【深度学习:TACO 数据集】探索 TACO 数据集【模型训练】
- 介绍
- 为什么选择以数据为中心的人工智能?
- 上次我们学到了什么?
- 问题
- 关于数据集
- 方法
- 什么是“对象注释质量”指标?
- 第一次迭代:修复标签错误
- 分析
- 重新贴标签
- 模型再训练
- 第二次迭代:修复错误标记的对象
- 分析
- 重新贴标签
- 模型再训练
- 结论
介绍
想象一下,您正在建造一个可以收集地面垃圾的自主机器人。作为机器学习工程师,您将负责赋予其在任何环境中检测垃圾的能力。
这是一个挑战,但有了正确的检测系统,您将离更清洁的世界更近一步,并且您将建造一个很酷的人工智能机器人。下载开源垃圾数据集后,您意识到您的模型存在多种挑战,并且即使您应用了最先进的模型,性能也很差。
这就是我们在这个以数据为中心的人工智能案例研究系列的第一部分中结束的地方。在上一篇文章中,我们分析了 TACO 数据集和标签,发现该数据集存在很多问题。
在以数据为中心的人工智能案例研究的第二部分中,我们将开始调试数据集并逐步提高模型的性能。
TLDR;
使用质量指标来计算流行的开源 TACO 数据集中多边形标签的对象注释质量,我们发现约 5% 的图像存在标签错误。通过修复标签错误,我们将最先进的计算机视觉模型的 mAP 与以下类别的基线相比提高了近 50%:透明塑料瓶。

为什么选择以数据为中心的人工智能?
作为机器学习工程师,了解构建人工智能模型的不同方法以及每种方法的优缺点非常重要。以数据为中心的方法强调静态机器学习模型并注重改进底层训练数据。以数据为中心的方法建议持续关注在交互过程中添加高价值的训练数据,以提高整体模型的准确性和性能。
另一方面,以模型为中心的方法基于静态数据集,重点是开发和改进机器学习模型和算法。这通常是课堂上教授和前沿研究中使用的方法。然而,在工业中,以数据为中心的方法更为普遍,它可能会推动人工智能的未来发展以及 MLOps 和主动学习等领域的成熟。

作为机器学习工程师和数据科学家,重要的是我们要考虑问题的具体要求和约束,并选择最适合手头任务的方法。在某些情况下,可以结合使用两种方法来实现最佳性能。众所周知,吴恩达(Andrew Ng)是机器学习领域的先驱,我们甚至可以称他为以数据为中心的人工智能之父(至少他是最直言不讳的粉丝)。值得研究他的工作,以更深入地了解这些方法以及如何将它们应用到实践中。如果您有兴趣,请查看 DeepLearning.AI 的不同资源。
上次我们学到了什么?
让我们首先回顾一下我们第一篇博文中在 TACO 数据集中发现的挑战:
- 类别不平衡:数据集包含很多类别(60),我们发现类别不平衡程度很高。有几个类别的标签接近 0(铝泡罩包装 6、电池 2、梳理泡罩包装 1)。
- 相似的对象类:许多对象类在语义上非常相似。
- 小物体:大多数物体都非常小,例如香烟、罐头、易拉罐。
- 标注质量低:众包数据集的标注质量比官方数据集差很多;因此,应对标签进行审查。
我们知道许多人在改进模型时在项目中面临这些常见挑战。让我们制定一个问题陈述并尝试逐步提高我们的模型性能。
问题
我们着手遵循以数据为中心的方法来提高 TACO 数据集上 Mask RCNN 模型的性能。
由于 TACO 数据集包含 60 个类,因此我们将本教程的重点缩小到一个类(并节省一些计算能力)。我们最终选择了:
透明塑料瓶:由 PET 制成的水瓶和软饮料瓶。

为什么?
