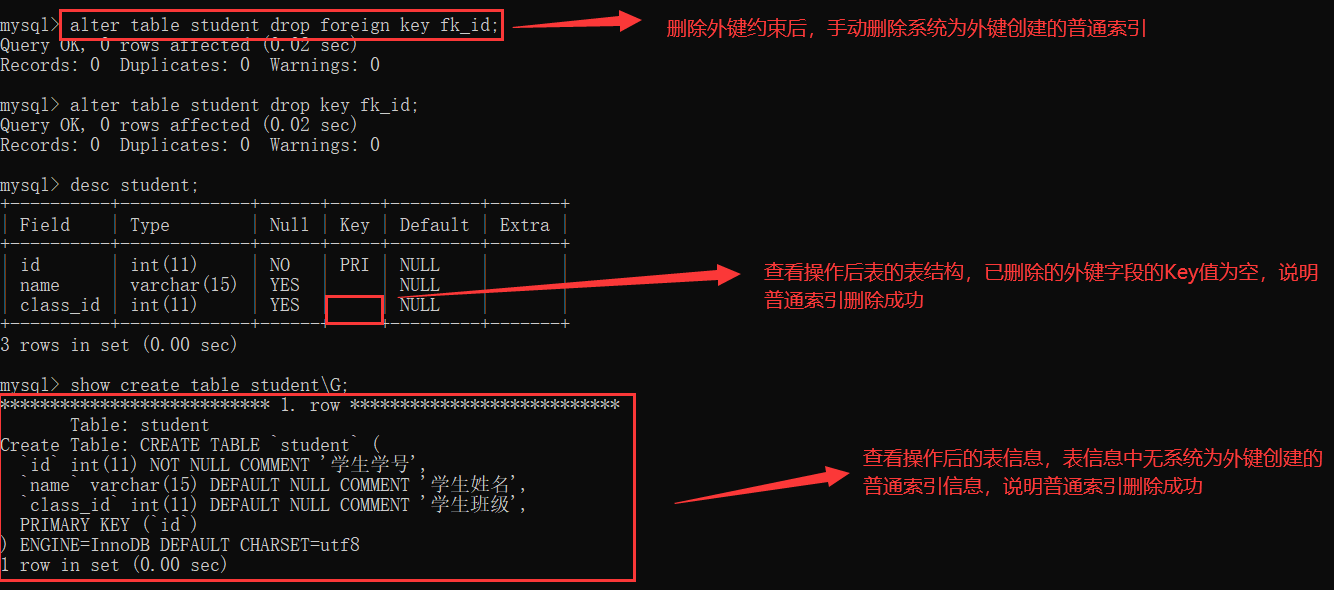
目录
1.值类型
1.1. 数组Array
数组遍历
数组初始化
值拷贝
内置函数len、cap
2. 引用数据类型
2.1. 切片slice
切片初始化
切片的内存布局
通过slice修改struct array值
用append内置函数操作切片(切片追加)
slice自动扩容
slice中cap重新分配规律
copy函数
字符串和切片(string and slice)
golang slice data[:6:8] 两个冒号的理解
2.2. Map
声明map
map初始化
map操作
map遍历
迭代时删除
1.值类型
1.1. 数组Array
Golang Array和以往认知的数组有很大不同。
1. 数组:是同一种数据类型的固定长度的序列。
2. 数组定义:var a [len]int,比如:var a [5]int,数组长度必须是常量,且是类型的组成部分。一旦定义,长度不能变。
3. 长度是数组类型的一部分,因此,var a[5] int和var a[10]int是不同的类型。
4. 数组可以通过下标进行访问,下标是从0开始,最后一个元素下标是:len-1
5. 访问越界,如果下标在数组合法范围之外,则触发访问越界,会panic
6. 数组是值类型,赋值和传参会复制整个数组,而不是指针。因此改变副本的值,不会改变本身的值。
7.支持 "=="、"!=" 操作符,因为内存总是被初始化过的。
8.指针数组 [n]*T,数组指针 *[n]T。
数组遍历
一维数组:
for i := 0; i < len(a); i++ {
}
for index, v := range a {
}多维数组:
var f [2][3]int = [...][3]int{{1, 2, 3}, {7, 8, 9}}
for k1, v1 := range f {
for k2, v2 := range v1 {
fmt.Printf("(%d,%d)=%d ", k1, k2, v2)
}
fmt.Println()
}
输出结果:
(0,0)=1 (0,1)=2 (0,2)=3
(1,0)=7 (1,1)=8 (1,2)=9 数组初始化
一维数组:
全局:
var arr0 [5]int = [5]int{1, 2, 3}
var arr1 = [5]int{1, 2, 3, 4, 5}
var arr2 = [...]int{1, 2, 3, 4, 5, 6}
var str = [5]string{3: "hello world", 4: "tom"}
局部:
a := [3]int{1, 2} // 未初始化元素值为 0。
b := [...]int{1, 2, 3, 4} // 通过初始化值确定数组长度。
c := [5]int{2: 100, 4: 200} // 使用引号初始化元素。
d := [...]struct {
name string
age uint8
}{
{"user1", 10}, // 可省略元素类型。
{"user2", 20}, // 别忘了最后一行的逗号。
}多维数组:
全局
var arr0 [5][3]int
var arr1 [2][3]int = [...][3]int{{1, 2, 3}, {7, 8, 9}}
局部:
a := [2][3]int{{1, 2, 3}, {4, 5, 6}}
b := [...][2]int{{1, 1}, {2, 2}, {3, 3}} // 第 2 纬度不能用 "..."。值拷贝
值拷贝行为会造成性能问题,通常会建议使用 slice,或数组指针。
package main
import (
"fmt"
)
func test(x [2]int) {
fmt.Printf("x: %p\n", &x)
x[1] = 1000
}
func main() {
a := [2]int{}
fmt.Printf("a: %p\n", &a)
test(a)
fmt.Println(a)
}输出结果:
a: 0xc42007c010
x: 0xc42007c030
[0 0]内置函数len、cap
内置函数 len 和 cap 都返回数组长度 (元素数量)。
package main
func main() {
a := [2]int{}
println(len(a), cap(a))
}输出结果:
2 22. 引用数据类型
Golang的引用类型包括 slice、map 和 channel。它们有复杂的内部结构,除了申请内存外,还需要初始化相关属性。
内置函数 new 计算类型大小,为其分配零值内存,返回指针。而 make 会被编译器翻译 成具体的创建函数,由其分配内存和初始化成员结构,返回对象而非指针。
package main
func main() {
a := []int{0, 0, 0} // 提供初始化表达式。
a[1] = 10
b := make([]int, 3) // make slice
