目录
概述
工程建立
代码集成
函数介绍
使用示例
概述
coreJSON是FreeRTOS中的一个组件库,支持key查找的解析器,他只是一个解析器,不能生成json数据。同时严格执行 ECMA-404 JSON 标准。该库用 C 语言编写,设计符合 ISO C90 和 MISRA C。它已被证明可以安全使用内存,并且无需堆分配,使其适用于 IoT 微控制器,而且还可以完全移植到其他平台。
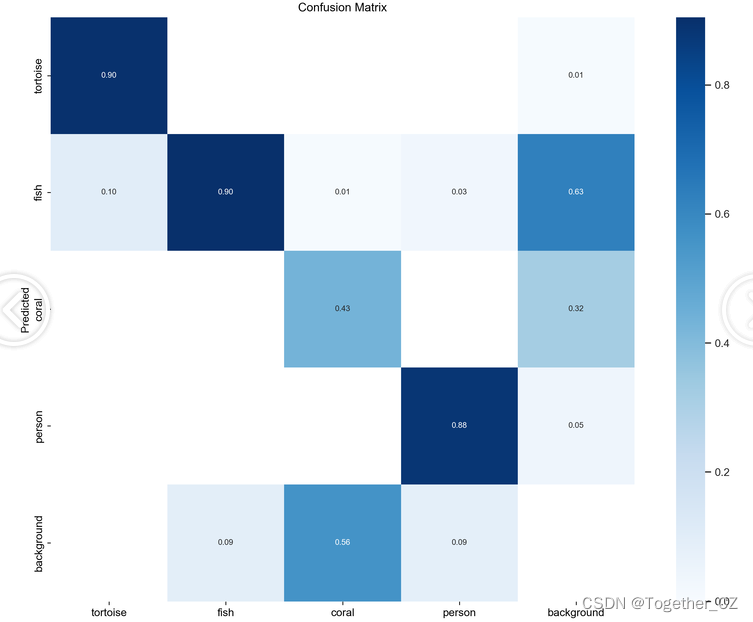
内存使用如下:

内存使用情况
JSON 库中的所有函数仅在提供的栈上运行,并且仅使用栈上的局部变量。为了支持仅静态使用,根据需要重新解析,这样就不需要保留状态。
解析严格性
输入验证对于强大的安全态势是必要的。因此,解析器严格执行 ECMA-404 JSON 标准。此外,还会检查 JSON 文档是否存在非法 UTF-8 序列,并且字符串会验证 unicode 十六进制转义。
合规性和覆盖范围
JSON 库的设计符合 ISO C90 和 MISRA C:2012。所有函数都被编写为具有最小的复杂性。编写单元测试和 CBMC 证明以覆盖每条执行路径并实现 100% 的分支覆盖率。←(很牛)
源码:
GitHub - FreeRTOS/coreJSON at b92c8cd9cdba790e46eab05f7a620b0f15c5be69
文档:
coreJSON: Overview (freertos.org)
但是可惜的是STM32CUBEIDE的freertos中未包含coreJSON组件。所以需要我们自己添加进入工程。下面我们只介绍coreJson的集成与使用,不介绍如何进行单元测试,因为想要使用单元测试需要集成Unity库,那又是另一个库了,想要了解的可以参考我的另外一篇文章,同样我也会把修改过能运行的单元测试代码附在文章的末尾
unity库的集成:
Unity(单元测试)在STM32上的移植与应用-CSDN博客
工程建立
使用STM32CUBEIDE新建工程,选择407芯片

配置串口,为了后面的调试信息输出


保存,生成代码。
在main.c中添加重映射函数,保证printf和scanf正常使用。
/* Private user code ---------------------------------------------------------*/
/* USER CODE BEGIN 0 */
int __io_putchar(int ch)
{
/* Implementation of __io_putchar */
/* e.g. write a character to the UART1 and Loop until the end of transmission */
HAL_UART_Transmit(&huart1, (uint8_t *)&ch, 1, 0xFFFFFFFF);
return ch;
}
int __io_getchar(void)
{
/* Implementation of __io_getchar */
char rxChar;
// This loops in case of HAL timeout, but if an ok or error occurs, we continue
while (HAL_UART_Receive(&huart1, (uint8_t *)&rxChar, 1, 0xFFFFFFFF) == HAL_TIMEOUT);
return rxChar;
}
/* USER CODE END 0 */
代码集成
下载coreJSON源码,在工程根路径下新建文件夹coreJSON,并将源码中的source中的文件复制到coreJSON文件夹中。


在工程中添加相关的源文件和头文件参与编译。
右键工程,选择properties

添加头文件。

添加编译源文件。

此时可以进行编译,这是事实可以编译通过的。
至此,coreJSON的集成就完成了,下面进行使用的讲解。
函数介绍
coreJSON中主要有五个函数可能会被用到。这里只介绍其中的四个,因为还有一个几乎用不上。
JSONStatus_t JSON_Validate( const char * buf, size_t max );解析缓冲区以确定它是否包含有效的 JSON 文档。
参数
[in]buf要解析的缓冲区。
[in]max缓冲区的大小。
返回值
如果缓冲区内容是有效的 JSON,则返回 JSONSuccess;
如果 buf 为 NULL则返回 JSONNullParameter ;
如果 max 为 0,则返回 JSONBadParameter;
如果缓冲区内容不是有效的 JSON则返回 JSONIllegalDocument ;
如果对象和数组嵌套超过阈值则返回 JSONMaxDepthExceeded ;
如果缓冲区内容可能有效但不完整则返回 JSONPartial 。
注意:最大嵌套深度可以通过定义宏 JSON_MAX_DEPTH 来指定。 默认值是 32。
默认情况下,有效的 JSON 文档可能只包含单个元素(例如字符串、布尔值、数字)。如果要求有效文档必须包含对象或数组,请定义 JSON_VALIDATE_COLLECTIONS_ONLY。
官方给出的例程为
// Variables used in this example.
