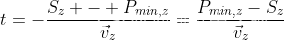综述
最近在进行车牌识别的开发,在数据收集阶段除了那些特定的数据集(开源数据集),还需要自己收集一些数据,这些数据主要来自如爬虫、行车记录视频、非特定数据集,而在这些数据集中,只有少量的数据是我们需要的,大多数数据对于开发来说是无用的。所以,如何从这些数据中筛选出对我们有用的数据则是数据收集工作的重点,手动筛选可以作为一种筛选方式,但对于大量数据来说,却是最笨最费时的方式。这时便可以想到如何通过写代码的方式来自动化实现这个筛选过程。
在此做一个记录,下面进入正题。
准备工作
算法准备
要实现依靠代码的筛选,就必须要找到一套现成可用的车牌识别算法,只需编写少量代码便可调用使用。我们这里主要用到的是HyperLPR 高性能开源中文车牌识别框架。
依赖环境
python 3
Keras (>2.0.0)
Theano(>0.9) or Tensorflow(>1.1.x)
Numpy (>1.10)
Scipy (0.19.1)
OpenCV(>3.0)
Scikit-image (0.13.0)
PIL
imageio
shutil
开源框架代码地址
https://github.com/szad670401/HyperLPR
代码准备
自动化筛选流程确定
- 确定筛选处理数据格式:图片、视频
- 确定图片和视频的读取调用库:图片——opencv,视频——imageio
- 确定图片和视频的读取方式:遍历读取
- 编写遍历读取相关代码:
# 遍历读取图片
for parent, dirnames, filenames in os.walk(input_image_root_path):
for filename in filenames:
img_path = os.path.join(parent, filename)
img_name = os.path.splitext(filename)[0]
img_format = os.path.splitext(filename)[1]
if img_format == ".jpg" or img_format == ".png":
img = cv2.imread(img_path)
# 进一步识别处理
# 遍历读取视频帧
vid = imageio.get_reader(input_video_path, 'ffmpeg')
for num, frame in enumerate(vid):
# 根据帧采样间隔进行选取(对于非高速运动的视频,一般相隔太近的帧数据差异很小,没必要对每一帧进行识别)
if num % frame_interval == 0:
# 保存帧数据为图片
image_path = output_image_root_path + "/" + str(num // frame_interval) + '.jpg'
imageio.imwrite(image_path, frame)
img = cv2.imread(image_path)
# 进一步识别处理
- 编写车牌识别相关代码:
# 预加载识别模型
model = pr.LPR("model/cascade.xml", "model/model12.h5", "model/ocr_plate_all_gru.h5")
# 获取识别结果
result = model.SimpleRecognizePlateByE2E(img)
- 确定识别结果判断规则
非空(数量)判断:判断是否有识别到车牌或识别到的车牌数量,该判断主要确定待筛选图片中是否含有车牌对象,如果含有则保留,如果不含则剔除
尺寸判断:判断识别到的车牌尺寸是否符合要求,由于拍摄距离和照片分辨率的限制,经常会存在一些尺寸较小的图片,有时甚至看不清具体的车牌号信息,这样的数据对于模型训练来说,意义不大,所以也是需要过滤的

完整代码
首先需要clone开源项目https://github.com/szad670401/HyperLPR,并在该项目目录下创建python文件
import cv2
import os
import imageio
import shutil
import HyperLPRLite as pr
import time
model = pr.LPR("model/cascade.xml", "model/model12.h5", "model/ocr_plate_all_gru.h5")
# 视频筛选
def getAndSaveVideoFrame(input_video_path, output_image_root_path, frame_interval):
if (os.path.exists(output_image_root_path)) is False:
os.makedirs(output_image_root_path)
try:
j = 0
vid = imageio.get_reader(input_video_path, 'ffmpeg')
for num, frame in enumerate(vid):
if num % frame_interval == 0:
image_path = output_image_root_path + "/" + str(num // frame_interval) + '.jpg'
imageio.imwrite(image_path, frame)
img = cv2.imread(image_path)
results = model.SimpleRecognizePlateByE2E(img)
if len(results)>0:
j += 1
match_num = 0
for result in results:
# 识别框像素高不能小于64
if result[2][3] >= 64:
match_num = match_num + 1
if match_num > 0:
print(image_path + "中存在车牌且尺寸符合要求:" + str(match_results))
else:
os.remove(image_path)
else:
os.remove(image_path)
print("视频 " + input_video_path + " 抓帧成功,数量:" + str(j))
except Exception as e:
print("视频 " + input_video_path + " 文件损坏或非视频文件:" + str(e))
# 图片筛选
def getAndSaveImage(input_video_path, output_image_root_path):
if (os.path.exists(output_image_root_path)) is False:
os.makedirs(output_image_root_path)
for parent, dirnames, filenames in os.walk(input_image_root_path):
for filename in filenames:
img_path = os.path.join(parent, filename)
img_name = os.path.splitext(filename)[0]
img_format = os.path.splitext(filename)[1]
if img_format == ".jpg" or img_format == ".png":
time_ = time.time()
img = cv2.imread(img_path)
results = model.SimpleRecognizePlateByE2E(img)
if len(results)>0:
match_num = 0
for result in results:
# 识别框像素高不能小于64
if result[2][3] >= 64:
match_num = match_num + 1
if match_num > 0:
new_file_name_path = os.path.join(output_image_root_path, str(time_) + "_" + img_name + img_format)
shutil.copyfile(img_path, new_file_name_path)
print(img_path + "存在符合要求的车牌识别结果:" + str(results))
至此,中文车牌识别的自动化筛选工具便开发完成了,最后,只需将需要将需要筛选的图片集或视频放入指定路径的文件夹下,设定好相关输出路径和规则,运行自动化筛选代码,只需等待一段时间便可以查看到筛选出的数据了,当然该模型识别未必百分百精确,也有可能出现误识别的情况,这时仍需要我们来手动筛选一遍,不过比起整个手动筛选的工作量,可以说是九牛一毛了。