b[1] = 10
c := new([]int)
c[1] = 10 // ./main.go:11:3: invalid operation: c[1] (type *[]int does not support indexing)
}引用类型:
- 变量存储的是一个地址,这个地址存储最终的值。内存通常在堆上分配。通过GC回收。
- 获取指针类型所指向的值,使用:" * " 取值符号 。比如:var *p int, 使用*p获取p指向的值
- 指针、slice、map、chan等都是引用类型。
new和make的区别
make 用来创建map、slice、channel
new 用来创建值类型
new 和 make 均是用于分配内存:
- new 用于值类型和用户定义的类型,如自定义结构,make 用于内置引用类型(切片、map 和管道)。它们的用法就像是函数,但是将类型作为参数:new(type)、make(type)。new(T) 分配类型 T 的零值并返回其地址,也就是指向类型 T 的指针。它也可以被用于基本类型:v := new(int)。
- make(T) 返回类型 T 的初始化之后的值,因此它比 new 进行更多的工作。new() 是一个函数,不要忘记它的括号。
2.1. 切片slice
需要说明,slice 并不是数组或数组指针。它通过内部指针和相关属性引用数组片段,以实现变长方案。
1. 切片:切片是数组的一个引用,因此切片是引用类型。但自身是结构体,值拷贝传递。
2. 切片的长度可以改变,因此,切片是一个可变的数组。
3. 切片遍历方式和数组一样,可以用len()求长度。表示可用元素数量,读写操作不能超过该限制。
4. cap可以求出slice最大扩张容量,不能超出数组限制。0 <= len(slice) <= len(array),其中array是slice引用的数组。
5. 切片的定义:var 变量名 []类型,比如 var str []string var arr []int。
6. 如果 slice == nil,那么 len、cap 结果都等于 0。
切片初始化
切片初始化
全局:
var arr = [...]int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
var slice0 []int = arr[start:end]
var slice1 []int = arr[:end]
var slice2 []int = arr[start:]
var slice3 []int = arr[:]
var slice4 = arr[:len(arr)-1] //去掉切片的最后一个元素
局部:
arr2 := [...]int{9, 8, 7, 6, 5, 4, 3, 2, 1, 0}
slice5 := arr[start:end]
slice6 := arr[:end]
slice7 := arr[start:]
slice8 := arr[:]
slice9 := arr[:len(arr)-1] //去掉切片的最后一个元素通过make来创建切片
var slice []type = make([]type, len)
slice := make([]type, len)
slice := make([]type, len, cap)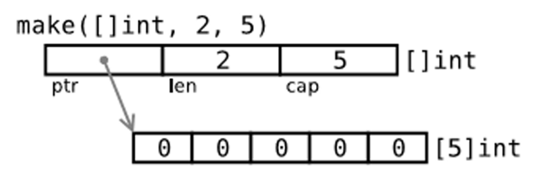
切片的内存布局

读写操作实际目标是底层数组,只需注意索引号的差别。
package main
import (
"fmt"
)
func main() {
data := [...]int{0, 1, 2, 3, 4, 5}
s := data[2:4]
s[0] += 100
s[1] += 200
fmt.Println(s)
fmt.Println(data)
}
输出:
[102 203]
[0 1 102 203 4 5]可直接使用make创建 slice 对象,自动分配底层数组。
使用 make 动态创建 slice,避免了数组必须用常量做长度的麻烦。还可用指针直接访问底层数组,退化成普通数组操作。
package main
import "fmt"
func main() {
s1 := []int{0, 1, 2, 3, 8: 100} // 通过初始化表达式构造,可使用索引号。
fmt.Println(s1, len(s1), cap(s1))
s2 := make([]int, 6, 8) // 使用 make 创建,指定 len 和 cap 值。
fmt.Println(s2, len(s2), cap(s2))
s3 := make([]int, 6) // 省略 cap,相当于 cap = len。
fmt.Println(s3, len(s3), cap(s3))
}
输出结果:
[0 1 2 3 0 0 0 0 100] 9 9
[0 0 0 0 0 0] 6 8