JSONStatus_t result;
char buffer[] = "{\"foo\":\"abc\",\"bar\":{\"foo\":\"xyz\"}}";
size_t bufferLength = sizeof( buffer ) - 1;
result = JSON_Validate( buffer, bufferLength );
// JSON document is valid.
assert( result == JSONSuccess );查找函数。
JSONStatus_t JSON_SearchT( char * buf,
size_t max,
const char * query,
size_t queryLength,
char ** outValue,
size_t * outValueLength,
JSONTypes_t * outType );在 JSON 文档中查找键或数组索引,并将指针 outValue 输出到其值,也输出找到的值的类型。
参数
[in]buf要搜索的缓冲区。
[in]缓冲区的最大大小。
[in]query要搜索的对象和数组的key名。
[in]queryLength 键的长度。
[out]outValue 指针,用于接收找到的值的地址。
[out]outValueLength用于接收找到的值的长度的指针。
[out]outType一个枚举,指示值的 JSON 特定类型。
类型如下:
enum JSONTypes_t {
JSONInvalid = 0 , JSONString , JSONNumber , JSONTrue ,
JSONFalse , JSONNull , JSONObject , JSONArray
}返回值同上。
成功时,指针 outValue 指向 buf 中的某个位置。没有对该值进行空终止。对于有效的 JSON,可以安全地在值的末尾放置一个空字符,只要在运行另一个搜索之前将替换的字符放回原处即可。也就是说这个指针outValue只是指向buf中的地址,并没有改变buf中的数据,所以不能直接使用outValue指针指向的数据,这个数据会一直持续到buf结束的字符。
注意:JSON_Search() 会执行验证,但在找到匹配的键及其值时停止。要验证整个 JSON 文档是否合法,请使用 JSON_Validate()。
查找函数:
#define JSON_Search( buf, max, query, queryLength, outValue, outValueLength ) \
JSON_SearchT( buf, max, query, queryLength, outValue, outValueLength, NULL )和上一个函数用法几乎一样,只是参数不同。
迭代函数:
JSONStatus_t JSON_Iterate( const char * buf,
size_t max,
size_t * start,
size_t * next,
JSONPair_t * outPair );输出集合中的下一个键值对或值。
该函数可以在循环中使用,以输出对象中的每个键值对,或数组中的每个值。对于第一次调用,start 和 next 指向的整数应初始化为 0。这些将由函数更新。如果存在另一个键值对或值,则填充输出结构并返回 JSONSuccess;否则结构不变并返回 JSONNotFound。
注意:该函数需要一个有效的 JSON 文档,需要首先运行 JSON_Validate()。
对于对象,outPair 结构将引用一个键及其值。对于数组,仅引用值(即 outPair.key 将为 NULL)。
官方例程:
// Variables used in this example.
static char * json_types[] =
{
"invalid",
"string",
"number",
"true",
"false",
"null",
"object",
"array"
};
void show( const char * json,
size_t length )
{
size_t start = 0, next = 0;
JSONPair_t pair = { 0 };
JSONStatus_t result;
result = JSON_Validate( json, length );
if( result == JSONSuccess )
{
result = JSON_Iterate( json, length, &start, &next, &pair );
}
while( result == JSONSuccess )
{
if( pair.key != NULL )
{
printf( "key: %.*s\t", ( int ) pair.keyLength, pair.key );
}
printf( "value: (%s) %.*s\n", json_types[ pair.jsonType ],
( int ) pair.valueLength, pair.value );
result = JSON_Iterate( json, length, &start, &next, &pair );
}
}使用示例
我们来自己写一个测试的程序,先准备一个打印返回值的函数。我们都在main文件中编写。
/* Private user code ---------------------------------------------------------*/
/* USER CODE BEGIN 0 */
int __io_putchar(int ch)
{
/* Implementation of __io_putchar */
/* e.g. write a character to the UART1 and Loop until the end of transmission */
HAL_UART_Transmit(&huart1, (uint8_t *)&ch, 1, 0xFFFFFFFF);
return ch;
}
int __io_getchar(void)
{
/* Implementation of __io_getchar */
char rxChar;
// This loops in case of HAL timeout, but if an ok or error occurs, we continue
while (HAL_UART_Receive(&huart1, (uint8_t *)&rxChar, 1, 0xFFFFFFFF) == HAL_TIMEOUT);
return rxChar;
}
char *result2str(JSONStatus_t ret) {
switch(ret) {
case JSONPartial:
return "JSONPartial";
case JSONSuccess:
return "JSONSuccess";
case JSONIllegalDocument:
return "JSONIllegalDocument";
case JSONMaxDepthExceeded:
return "JSONMaxDepthExceeded";
case JSONNotFound:
return "JSONNotFound";
case JSONNullParameter:
return "JSONNullParameter";
case JSONBadParameter:
return "JSONBadParameter";
};
}
/* USER CODE END 0 */写一个简单的测试程序。
/* USER CODE BEGIN 2 */
char *test = "{\"foo\":1,\"arr\":[1,2,3],\"obj\":{\"a\":1,\"b\":2}}"; // 包含对象和数组的json
char *test2 = "[\"a\",\"b\",\"c\",\"d\",\"e\"]"; // 只有数组
char *test3 = "HelloKitty"; // 无效的json
JSONStatus_t result; // 函数返回值
result = JSON_Validate( test, strlen(test) ); // 测试正常完整json的有效性
printf("teset: %s\r\n", result2str(result)); // 输出有效性测试结果
result = JSON_Validate( test2, strlen(test2) ); // 测试数组有效性
printf("teset2: %s\r\n", result2str(result)); // 输出测试结果
result = JSON_Validate( test3, strlen(test3) ); // 测试无效性
printf("teset3: %s\r\n", result2str(result)); // 输出测试结果