嗯,它在数据集中得到了很好的体现(476 张图像中的 626 个注释),我们发现它经常与其他对象(例如其他塑料瓶和饮料罐)混淆。
此外,这是一个有趣且有用的用例,对于拥有存款返还系统(例如丹麦或瑞典系统)的国家可能具有潜在价值。
为简单起见,我们将根据三个指标来衡量性能:mAP、mAR 和我们自己的目标注释质量指标。
关于数据集
- 研究论文:TACO:用于垃圾检测的垃圾注释
- 作者:佩德罗·F·普罗恩萨 (Pedro F Proença)、佩德罗·西蒙斯 (Pedro Simões)
- 数据集大小:官方:1500 张图像,4784 个注释;非官方:3736 张图像,8419 个注释。
- 类别: 60 窝类别
- 许可证:CC BY 4.0
- 发布日期:2020 年 3 月 17 日
- 了解更多:Github 和网页
方法
为了改进机器学习模型,我们开始使用各种不同的策略:(1)重新标记不良样本,(2)修复错误标记的类,(3)标记新样本,以及(4)数据增强。
在本教程中,我们将尝试策略 (1) 和 (2),在下一个教程中我们将尝试策略 (3) 和 (4)。
每次迭代后,我们将使用改进的非官方数据集使用相同的神经网络架构重新训练模型,以比较固定官方数据集上的模型性能。
在我们开始讨论之前,让我们快速介绍一下“对象注释质量”指标:
什么是“对象注释质量”指标?
“对象注释质量”指标计算嵌入空间中最近邻居之间标签类别的偏差,以识别哪些标签可能包含错误。
从技术上讲,该度量将多边形转换为边界框,并提取每个边界框的嵌入。然后,将这些嵌入与它们的邻居进行比较。如果邻居的注释不同,则给予低分。您可以在 Encord Active 的 GitHub 存储库上找到技术实现。
太好了,让我们开始吧。
第一次迭代:修复标签错误
分析
使用对象注释质量指标,我们可以看到透明塑料瓶类与其他塑料瓶类混淆,有时甚至与饮料罐类混淆。
提示:您可以使用 "标签质量"→"探索 "选项卡对对象类的样本进行排序,并选择任何质量指标。只需选择 "对象注释质量 "指标,并按降序对样本进行排序。这将首先显示该类的正确标注样本。