[0 0 0 0 0 0] 6 6通过slice修改struct array值
package main
import (
"fmt"
)
func main() {
d := [5]struct {
x int
}{}
s := d[:]
d[1].x = 10
s[2].x = 20
fmt.Println(d)
fmt.Printf("%p, %p\n", &d, &d[0])
}
输出结果:
[{0} {10} {20} {0} {0}]
0xc4200160f0, 0xc4200160f0用append内置函数操作切片(切片追加)
append :向 slice 尾部添加数据,返回新的 slice 对象。
package main
import (
"fmt"
)
func main() {
var a = []int{1, 2, 3}
fmt.Printf("slice a : %v\n", a)
var b = []int{4, 5, 6}
fmt.Printf("slice b : %v\n", b)
c := append(a, b...)
fmt.Printf("slice c : %v\n", c)
d := append(c, 7)
fmt.Printf("slice d : %v\n", d)
e := append(d, 8, 9, 10)
fmt.Printf("slice e : %v\n", e)
}
输出:
slice a : [1 2 3]
slice b : [4 5 6]
slice c : [1 2 3 4 5 6]
slice d : [1 2 3 4 5 6 7]
slice e : [1 2 3 4 5 6 7 8 9 10]slice自动扩容
超出原 slice.cap 限制,就会重新分配底层数组,即便原数组并未填满。
package main
import (
"fmt"
)
func main() {
data := [...]int{0, 1, 2, 3, 4, 10: 0}
s := data[:2:3]
fmt.Printf("array s: %v, len:%v, cap:%v\n", s, len(s), cap(s)) // array s: [0 1], len:2, cap:3
s = append(s, 100, 200) // 一次 append 两个值,超出 s.cap 限制。
fmt.Println(s, data) // 重新分配底层数组,与原数组无关。
fmt.Println(&s[0], &data[0]) // 比对底层数组起始指针。
}
输出:
array s: [0 1], len:2, cap:3
[0 1 100 200] [0 1 2 3 4 0 0 0 0 0 0]
0xc0000180c0 0xc000066060slice中cap重新分配规律
package main
import (
"fmt"
)
func main() {
s := make([]int, 0, 1)
c := cap(s)
for i := 0; i < 50; i++ {
s = append(s, i)
if n := cap(s); n > c {
fmt.Printf("cap: %d -> %d\n", c, n)
c = n
}
}
}
输出:
cap: 1 -> 2
cap: 2 -> 4
cap: 4 -> 8
cap: 8 -> 16
cap: 16 -> 32
cap: 32 -> 64- 从输出结果可以看出,append 后的 s 重新分配了底层数组,并复制数据。如果只追加一个值,则不会超过 s.cap 限制,也就不会重新分配。
- 通常以 2 倍容量重新分配底层数组。在大批量添加数据时,建议一次性分配足够大的空间,以减少内存分配和数据复制开销。或初始化足够长的 len 属性,改用索引号进行操作。及时释放不再使用的 slice 对象,避免持有过期数组,造成 GC 无法回收。
copy函数
切片拷贝
s1 := []int{1, 2, 3, 4, 5}
fmt.Printf("slice s1 : %v\n", s1)
s2 := make([]int, 10)
fmt.Printf("slice s2 : %v\n", s2)
copy(s2, s1) //func copy(dst, src []Type) int
fmt.Printf("copied slice s1 : %v\n", s1)
fmt.Printf("copied slice s2 : %v\n", s2)
输出:
slice s1 : [1 2 3 4 5]
slice s2 : [0 0 0 0 0 0 0 0 0 0]
copied slice s1 : [1 2 3 4 5]
copied slice s2 : [1 2 3 4 5 0 0 0 0 0]字符串和切片(string and slice)
string底层就是一个byte的数组,因此,也可以进行切片操作。