char * value;
size_t valueLength;
// 搜索字符串test中,长度为strlen(test),查找字符串"foo",长度为strlen("foo"),将查找到的值存入value中,并将valueLength设置为查找到的值的长度
JSON_Search(test, strlen(test), "foo", strlen("foo"), &value, &valueLength);
printf("foo: %.*s\r\n", valueLength, value); // 输出查找到的值
// 查找数组
JSON_Search(test, strlen(test), "arr", strlen("arr"), &value, &valueLength);
printf("arr: %.*s\r\n", valueLength, value); // 输出查找到的值
// 查找对象
JSON_Search(test, strlen(test), "obj", strlen("obj"), &value, &valueLength);
printf("obj: %.*s\r\n", valueLength, value); // 输出查找到的值
// 查找对象中的元素
JSON_Search(test, strlen(test), "obj.a", strlen("obj.a"), &value, &valueLength);
printf("obj.a: %.*s\r\n", valueLength, value); // 输出查找到的值
size_t start = 0, next = 0;
JSONPair_t pair = { 0 };
// 遍历json文档
result = JSON_Validate( test, strlen(test) );
if( result == JSONSuccess )
{
result = JSON_Iterate( test, strlen(test), &start, &next, &pair );
}
while( result == JSONSuccess )
{
if( pair.key != NULL )
{
printf( "key: %.*s\t", ( int ) pair.keyLength, pair.key );
}
printf( "value: %.*s\n", ( int ) pair.valueLength, pair.value );
result = JSON_Iterate( test, strlen(test), &start, &next, &pair );
}
// 遍历数组中的值
start = 0; next = 0;
result = JSON_Validate( test2, strlen(test2) );
if( result == JSONSuccess )
{
result = JSON_Iterate( test2, strlen(test2), &start, &next, &pair );
}
while( result == JSONSuccess )
{
printf( "arr[%d]: %.*s\n", next, ( int ) pair.valueLength, pair.value );
result = JSON_Iterate( test2, strlen(test2), &start, &next, &pair );
}
/* USER CODE END 2 */输出:
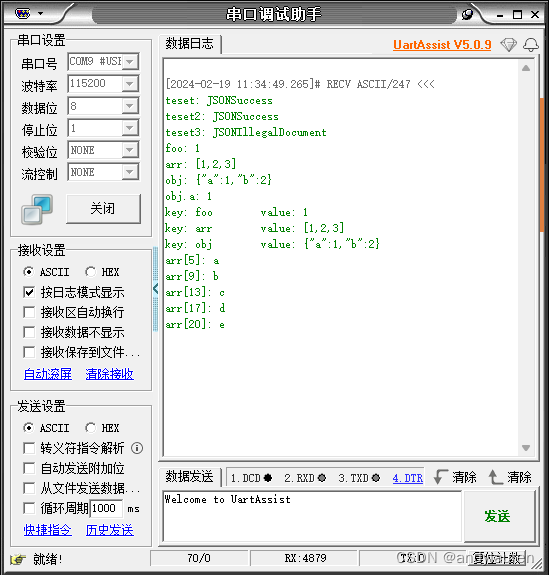
单元测试代码
要使用coreJSON的单元测试需要先集成unity,然后把下面的代码放到coreJSON文件夹中,最后在找个地方调用core_json_test_unity函数即可输出单元测试结果。
/*
* coreJSON v3.2.0
* Copyright (C) 2020 Amazon.com, Inc. or its affiliates. All Rights Reserved.
*
* SPDX-License-Identifier: MIT
*
* Permission is hereby granted, free of charge, to any person obtaining a copy of
* this software and associated documentation files (the "Software"), to deal in
* the Software without restriction, including without limitation the rights to
* use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of
* the Software, and to permit persons to whom the Software is furnished to do so,
* subject to the following conditions:
*
* The above copyright notice and this permission notice shall be included in all
* copies or substantial portions of the Software.
*
* THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
* IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS
* FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR
* COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER
* IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN
* CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
*/
/**
* @file core_json_utest.c
* @brief Unit tests for the coreJSON library.
*/
#include <string.h>
#include <stdlib.h>
#include <stdio.h>
#include <stdbool.h>
#include <stdint.h>
#include "unity.h"
#include "catch_assert.h"
/* Include paths for public enums, structures, and macros. */
#include "core_json.h"
#include "log.h"
#include "shell_port.h"
//#include "core_json_annex.h"
typedef union
{
char c;
uint8_t u;
} char_;
#if ( CHAR_MIN == 0 )
#define isascii_( x ) ( ( x ) <= '\x7F' )
#else
#define isascii_( x ) ( ( x ) >= '\0' )
#endif
#define iscntrl_( x ) ( isascii_( x ) && ( ( x ) < ' ' ) )
#define isdigit_( x ) ( ( ( x ) >= '0' ) && ( ( x ) <= '9' ) )
#define isOpenBracket_( x ) ( ( ( x ) == '{' ) || ( ( x ) == '[' ) )
#define isCloseBracket_( x ) ( ( ( x ) == '}' ) || ( ( x ) == ']' ) )
#define isCurlyPair_( x, y ) ( ( ( x ) == '{' ) && ( ( y ) == '}' ) )
#define isSquarePair_( x, y ) ( ( ( x ) == '[' ) && ( ( y ) == ']' ) )
#define isMatchingBracket_( x, y ) ( isCurlyPair_( x, y ) || isSquarePair_( x, y ) )
#define isSquareOpen_( x ) ( ( x ) == '[' )
#define isSquareClose_( x ) ( ( x ) == ']' )
/* Sample test from the docs. */
#define JSON_QUERY_SEPARATOR "."