让我们把这三种物体形象化,了解它们的真正含义:

它们之间的相似性似乎并不明显:然而,由于这些注释是众包的,因此注释者对于该用例可能具有不同级别的上下文,并且每个类的描述可能会引起混乱(考虑到有 60 个标签类)。
让我们深入研究 Encord Active 应用程序并打开非官方数据集。
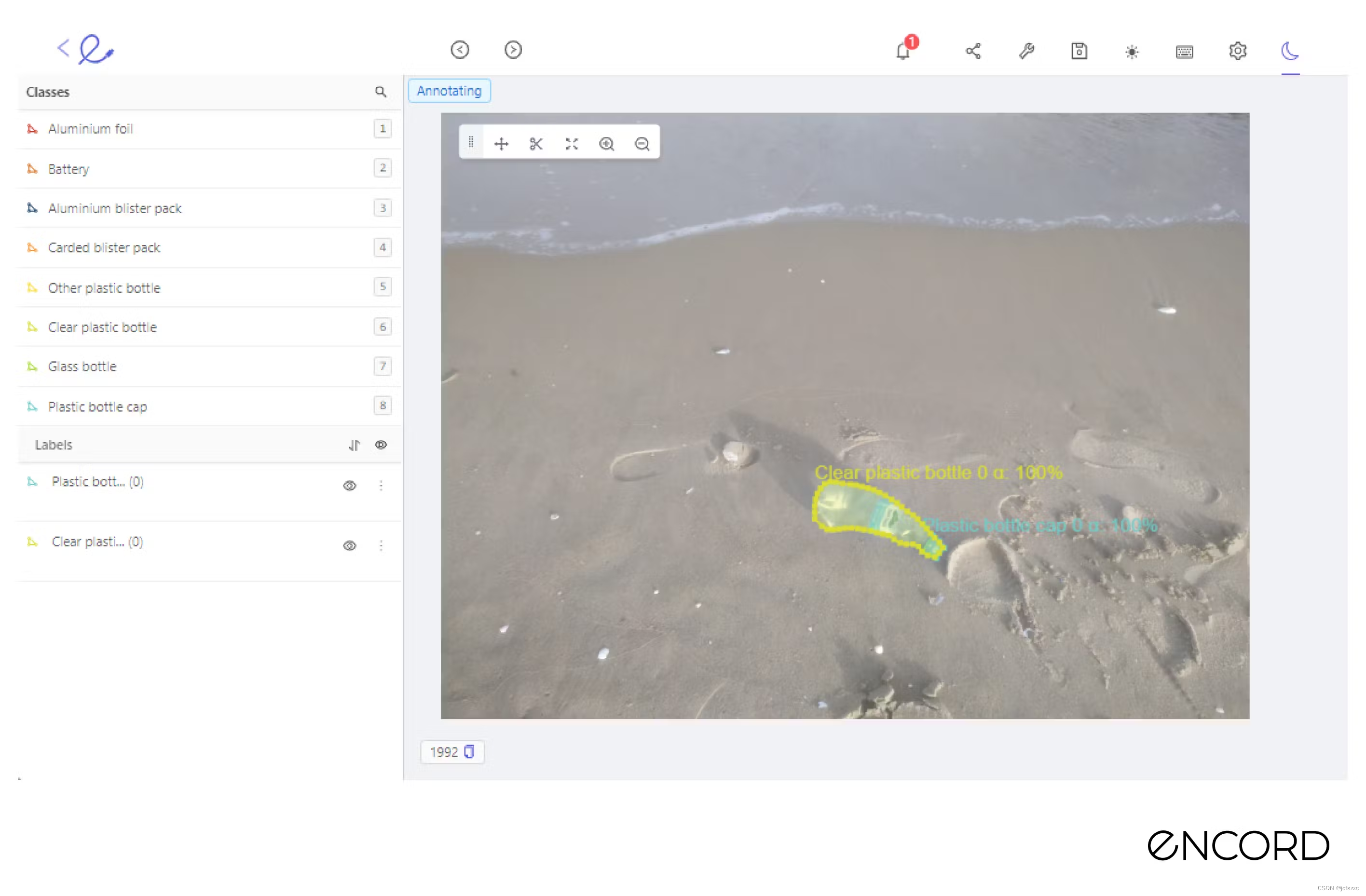
我们导航到**“标签质量”→“资源管理器”**选项卡,选择“对象注释质量”作为指标,然后选择“透明塑料瓶”作为目标类别。按升序对样本进行排序,以查看注释质量分数较低的对象。

这里有些例子:

使用 Encord Active,我们可以直接发现这些标签错误。
提示:如果您是从 Encord Annotate 帐户导入的项目,则可以直接单击每个图像下方的编辑器按钮,在 Encord Annotate 平台中将其及其注释打开,您可以在其中轻松修复注释。
重新贴标签
在第一次迭代中,我们将修复所有注释为透明塑料瓶的对象的标签。通过从低注释质量到高注释质量,我们可以首先识别质量最低的标签。