package main
import (
"fmt"
)
func main() {
str := "hello world"
s1 := str[0:5]
fmt.Println(s1)
s2 := str[6:]
fmt.Println(s2)
}
输出:
hello
worldstring本身是不可变的,因此要改变string中字符。需要如下操作:
英文字符串:
package main
import (
"fmt"
)
func main() {
str := "Hello world"
s := []byte(str) //中文字符需要用[]rune(str)
s[6] = 'G'
s = s[:8]
s = append(s, '!')
str = string(s)
fmt.Println(str)
}
输出:
Hello Go!中文字符串:
package main
import (
"fmt"
)
func main() {
str := "你好,世界!hello world!"
s := []rune(str)
s[3] = '够'
s[4] = '浪'
s[12] = 'g'
s = s[:14]
str = string(s)
fmt.Println(str)
}
输出:
你好,够浪!hello gogolang slice data[:6:8] 两个冒号的理解
- 常规slice , data[6:8],从第6位到第8位(返回6, 7),长度len为2, 最大可扩充长度cap为4(6-9)
- 另一种写法: data[:6:8] 每个数字前都有个冒号, slice内容为data从0到第6位,长度len为6,最大扩充项cap设置为8
- a[x:y:z] 切片内容 [x:y] 切片长度: y-x 切片容量:z-x
package main
import (
"fmt"
)
func main() {
slice := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
d1 := slice[6:8]
fmt.Println(d1, len(d1), cap(d1))
d2 := slice[:6:8]
fmt.Println(d2, len(d2), cap(d2))
}2.2. Map
Golang Map:引用类型,哈希表。一堆键值对的未排序集合。
键必须是支持相等运算符 ("=="、"!=") 类型, 如 number、string、 pointer、array、struct,以及对应的 interface。值可以是任意类型,没有限制。
声明map
var map变量名 map[key] value
其中:key为键类型,value为值类型
例如:value不仅可以是标注数据类型,也可以是自定义数据类型
package main
type personInfo struct {
ID string
Name string
Address string
}
var m1 map[string]int
var m2 map[string]personInfo
func main() {}map初始化
直接初始化(创建)
package main
import (
"fmt"
)
var m1 map[string]float32 = map[string]float32{"C": 5, "Go": 4.5, "Python": 4.5, "C++": 2}
func main() {
m2 := map[string]float32{"C": 5, "Go": 4.5, "Python": 4.5, "C++": 2}
m3 := map[int]struct {
name string
age int
}{
1: {"user1", 10}, // 可省略元素类型。
2: {"user2", 20},
}
fmt.Printf("全局变量 map m1 : %v\n", m1)
fmt.Printf("局部变量 map m2 : %v\n", m2)
fmt.Printf("局部变量 map m3 : %v\n", m3)
}
输出结果:
全局变量 map m1 : map[Python:4.5 C++:2 C:5 Go:4.5]
局部变量 map m2 : map[C++:2 C:5 Go:4.5 Python:4.5]
局部变量 map m3 : map[2:{user2 20} 1:{user1 10}]
注意:由m1,m2可以看出map是键值对的无序集合通过make初始化(创建)
- Go语言提供的内置函数make()可以用于灵活地创建map。
- 预先给 make 函数一个合理元素数量参数,有助于提升性能。因为事先申请一大块内存,可避免后续操作时频繁扩张。
package main
import (
"fmt"
)
func main() {
// 创建了一个键类型为string,值类型为int的map
