensure that a translated version of an image should have the same category as the original image. Second, when dropout and stochastic depth function are used as noise, the teacher behaves like an ensemble at inference time (when it generates pseudo labels), whereas the student behaves like a single model. In other words, the student is forced to mimic a more powerful ensemble model. We present an ablation study on the effects of noise in Section 4.1.
翻译:
当学生被故意加噪时,它被训练成与老师一致,当它(老师)产生伪标签时没有加噪。在我们的实验中,我们使用了两种类型的噪声:输入噪声和模型噪声。对于输入噪声,我们使用RandAugment进行数据增强[18]。对于模型噪声,我们使用dropout[76]和随机深度[37]。
当应用于未标记数据时,噪声有一个重要的好处,即在标记和未标记数据的决策函数中强制执行不变性。首先,数据增强是Noisy Student Training中的一种重要的降噪方法,因为它迫使学生确保图像的增强版本之间的预测一致性(类似于UDA[91])。具体来说,在我们的方法中,教师通过读取干净的图像来生成高质量的伪标签,而学生则需要用增强的图像作为输入来复制这些标签。例如,学生必须确保图像的翻译版本应与原始图像具有相同的类别。其次,当dropout和随机深度函数被用作噪声时,教师在推理时间(当它生成伪标签时)表现得像一个集成,而学生表现得像一个单一的模型。换句话说,学生被迫模仿一个更强大的集成模型。我们在第4.1节中提出了噪声影响的消融研究。
总结:
由于训练过程中的噪声引入,教师模型学习到了多个略有不同的表示。这使得教师模型在推理时的表现类似于一个集成模型,而学生模型表现得像一个单一的模型。换句话说,学生被迫模仿更强大的集成模型
Other Techniques
Noisy Student Training also works better with an additional trick: data filtering and balancing, similar to [91, 93]. Specifically, we filter images that the teacher model has low confidences on since they are usually out-of-domain images. To ensure that the distribution of the unlabeled images match that of the training set, we also need to balance the number of unlabeled images for each class, as all classes in ImageNet have a similar number of labeled images. For this purpose, we duplicate images in classes where there are not enough images. For classes where we have too many images, we take the images with the highest confidence.
Finally, we emphasize that our method can be used with soft or hard pseudo labels as both work well in our experiments. Soft pseudo labels, in particular, work slightly better for out-of-domain unlabeled data. Thus in the following, for consistency, we report results with soft pseudo labels unless otherwise indicated.
翻译:
Noisy Student Training还可以通过一个额外的技巧来更好地工作:数据过滤和平衡,类似于[91,93]。具体来说,我们过滤了教师模型置信度较低的图像,因为它们通常是域外图像。为了确保未标记图像的分布与训练集的分布相匹配,我们还需要平衡每个类的未标记图像的数量,因为ImageNet中的所有类都有相似数量的标记图像。为此,我们在没有足够图像的类中复制图像。对于我们有太多图像的类,我们以最高的置信度拍摄图像
最后,我们强调,我们的方法可以与软或硬伪标签一起使用,因为在我们的实验中两者都很好。特别是软伪标签,对于域外未标记的数据工作得稍微好一些。因此,在下文中,为了一致性,除非另有说明,否则我们使用软伪标签报告结果。
总结:
教师模型具有低置信度(<0.3)的图像会被过滤
每个类的未标记图像的数量需要进行平衡,因为 ImageNet 中的所有类都具有相似数量的标记图像
