文章目录
- 3.1 性能优化简介
- 3.1.1 通过性能剖析进行优化
- 3.1.2 理解性能剖析
- 3.2 对应用程序进行性能剖析
- 3.3 剖析 MySQL 查询
- 3.3.1 剖析服务器负载
- 捕获 MySQL 的查询到日志文件中
- 分析查询日志
- 3.3.2 剖析单挑查询
- 使用 SHOW PROFILE (现已过时)
- 使用SHOW STATUS
- 3.4 诊断间歇性问题
- 3.4.1 单条查询问题还是服务器问题
- 使用SHOW GLOBAL STATUS
- 使用SHOW PROCESSLIST
- 使用查询日志
- 理解发现的问题(Making sense of the findings)
- 3.4.2 捕获诊断数据
- 诊断触发器
- 需要收集什么样的数据
- 解释结果数据
- 3.5 其他剖析工具
- 3.5.1 使用 USER_STATISTICS 表
- 3.5.2 使用 strace
作者总结在他们的技术咨询生涯中,最常碰到的三个性能相关的服务请求是:
- 如何确认服务器是否达到了性能最佳状态
- 找出某条语句为什么执行不够快
- 诊断被用户描述成“停顿”、“堆积”或者“卡死”的某些间歇性疑难故障。
性能剖析的一个简单方法是专注于测量服务器的事件花费在哪里,使用的技术叫做性能剖析(profiling)。在本章,我们将展示如何测量系统并生成剖析报告,以及如何分析系统的整个堆栈(stack),包括从应用程序到数据库服务器到单个查询。
3.1 性能优化简介
先来看一下我们对性能的定义:
-
性能
- 即 响应时间,完成某个任务所需要的时间度量。这是一个非常重要的原则。
我们通过任务和时间而不是资源来测量性能。数据库服务器的目的是执行 SQL 语句,所以它关注的任务是 查询 或者语句,如 SELECT 、UPDATE、DELETE 等。数据库服务器的性能用查询的响应时间来度量,单位是每个查询花费的时间。
然后简要定义了性能优化为在一定工作负载下尽可能地降低响应时间。注意,优化和提升是两回事。当继续提升的成本超过收益的时候,应当停止优化。
作者推荐了两篇有关性能优化的文章(如今可能有些过时了):
- Goal-Driven Performance Optimization
- Optimizing Oracle Performance (O’Reilly) by Cary Millsap, Jeff Holt
-
吞吐量
- 单位时间内的查询数量。正好是我们对性能的定义的倒数。
降低 CPU 等资源的利用率、提升吞吐量可以看作是性能优化的副产品,而不是性能优化本身。
性能优化第一步要做的是测量响应时间花在哪里,并且应将大部分(甚至 90%)时间花在这里。如果测量系统获得了足够完整、精确的数据,性能问题一般都能暴露出来。如果通过测量没有找到答案,那要么是测量方式错了,要么是测量得不够完整。
**完成一项任务所需要的时间可以分成两部分:执行时间和等待时间。**如果要优化任务的执行时间,最好的办法是通过测量定位不同的子任务花费的时间,然后优化去掉一些子任务、降低子任务的执行频率或执行时间。而优化任务的等待时间则相对要复杂一些,因为等待有可能是由其他系统间接影响导致,任务之间也可能由于争用磁盘或者 CPU 资源而相互影响。根据时间花在执行还是等待上的不同,诊断也需要不同的工具和技术。性能剖析是确认哪些子任务需要优化的技术。
注意:测量的数据很可能是不准确的,测量结果有时无法反映真实情况,我们仅需要保证测量数据的偏差在可接受范围内并且不影响分析问题。
3.1.1 通过性能剖析进行优化
性能剖析是测量和分析时间花费在哪里的主要方法。性能剖析一般分为两步:
- 测量任务所花费的时间;
- 然后按任务的重要程度(从高到低)对结果进行统计和排序。
性能剖析报告(profile report) 会列出所有任务列表,每行记录一个任务,包括任务名、任务的执行时间、任务的消耗时间、任务的平均执行时间,以及该任务执行时间占全部时间的百分比,按任务的消耗时间进行降序排序。
有两种类型的性能剖析:基于执行时间的分析和基于等待的分析。如果可以确定时间大部分花在执行还是等待上,另一部分时间的影响相对很小,则应集中精力优先处理重要的部分,对不重要的部分的优化可以推迟甚至不做。
在性能剖析报告中显示的某些“执行时间”实际上是在等待。例如,报告中显示某些 SELECT 查询花费了大量时间,深入分析则可能发现时间都花在了等待 I/O 完成上。
对系统剖析前,需要确保系统是可测量的。这需要系统提供一些计数器来形成测量点。如果系统内部无法做到可测量化,则可从外部测量系统。如果测量失败,可以根据对系统的了解做出一些靠谱的猜测。但,无论是外部测量还是猜测,数据都不是百分百准确的,这是系统不透明所带来的风险。
