大家好,我是派森酱!
最近工作压力大,每天晚上回来基本洗洗就要睡了。但是总觉得一天就这么过去,有点遗憾,所以每天睡前躺床上刷刷抖音,看看美丽小姐姐,心情就会舒畅许多!
有些小姐姐的视频真是百看不厌,就想保存到手机,在需要安慰的时候(空虚寂寞冷)拿出来欣赏一下,给自己打打气!
所以就动手把她们的视频扒下来,慢慢欣赏!下面就给大家介绍一下扒拉的过程。
本文介绍3个方面
怎么下载windows版某音的高清视频壁纸(回顾旧文+视频介绍)
下载某音单个视频(视频介绍)
下载某音用户视频合集(详细介绍)
使用mitmproxy,不论是网页版某音还是windows版某音,视频、动态壁纸、评论都可以下载。
mitmproxy的代理配置和证书安装在
python技术公众号已介绍过 抓取某音短视频数据
写这篇文章,是因为我想下载这个合集的105个视频

下载这些有什么用处呢?
好处之一是获得丰富的素材,让你眼花缭乱,我一口气下载了windows版某音400多个高清视频壁纸
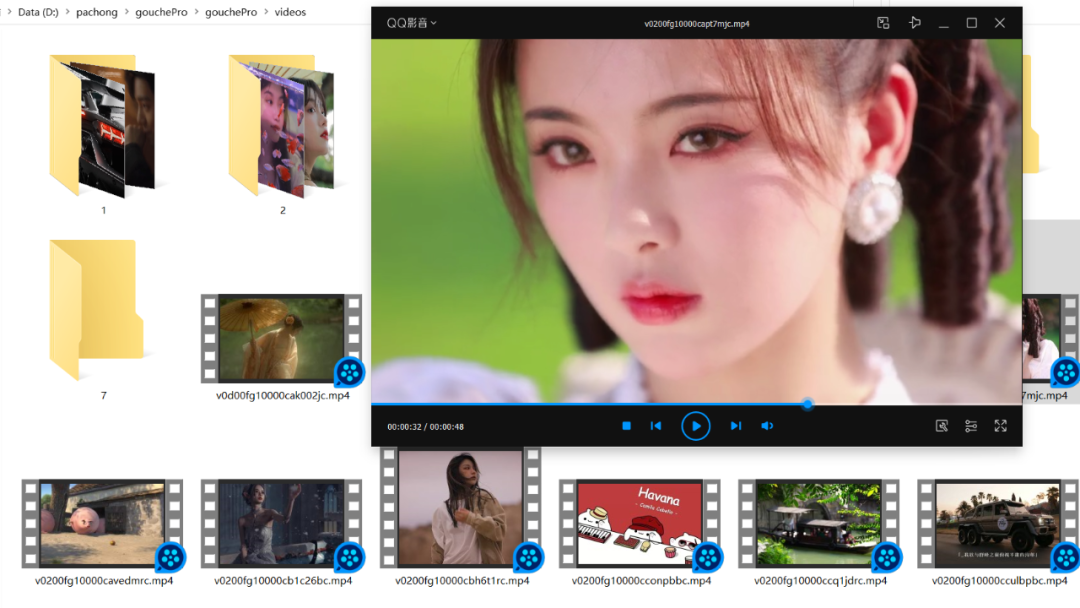
都是高清横版的桌面动态视频壁纸,简直不要太香。
之前用“绕过cookie”的方式下载过懂车帝上收藏的视频,比较来说,我们今天介绍的方法更简单,都不用运行python去模拟请求了。看mitmweb怎么帮你精确匹配:
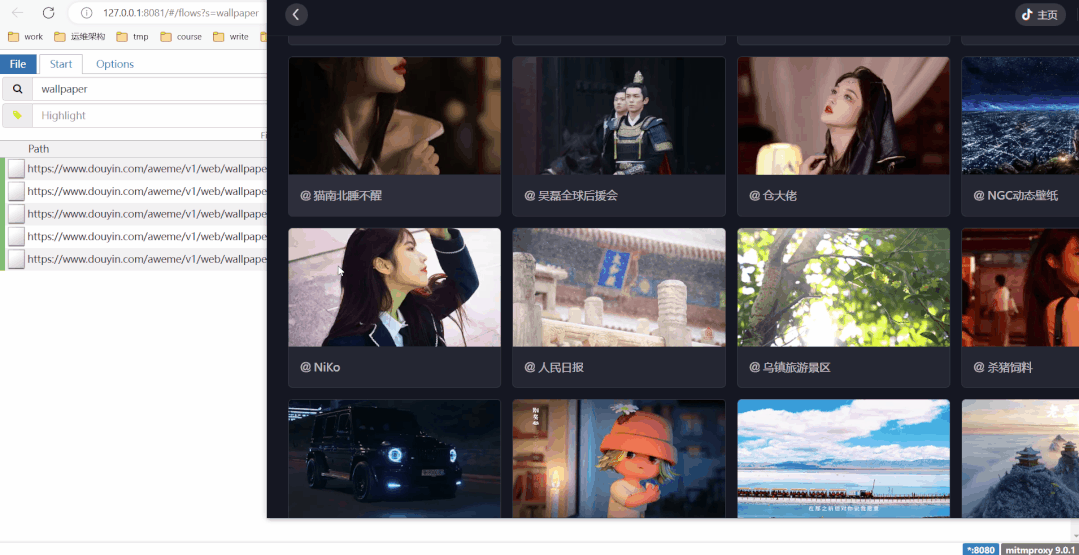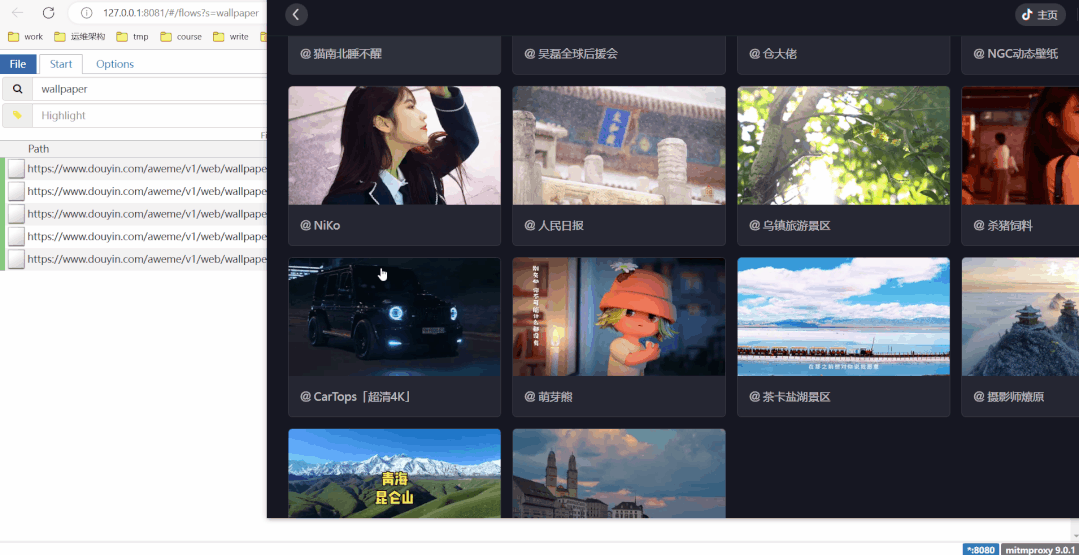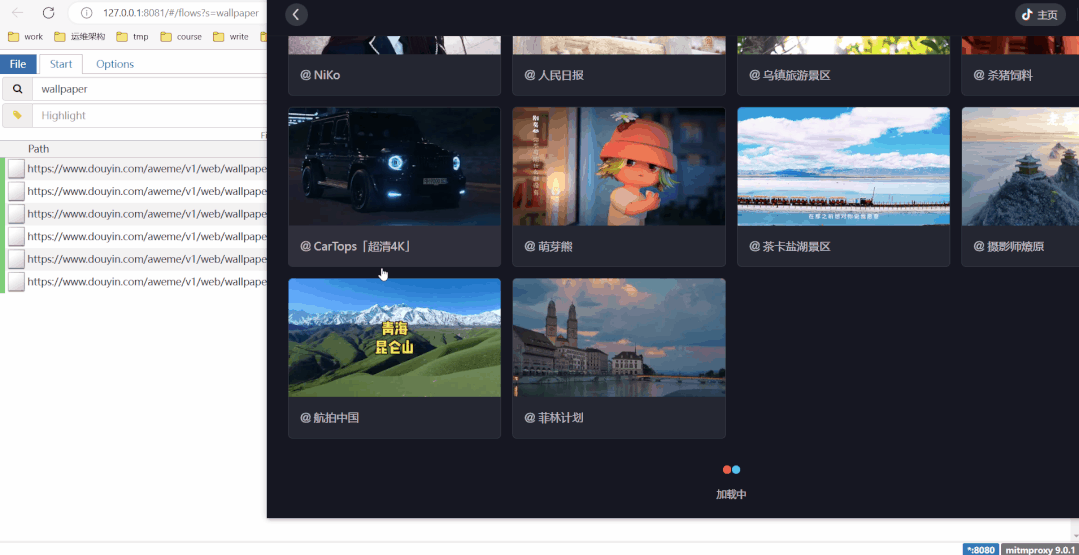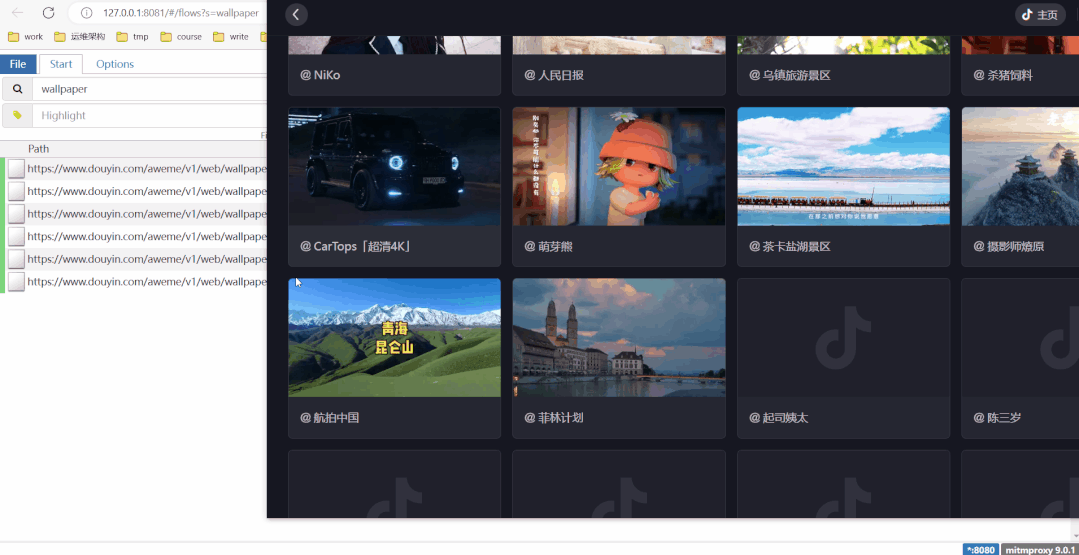