#define FIRST_QUERY_KEY "bar"
#define FIRST_QUERY_KEY_LENGTH ( sizeof( FIRST_QUERY_KEY ) - 1 )
#define SECOND_QUERY_KEY "foo"
#define SECOND_QUERY_KEY_LENGTH ( sizeof( SECOND_QUERY_KEY ) - 1 )
#define COMPLETE_QUERY_KEY \
FIRST_QUERY_KEY \
JSON_QUERY_SEPARATOR \
SECOND_QUERY_KEY
#define COMPLETE_QUERY_KEY_LENGTH ( sizeof( COMPLETE_QUERY_KEY ) - 1 )
#define COMPLETE_QUERY_KEY_ANSWER "xyz"
#define COMPLETE_QUERY_KEY_ANSWER_TYPE JSONString
#define COMPLETE_QUERY_KEY_ANSWER_LENGTH ( sizeof( COMPLETE_QUERY_KEY_ANSWER ) - 1 )
#define FIRST_QUERY_KEY_ANSWER \
"{\"" SECOND_QUERY_KEY "\":\"" \
COMPLETE_QUERY_KEY_ANSWER "\"}"
#define FIRST_QUERY_KEY_ANSWER_TYPE JSONObject
#define FIRST_QUERY_KEY_ANSWER_LENGTH ( sizeof( FIRST_QUERY_KEY_ANSWER ) - 1 )
#define ARRAY_ELEMENT_0 "123"
#define ARRAY_ELEMENT_1 "456"
#define ARRAY_ELEMENT_2_SUB_0 "abc"
#define ARRAY_ELEMENT_2_SUB_1 "[88,99]"
#define ARRAY_ELEMENT_2_SUB_1_SUB_0 "88"
#define ARRAY_ELEMENT_2_SUB_1_SUB_1 "99"
#define ARRAY_ELEMENT_3 "true"
#define ARRAY_ELEMENT_4 "false"
#define ARRAY_ELEMENT_5 "null"
#define JSON_NESTED_OBJECT \
"{\"" FIRST_QUERY_KEY "\":\"" ARRAY_ELEMENT_2_SUB_0 "\",\"" \
SECOND_QUERY_KEY "\":" ARRAY_ELEMENT_2_SUB_1 "}"
#define JSON_NESTED_OBJECT_LENGTH ( sizeof( JSON_NESTED_OBJECT ) - 1 )
#define ARRAY_ELEMENT_2 JSON_NESTED_OBJECT
#define JSON_DOC_LEGAL_ARRAY \
"[" ARRAY_ELEMENT_0 "," ARRAY_ELEMENT_1 "," ARRAY_ELEMENT_2 "," \
ARRAY_ELEMENT_3 "," ARRAY_ELEMENT_4 "," ARRAY_ELEMENT_5 "]"
#define JSON_DOC_LEGAL_ARRAY_LENGTH ( sizeof( JSON_DOC_LEGAL_ARRAY ) - 1 )
#define ARRAY_ELEMENT_0_TYPE JSONNumber
#define ARRAY_ELEMENT_1_TYPE JSONNumber
#define ARRAY_ELEMENT_2_TYPE JSONObject
#define ARRAY_ELEMENT_2_SUB_0_TYPE JSONString
#define ARRAY_ELEMENT_2_SUB_1_TYPE JSONArray
#define ARRAY_ELEMENT_2_SUB_1_SUB_0_TYPE JSONNumber
#define ARRAY_ELEMENT_2_SUB_1_SUB_1_TYPE JSONNumber
#define ARRAY_ELEMENT_3_TYPE JSONTrue
#define ARRAY_ELEMENT_4_TYPE JSONFalse
#define ARRAY_ELEMENT_5_TYPE JSONNull
/* This JSON document covers all cases where scalars are exponents, literals, numbers, and decimals. */
#define JSON_DOC_VARIED_SCALARS \
"{\"literal\":true, \"more_literals\": {\"literal2\":false, \"literal3\":null}," \
"\"exp1\": 5E+3, \"more_exponents\": [5e+2,\t4e-2,\r93E-5, 128E-6],\n " \
"\"number\": -123412, " \
"\"decimal\":109238.42091289, " \
"\"foo\":\"abc\",\"" FIRST_QUERY_KEY "\":" FIRST_QUERY_KEY_ANSWER "}"
#define JSON_DOC_VARIED_SCALARS_LENGTH ( sizeof( JSON_DOC_VARIED_SCALARS ) - 1 )
#define MULTIPLE_VALID_ESCAPES "\\\\ \\\" \\/ \\b \\f \\n \\r \\t \\\x12"
#define MULTIPLE_VALID_ESCAPES_LENGTH ( sizeof( MULTIPLE_VALID_ESCAPES ) - 1 )
#define JSON_DOC_QUERY_KEY_NOT_FOUND "{\"hello\": \"world\"}"
#define JSON_DOC_QUERY_KEY_NOT_FOUND_LENGTH ( sizeof( JSON_DOC_QUERY_KEY_NOT_FOUND ) - 1 )
#define JSON_DOC_MULTIPLE_VALID_ESCAPES \
"{\"foo\":\"abc\",\"" FIRST_QUERY_KEY \
"\":{\"" SECOND_QUERY_KEY "\" :\t\"" MULTIPLE_VALID_ESCAPES "\"}}"
#define JSON_DOC_MULTIPLE_VALID_ESCAPES_LENGTH ( sizeof( JSON_DOC_MULTIPLE_VALID_ESCAPES ) - 1 )
/* A single byte in UTF-8 is just an ASCII character, so it's not included here. */
#define LEGAL_UTF8_BYTE_SEQUENCES "\xc2\xa9 \xe2\x98\x95 \xf0\x9f\x98\x80"
#define LEGAL_UTF8_BYTE_SEQUENCES_LENGTH ( sizeof( LEGAL_UTF8_BYTE_SEQUENCES ) - 1 )