3.1.2 理解性能剖析
性能剖析报告缺失的信息:
- 值得优化的查询。首先,一些只占总响应时间比重很小的查询是不值得优化的。根据阿姆达尔定律(Amadahl’s Law),对一个占总响应时间不超过 5% 的查询进行优化,无论如何努力,收益也不会超过 5% 。其次,如果优化的成本大于收益,就应当停止优化。
- 异常情况。某些任务即使没有出现在性能剖析输出的前面也需要优化。例如,某些任务执行频率很低,但每次执行都很慢,严重影响用户体验。
- “丢失的时间”。一款好的性能剖析工具会显示可能存在的“丢失的时间”。“丢失的时间”指的是任务的总时间和实际测量到的时间的差值。例如,如果处理器的 CPU 时间是 10 秒,而剖析到的任务总时间是 9.7 秒,那么就有 300 毫秒的丢失时间。这可能是有些任务没有测量到,也可能是由于测量的误差和精度问题的缘故。
- 被掩藏的细节。性能剖析无法显示所有响应时间的分布。平均值无法表达全部情况。例如,测量医院所有病人的平均体温没有任何价值。应追加更多响应时间的信息,比如直方图、百分比、标准差、方差、偏差指数等。
推荐使用 pt-query-digest ,它在剖析的结果里包含了很多这类细节信息,并输出在剖析报告中。
3.2 对应用程序进行性能剖析
对整个应用系统进行性能剖析时建议采自顶向下地进行,这样可以追踪自用户发起到服务器响应的整个流程。
建议在所有的新项目中都考虑包含性能剖析的代码。
建议使用诸如 New Relic 、Pinpoint 的应用性能监控分析工具。
APM 是 Application Performance Managment 的缩写,即:“应用性能管理”。现代的APM体系,基本都是参考Google的《Dapper,大规模分布式系统的跟踪系统》的体系来实践的。
3.3 剖析 MySQL 查询
3.3.1 剖析服务器负载
服务器端的剖析很有价值,因为在服务器端可以有效地审计效率低下的查询。定位和优化“坏”查询能够显著地提升应用的性能,也能解决某些特定的难题。还可以降低服务器的整体压力,这样所有的查询都将因为减少了对共享资源的争用而受益(“间接的好处”)。降低服务器的负载也可以推迟或者避免升级更昂贵硬件的需求,还可以发现和定位糟糕的用户体验,比如某些极端情况。
捕获 MySQL 的查询到日志文件中
在 MySQL 5.1 以上版本中,慢查询日志功能已经被加强,可以通过设置 long_query_time 为 0 来捕获所有查询 ,而且查询的响应时间单位已经可以做到微秒级。
在 MySQL 的当前版本中,慢查询日志是开销最低、精度最高的测量查询时间的工具。如果长期开启慢查询日志,注意要部署 日志轮转(log rotation) 工具。或者不要长期启用慢查询日志,只在需要收集负载样本的期间开启即可。
通用日志在查询请求到服务器时进行记录,所以不包含响应时间和执行计划等重要信息。
有时因为某些原因如权限不足等,无法在服务器上记录查询。这样的限制我们也常常碰到,所以我们开发了两种替代的技术,都集成到了 Percona Toolkit 中的 pt-query-digest 中。第一种是通过 --processlist 选项不断查看 SHOW FULL PROCESSLIST 的输出,记录查询第一次出现的时间和消失的时间。某些情况下这样的精度也足够发现问题,但却无法捕获所有的查询。一些执行较快的查询可能在两次执行的间隙就执行完成了,从而无法捕获到。
第二种技术是通过抓取 TCP 网络包,然后根据 MySQL 的客户端/服务端通信协议进行解析。可以先通过 tcpdump 将网络包数据保存到磁盘,然后使用 pt-query-digest 的 --type=tcpdump 选项来解析并分析查询。此方法的精度比较高,并且可以捕获所有查询。还可以解析更高级的协议特性,比如可以解析二进制协议,从而创建并执行服务端预解析的语句(prepared statement)及压缩协议。另外还有一种方法,就是通过 MySQL Proxy 代理层的脚本来记录所有查询,但在实践中我们很少这样做。
分析查询日志
不要直接打开整个慢查询日志进行分析,这样做只会浪费时间和金钱。首先应该生成一个剖析报告,如果需要,则可以再查看日志中需要特别关注的部分。自顶向下是比较好的方式,否则有可能像前面提到的,反而导致业务的逆优化。
从慢查询日志中生成剖析报告需要有一款好工具,这里我们建议使用 pt-query-digest ,这毫无疑问是分析 MySQL 查询日志最有力的工具。该工具功能强大,包括可以将查询报告保存到数据库中,以及追踪工作负载随时间的变化。
这里给出一份 pt-query-digest 输出的报告的例子,作为进行性能剖析的开始。这是前面提到过的一个未修改过的剖析报告:
# Profile
# Rank Query ID Response time Calls R/Call V/M Item
# ==== ================== ================ ===== ====== ===== =======
# 1 0xBFCF8E3F293F6466 11256.3618 68.1% 78069 0.1442 0.21 SELECT InvitesNew?
# 2 0x620B8CAB2B1C76EC 2029.4730 12.3% 14415 0.1408 0.21 SELECT StatusUpdate?
# 3 0xB90978440CC11CC7 1345.3445 8.1% 3520 0.3822 0.00 SHOW STATUS
# 4 0xCB73D6B5B031B4CF 1341.6432 8.1% 3509 0.3823 0.00 SHOW STATUS
# MISC 0xMISC 560.7556 3.4% 23930 0.0234 0.0 <17 ITEMS>
可以看到这个比之前的版本多了一些细节。首先,每个查询都有一个 ID,这是对查询语句计算出的哈希值指纹,计算时去掉了查询条件中的文本值和所有空格,并且全部转化为小写字母(请注意第三条和第四条语句的摘要看起来一样,但哈希指纹是不一样的)。该工具对表名也有类似的规范做法。表名 InvitesNew 后面的问号意味着这是一个 分片(shard) 的表,表名后面的分片标识被问号替代,这样就可以将同一组分片表作为一个整体做汇总统计。这个例子实际上是来自一个压力很大的分片过的 Facebook 应用。
报告中的 V/M 列提供了方差均值比(variance-to-mean ratio)的详细数据,方差均值比也就是常说的离差指数(index of dispersion)。离差指数高的查询对应的执行时间的变化较大,而这类查询通常都值得去优化。如果 pt-query-digest 指定了 --explain 选项,输出结果中会增加一列简要描述查询的执行计划,执行计划是查询背后的“极客代码”。通过联合观察执行计划列和V/M列,可以更容易识别出性能低下需要优化的查询。
最后,在尾部也增加了一行输出,显示了其他 17 个占比较低而不值得单独显示的查询的统计数据。可以通过–limit和–outliers选项指定工具显示更多查询的详细信息,而不是将一些不重要的查询汇总在最后一行。默认只会打印时间消耗前 10 位的查询,或者执行时间超过 1 秒阈值很多倍的查询,这两个限制都是可配置的。
剖析报告的后面包含了每种查询的详细报告。可以通过查询的ID或者排名来匹配前面的剖析统计和查询的详细报告。下面是排名第一也就是“最差”的查询的详细报告:
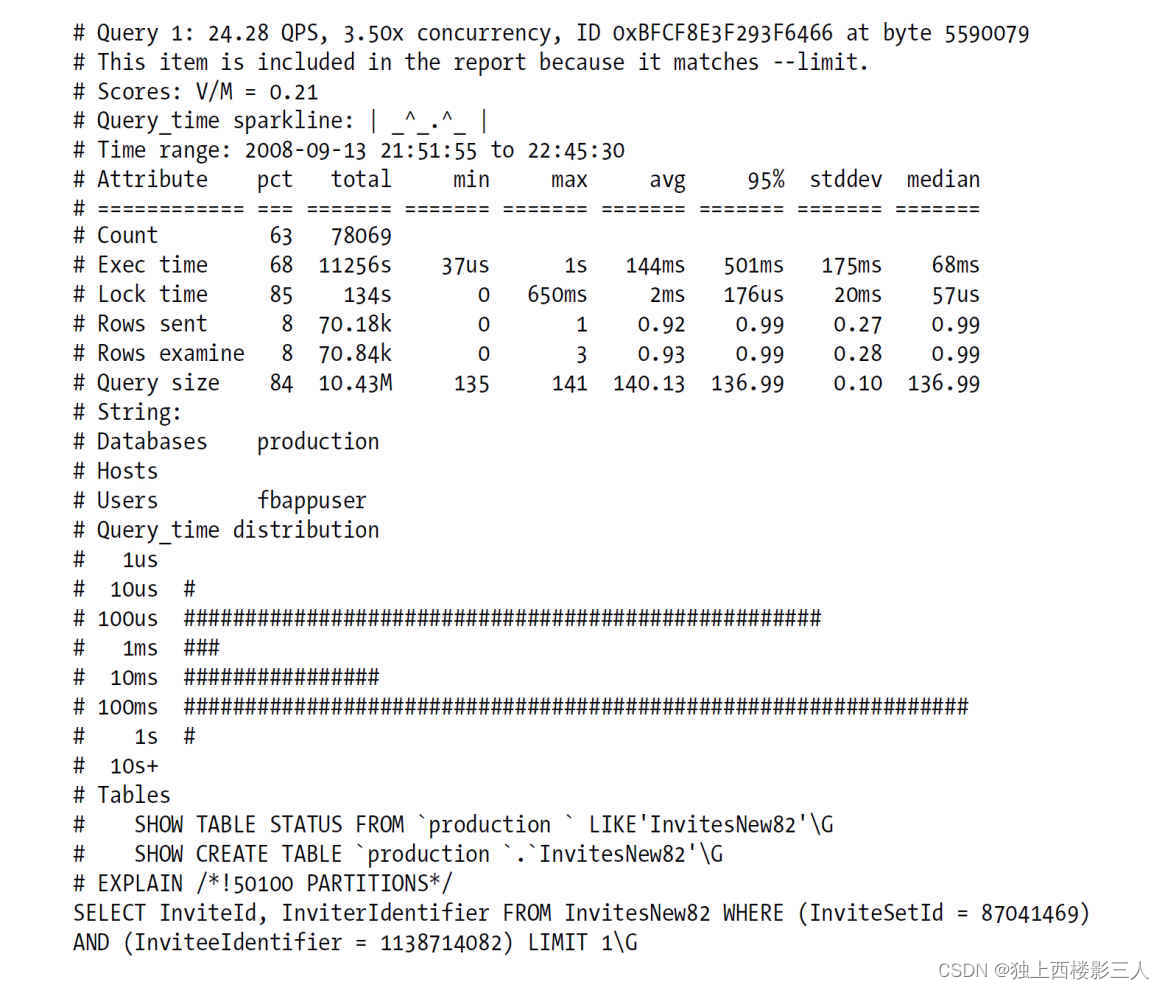
查询报告的顶部包含了一些元数据,包括查询执行的频率、平均并发度,以及该查询性能最差的一次执行在日志文件中的字节偏移值,接下来还有一个表格格式的元数据,包括诸如标准差一类的统计信息。
接下来的部分是响应时间的直方图。
在细节报告的最后部分是方便复制、粘贴到终端去检查表的模式和状态的语句,以及完整的可用于EXPLAIN分析执行计划的语句。
3.3.2 剖析单挑查询
使用 SHOW PROFILE (现已过时)
默认是禁用的,但可以通过服务器变量在会话(连接)级别动态地修改。
mysql> SET profiling = 1;