按照这种方法,我们在 1 个小时多一点的时间里为 81 张图像修复了 117 个标签。
数据标记之后,让我们回到模型训练。
模型再训练
让我们在更新的数据集上重新训练我们的机器学习模型,看看透明塑料瓶的性能是否发生变化。
现在,在项目中填写 config.ini 文件的详细信息并重新训练模型(如果您之前没有这样做,请阅读此处的第一篇博客)。
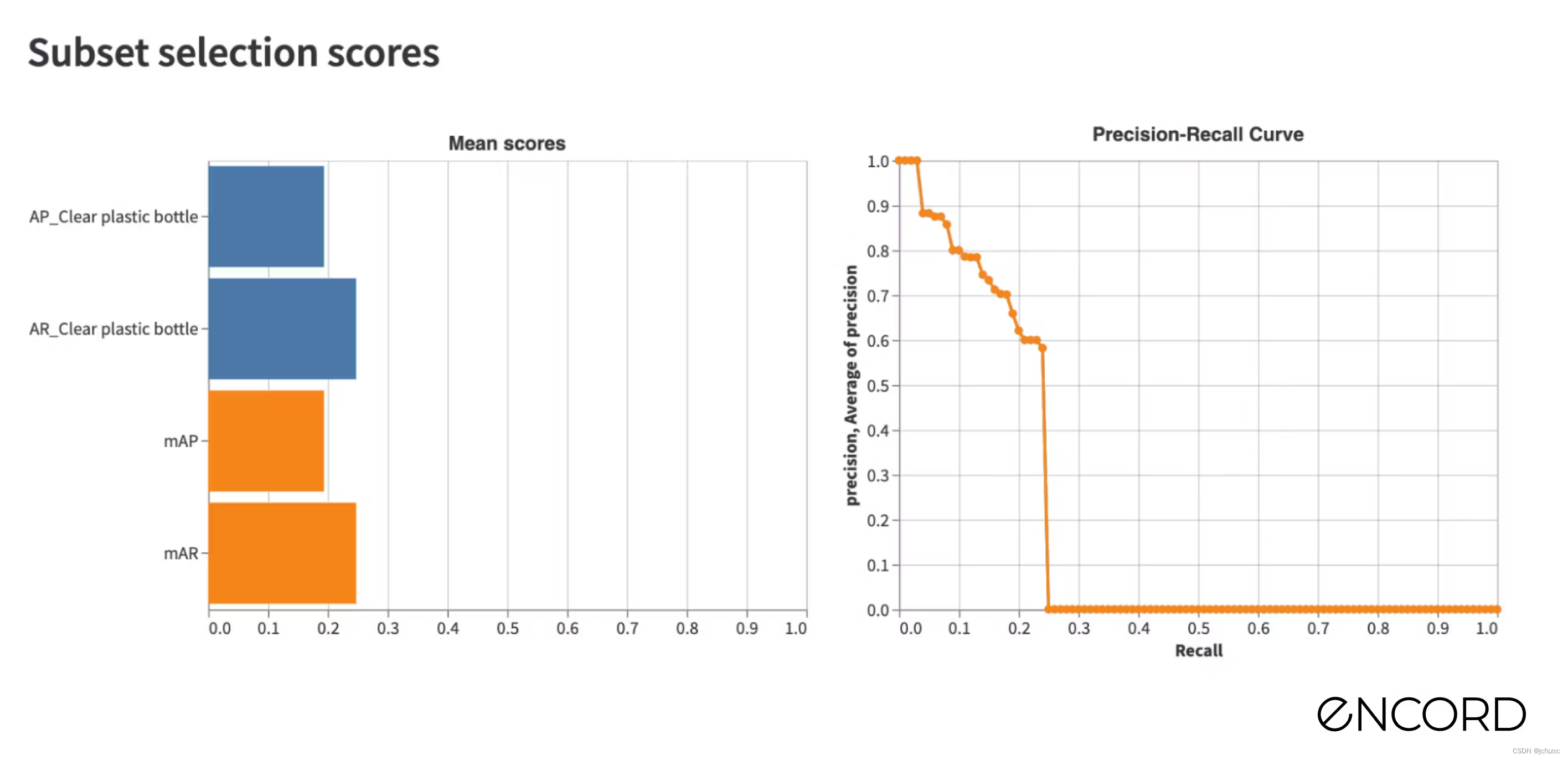
训练结束后,我们将预测导入到 Encord Active 中,就像我们在上一篇博客文章中所做的那样,并检查性能。我们可以看到对象注释质量的性能现在为 0.416。
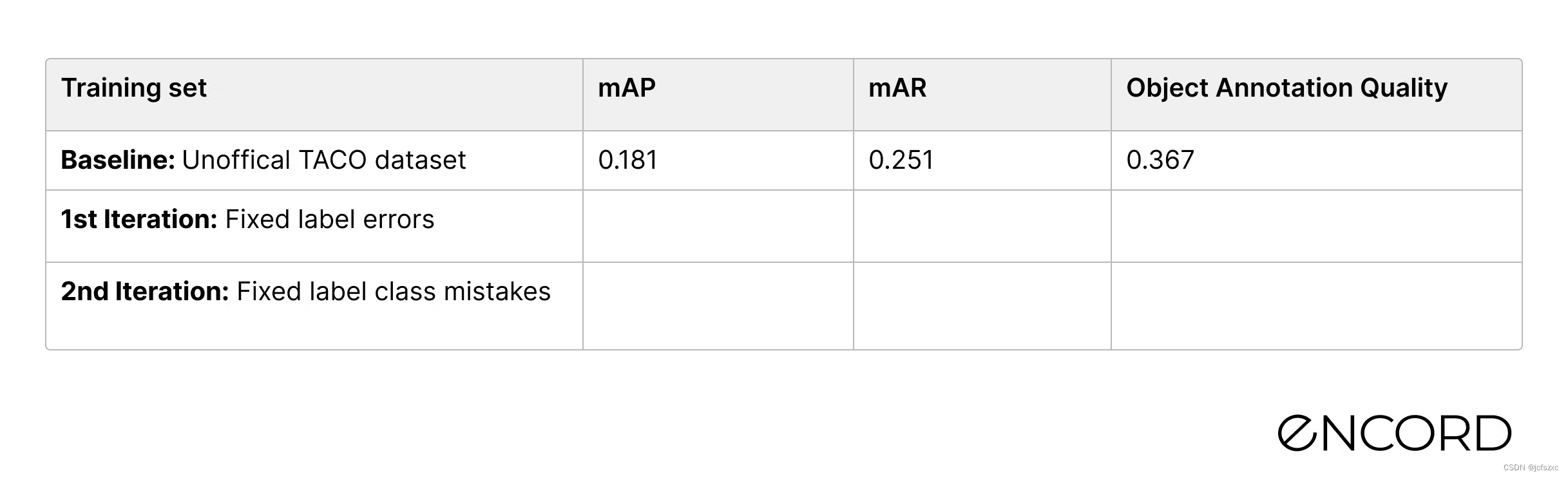
与基线相比的性能结果如下表所示。新模型的检测性能比 mAP 的基线高 7.7%,而 mAR 的检测性能略低 (-1.5%)。
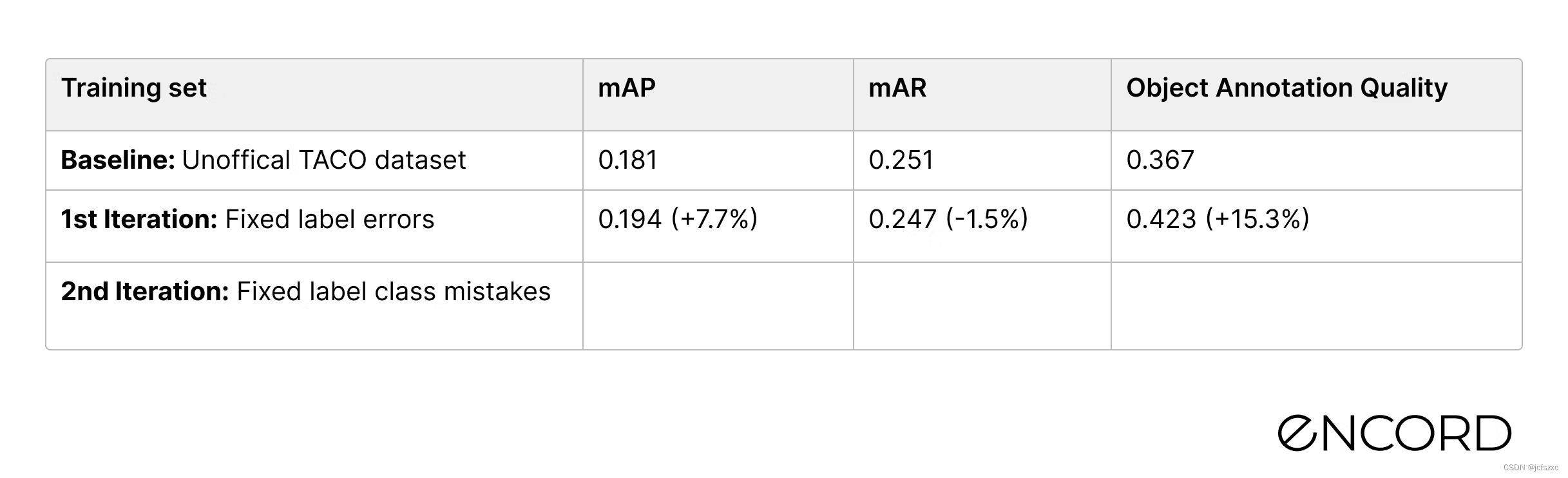
