摘要:本文整理自蚂蚁集团高级技术专家赵亮星云,在 Flink Forward Asia 2023 AI 特征工程专场的分享。本篇内容主要分为以下四部分:
- 蚂蚁特征平台
- 特征实时计算
- 特征 Serving
- 特征仿真回溯
一、蚂蚁特征平台

蚂蚁特征平台是一个多计算模式融合的高性能 AI 数据处理框架,能够满足 AI 训练和推理场景对特征低延迟产出、高并发访问以及在离线一致等方面的诉求。
蚂蚁建设特征平台的核心目的,是让算法同学在数据供给侧能够自给自足,即 data-self-sufficient。具体是希望算法同学通过平台以低代码的方式进行特征研发、测试、发布、上线,整个流程不需要专门数据工程团队支持对接。
特征上线以后,背后对应的高性能实时特征生产任务、高性能查询服务以及特征在 “离线” 和 ”在线” 两个世界保持数据一致性等功能由特征平台自动提供,对用户透明。
特征平台从 2017 年开始建设,基于风控领域的积累和数据经验把风控的核心数据产品抽出来,组建为特征平台。这套特征平台较好地服务了蚂蚁风控的业务。在 19 年到 20 年期间,平台向全站算法业务推广的过程十分困难。核心原因是基于风控建设的特征平台包含非常多风控业务语义,它的计算范式是面向风控场景特别定制的,包括计算 DAG、数据精度、算子类型等都是针对风控领域优化设计的,所以向全站推广的过程中显得难以适配。因此从 20 年开始,蚂蚁特征平台进行了彻底的重构。
截止目前,蚂蚁特征平台已经服务了蚂蚁包括搜推,微贷,国际风控,网商,财富保险,芝麻等主要业务方。特征规模 10 万+,在线 Serving 的 QPS 两百万,日常的计算 TPS 100 万左右。

想一套特征平台满足全站特征业务诉求,平台应该具备的核心能力有以下 4 方面:
-
快速实现任意计算范式的能力:
首要诉求是算法同学面对异构场景、差异需求能够快速以配置化方式将实时特征上线。所以特征平台不能和某种固定计算范式绑定,需要具备快速实现任意灵活计算范式的能力。
-
特征大规模仿真回溯的能力:
模型训练的第一个阶段是样本准备。如果算法同学想训练一个模型,选好了一批实时特征,而这些实时特征还没上线,意味着它没快照,构建不出来样本。因此对于这批新定义且未上线的实时特征,特征平台需要快速计算出它们在历史时刻面对历史查询请求的“瞬时值”,即特征平台能够针对历史样本对新增未上线特征进行特征补全。这就需要特征平台具备大规模特征仿真回溯的能力,对平台提出了流批一致性的能力要求。
-
实时特征冷启动的能力:
试想某个模型里用了很多实时特征,这些实时特征又是窗口特征,如果等实时特征上线、窗口累计完整后再提供 Serving 服务,模型迭代效率非常低。这就要求实时特征一旦定义好,要快速补全特征窗口值,进而让特征尽快开始提供线上 Serving 服务,这就需要特征平台具备实时数据冷启动的能力。
-
高性能特征 Serving 的能力:
模型上线后,要提供一个高性能的模型推理服务,依赖的数据输入必须是高性能的。因为在模型服务的过程中,性能瓶颈点一般在数据 IO 阶段,为了让模型服务更高效、更准确,必须要提供一套高性能、低延迟的特征在线查询服务。这就需要特征平台具备高性能特征 Serving 的能力。
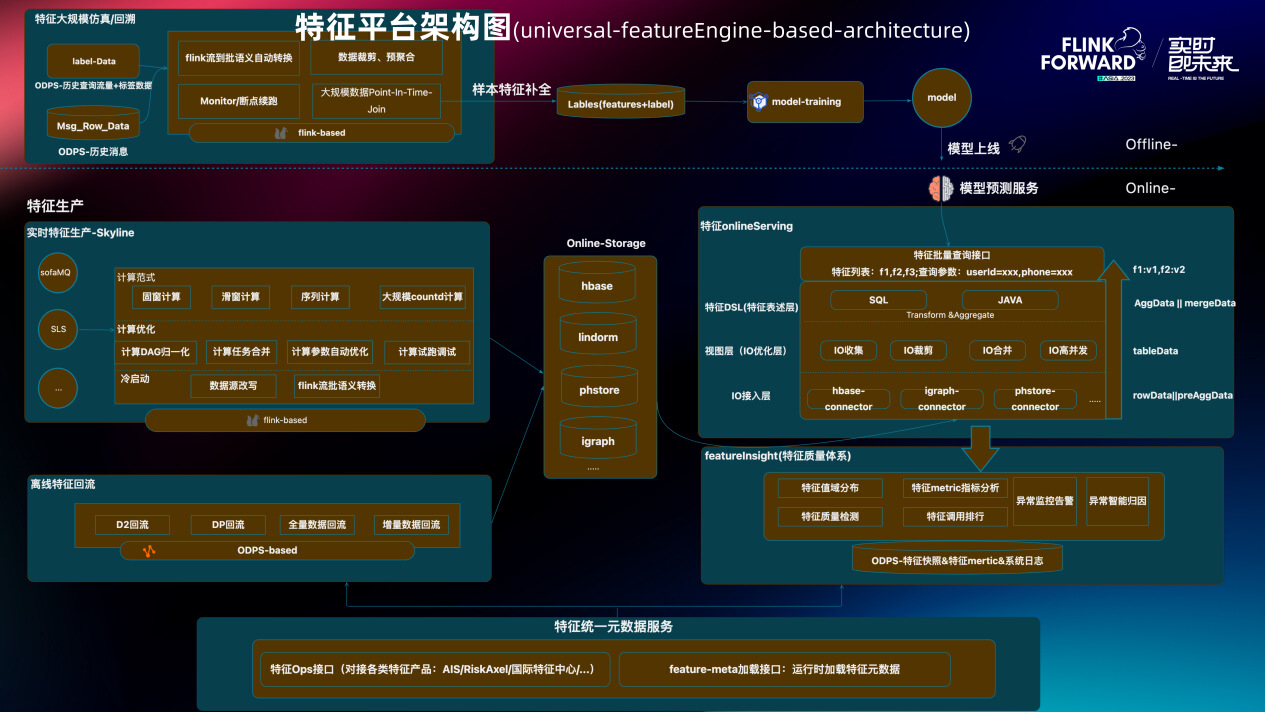
根据四个必须具备的核心能力提出蚂蚁新一代的特征平台架构 UFE(universal-featureEngine-based-architecture),这个架构横跨离线和在线两个数据世界。离线部分是一套用于特征大规模仿真回溯的系统。在线部分用存储把 “写” 和 “读” 两侧分开:“写” 是基于Flink打造的一套实时数据生产系统。这套实时生产系统跟大规模仿真系统合起来的叫做 Skyline。“读” 是一套基于自研高性能 SQL 引擎实现的高性能特征查询服务。其主要目的是给模型推理服务提供高效的特征批量查询服务,即如何把一批特征在尽量短的延迟内返回给模型服务。
Serving 服务下面有一套用于特征质量监控的 feature insight 体系。它可以实时监控特征的调用情况、耗时情况,也可以分析特征的内容分布。如果内容分布产生了急剧的变化则会产生警告。