然后,在服务器上执行的所有语句,都会测量其耗费的时间和其他一些查询执行状态变更相关的数据。这个功能有一定的作用,而且最初的设计功能更强大,但未来版本中可能会被 Performance Schema 所取代。尽管如此,这个工具最有用的作用还是在语句执行期间剖析服务器的具体工作。输出是按照执行顺序排序,而不是按花费的时间排序的,且无法通过诸如ORDER BY之类的命令重新排序。假如不使用SHOW PROFILE命令而是直接查询INFORMATION_SCHEMA中对应的表,则可以按照需要格式化输出:
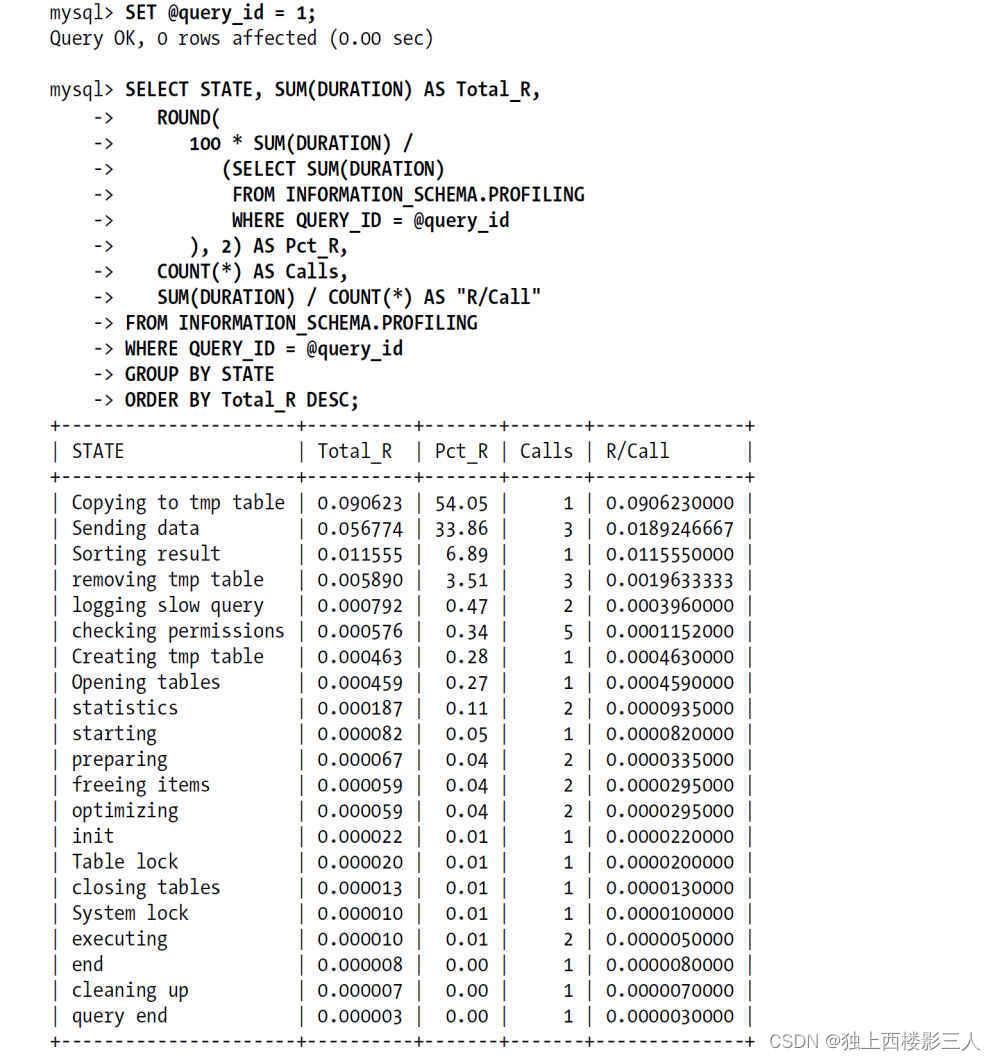
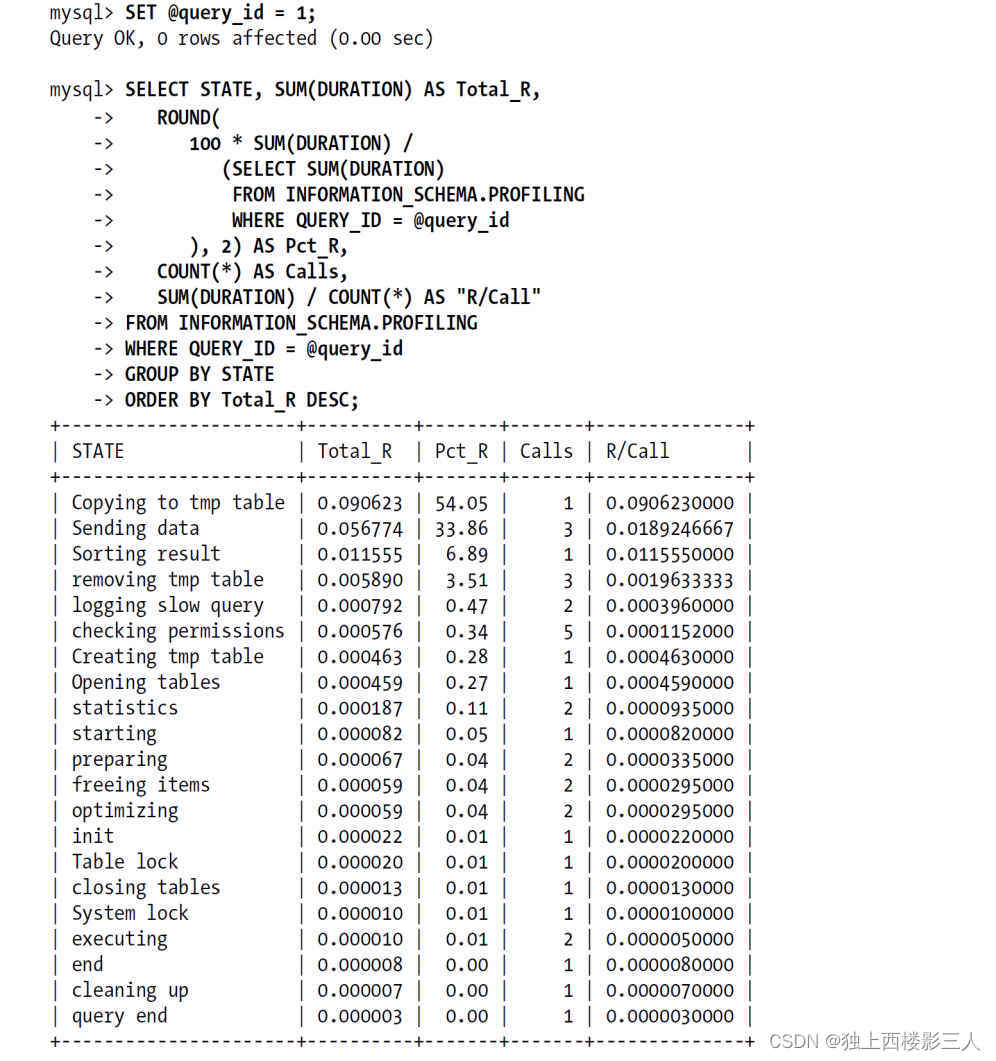
效果好多了!通过这个结果可以很容易看到查询时间太长主要是因为花了一大半的时间在将数据复制到临时表这一步。那么优化就要考虑如何改写查询以避免使用临时表,或者提升临时表的使用效率。第二个消耗时间最多的是“发送数据(Sending data)”,这个状态代表的原因非常多,可能是各种不同的服务器活动,包括在关联时搜索匹配的行记录等,这部分很难说能优化节省多少消耗的时间。另外也要注意到“结果排序(Sorting result)”花费的时间占比非常低,所以这部分是不值得去优化的。这是一个比较典型的问题,所以一般我们都不建议用户在“优化排序缓冲区(tuning sort buffer)”或者类似的活动上花时间。
使用SHOW STATUS
SHOW STATUS 是一个有用的工具,但并不是一款剖析工具。SHOW STATUS的大部分结果都只是一个计数器,可以显示某些活动如读索引的频繁程度,但无法给出消耗了多少时间。SHOW STATUS的结果中只有一条指的是操作的时间(Innodb_row_lock_time),而且只能是全局级的,所以还是无法测量会话级别的工作。
最有用的计数器包括句柄计数器(handler counter)、临时文件和表计数器等。
从结果可以看到该查询使用了三个临时表,其中两个是磁盘临时表,并且有很多的没有用到索引的读操作(Handler_read_rnd_next)。
使用这个技术的时候,要注意SHOW STATUS本身也会创建一个临时表,而且也会通过句柄操作访问此临时表,这会影响到SHOW STATUS结果中对应的数字,而且不同的版本可能行为也不尽相同。
你可能会注意到通过EXPLAIN查看查询的执行计划也可以获得大部分相同的信息,但EXPLAIN是通过估计得到的结果,而通过计数器则是实际的测量结果。例如,EXPLAIN无法告诉你临时表是否是磁盘表,这和内存临时表的性能差别是很大的。
3.4 诊断间歇性问题
间歇性的问题比如系统偶尔停顿或者慢查询,很难诊断。
为了演示为什么要尽量避免试错的诊断方式,下面列举了我们认为已经解决的一些间歇性数据库性能问题的实际案例:
- 应用通过
curl从一个运行得很慢的外部服务来获取汇率报价的数据。 - memcached 缓存中的一些重要条目过期,导致大量请求落到 MySQL 以重新生成缓存条目。
即 缓存击穿、缓存雪崩。
- DNS 查询偶尔会有超时现象。
- 可能是由于互斥锁争用,或者内部删除查询缓存的算法效率太低的缘故,MySQL 的查询缓存有时候会导致服务有短暂的停顿。
- 当并发度超过某个阈值时,InnoDB 的扩展性限制导致查询计划的优化需要很长的时间。
3.4.1 单条查询问题还是服务器问题
如何判断是单条查询问题还是服务器问题呢?如果问题不停地周期性出现,那么可以在某次活动中观察到;或者整夜运行脚本收集数据,第二天来分析结果。大多数情况下都可以通过三种技术来解决,下面将一一道来。