硬伪标签:预测结果中最自信的类别作为伪标签使用
软伪标签:利用模型预测的类别概率分布作为伪标签
软伪标签对于域外未标记的数据工作得稍微好一些
Comparisons with Existing SSL Methods
Apart from self-training, another important line of work in semisupervised learning [12, 103] is based on consistency training [5, 64, 47, 84, 56, 91, 8] and pseudo labeling [48, 39, 73, 1]. Although they have produced promising results, in our preliminary experiments, methods based on consistency regularization and pseudo labeling work less well on ImageNet. Instead of using a teacher model trained on labeled data to generate pseudo-labels, these methods do not have a separate teacher model and use the model being trained to generate pseudo-labels. In the early phase of training, the model being trained has low accuracy and high entropy, hence consistency training regularizes the model towards high entropy predictions, and prevents it from achieving good accuracy. A common workaround is to use entropy minimization, to filter examples with low confidence or to ramp up the consistency loss. However, the additional hyperparameters introduced by the ramping up schedule, confidence-based filtering and the entropy minimization make them more difficult to use at scale. The selftraining / teacher-student framework is better suited for ImageNet because we can train a good teacher on ImageNet using labeled data
翻译:
除了自我训练之外,半监督学习的另一项重要工作[12,103]是基于一致性训练[5,64,47,84,56,91,8]和伪标注[48,39,73,1]。虽然他们已经产生了有希望的结果,但在我们的初步实验中,基于一致性正则化和伪标记的方法在ImageNet上的效果不太好。这些方法不是使用在标记数据上训练的教师模型来生成伪标签,而是没有单独的教师模型,而是使用正在训练的模型来生成伪标签。在训练的早期阶段,被训练的模型具有低准确率和高熵,因此一致性训练使模型向高熵预测规范化,从而使其无法达到良好的准确率。一种常见的解决方法是使用熵最小化,过滤低置信度的示例或增加一致性损失。然而,由上升调度、基于置信度的滤波和熵最小化引入的额外超参数使它们更难以大规模使用。自我训练/师生框架更适合于ImageNet,因为我们可以使用标记数据在ImageNet上训练一个好的老师
总结:
以往的模型没有拆分成两个模型生成伪标签,导致难以训练
而Noisy Student允许teacher模型在有标签数据上充分训练后生成伪标签,效果更好
Experiments
Experiment Details
Unlabeled dataset
从JFT数据集[33,15]中获得未标记的图像,该数据集大约有300万张图像。虽然数据集中的图像有标签,但我们忽略标签并将其视为未标记的数据
选择标签置信度高于0.3的图像。对于每个类,我们最多选择130K具有最高置信度的图像。最后,对于拥有少于130K图像的类,我们随机复制一些图像,以便每个类可以拥有130K图像
Architecture
使用efficientnets作为基线模型,因为它们为更多的数据提供了更好的容量
使用了 EfficientNet-L2,它比 EfficientNet-B7 更宽更深,但使用了较低的分辨率,这给了它更多的参数来适应大量未标记的图像
Training details
使用了较大的批处理大小
将标记的图像和未标记的图像连接在一起计算平均交叉熵损失
应用最近提出的技术来修复EfficientNet-L2的列车测试分辨率差异
首先以较小的分辨率进行350次的正常训练,然后在未增强的标记图像上对模型进行1.5 epoch的更大分辨率的微调,在微调期间固定了浅层
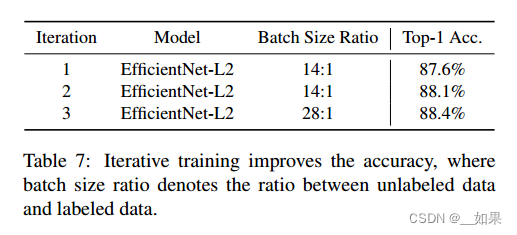
Iterative training