架构最下面是特征统一元数据服务,这份服务的存在其实是很有意义的。把 feature-devops 的操作,包括特征研发、定义、发布、验证,推送上线等全部抽象为接口。“特征平台管理时” 是基于这套接口实现的,如果有外部的大业务方想基于特征平台的核心数据能力去构建自己的平台产品,也可以对接这套接口。在蚂蚁运行的特征看似来源于不同的配置平台,其实进到特征平台内部元数据是统一的。元数据统一有一个极大的好处是无论生产侧还是消费侧特征平台做的任何技术优化,对全局都是统一生效的。在蚂蚁内部这套特征元数据系统已经对接了非常多的平台,而 “特征平台管理时”,就像一套精装公寓,如果没有特殊需求可以领包入住。如果资源特别充裕且个性化定制诉求非常多,那可以基于特征平台的数据技术自己盖房子。
二、特征实时计算
2.1 特征实时计算的挑战
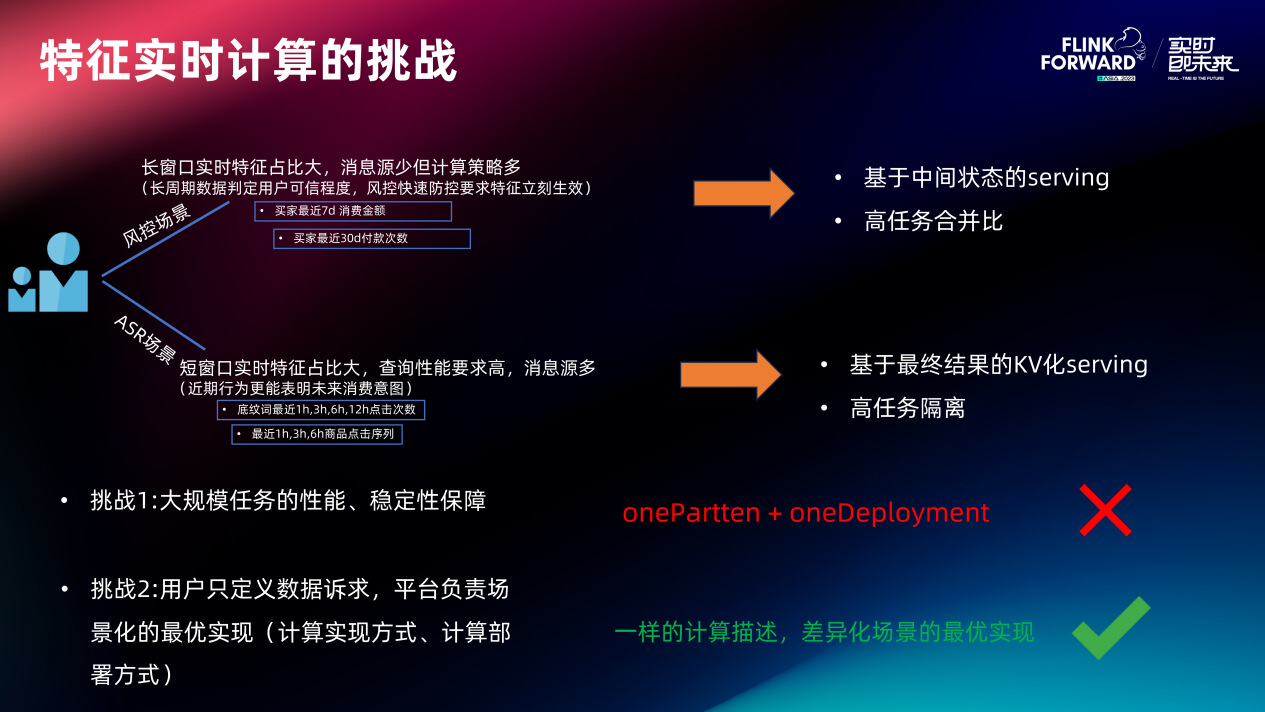
特征实时计算面临的第一个挑战是性能上的挑战。在蚂蚁,动辄就会遇到一个计算任务要面临大几十万甚至上百万的 TPS 的情况。如何让这种超大规模的计算任务能够有低延迟稳定的输出?这是一个巨大的挑战。
第二个挑战是希望用户在平台上只定义数据诉求,而不需要关心数据的具体是怎么实现的。但相同的数据诉求在不同的场景下其最优的实现路径可能完全不同(因为不同场景的资源情况、数据精度、延迟时长、数据查询性能等要求都不同)。如何用一套实时特征生产系统满足差异化场景下最优计算路径的快速适配?这是另一个挑战。
举 2 个场景的区别来说明这个问题:
-
风控场景
风控场景下长窗口特征占比非常高。例如 “用户 90 天内的实时交易次数”、“用户 90 天内日平均转账次数” 等等。长窗口的特征占比大是因为风控领域长窗口数据更能综合判定用户的可信度,且风控业务经常用长窗口数据和近期数据做比较来判别行为突变。再者风控需要快攻快防,一旦发现风险要立即改变数据口径且立即生效。基于这两个特性,在风控不太适合把这类特征数据在计算侧直接算成最终结果来提供 Serving(虽然这样的对 Serving 性能是最好的)。因为首先超长窗口的实时计算现在还没有引擎能够将 State 全部放到计算引擎内部,其次面对快攻快防需要灵活调整数据口径的诉求,完全预计算好的 KV 结果无法做任何程度的数据复用,一旦计算口径发生改变,之前所有计算好的数据全部都无效了。因此在风控场景比较适合基于明细或者中间状态的 Serving,也就是说在计算侧,把明细或小时账、天账算出来存到存储里面去,特征 Serving 时临时从存储里把这些账拿出来做聚合。