使用SHOW GLOBAL STATUS
这个方法实际上就是以较高的频率比如一秒执行一次SHOW GLOBAL STATUS命令捕获数据,问题出现时,则可以通过某些计数器(比如Threads_running、Threads_connected、Questions和Queries)的“尖刺”或者“凹陷”来发现。这个方法比较简单,所有人都可以使用(不需要特殊的权限),对服务器的影响也很小,所以是一个花费时间不多却能很好地了解问题的好方法。
$ mysqladmin ext -i1 | awk '
/Queries/{q=$4-qp;qp=$4}
/Threads_connected/{tc=$4}
/Threads_running/{printf "%5d %5d %5d\n", q, tc, $4}'
2147483647 136 7
798 136 7
767 134 9
828 134 7
683 134 7
784 135 7
614 134 7
108 134 24
187 134 31
179 134 28
1179 134 7
1151 134 7
1240 135 7
1000 135 7
这个命令每秒捕获一次SHOW GLOBAL STATUS的数据,输出给awk计算并输出每秒的查询数、Threads_connected和Threads_running(表示当前正在执行查询的线程数)。这三个数据的趋势对于服务器级别偶尔停顿的敏感性很高。一般发生此类问题时,根据原因的不同和应用连接数据库方式的不同,每秒的查询数一般会下跌,而其他两个则至少有一个会出现尖刺。
在实践中有两个原因的可能性比较大。其中之一是服务器内部碰到了某种瓶颈,导致新查询在开始执行前因为需要获取老查询正在等待的锁而造成堆积。另外一个常见的原因是服务区突然遇到了大量查询请求的冲击,比如前端的memcached 突然失效导致的查询风暴。
这个命令每秒输出一行数据,可以运行几个小时或者几天,然后将结果绘制成图形,这样就可以方便地发现是否有趋势的突变。
使用SHOW PROCESSLIST
这个方法是通过不停地捕获SHOW PROCESSLIST的输出,来观察是否有大量线程处于不正常的状态或者有其他不正常的特征。
示例:
$ mysql -e 'SHOW PROCESSLIST\G' | grep State: | sort | uniq -c | sort -rn
744 State:
67 State: Sending data
36 State: freeing items
8 State: NULL
6 State: end
4 State: Updating
4 State: cleaning up
2 State: update
1 State: Sorting result
1 State: logging slow query
大量的线程处于“freeing items”状态是出现了大量有问题查询的很明显的特征和指示。
用这种技术查找问题,上面的命令行不是唯一的方法。如果MySQL服务器的版本较新,也可以直接查询INFORMATION_SCHEMA中的PROCESSLIST表;或者使用innotop工具以较高的频率刷新,以观察屏幕上出现的不正常查询堆积。上面演示的这个例子是由于InnoDB内部的争用和脏块刷新所导致,但有时候原因可能比这个要简单得多。一个经典的例子是很多查询处于“Locked”状态,这是MyISAM的一个典型问题,它的表级别锁定,在写请求较多时,可能迅速导致服务器级别的线程堆积。
使用查询日志