最好的模型是将学生重新作为新老师进行三次迭代的结果
ImageNet Results

即使没有迭代训练,视觉模型也可以从Noisy Student Training中受益
EfficientNet越大越好用
Robustness Results on ImageNet-A, ImageNetC and ImageNet-P
对常见损坏和扰动的图像,如模糊、雾化、旋转和缩放等有很强的鲁棒性
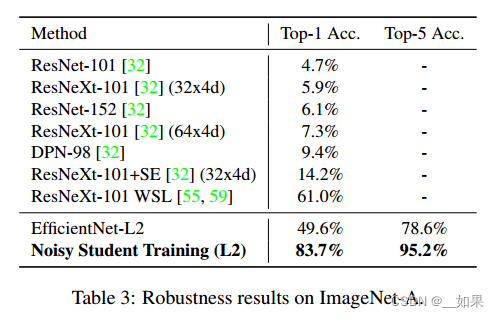
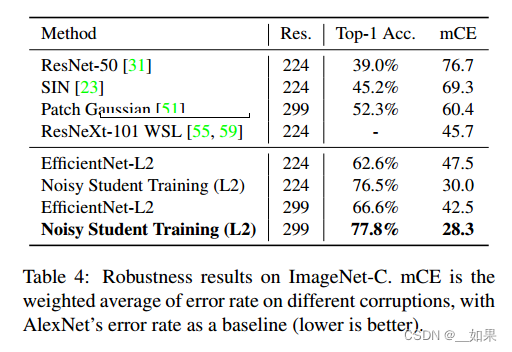

鲁棒性的显著提高是令人惊讶的,因为Noisy Student没有故意优化鲁棒性
Adversarial Robustness Results
After testing our model’s robustness to common corruptions and perturbations, we also study its performance on adversarial perturbations. We evaluate our EfficientNet-L2 models with and without Noisy Student Training against an FGSM attack. This attack performs one gradient descent step on the input image [25] with the update on each pixel set to ε. As shown in Figure 4, Noisy Student Training leads to very significant improvements in accuracy even though the model is not optimized for adversarial robustness. Under a stronger attack PGD with 10 iterations [54], at ε = 16, Noisy Student Training improves EfficientNet-L2’s accuracy from 1.1% to 4.4%.
Note that these adversarial robustness results are not directly comparable to prior works since we use a large input resolution of 800x800 and adversarial vulnerability can scale with the input dimension [22, 25, 24, 74].
翻译:
在测试了我们的模型对常见的破坏和扰动的鲁棒性之后,我们还研究了它对对抗扰动的性能。我们评估了有和没有Noisy Student Training的EfficientNet-L2模型对FGSM攻击的影响。这种攻击在输入图像[25]上执行一个梯度下降步骤,并将每个像素的更新设置为ε。如图4所示,即使模型没有针对对抗鲁棒性进行优化,Noisy Student Training也会导致准确性的显著提高。在10次迭代的更强攻击PGD下[54],当ε = 16时,Noisy Student Training将EfficientNet-L2的准确率从1.1%提高到4.4%。
请注意,这些对抗性鲁棒性结果不能直接与之前的工作进行比较,因为我们使用了800x800的大输入分辨率,并且对抗性漏洞可以随输入维度缩放[22,25,24,74]。
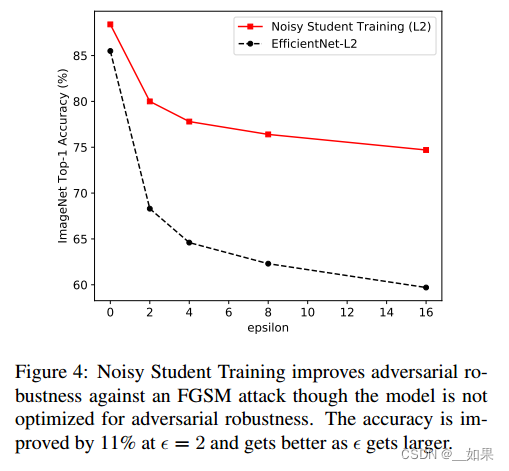
总结:
尽管模型没有针对对抗鲁棒性进行优化,但Noisy Student Training提高了对FGSM攻击的对抗鲁棒性,并且随着ε的增大而提高。
Ablation Study
The Importance of Noise in Self-training
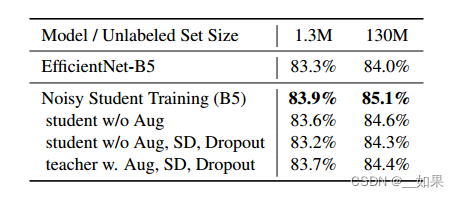
Here, we show the evidence in Table 6, noise such as stochastic depth, dropout and data augmentation plays an important role in enabling the student model to perform better than the teacher. The performance consistently drops with noise function removed. However, in the case with 130M unlabeled images, when compared to the supervised baseline, the performance is still improved to 84.3% from 84.0% with noise function removed. We hypothesize that the improvement can be attributed to SGD, which introduces stochasticity into the training process.