#define JSON_DOC_LEGAL_UTF8_BYTE_SEQUENCES \
"{\"foo\":\"abc\",\"" FIRST_QUERY_KEY \
"\":{\"" SECOND_QUERY_KEY "\" : \"" LEGAL_UTF8_BYTE_SEQUENCES "\"}}"
#define JSON_DOC_LEGAL_UTF8_BYTE_SEQUENCES_LENGTH ( sizeof( JSON_DOC_LEGAL_UTF8_BYTE_SEQUENCES ) - 1 )
/* Unicode escape sequences in the Basic Multilingual Plane. */
#define UNICODE_ESCAPE_SEQUENCES_BMP "\\uCB00\\uEFFF"
#define UNICODE_ESCAPE_SEQUENCES_BMP_LENGTH ( sizeof( UNICODE_ESCAPE_SEQUENCES_BMP ) - 1 )
#define JSON_DOC_UNICODE_ESCAPE_SEQUENCES_BMP \
"{\"foo\":\"abc\",\"" FIRST_QUERY_KEY \
"\":{\"" SECOND_QUERY_KEY "\" : \"" UNICODE_ESCAPE_SEQUENCES_BMP "\"}}"
#define JSON_DOC_UNICODE_ESCAPE_SEQUENCES_BMP_LENGTH ( sizeof( JSON_DOC_UNICODE_ESCAPE_SEQUENCES_BMP ) - 1 )
/* Unicode escape sequences using surrogates for Astral Code Points (outside BMP). */
#define LEGAL_UNICODE_ESCAPE_SURROGATES "\\uD83D\\ude07"
#define LEGAL_UNICODE_ESCAPE_SURROGATES_LENGTH ( sizeof( LEGAL_UNICODE_ESCAPE_SURROGATES ) - 1 )
#define JSON_DOC_LEGAL_UNICODE_ESCAPE_SURROGATES \
"{\"foo\":\"abc\",\"" FIRST_QUERY_KEY \
"\":{\"" SECOND_QUERY_KEY "\" : \"" LEGAL_UNICODE_ESCAPE_SURROGATES "\"}}"
#define JSON_DOC_LEGAL_UNICODE_ESCAPE_SURROGATES_LENGTH ( sizeof( JSON_DOC_LEGAL_UNICODE_ESCAPE_SURROGATES ) - 1 )
#define JSON_DOC_LEGAL_TRAILING_SPACE \
"{\"foo\":\"abc\",\"" FIRST_QUERY_KEY \
"\":{\"" SECOND_QUERY_KEY "\" : \"" COMPLETE_QUERY_KEY_ANSWER "\"}} "
#define JSON_DOC_LEGAL_TRAILING_SPACE_LENGTH ( sizeof( JSON_DOC_LEGAL_TRAILING_SPACE ) - 1 )
/* A single scalar is still considered a valid JSON document. */
#define SINGLE_SCALAR "\"l33t\""
#define SINGLE_SCALAR_LENGTH ( sizeof( SINGLE_SCALAR ) - 1 )
/* Illegal scalar entry in the array. */
#define ILLEGAL_SCALAR_IN_ARRAY "{\"hello\": [42, world]\""
#define ILLEGAL_SCALAR_IN_ARRAY_LENGTH ( sizeof( ILLEGAL_SCALAR_IN_ARRAY ) - 1 )
#define ILLEGAL_SCALAR_IN_ARRAY2 "[42, world]"
#define ILLEGAL_SCALAR_IN_ARRAY2_LENGTH ( sizeof( ILLEGAL_SCALAR_IN_ARRAY2 ) - 1 )
#define TRAILING_COMMA_AFTER_VALUE \
"{\"foo\":\"abc\",\"" FIRST_QUERY_KEY \
"\":{\"" SECOND_QUERY_KEY "\" : \"" COMPLETE_QUERY_KEY_ANSWER "\",}}"
#define TRAILING_COMMA_AFTER_VALUE_LENGTH ( sizeof( TRAILING_COMMA_AFTER_VALUE ) - 1 )
#define MISSING_COMMA_AFTER_VALUE "{\"foo\":{}\"bar\":\"abc\"}"
#define MISSING_COMMA_AFTER_VALUE_LENGTH ( sizeof( MISSING_COMMA_AFTER_VALUE ) - 1 )
#define MISSING_VALUE_AFTER_KEY "{\"foo\":{\"bar\":}}"
#define MISSING_VALUE_AFTER_KEY_LENGTH ( sizeof( MISSING_VALUE_AFTER_KEY ) - 1 )
#define MISMATCHED_BRACKETS "{\"foo\":{\"bar\":\"xyz\"]}"
#define MISMATCHED_BRACKETS_LENGTH ( sizeof( MISMATCHED_BRACKETS ) - 1 )
#define MISMATCHED_BRACKETS2 "{\"foo\":[\"bar\",\"xyz\"}}"
#define MISMATCHED_BRACKETS2_LENGTH ( sizeof( MISMATCHED_BRACKETS2 ) - 1 )
#define MISMATCHED_BRACKETS3 "{\"foo\":[\"bar\",\"xyz\"]]"
#define MISMATCHED_BRACKETS3_LENGTH ( sizeof( MISMATCHED_BRACKETS3 ) - 1 )
#define MISMATCHED_BRACKETS4 "[\"foo\",\"bar\",\"xyz\"}"
#define MISMATCHED_BRACKETS4_LENGTH ( sizeof( MISMATCHED_BRACKETS4 ) - 1 )
#define INCORRECT_OBJECT_SEPARATOR "{\"foo\": \"bar\"; \"bar\": \"foo\"}"
#define INCORRECT_OBJECT_SEPARATOR_LENGTH ( sizeof( INCORRECT_OBJECT_SEPARATOR ) - 1 )
#define MISSING_ENCLOSING_ARRAY_MARKER \