如果因为某些原因,不能设置慢查询日志记录所有的查询,也可以通过tcpdump和pt-query-digest工具来模拟替代。要注意找到吞吐量突然下降时间段的日志。查询是在完成阶段才写入到慢查询日志的,所以堆积会造成大量查询处于完成阶段,直到阻塞其他查询的资源占用者释放资源后,其他的查询才能执行完成。这种行为特征的一个好处是,当遇到吞吐量突然下降时,可以归咎于吞吐量下降后完成的第一个查询(有时候也不一定是第一个查询。当某些查询被阻塞时,其他查询可以不受影响继续运行,所以不能完全依赖这个经验)。
根据MySQL每秒将当前时间写入日志中的模式统计每秒的查询数量:
$ awk '/^# Time:/{print$3,$4,c;c=0}/^# User/{c++}' slow-query.log
080913 21:52:17 51
080913 21:52:18 29
080913 21:52:19 34
080913 21:52:20 33
080913 21:52:21 38
080913 21:52:22 15
080913 21:52:23 47
080913 21:52:24 96
080913 21:52:25 6
080913 21:52:26 66
080913 21:52:27 37
080913 21:52:28 59
理解发现的问题(Making sense of the findings)
可视化的数据最具有说服力。上面只演示了很少的几个例子,但在实际情况中,利用上面的工具诊断时可能产生大量的输出结果。可以选择用 gnuplot 或 R,或者其他绘图工具将结果绘制成图形。
我们建议诊断问题时先使用前两种方法:SHOW STATUS和SHOW PROCESSLIST。这两种方法的开销很低,而且可以通过简单的shell脚本或者反复执行的查询来交互式地收集数据。分析慢查询日志则相对要困难一些,经常会发现一些蛛丝马迹,但仔细去研究时可能又消失了。这样我们很容易会认为其实没有问题。
发现输出的图形异常意味着什么?通常来说可能是查询在某个地方排队了,或者某种查询的量突然飙升了。接下来的任务就是找出这些原因。
3.4.2 捕获诊断数据
当出现间歇性问题时,需要尽可能多地收集所有数据,而不只是问题出现时的数据。虽然这样会收集大量的诊断数据,但总比真正能够诊断问题的数据没有被收集到的情况要好。
在开始之前,需要搞清楚两件事:
- 一个可靠且实时的“触发器”,也就是能区分什么时候问题出现的方法。
- 一个收集诊断数据的工具。
诊断触发器
触发器非常重要。这是在问题出现时能够捕获数据的基础。有两个常见的问题可能导致无法达到预期的结果:误报(false positive)或者漏检(false negative)。误报是指收集了很多诊断数据,但期间其实没有发生问题,这可能浪费时间,而且令人沮丧。而漏检则指在问题出现时没有捕获到数据,错失了机会,一样地浪费时间。所以在开始收集数据前多花一点时间来确认触发器能够真正地识别问题是划算的。
那么好的触发器的标准是什么呢?像关键是找到一些能和正常时的阈值进行比较的指标。通常情况下这是一个计数,比如正在运行的线程的数量、处于“freeing items”状态的线程的数量等。
选择一个合适的阈值很重要,既要足够高,以确保在正常时不会被触发;又不能太高,要确保问题发生时不会错过。另外要注意,要在问题开始时就捕获数据,就更不能将阈值设置得太高。
触发条件可以这样设置:每秒监控状态值,如果Threads_running连续5秒超过20,就开始收集诊断数据。
需要收集什么样的数据