定义好搜索条件"wallpaper",刷新某音动态壁纸,左边会出现新的链接,视频MP4地址都在这些链接里!
具体可以参考文章 用Python爬取某音动态壁纸,桌面更香了
为表述清楚,第一次尝试制作了视频版进行说明:
使用视频素材
我用剪映做的这个"三分屏片头效果":
需要3个舞蹈视频,都是通过mitmproxy从某音动态壁纸获取链接,然后python处理批量下载的。
很多青春活力的舞蹈,下载下来用上去简直不要太合适
下载单个视频
单个视频的下载用mitmdump -q -s 脚本名的方式,脚本很简单,这样写就可以了
def response(flow):
if 'web.douyinvod.com' in flow.request.url:
print('nice111',flow.request.url)你刷的某音视频匹配web.douyinvod.com,
微信的视频号,某音视频下的评论,同样可以用这种方式获取或下载,因为链接是有特征的:
某音视频链接一般匹配
web.douyinvod.com微信视频号匹配
video.qq.com某音视频下的评论匹配
v1/web/comment/list
具体看我录制的视频介绍:
这种方式可以把你正在看的某音漂亮视频实时下载下来
下载某音用户视频合集
说了这么多,进入今天的主题,下载视频合集

注意看,这个合集更新至105集。
记住这个数字,我们要把它全部下载下来。以免作者删除作品就看不到了。