第二次迭代:修复错误标记的对象
良好的开端;但是,我们希望研究提高透明塑料瓶类模型性能的其他方法。
接下来,我们将讨论修复类标签错误。我们将首先查看其他塑料瓶物体的标签质量,以确定某些物体是否被错误地标记为透明塑料瓶。
分析
首先,我们调查一些注释错误的其他塑料瓶标签。

我们看到许多标签实际上属于透明塑料瓶类别,但被标记为其他塑料瓶。
因此,让我们重新标记其他塑料瓶的错误分类图像,就像我们之前所做的那样。
重新贴标签

1.5 小时后,现在已经重新标记了近 100 张图像中的 150 个标签(98…)。数据标记既耗时又乏味,但让我们看看它作为一种以数据为中心的方法来提高模型性能有多么强大。
模型再训练
我们将该数据集命名为 Unofficial-v3 并训练一个新的机器学习模型。训练完成后,我们导入官方数据集的预测,打开应用程序并检查对象注释质量的性能现在为 0.466。
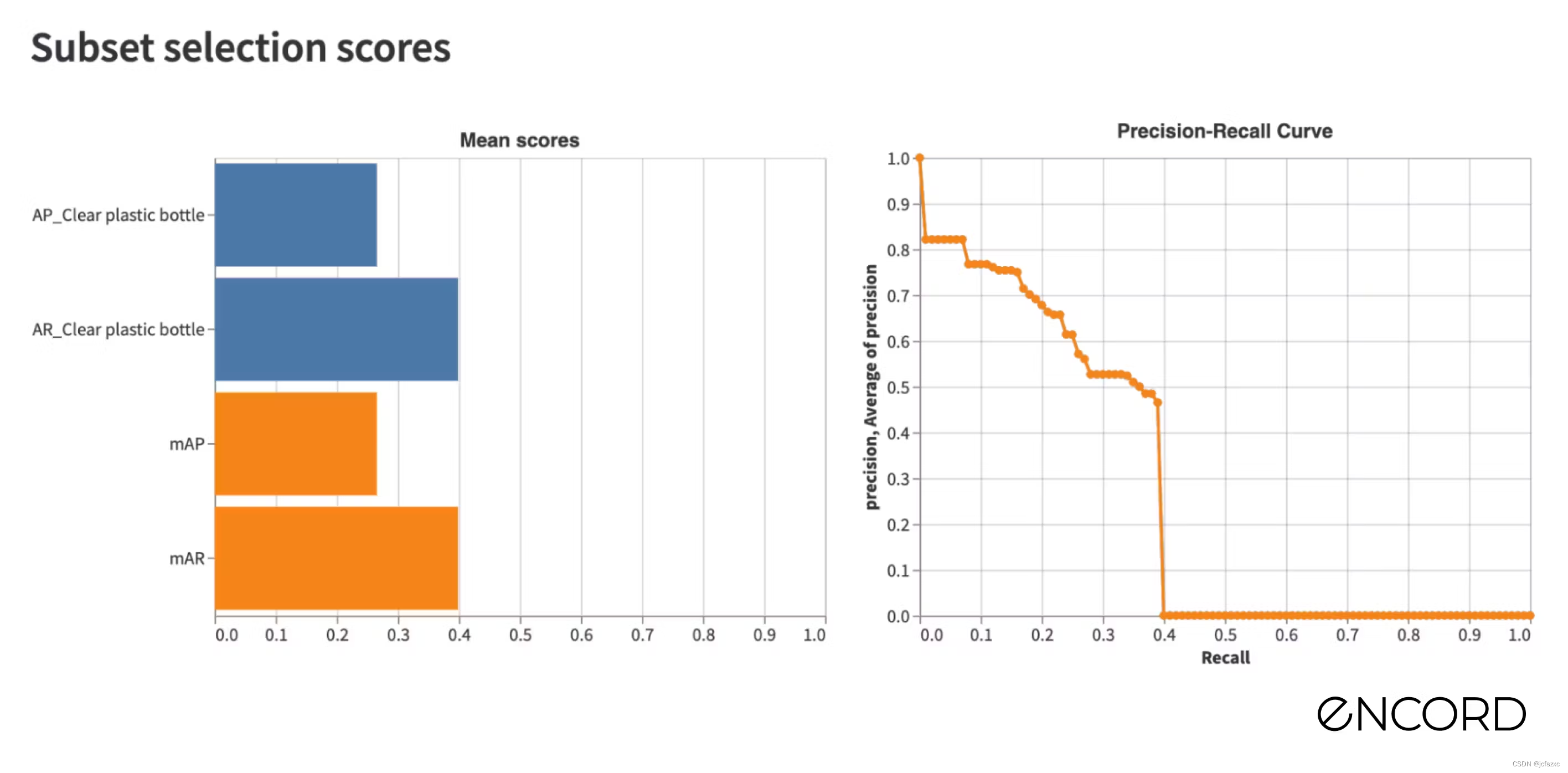
多么大的进步啊!