-
搜索场景
在搜索场景短窗口实时特征占比非常大。因为一般认为用户近期的行为表现更能体现接下来的消费意图。但搜推场景对特征查询性能要求非常高。例如一次查询 100 个特征,平均 RT 要在 10 毫秒以内,且长尾毛刺不能高于 80 毫秒(P99.99 的 RT<80ms)。要达到这种诉求,需要尽量把结果在计算侧直接算出来,然后把它以 KV 化结构存到存储里供 Serving 使用。
两种场景的比较意味着看似差不多的实时特征诉求,其实在不一样的场景下最优实现路径是不一样的。也就意味着没有办法用一种计算范式和一种计算的部署模式去服务全部业务。因此对特征平台提出一个要求,即平台能够灵活将用户的数据诉求以场景化最优路径来实现。
2.2 特征计算框架 skyline 架构
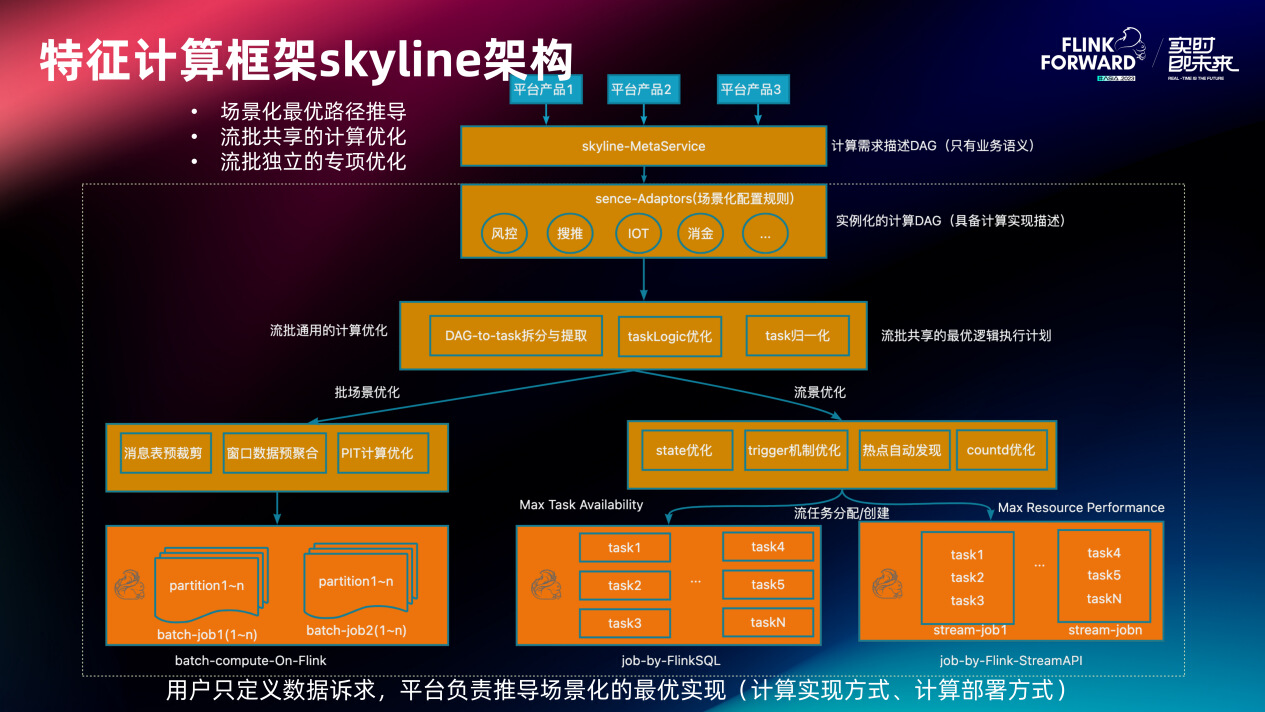
基于这样的考虑,提出了 Skyline 计算架构。Skyline 通过元数据服务接收来自各平台产品的实时特征的定义(定义过程是面向计算需求的 DAG)。这个 DAG 会传到场景化定制的 adaptor 层,被实例化为具体应该在这个场景最优化的计算方式。例如同样 “求七天内的复登录次数” 到底是应该直接算出 KV 化的结果,还是在计算侧算一些账存到存储中在特征查询时候临时聚合呢?这个问题在这一层会确定。之后实例化的计算 DAG 会被流批通用的计算优化模块进行 DAG 到 Task 的拆分,然后对这些 Task 会做一些逻辑优化(filter 上推、列裁剪等)和计算 DAG 归一化,其结果可以被流场景跟批场景识别逻辑执行计划。这个逻辑执行计划在批场景和流场景会各自应用各自的独立专项优化,进而上线部署。
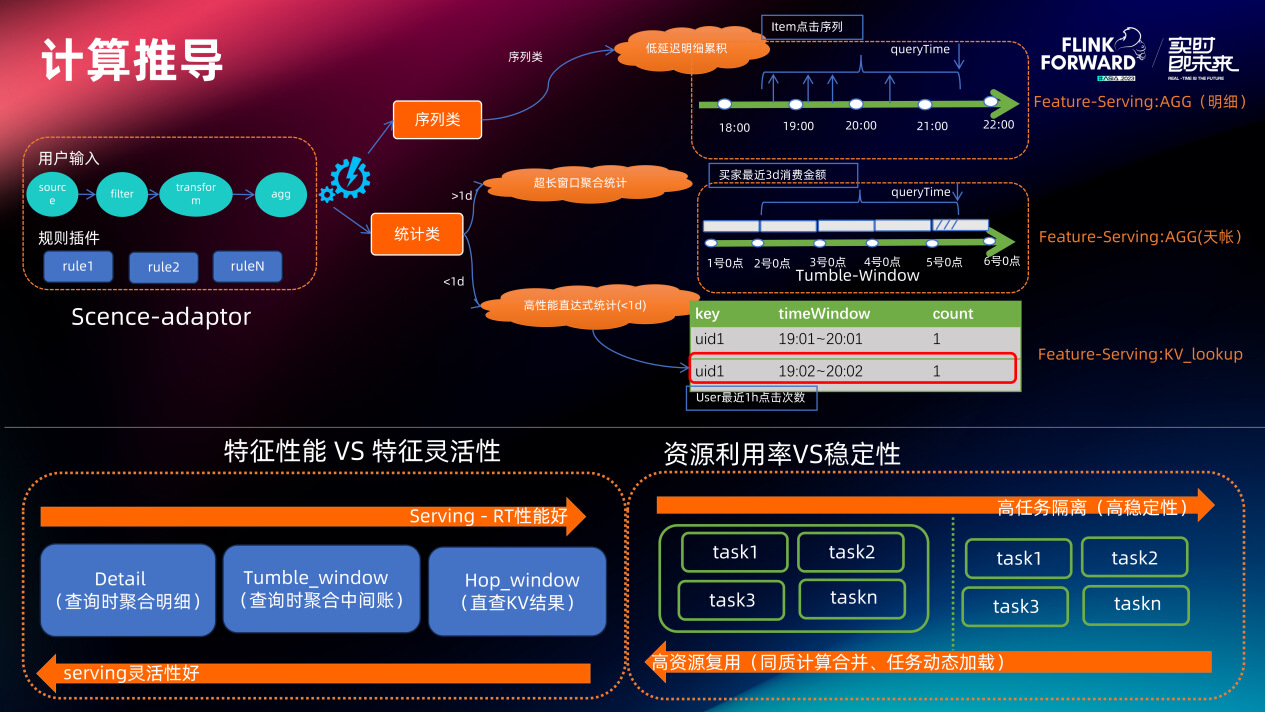
这里面有 3 个关键阶段:计算推导、计算归一化、计算部署。