"{\"foo\":\"abc\",\"" FIRST_QUERY_KEY \
"\":{\"" SECOND_QUERY_KEY "\" : []]}}"
#define MISSING_ENCLOSING_ARRAY_MARKER_LENGTH ( sizeof( MISSING_ENCLOSING_ARRAY_MARKER ) - 1 )
#define MISSING_ENCLOSING_OBJECT_MARKER \
"{\"foo\":\"abc\",\"" FIRST_QUERY_KEY \
"\":{\"" SECOND_QUERY_KEY "\" : \"" COMPLETE_QUERY_KEY_ANSWER "\"}"
#define MISSING_ENCLOSING_OBJECT_MARKER_LENGTH ( sizeof( MISSING_ENCLOSING_OBJECT_MARKER ) - 1 )
#define CUT_AFTER_OBJECT_OPEN_BRACE "{\"foo\":\"abc\",\"bar\":{"
#define CUT_AFTER_OBJECT_OPEN_BRACE_LENGTH ( sizeof( CUT_AFTER_OBJECT_OPEN_BRACE ) - 1 )
#define LEADING_ZEROS_IN_NUMBER \
"{\"foo\":\"abc\",\"" FIRST_QUERY_KEY \
"\":{\"" SECOND_QUERY_KEY "\" : 07}}"
#define LEADING_ZEROS_IN_NUMBER_LENGTH ( sizeof( LEADING_ZEROS_IN_NUMBER ) - 1 )
#define TRAILING_COMMA_IN_ARRAY "[{\"hello\": [\"foo\",]}]"
#define TRAILING_COMMA_IN_ARRAY_LENGTH ( sizeof( TRAILING_COMMA_IN_ARRAY ) - 1 )
#define CUT_AFTER_COMMA_SEPARATOR "{\"hello\": [5,"
#define CUT_AFTER_COMMA_SEPARATOR_LENGTH ( sizeof( CUT_AFTER_COMMA_SEPARATOR ) - 1 )
#define CLOSING_SQUARE_BRACKET "]"
#define CLOSING_SQUARE_BRACKET_LENGTH ( sizeof( CLOSING_SQUARE_BRACKET ) - 1 )
#define CLOSING_CURLY_BRACKET "}"
#define CLOSING_CURLY_BRACKET_LENGTH ( sizeof( CLOSING_CURLY_BRACKET ) - 1 )
#define OPENING_CURLY_BRACKET "{"
#define OPENING_CURLY_BRACKET_LENGTH ( sizeof( OPENING_CURLY_BRACKET ) - 1 )
#define QUERY_KEY_TRAILING_SEPARATOR FIRST_QUERY_KEY JSON_QUERY_SEPARATOR
#define QUERY_KEY_TRAILING_SEPARATOR_LENGTH ( sizeof( QUERY_KEY_TRAILING_SEPARATOR ) - 1 )
#define QUERY_KEY_EMPTY JSON_QUERY_SEPARATOR SECOND_QUERY_KEY
#define QUERY_KEY_EMPTY_LENGTH ( sizeof( QUERY_KEY_EMPTY ) - 1 )
/* Separator between a key and a value must be a colon (:). */
#define WRONG_KEY_VALUE_SEPARATOR \
"{\"foo\";\"abc\",\"" FIRST_QUERY_KEY \
"\":{\"" SECOND_QUERY_KEY "\":\"" COMPLETE_QUERY_KEY_ANSWER "\"}} "
#define WRONG_KEY_VALUE_SEPARATOR_LENGTH ( sizeof( WRONG_KEY_VALUE_SEPARATOR ) - 1 )
/* Key must be a string. */
#define ILLEGAL_KEY_NOT_STRING \
"{foo:\"abc\",\"" FIRST_QUERY_KEY \
"\":{\"" SECOND_QUERY_KEY "\" : \"" COMPLETE_QUERY_KEY_ANSWER "\"}}"
#define ILLEGAL_KEY_NOT_STRING_LENGTH ( sizeof( ILLEGAL_KEY_NOT_STRING ) - 1 )
/* A non-number after the exponent marker is illegal. */
#define LETTER_AS_EXPONENT \
"{\"foo\":\"abc\",\"" FIRST_QUERY_KEY \
"\":{\"" SECOND_QUERY_KEY "\" : 5Ea}}"
#define LETTER_AS_EXPONENT_LENGTH ( sizeof( LETTER_AS_EXPONENT ) - 1 )
/* The octet values C0, C1, and F5 to FF are illegal, since C0 and C1
* would introduce a non-shortest sequence, and F5 or above would
* introduce a value greater than the last code point, 0x10FFFF. */
#define ILLEGAL_UTF8_NEXT_BYTE \
"{\"foo\":\"abc\",\"" FIRST_QUERY_KEY \
"\":{\"" SECOND_QUERY_KEY "\" : \"\xc2\x00\"}}"
#define ILLEGAL_UTF8_NEXT_BYTE_LENGTH ( sizeof( ILLEGAL_UTF8_NEXT_BYTE ) - 1 )
/* The first byte in a UTF-8 sequence must be greater than C1. */
#define ILLEGAL_UTF8_START_C1 \
"{\"foo\":\"abc\",\"" FIRST_QUERY_KEY \
"\":{\"" SECOND_QUERY_KEY "\" : \"\xC1\"}}"
#define ILLEGAL_UTF8_START_C1_LENGTH ( sizeof( ILLEGAL_UTF8_START_C1 ) - 1 )
/* The first byte in a UTF-8 sequence must be less than F5. */
#define ILLEGAL_UTF8_START_F5 \
"{\"foo\":\"abc\",\"" FIRST_QUERY_KEY \