先设置代理并启动mitmweb,
然后在网页上点开合集,进入到播放页面
滚动鼠标滚轮会依次播放这个合集的视频,我们耐心一点,滚动到最后一个作品(第105个)。
快速滚动就好了,目的是让mitmweb记录到这些视频数据。虽然稍微繁琐,但100多个视频十几秒滚动完,然后就好办了。
接下来的步骤跟用Python爬取某音动态壁纸,桌面更香了!几乎一样,只要换个搜索条件。
mix有“合集”的意思,我们搜索“mix/”看到7个url
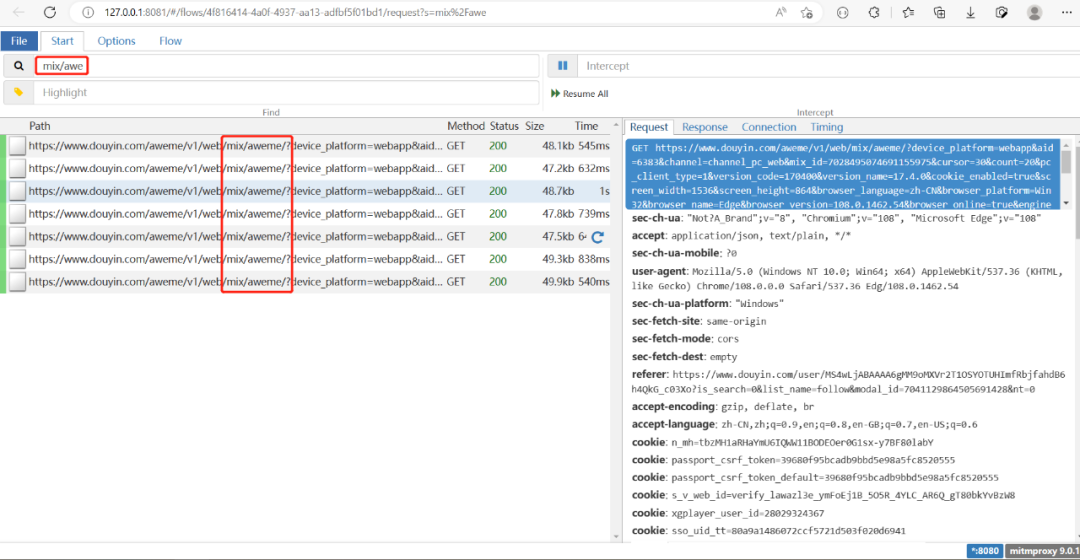
假如选中一个,点击“Download”按钮,会下载一个“content.data”的文件
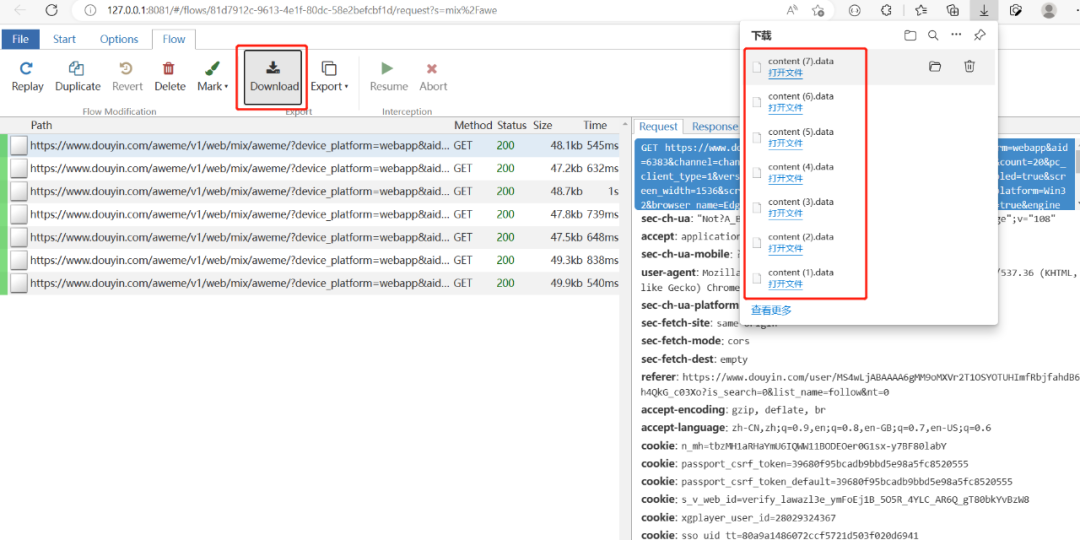
7个url就是7个content.data文件,用脚本去做去重处理
import json
url_list = []
url_dict = {}
with open('content.data', 'r',encoding='utf-8') as f:
x = json.load(f)
for i in x['aweme_list']:
#去掉特殊的
if 'anchor_info' in i:
continue
else:
for i in i['video']['bit_rate']:
#url_list有3个url,但视频内容相同,取最后一个
url = i['play_addr']['url_list'][2]
#video_id相同的是同一个视频,取出video_id,用字典去重