首先场景定制的规则插件会将计算描述 DAG 根据 AGG 算子类型和时间窗口长度实例化成不同的计算 Task,例如小于 1 天的 sum 直接使用 hopWindow 实现,大于 1 天的 sum 使用 tumbleWindow 计算天账(特征 Serving 时候查询多天的天账去二次聚合)。
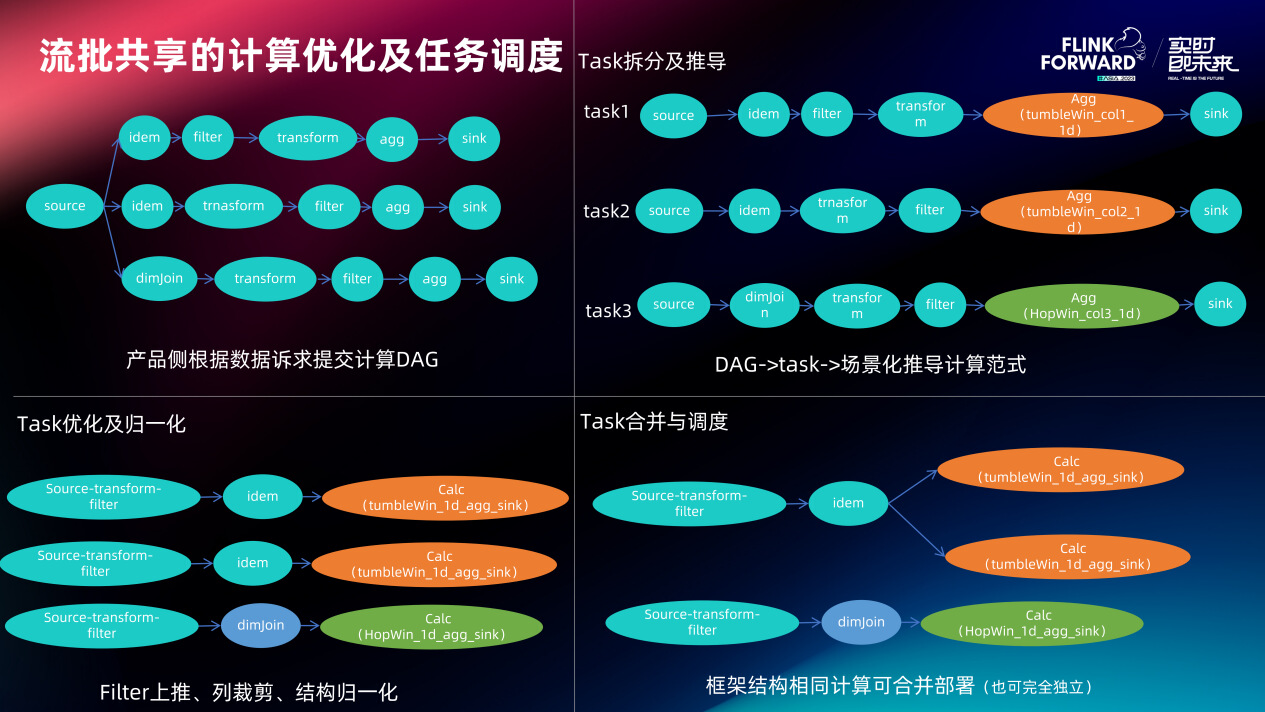
接下来 Skyline 对计算 Task 进行 filter 上推、列裁剪、归一化(节点顺序调整和链接压缩)进而形成由核心“骨架节点”组成的逻辑执行计划。最后是计算部署,如果该场景要求绝对的任务隔离、追求不同计算之间不会相互影响,则归一化后的逻辑执行计划会被转化成 Flink SQL 任务直接运行。如果计算资源紧张、追求最大集群资源利用率,则 Skyline 会在全局计算元数据中进行查找匹配,判断现在集群里面有没有相同骨架结构的物理任务,如果有 Task 会被合并到已有物理任务,如果没有则新建一个物理任务(此类物理任务是用 stream API 写的,可不重启直接动态加载计算策略)。
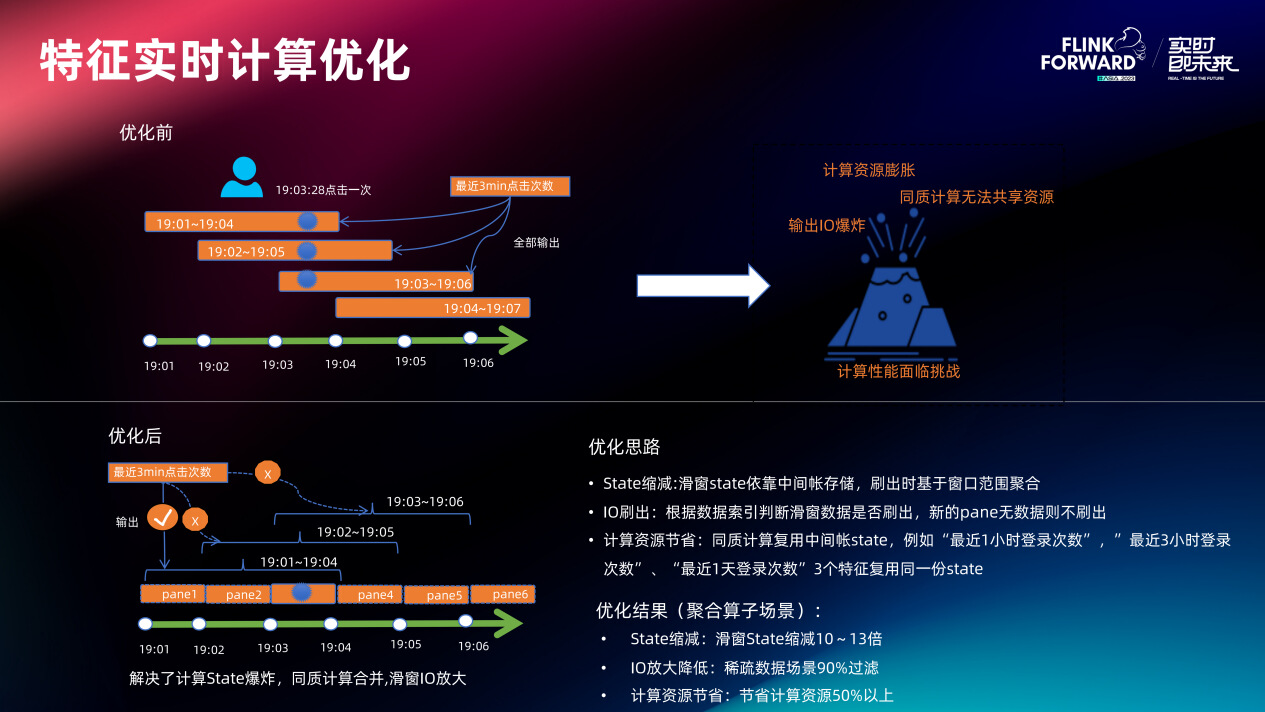
在 Flink 里面最直接的优化是尽可能缩减 Flink 的 State 的大小,State 越小任务稳定性越好,从而能够让实时计算任务在超大流量规模下做到低延迟数据产出。蚂蚁有非常多的 “同质滑窗特征”:“滑窗特征” 即从现在到 N 久前的某种行为的聚合值,“同质” 即数据计算逻辑都一样,只是最后查询的窗口长度不一样。如果这种滑窗场景用 Flink 原生的 hopWindow 实现,计算资源一定会无限膨胀且结果数据刷存在 IO 爆炸风险。因此对 hopWindow 的 State 进行了 “滑窗转固窗” 的重构,数据到来会根据 eventTime 把它放到 merge 到固窗的 pane 里面(pane 的长度为滑窗 slide 长度),在窗口刷出时根据 pane 里的数据做二次聚合输出。这样极大的缩减了滑窗计算任务的 State,且同质计算完全可以基于这同一份 State 进行。同时更改了原始滑窗数据刷出机制,前后 2 个滑窗如果被判定数据完全一致,则不会刷出后一个窗口数据(因为 Serving 的时候都是查最新窗口的数据,如果后面窗口数据无变化则没有必要刷出)。