答案是尽可能收集所有能收集的数据,但只在需要的时间段内收集。包括系统的状态、CPU利用率、磁盘使用率和可用空间、ps的输出采样、内存利用率,以及可以从MySQL获得的信息,如SHOW STATUS、SHOW PROCESSLIST和SHOW INNODB STATUS。这些在诊断问题时都需要用到(可能还会有更多)。
执行时间包括用于工作的时间和等待的时间。当一个未知问题发生时,一般来说有两种可能:服务器需要做大量的工作,从而导致大量消耗CPU;或者在等待某些资源被释放。所以需要用不同的方法收集诊断数据,来确认是何种原因:剖析报告用于确认是否有太多工作,而等待分析则用于确认是否存在大量等待。如果是未知的问题,怎么知道将精力集中在哪个方面呢?没有更好的办法,所以只能两种数据都尽量收集。
在GNU/Linux平台,可用于服务器内部诊断的一个重要工具是oprofile。后面会展示一些例子。也可以使用strace剖析服务器的系统调用,但在生产环境中使用它有一定的风险。后面还会继续讨论它。如果要剖析查询,可以使用tcpdump。大多数MySQL版本无法方便地打开和关闭慢查询日志,此时可以通过监听TCP流量来模拟。另外,网络流量在其他一些分析中也非常有用。
对于等待分析,常用的方法是GDB的堆栈跟踪。MySQL内的线程如果卡在一个特定的地方很长时间,往往都有相同的堆栈跟踪信息。还可以用 pt-pmp 工具来完成这个工作。
pt-collect 用于收集数据,一般通过 pt-stalk 来调用。因为涉及很多重要数据的收集,所以需要用root权限来运行。默认情况下,启动后会收集30秒的数据,然后退出。对于大多数问题的诊断来说,这已经足够,但如果有误报(false positive)的问题出现,则可能收集的信息就不够。这个工具很容易下载到,并且不需要任何配置,配置都是通过pt-stalk进行的。系统中最好安装gdb和oprofile,然后在pt-stalk中配置使用。另外mysqld也需要有调试[符号信息]。当触发条件满足时,pt-collect会很好地收集完整的数据。它也会在目录中创建时间戳文件。
解释结果数据
如果已经正确地设置好触发条件,并且长时间运行pt-stalk,则只需要等待足够长的时间来捕获几次问题,就能够得到大量的数据来进行筛选。从哪里开始最好呢?我们建议先根据两个目的来查看一些东西。第一,检查问题是否真的发生了,因为有很多的样本数据需要检查,如果是误报就会白白浪费大量的时间。第二,是否有非常明显的跳跃性变化。
在服务器正常运行时捕获一些样本数据也很重要,而不只是在有问题时捕获数据。这样可以帮助对比确认是否某些样本,或者样本中的某部分数据有异常。例如,在查看进程列表(process list)中查询的状态时,可以回答一些诸如“大量查询处于正在排序结果的状态是不是正常的”的问题。
查看异常的查询或事务的行为,以及异常的服务器内部行为通常都是最有收获的。查询或事务的行为可以显示是否是由于使用服务器的方式导致的问题:性能低下的SQL查询、使用不当的索引、设计糟糕的数据库逻辑架构等。通过抓取TCP流量或者SHOW PROCESSLIST输出,可以获得查询和事务出现的地方,从而知道用户对数据库进行了什么操作。通过服务器的内部行为则可以清楚服务器是否有bug,或者内部的性能和扩展性是否有问题。这些信息在类似的地方都可以看到,包括在oprofile或者gdb的输出中,但要理解则需要更多的经验。
如果遇到无法解释的错误,则最好将收集到的所有数据打包,提交给技术支持人员进行分析。MySQL的技术支持专家应该能够从数据中分析出原因,详细的数据对于支持人员来说非常重要。另外也可以将Percona Toolkit中另外两款工具pt-mysql-summary和pt-summary的输出结果打包,这两个工具会输出MySQL的状态和配置信息,以及操作系统和硬件的信息。