"\":{\"" SECOND_QUERY_KEY "\" : \"\xF5\"}}"
#define ILLEGAL_UTF8_START_F5_LENGTH ( sizeof( ILLEGAL_UTF8_START_F5 ) - 1 )
/* Additional bytes must match 10xxxxxx, so this case is illegal UTF8. */
#define ILLEGAL_UTF8_NEXT_BYTES \
"{\"foo\":\"abc\",\"" FIRST_QUERY_KEY \
"\":{\"" SECOND_QUERY_KEY "\" : \"\xc2\xC0\"}}"
#define ILLEGAL_UTF8_NEXT_BYTES_LENGTH ( sizeof( ILLEGAL_UTF8_NEXT_BYTES ) - 1 )
#define ILLEGAL_UTF8_SURROGATE_RANGE_MIN \
"{\"foo\":\"abc\",\"" FIRST_QUERY_KEY \
"\":{\"" SECOND_QUERY_KEY "\" : \"\xED\xA0\x80\"}}"
#define ILLEGAL_UTF8_SURROGATE_RANGE_MIN_LENGTH ( sizeof( ILLEGAL_UTF8_SURROGATE_RANGE_MIN ) - 1 )
#define ILLEGAL_UTF8_SURROGATE_RANGE_MAX \
"{\"foo\":\"abc\",\"" FIRST_QUERY_KEY \
"\":{\"" SECOND_QUERY_KEY "\" : \"\xED\xBF\xBF\"}}"
#define ILLEGAL_UTF8_SURROGATE_RANGE_MAX_LENGTH ( sizeof( ILLEGAL_UTF8_SURROGATE_RANGE_MAX ) - 1 )
#define ILLEGAL_UTF8_GT_MIN_CP_THREE_BYTES \
"{\"foo\":\"abc\",\"" FIRST_QUERY_KEY \
"\":{\"" SECOND_QUERY_KEY "\" : \"\xC2\x80\x80\"}}"
#define ILLEGAL_UTF8_GT_MIN_CP_THREE_BYTES_LENGTH ( sizeof( ILLEGAL_UTF8_GT_MIN_CP_THREE_BYTES ) - 1 )
#define ILLEGAL_UTF8_GT_MIN_CP_FOUR_BYTES \
"{\"foo\":\"abc\",\"" FIRST_QUERY_KEY \
"\":{\"" SECOND_QUERY_KEY "\" : \"\xF4\x9F\xBF\xBF\"}}"
#define ILLEGAL_UTF8_GT_MIN_CP_FOUR_BYTES_LENGTH ( sizeof( ILLEGAL_UTF8_GT_MIN_CP_FOUR_BYTES ) - 1 )
#define ILLEGAL_UTF8_LT_MAX_CP_FOUR_BYTES \
"{\"foo\":\"abc\",\"" FIRST_QUERY_KEY \
"\":{\"" SECOND_QUERY_KEY "\" : \"\xF0\x80\x80\x80\"}}"
#define ILLEGAL_UTF8_LT_MAX_CP_FOUR_BYTES_LENGTH ( sizeof( ILLEGAL_UTF8_LT_MAX_CP_FOUR_BYTES ) - 1 )
/* The following escapes are considered ILLEGAL. */
/* Hex characters must be used for the unicode escape sequence to be valid. */
#define ILLEGAL_UNICODE_LITERAL_HEX \
"{\"foo\":\"abc\",\"" FIRST_QUERY_KEY \
"\":{\"" SECOND_QUERY_KEY "\" : \"\\u\xD8\x3D\\u\xde\x07\"}}"
#define ILLEGAL_UNICODE_LITERAL_HEX_LENGTH ( sizeof( ILLEGAL_UNICODE_LITERAL_HEX ) - 1 )
#define UNICODE_PREMATURE_LOW_SURROGATE \
"{\"foo\":\"abc\",\"" FIRST_QUERY_KEY \
"\":{\"" SECOND_QUERY_KEY "\" : \"\\ude07\\uD83D\"}}"
#define UNICODE_PREMATURE_LOW_SURROGATE_LENGTH ( sizeof( UNICODE_PREMATURE_LOW_SURROGATE ) - 1 )
#define UNICODE_INVALID_LOWERCASE_HEX \
"{\"foo\":\"abc\",\"" FIRST_QUERY_KEY \
"\":{\"" SECOND_QUERY_KEY "\" : \"\\uge07\\uD83D\"}}"
#define UNICODE_INVALID_LOWERCASE_HEX_LENGTH ( sizeof( UNICODE_INVALID_LOWERCASE_HEX ) - 1 )
#define UNICODE_INVALID_UPPERCASE_HEX \
"{\"foo\":\"abc\",\"" FIRST_QUERY_KEY \
"\":{\"" SECOND_QUERY_KEY "\" : \"\\ude07\\uG83D\"}}"
#define UNICODE_INVALID_UPPERCASE_HEX_LENGTH ( sizeof( UNICODE_INVALID_UPPERCASE_HEX ) - 1 )
#define UNICODE_NON_LETTER_OR_DIGIT_HEX \
"{\"foo\":\"abc\",\"" FIRST_QUERY_KEY \
"\":{\"" SECOND_QUERY_KEY "\" : \"\\u\0e07\\uG83D\"}}"
#define UNICODE_NON_LETTER_OR_DIGIT_HEX_LENGTH ( sizeof( UNICODE_NON_LETTER_OR_DIGIT_HEX ) - 1 )
#define UNICODE_VALID_HIGH_NO_LOW_SURROGATE \
"{\"foo\":\"abc\",\"" FIRST_QUERY_KEY \
"\":{\"" SECOND_QUERY_KEY "\" : \"\\uD83D. Hello there!\"}}"
#define UNICODE_VALID_HIGH_NO_LOW_SURROGATE_LENGTH ( sizeof( UNICODE_VALID_HIGH_NO_LOW_SURROGATE ) - 1 )
#define UNICODE_WRONG_ESCAPE_AFTER_HIGH_SURROGATE \
"{\"foo\":\"abc\",\"" FIRST_QUERY_KEY \
"\":{\"" SECOND_QUERY_KEY "\" : \"\\uD83D\\Ude07\"}}"