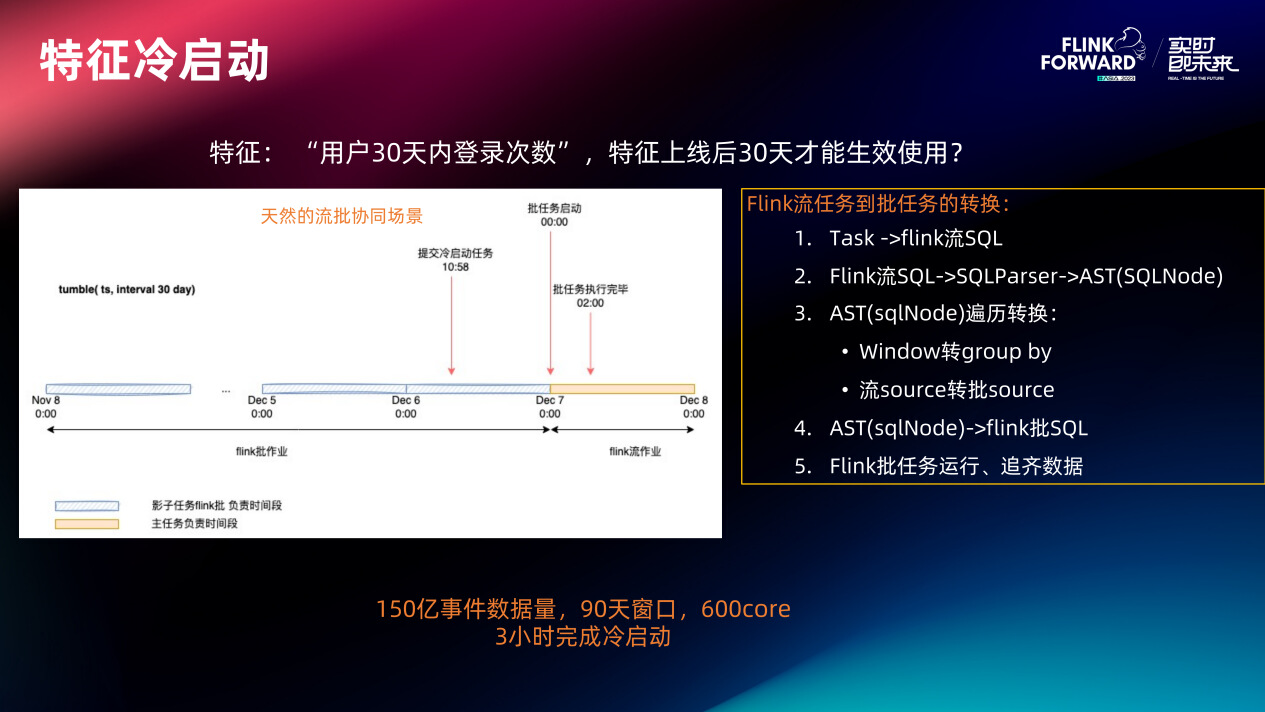
特征冷启动主要利用了 Flink 天然的流批一致特性。将实时特征生产逻辑转化为等价的 Flink 批 SQL,在线上的实时任务提交之前先将 Flink 批 SQL 任务提交运行进行历史数据补齐。之后把流任务从零点开始重置,这样的流批两边的数据就可以拼接上。
三、特征 Serving
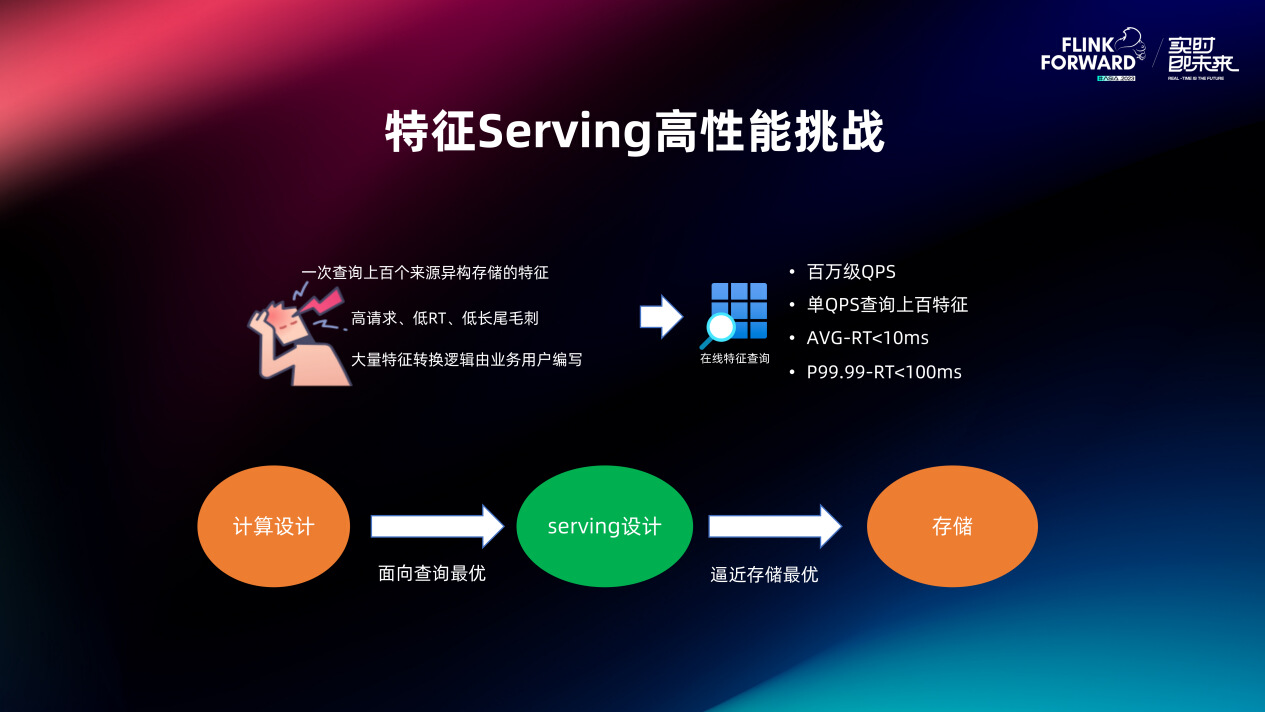
特征 Serving 的作用是给在线模型推理提供特征查询服务。实际场景中上层业务对特征查询性能要求非常严苛:一次查询请求包含上百个特征(由于数据链路的复杂性这些特征对应的数据可能分散在不同存储中),平均 RT 要求小于 10ms,P99.99<100ms。做到高请求、高并发情况下的低 RT 低长尾毛刺是 UFE-serving 服务的核心意义所在。

UFE-serving 由三层构成:
-
表述层
最上层是特征的表述层,现在主推的特征表述是 SQL,即用户通过写 SQL 的方式来定义数据从存储查询出后临时转换和二次加工的过程。
用 SQL 有三个好处:
-
SQL 作为通用数据描述 DSL 没有学习成本。
-
数据 Serving 的描述用 SQL 定义,计算的描述也用 SQL 定义,意味着面对同一个实时特征可以根据实际场景灵活的做计算和查询的推导和拆分。
-
优化全局生效:由于特征都是用 SQL 描述的,对 SQL 引擎做的任意优化都会立刻应用到全局的特征执行过程中。
-
-
IO 优化层
IO 优化层屏蔽了底层异构存储,将存储都抽象为视图的概念(SQL 中涉及到的表是 UFE 的视图),特征 Serving 引擎在一次特征批量查询过程会进行跨 SQL 的 IO 提取、合并及并发优化。
-
IO 实例层
最下面是 IO 实例层,用于对接任意存储。新的存储出现,只要基于 UFE 公布的 connector 接口实现一个 connector 实例,就可以把其纳入到 Serving 体系里面来。