a = url.split('video_id=')[1].split('&line=')[0]
print(a)
url_dict[a] = url
#去重后的视频添加到列表中
for k,v in url_dict.items():
url_list.append(v)
print(len(url_list))
print(url_list)打印一下输出,每个content.data有15个视频地址
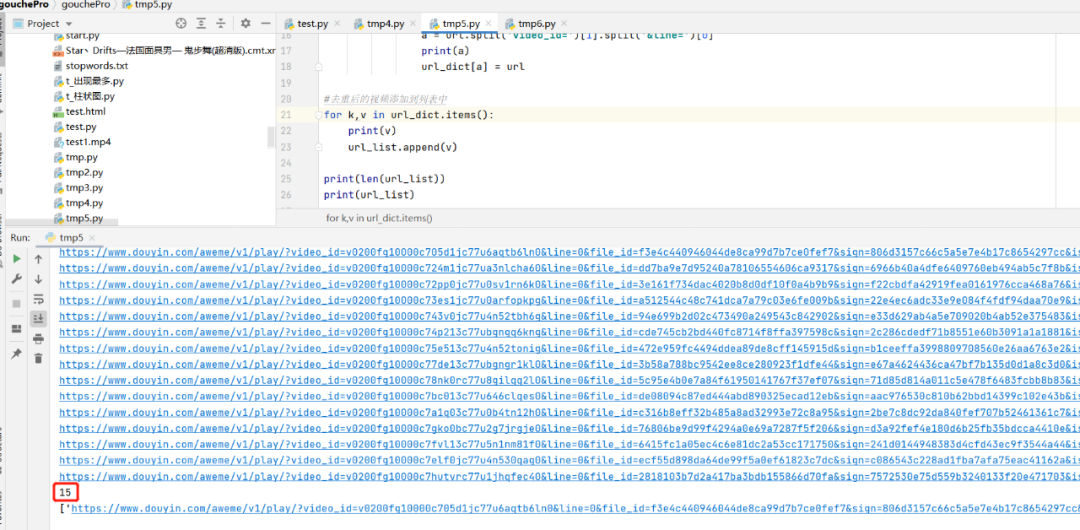
7个content.data,7乘以15就是105个视频,整个合集的视频下载地址都在这了!
然后用脚本下载
import os
import requests
from tqdm import tqdm
VIDEO_PATH = r'videos'
def download(url,fname):
# 用流stream的方式获取url的数据
resp = requests.get(url, stream=True,verify=False)
total = int(resp.headers.get('content-length', 0))
with open(fname, 'wb') as file, tqdm(
desc=fname,
total=total,
unit='iB',
unit_scale=True,
unit_divisor=1024,
) as bar:
for data in resp.iter_content(chunk_size=1024):
size = file.write(data)
bar.update(size)
if __name__ == "__main__":
url_list = ['https://www.douyin.com/aweme/v1/play/?video_id=v0d00fg10000cagm35rc77u3k4nb0430&line=0&file_id=fec3f8eeb45e48a18f30dfd96922f659&sign=4450c5609c69d0a5c1100e6801cf25dd&is_play_url=1&source=PackSourceEnum_AWEME_DETAIL', 'https://www.douyin.com/aweme/v1/play/?video_id=v0200fg10000c9glhfrc77u0fbj4iqs0&line=0&file_id=e330ce20f5f245e9b1923f8cd26b6ef9&sign=0ee1a91a52645237a4d1382c22a0b540&is_play_url=1&source=PackSourceEnum_AWEME_DETAIL', ...]
for url in url_list:
video_name = url[47:67]
video_full_path = os.path.join(VIDEO_PATH,"%s.mp4" % video_name)
download(url, video_full_path)下载好的视频,如下图所示

好了,今天就介绍到这里,咱们下期见!