One might argue that the improvements from using noise can be resulted from preventing overfitting the pseudo labels on the unlabeled images. We verify that this is not the case when we use 130M unlabeled images since the model does not overfit the unlabeled set from the training loss. While removing noise leads to a much lower training loss for labeled images, we observe that, for unlabeled images, removing noise leads to a smaller drop in training loss. This is probably because it is harder to overfit the large unlabeled dataset.
Lastly, adding noise to the teacher model that generates pseudo labels leads to lower accuracy, which shows the importance of having a powerful unnoised teacher model.
翻译:
在这里,我们展示了表6中的证据,随机深度、dropout和数据增强等噪声在使学生模型优于教师模型方面发挥了重要作用。去除噪声功能后,性能持续下降。然而,在130M未标记图像的情况下,与监督基线相比,去除噪声函数后的性能仍然从84.0%提高到84.3%。我们假设这种改进可以归因于SGD,它在训练过程中引入了随机性。
有人可能会争辩说,使用噪声的改进可以通过防止在未标记的图像上过度拟合伪标签来实现。当我们使用130M张未标记图像时,我们验证了这种情况,因为模型不会从训练损失中过拟合未标记集。虽然去除噪声对标记图像的训练损失要小得多,但我们观察到,对于未标记图像,去除噪声导致的训练损失下降较小。这可能是因为难以对大型未标记数据集进行过拟合。
最后,在生成伪标签的教师模型中添加噪声会导致准确性降低,这表明拥有一个强大的无噪声教师模型的重要性。
总结:
模型不会从训练损失中过拟合未标记集,对于未标记图像,去除噪声导致的训练损失下降较小可能是因为难以对大型未标记数据集进行过拟合
在生成伪标签的教师模型中添加噪声会导致准确性降低
A Study of Iterative Training
Additional Ablation Study Summarization
• Finding #1: Using a large teacher model with better performance leads to better results.
• Finding #2: A large amount of unlabeled data is necessary for better performance.
• Finding #3: Soft pseudo labels work better than hard pseudo labels for out-of-domain data in certain cases.
• Finding #4: A large student model is important to enable the student to learn a more powerful model.
• Finding #5: Data balancing is useful for small models.
• Finding #6: Joint training on labeled data and unlabeled data outperforms the pipeline that first pretrains with unlabeled data and then finetunes on labeled data.
• Finding #7: Using a large ratio between unlabeled batch size and labeled batch size enables models to train longer on unlabeled data to achieve a higher accuracy.
• Finding #8: Training the student from scratch is sometimes better than initializing the student with the teacher and the student initialized with the teacher still requires a large number of training epochs to perform well.