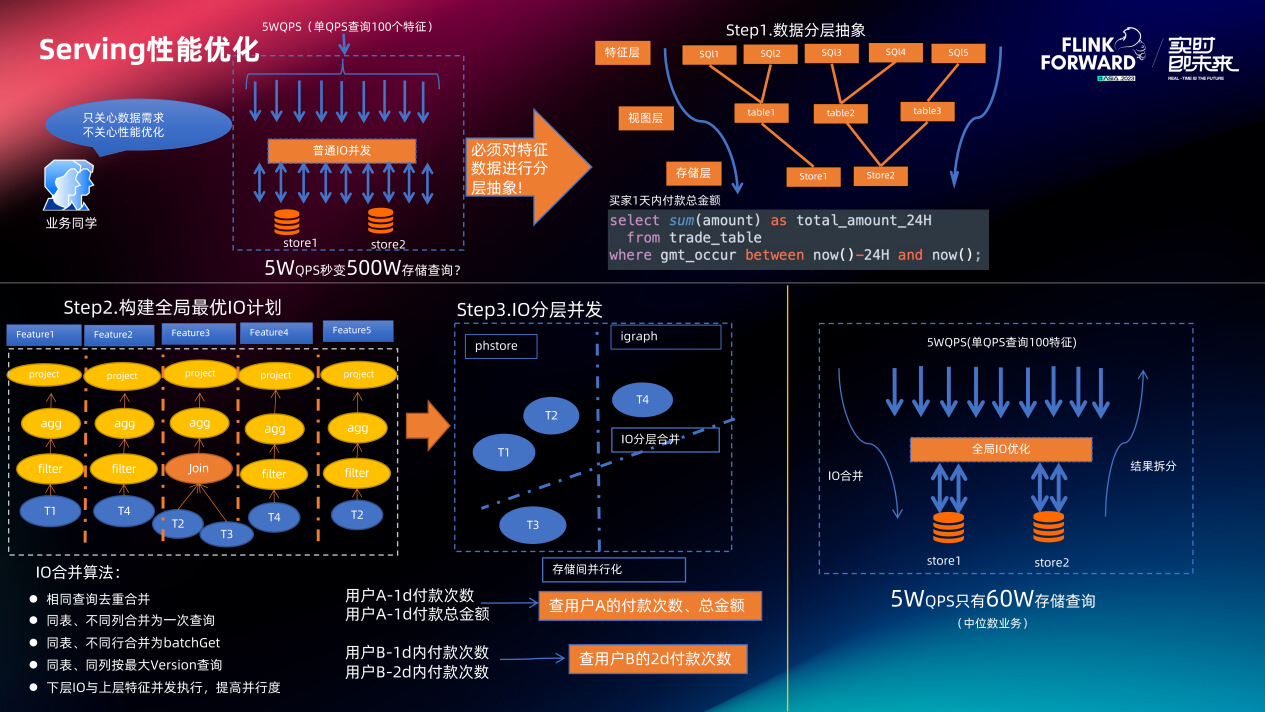
具体一次特征批量查询的 IO 优化过程如下。
首先对数据进行分层抽象,例如用户定义如下特征 SQL:
select sum(amount) as total amount_24H
from trade_table
where gmt_occur between now()-24H and now();
SQL 中的 trade_table 就是定义的视图,一个存储会产生不同的视图,同一个视图又会产生不同的特征。ufeServing 引擎会对一次批量特征查询涉及到的全部特征 SQL 构建全局最优 IO 计划。构建过程是遍历全部 SQL 收集列、窗口及视图信息,对这些 IO 信息执行 “IO 分类合并” 算法。算法思想很简单,首先根据视图存储类型进行 IO 分类,对于同一类 IO 将同行不同列及同表不同行的数据合并到一次 IO,同时基于 SQL 收集到的有效列、窗口范围等信息缩减单次 IO 的 scan 范围。总的来说,一方面减少单次 Serving 过程中查询引擎与存储的交互次数,一方面减少数据 scan 的范围,不同存储并发查询后引擎会将结果拆分到不同特征。
通过 IO 合并优化和特征 Serving 引擎内置的热点自动发现、并发精准超时控制等技术,在特征查询侧的长尾毛刺率能控在四个九以上,而且平均 RT 是非常低的。
四、特征仿真回溯
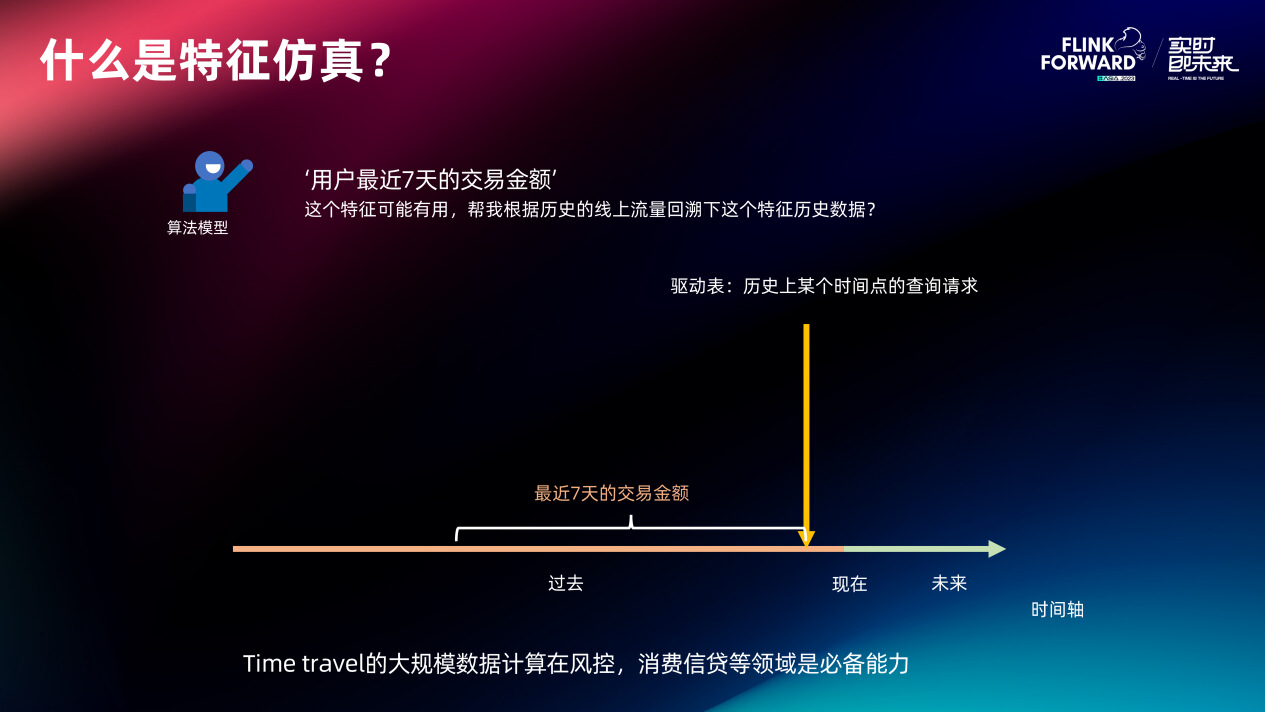
实时特征的值随着时间轴的推移一直在变化,在线如此、离线也如此,特征仿真就是要根据历史驱动表(历史特征查询流量)和历史消息表(例如历史交易事件)算出某个特征在全部历史时刻的瞬时值。这种 Time travel 计算在风控和消费信贷场景属于核心的必备能力,因为这些场景进行策略调整或新模型的迭代时需要充分评估新特征可能对线上交易造成的影响,因此他们需要仿真的样本量很多都跨半年以上。