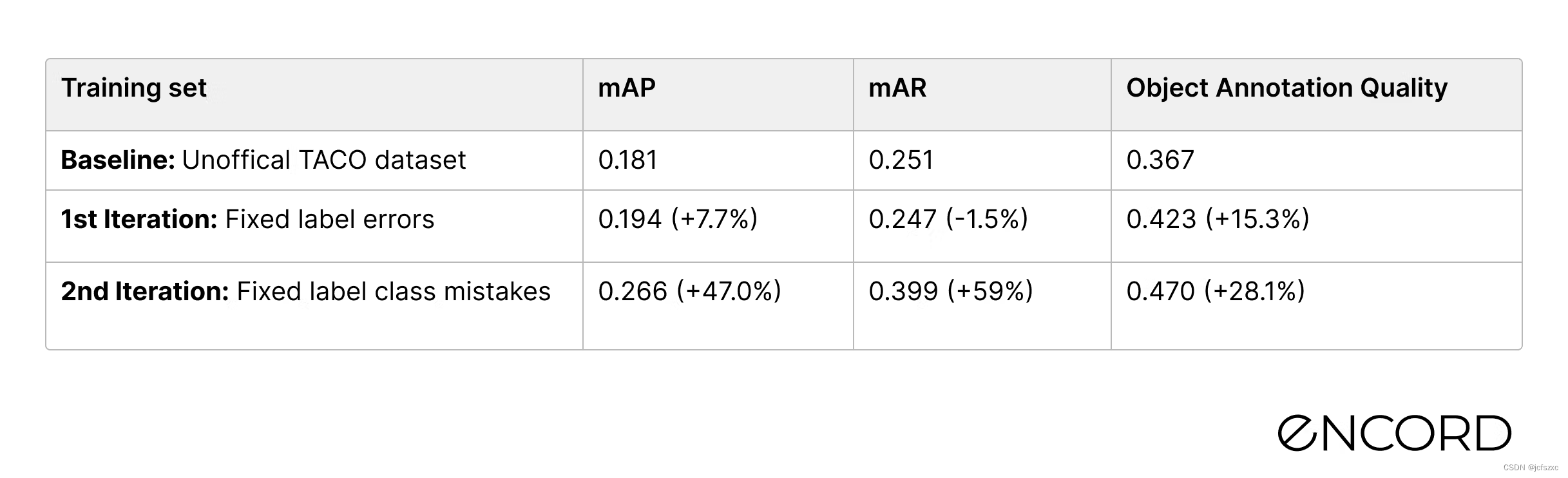
通过修复错误标记的其他塑料瓶对象,我们将 Mask-RCNN 机器学习模型的 mAP 分数性能提高了 40%。如果我们选择以模型为中心的人工智能方法并简单地尝试微调模型,那么这种性能提升几乎是不可能的。与基线相比,我们的性能提高了近 50%!
在这项工作中,我们只专注于提高单个班级的表现;但如果我们对其他班级做同样的工作,也可以取得类似的结果。
结论
在以数据为中心的人工智能案例研究系列的第二部分中,我们的目标是提高特定类别的垃圾检测模型的性能。为此,我们利用开源主动学习工具 Encord Active,利用简单的数据驱动工作流程。使用该工具,我们:
- 发现并修复不良标签以优化我们的模型性能,从而提高透明塑料瓶类别的准确性。
- 发现并修复了被错误分类的对象并修复了标签。
在两个迭代周期结束时,我们将目标类的 mAP 比基线提高了 47%。
在以数据为中心的人工智能案例研究系列的最后一篇文章中,我们将展示如何通过定位标记工作和增强当前图像来提高基于类的模型性能。