m1 := make(map[string]int)
// 也可以选择是否在创建时指定该map的初始存储能力,如创建了一个初始存储能力为5的map
m2 := make(map[string]int, 5)
m1["a"] = 1
m2["b"] = 2
fmt.Printf("局部变量 map m1 : %v\n", m1)
fmt.Printf("局部变量 map m2 : %v\n", m2)
}
输出:
局部变量 map m1 : map[a:1]
局部变量 map m2 : map[b:2]map操作
插入、更新、查找、删除、判断是否存在、求长度
m := map[string]string{"key0": "value0", "key1": "value1"}
fmt.Printf("map m : %v\n", m)
//map插入
m["key2"] = "value2"
fmt.Printf("inserted map m : %v\n", m)
//map修改
m["key0"] = "hello world!"
fmt.Printf("updated map m : %v\n", m)
//map查找
val, ok := m["key0"]
if ok {
fmt.Printf("map's key0 is %v\n", val)
}
// 长度:获取键值对数量。
len := len(m)
fmt.Printf("map's len is %v\n", len)
// cap 无效,error
// cap := cap(m) //invalid argument m (type map[string]string) for cap
// fmt.Printf("map's cap is %v\n", cap)
// 判断 key 是否存在。
if val, ok = m["key"]; !ok {
fmt.Println("map's key is not existence")
}
// 删除,如果 key 不存在,不会出错。
if val, ok = m["key1"]; ok {
delete(m, "key1")
fmt.Printf("deleted key1 map m : %v\n", m)
}map遍历
不能保证迭代返回次序,通常是随机结果,具体和版本实现有关。
for k, v := range map {}
for _, v := range map {}
for k := range map {}
容器和结构体(map and struct)
语法比较:
map[type]struct
map[type]*struct
package main
import "fmt"
func main() {
type user struct{ name string }
/*
当 map 因扩张而重新哈希时,各键值项存储位置都会发生改变。
因此,map 被设计成 not addressable。
类似 m[1].name 这种期望透过原 value 指针修改成员的行为自然会被禁 。
*/
m := map[int]user{ //
1: {"user1"},
}
// m[1].name = "Tom"
// ./main.go:16:12: cannot assign to struct field m[1].name in map
fmt.Println(m)
// 正确做法是完整替换 value 或使用指针。
u := m[1]
u.name = "Tom"
m[1] = u // 替换 value。
m2 := map[int]*user{
1: &user{"user1"},
}
m2[1].name = "Jack" // 返回的是指针复制品。透过指针修改原对象是允许的。
fmt.Println(m2)
}
输出:
map[1:{user1}]
map[1:0xc42000e1e0]迭代时删除
可以在迭代时安全删除键值。但如果期间有新增操作,那么就不知道会有什么意外了。
package main
import "fmt"
func main() {
for i := 0; i < 5; i++ {
m := map[int]string{
0: "a", 1: "a", 2: "a", 3: "a", 4: "a",
5: "a", 6: "a", 7: "a", 8: "a", 9: "a",
}
for k := range m {
m[k+k] = "x"
delete(m, k)
}
fmt.Println(m)
}
}输出
//每次输出都会变化
map[36:x 28:x 32:x 2:x 8:x 10:x 12:x]
map[12:x 6:x 16:x 28:x 4:x 10:x 72:x]
map[12:x 14:x 16:x 18:x 20:x]
map[18:x 10:x 14:x 4:x 6:x 16:x 24:x]
map[12:x 16:x 4:x 40:x 14:x 18:x]