如果用户自己在数仓里面写 SQL,如果数据量小的话可以算出来。但当驱动表扩张到百亿级别的时候,没有任何一种计算引擎的原生计算方式能够在短时间内完成这种计算,因为这会涉及到大量的数据 shuffle 和数据 join,数据膨胀相当严重。

特征仿真的核心挑战:大数据量在 PIT 语义下计算的性能和稳定性。首先要让这种计算能算得动,其次要有稳定的输出。
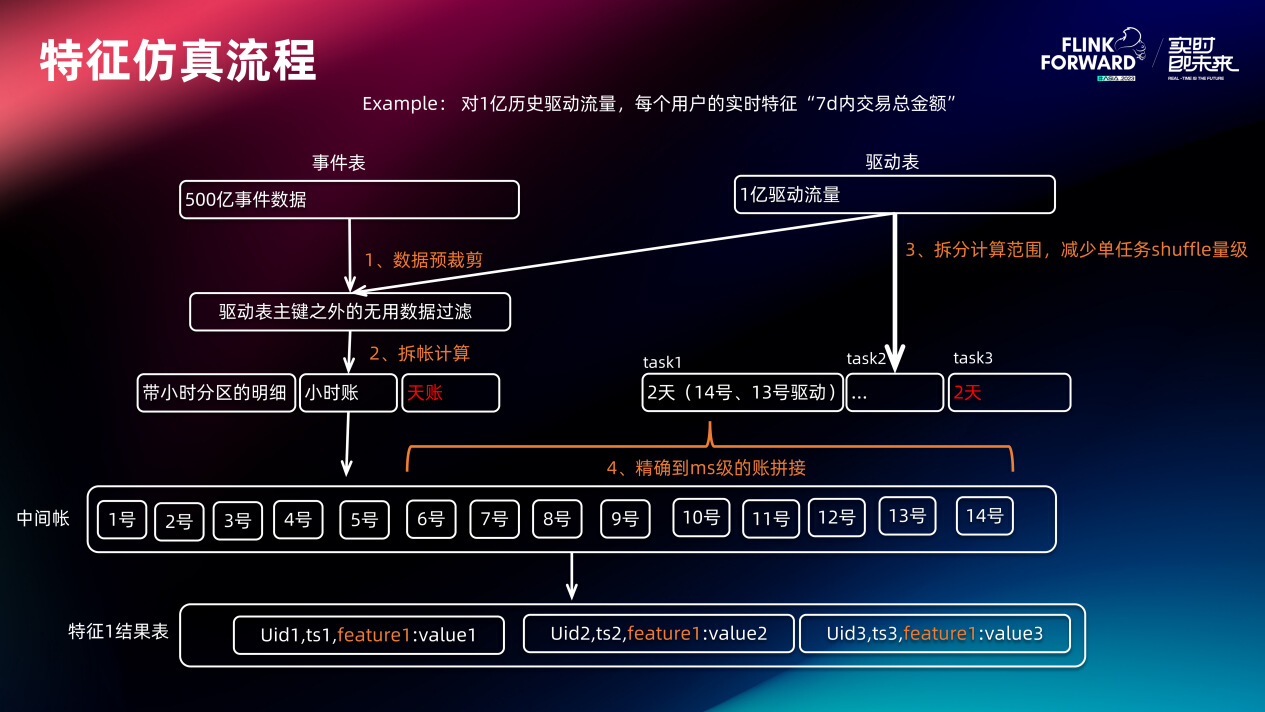
这个流程图讲了特征仿真的核心流程。首先根据驱动表、特征逻辑、及事件表进行数据预裁剪(剔除事件表中不可能被用到的事件,因为没有查询流量查它)。数据裁剪后进行拆账计算,将明细数据计算成小时账、天账,并且对明细加时间分区(主要用于后面的数据裁剪)。同时对驱动表按时间片拆分,接下来用驱动表再加上拆出来的账做二次聚合加工,把最终特征算出来。
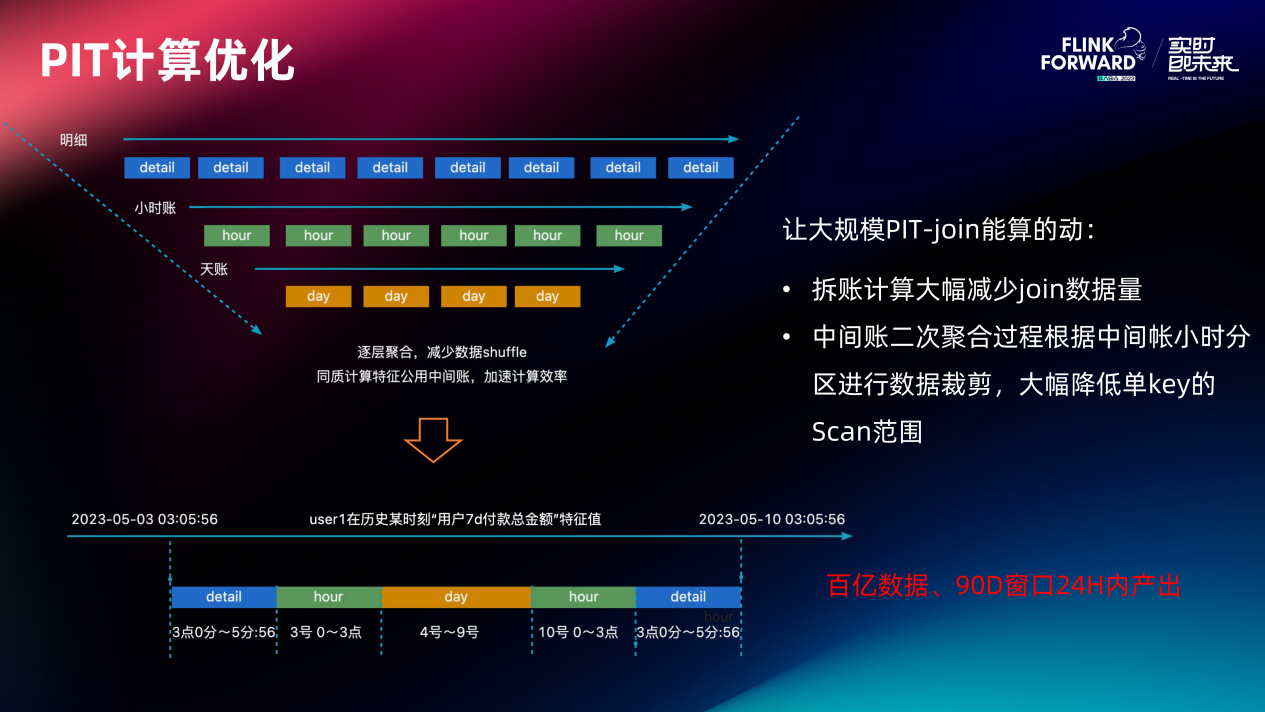
二次聚合过程:首先算出驱动流量对于该特征的窗口开始和结束时间。然后根据计算出的窗口信息到将日账、两端的小时账拼过来,最后会将小时账两端的明细拼进来(因为仿真计算的数据产出精度跟在线保持一致,也是毫秒级的)。这时候再拼明细,比用户原生写的 join 方式的性能高很多。因为明细在上面数据处理的过程中,其实已经携带了时间分区了。在具体找明细的过程中,特征引擎会根据他所属的小时分区天分区对数据进行大量的裁剪。经过拆账优化和二次聚合,特征平台就能支持这样的大规模 PIT 计算了。大概百亿的数据量、90 天的窗口,特征平台能保证一个特征在 24 小时之内产出。
)]
二次聚合过程:首先算出驱动流量对于该特征的窗口开始和结束时间。然后根据计算出的窗口信息到将日账、两端的小时账拼过来,最后会将小时账两端的明细拼进来(因为仿真计算的数据产出精度跟在线保持一致,也是毫秒级的)。这时候再拼明细,比用户原生写的 join 方式的性能高很多。因为明细在上面数据处理的过程中,其实已经携带了时间分区了。在具体找明细的过程中,特征引擎会根据他所属的小时分区天分区对数据进行大量的裁剪。经过拆账优化和二次聚合,特征平台就能支持这样的大规模 PIT 计算了。大概百亿的数据量、90 天的窗口,特征平台能保证一个特征在 24 小时之内产出。