Percona Toolkit还提供了一款快速检查收集到的样本数据的工具:pt-sift。这个工具会轮流导航到所有的样本数据,得到每个样本的汇总信息。如果需要,也可以钻取到详细信息。使用此工具至少可以少打很多字,少敲很多次键盘。
另外一个重要的关于等待分析的性能瓶颈分析工具是gdb的堆栈跟踪。堆栈需要自下而上来看。要真正地发挥堆栈跟踪的价值需要将很多的信息聚合在一起来看。这种技术是由Domas Mituzas推广的,他以前是MySQL的支持工程师,开发了著名的穷人剖析器“poor man’s profiler”。他目前在Facebook工作,和其他人一起开发了更多的收集和分析堆栈跟踪的工具。可以从他的这个网站发现更多的信息:http://www.poormansprofiler.org。
在Percona Toolkit中我们也开发了一个类似的穷人剖析器,叫做 pt-pmp 。这是一个用shell和awk脚本编写的工具,可以将类似的堆栈跟踪输出合并到一起,然后通过sort|uniq|sort将最常见的条目在最前面输出。
3.5 其他剖析工具
3.5.1 使用 USER_STATISTICS 表
有几个要点要说明一下:
- 可以查找使用得最多或者使用得最少的表和索引,通过读取次数或者更新次数,或者两者一起排序。
- 可以查找出从未使用的索引,可以考虑删除之。
- 可以看看复制用户的CONNECTED_TIME和BUSY_TIME,以确认复制是否会很难跟上主库的进度。
在MySQL 5.6中,Performance Schema中也添加了很多类似上面这些功能的表。
3.5.2 使用 strace
strace工具可以调查系统调用的情况。有好几种可以使用的方法,其中一种是计算系统调用的时间并打印出来:

这种用法和oprofile有点像。但是oprofile还可以剖析程序的内部符号,而不仅仅是系统调用。另外,strace拦截系统调用使用的是不同于oprofile的技术,这会有一些不可预期性,开销也更大些。strace度量时使用的是实际时间,而oprofile使用的是花费的CPU周期。举个例子,当I/O等待出现问题的时候,strace能将它们显示出来,因为它从诸如read或者pread64这样的系统调用开始计时,直到调用结束。但oprofile不会这样,因为I/O系统调用并不会真正地消耗CPU周期,而只是等待I/O完成而已。
我们会在需要的时候使用oprofile,因为strace对像mysqld这样有大量线程的场景会产生一些副作用。当strace附加上去后,mysqld的运行会变得很慢,因此不适合在产品环境中使用。但在某些场景中strace还是相当有用的,Percona Toolkit中有一个叫做pt-ioprofile的工具就是使用strace来生成I/O活动的剖析报告的。这个工具很有帮助,可以证明或者驳斥某些难以测量的情况下的一些观点,此时其他方法很难达到目的(如果运行的是MySQL 5.6,使用Performance Schema也可以达到目的)。
![猫头虎分享已解决Bug || RuntimeError: size mismatch, m1: [32 x 100], m2: [500 x 10]](https://img-blog.csdnimg.cn/direct/aa86eef0d81e4f279688a772e92ea3bc.webp#pic_center)