翻译:
•发现#1:使用表现更好的大型教师模型会带来更好的结果。
•发现#2:大量未标记的数据对于更好的性能是必要的。
•发现#3:在某些情况下,对于域外数据,软伪标签比硬伪标签效果更好。
•发现#4:一个大的学生模型对于让学生学习一个更强大的模型很重要。
•发现#5:数据平衡对小模型很有用。
•发现#6:在标记数据和未标记数据上进行联合训练,优于先使用未标记数据进行预训练,然后在标记数据上进行微调的管道。
•发现#7:在未标记的批大小和已标记的批大小之间使用较大的比例,使模型能够在未标记的数据上训练更长时间,以达到更高的准确性。
•发现#8:从头开始训练学生有时比用老师初始化学生更好,而用老师初始化学生仍然需要大量的训练时间才能表现良好。
Related works
Self-training
与之前的工作的主要区别在于,我们认识到噪音的重要性,并积极地注入噪音,使学生变得更好
Data Distillation [63], which ensembles predictions for an image with different transformations to strengthen the teacher, is the opposite of our approach of weakening the student. Parthasarathi et al [61] find a small and fast speech recognition model for deployment via knowledge distillation on unlabeled data. As noise is not used and the student is also small, it is difficult to make the student better than teacher. The domain adaptation framework in [69] is related but highly optimized for videos, e.g., prediction on which frame to use in a video. The method in [101] ensembles predictions from multiple teacher models, which is more expensive than our method.
Co-training [9] divides features into two disjoint partitions and trains two models with the two sets of features using labeled data. Their source of “noise” is the feature partitioning such that two models do not always agree on unlabeled data. Our method of injecting noise to the student model also enables the teacher and the student to make different predictions and is more suitable for ImageNet than partitioning features.
翻译:
数据蒸馏[63]将不同变换的图像预测组合在一起以增强教师的能力,这与我们削弱学生的方法相反。Parthasarathi等人[61]通过对未标记数据的知识蒸馏,找到了一种小型快速的语音识别模型。由于不使用噪音,学生也小,很难让学生比老师好。[69]中的领域自适应框架是相关的,但对视频进行了高度优化,例如,预测在视频中使用哪一帧。[101]中的方法集成了来自多个教师模型的预测,这比我们的方法更昂贵。
Co-training[9]将特征划分为两个不相交的分区,使用标记数据用两组特征训练两个模型。它们的“噪声”来源是特征划分,这样两个模型在未标记的数据上并不总是一致。我们在学生模型中注入噪声的方法也使老师和学生能够做出不同的预测,并且比分割特征更适合于ImageNet。
Semi-supervised Learning
Apart from self-training, another important line of work in semi-supervised learning [12, 103] is based on consistency training [5, 64, 47, 84, 56, 52, 62, 13, 16, 60, 2, 49, 88, 91, 8, 98, 46, 7]. They constrain model predictions to be invariant to noise injected to the input, hidden states or model parameters. As discussed in Section 2, consistency regularization works less well on ImageNet because consistency regularization uses a model being trained to generate the pseudo-labels. In the early phase of training, they regularize the model towards high entropy predictions, and prevents it from achieving good accuracy.
Works based on pseudo label [48, 39, 73, 1] are similar to self-training, but also suffer the same problem with consistency training, since they rely on a model being trained instead of a converged model with high accuracy to generate pseudo labels. Finally, frameworks in semi-supervised learning also include graph-based methods [102, 89, 94, 42], methods that make use of latent variables as target variables [41, 53, 95] and methods based on low-density separation [26, 70, 19], which might provide complementary benefits to our method.
翻译:
除了自我训练之外,半监督学习的另一项重要工作[12,103]是基于一致性训练[5,64,47,84,56,52,62,13,16,60,2,49,88,91,8,98,46,7]。它们约束模型预测不受注入到输入的噪声、隐藏状态或模型参数的影响。正如第2节所讨论的,一致性正则化在ImageNet上的效果不太好,因为一致性正则化使用正在训练的模型来生成伪标签。在训练的早期阶段,他们将模型正则化到高熵预测,并阻止它达到良好的准确性。
基于伪标签的作品[48,39,73,1]与自训练相似,但也存在一致性训练的问题,因为它们依赖于被训练的模型而不是高精度的收敛模型来生成伪标签。最后,半监督学习的框架还包括基于图的方法[102,89,94,42],使用潜在变量作为目标变量的方法[41,53,95]和基于低密度分离的方法[26,70,19],这些方法可能为我们的方法提供补充优势。
Knowledge Distillation
Our work is also related to methods in Knowledge Distillation [10, 3, 33, 21, 6] via the use of soft targets. The main use of knowledge distillation is model compression by making the student model smaller.The main difference between our method and knowledge distillation is that knowledge distillation does not consider unlabeled data and does not aim to improve the student model.
翻译:
我们的工作也通过使用软目标与知识蒸馏[10,3,33,21,6]中的方法相关。知识蒸馏的主要用途是通过使学生模型更小来压缩模型。我们的方法与知识蒸馏的主要区别在于知识蒸馏不考虑未标记的数据,也不以改进学生模型为目的。
Robustness
A number of studies, e.g. [82, 31, 66, 27], have shown that vision models lack robustness. Addressing the lack of robustness has become an important research direction in machine learning and computer vision in recent years. Our study shows that using unlabeled data improves accuracy and general robustness. Our finding is consistent with arguments that using unlabeled data can improve adversarial robustness [11, 77, 57, 97]. The main difference between our work and these works is that they directly optimize adversarial robustness on unlabeled data, whereas we show that Noisy Student Training improves robustness greatly even without directly optimizing robustness.
翻译:
许多研究,如[82,31,66,27],表明视觉模型缺乏鲁棒性。近年来,解决鲁棒性不足问题已成为机器学习和计算机视觉领域的重要研究方向。我们的研究表明,使用未标记的数据提高了准确性和一般稳健性。我们的发现与使用未标记数据可以提高对抗鲁棒性的观点一致[11,77,57,97]。我们的工作与这些工作之间的主要区别在于,它们直接优化了未标记数据的对抗鲁棒性,而我们表明,即使没有直接优化鲁棒性,Noisy Student Training也可以大大提高鲁棒性。
Conclusion
Prior works on weakly-supervised learning required billions of weakly labeled data to improve state-of-the-art ImageNet models. In this work, we showed that it is possible to use unlabeled images to significantly advance both accuracy and robustness of state-of-the-art ImageNet models.
We found that self-training is a simple and effective algorithm to leverage unlabeled data at scale. We improved it by adding noise to the student, hence the name Noisy Student Training, to learn beyond the teacher’s knowledge.
Our experiments showed that Noisy Student Training and EfficientNet can achieve an accuracy of 88.4% which is 2.9% higher than without Noisy Student Training. This result is also a new state-of-the-art and 2.0% better than the previous best method that used an order of magnitude more weakly labeled data [55, 86].
An important contribution of our work was to show that Noisy Student Training boosts robustness in computer vision models. Our experiments showed that our model significantly improves performances on ImageNet-A, C and P.
翻译:
先前关于弱监督学习的工作需要数十亿弱标记数据来改进最先进的ImageNet模型。在这项工作中,我们证明了使用未标记的图像可以显著提高最先进的ImageNet模型的准确性和鲁棒性。
我们发现自我训练是一种简单而有效的算法,可以大规模地利用未标记的数据。我们通过给学生增加噪音来改进它,因此命名为Noisy Student Training,以学习超越老师的知识。
我们的实验表明,Noisy Student Training和EfficientNet可以达到88.4%的准确率,比没有Noisy Student Training训练提高2.9%。该结果也是一种新的最先进的方法,比之前使用弱标记数据数量级的最佳方法好2.0%[55,86]。
我们工作的一个重要贡献是表明,Noisy Student Training提高了计算机视觉模型的鲁棒性。我们的实验表明,我们的模型显著提高了ImageNet-A, C和P上的性能。




![猫头虎分享已解决Bug || RuntimeError: size mismatch, m1: [32 x 100], m2: [500 x 10]](https://img-blog.csdnimg.cn/direct/aa86eef0d81e4f279688a772e92ea3bc.webp#pic_center)