#define UNICODE_WRONG_ESCAPE_AFTER_HIGH_SURROGATE_LENGTH ( sizeof( UNICODE_WRONG_ESCAPE_AFTER_HIGH_SURROGATE ) - 1 )
#define UNICODE_VALID_HIGH_INVALID_LOW_SURROGATE \
"{\"foo\":\"abc\",\"" FIRST_QUERY_KEY \
"\":{\"" SECOND_QUERY_KEY "\" : \"\\uD83D\\uEFFF\"}}"
#define UNICODE_VALID_HIGH_INVALID_LOW_SURROGATE_LENGTH ( sizeof( UNICODE_VALID_HIGH_INVALID_LOW_SURROGATE ) - 1 )
#define UNICODE_BOTH_SURROGATES_HIGH \
"{\"foo\":\"abc\",\"" FIRST_QUERY_KEY \
"\":{\"" SECOND_QUERY_KEY "\" : \"\\uD83D\\uD83D\"}}"
#define UNICODE_BOTH_SURROGATES_HIGH_LENGTH ( sizeof( UNICODE_BOTH_SURROGATES_HIGH ) - 1 )
/* For security, \u0000 is disallowed. */
#define UNICODE_ESCAPE_SEQUENCE_ZERO_CP \
"{\"foo\":\"abc\",\"" FIRST_QUERY_KEY \
"\":{\"" SECOND_QUERY_KEY "\" : \"\\u0000\"}}"
#define UNICODE_ESCAPE_SEQUENCE_ZERO_CP_LENGTH ( sizeof( UNICODE_ESCAPE_SEQUENCE_ZERO_CP ) - 1 )
/* /NUL escape is disallowed. */
#define NUL_ESCAPE \
"{\"foo\":\"abc\",\"" FIRST_QUERY_KEY \
"\":{\"" SECOND_QUERY_KEY "\" : \"\\\x0\"}}"
#define NUL_ESCAPE_LENGTH ( sizeof( NUL_ESCAPE ) - 1 )
#define ESCAPE_CHAR_ALONE \
"{\"foo\":\"abc\",\"" FIRST_QUERY_KEY \
"\":{\"" SECOND_QUERY_KEY "\" : \"\\\"}}"
#define ESCAPE_CHAR_ALONE_LENGTH ( sizeof( ESCAPE_CHAR_ALONE ) - 1 )
/* Valid control characters are those in the range of (NUL,SPACE).
* Therefore, both cases below are invalid. */
#define SPACE_CONTROL_CHAR \
"{\"foo\":\"abc\",\"" FIRST_QUERY_KEY \
"\":{\"" SECOND_QUERY_KEY "\" : \"\\ \"}}"
#define SPACE_CONTROL_CHAR_LENGTH ( sizeof( SPACE_CONTROL_CHAR ) - 1 )
/* \x80 implies a single one in the MSB, leading to a negative value. */
#define LT_ZERO_CONTROL_CHAR \
"{\"foo\":\"abc\",\"" FIRST_QUERY_KEY \
"\":{\"" SECOND_QUERY_KEY "\" : \"\\\x80 \"}}"
#define LT_ZERO_CONTROL_CHAR_LENGTH ( sizeof( LT_ZERO_CONTROL_CHAR ) - 1 )
/* An unescaped control character is considered ILLEGAL. */
#define UNESCAPED_CONTROL_CHAR \
"{\"foo\":\"abc\",\"" FIRST_QUERY_KEY \
"\":{\"" SECOND_QUERY_KEY "\" : \"\x15\"}}"
#define UNESCAPED_CONTROL_CHAR_LENGTH ( sizeof( UNESCAPED_CONTROL_CHAR ) - 1 )
/* Each skip function has a check that the iterator i has not exceeded the
* length of the buffer. The cases below test that those checks work as intended. */
/* Triggers the case in which i >= max for search. */
#define PADDED_OPENING_CURLY_BRACKET " { "
#define PADDED_OPENING_CURLY_BRACKET_LENGTH ( sizeof( PADDED_OPENING_CURLY_BRACKET ) - 1 )
/* Triggers the case in which i >= max for skipUTF8MultiByte.
* UTF-8 is illegal if the number of bytes in the sequence is
* less than what was expected from the first byte. */
#define CUT_AFTER_UTF8_FIRST_BYTE \
"{\"foo\":\"abc\",\"" FIRST_QUERY_KEY \
"\":{\"" SECOND_QUERY_KEY "\" : \"\xC2"
#define CUT_AFTER_UTF8_FIRST_BYTE_LENGTH ( sizeof( CUT_AFTER_UTF8_FIRST_BYTE ) - 1 )
/* Triggers the case in which end >= max for skipHexEscape. */
#define UNICODE_STRING_END_AFTER_HIGH_SURROGATE \
"{\"foo\":\"abc\",\"" FIRST_QUERY_KEY \
"\":{\"" SECOND_QUERY_KEY "\" : \"\\uD83D\"}}"
#define UNICODE_STRING_END_AFTER_HIGH_SURROGATE_LENGTH ( sizeof( UNICODE_STRING_END_AFTER_HIGH_SURROGATE ) - 1 )
/* Triggers the case in which i >= max for skipDigits. */
#define CUT_AFTER_NUMBER \
"{\"foo\":\"abc\",\"" FIRST_QUERY_KEY \
"\":{\"" SECOND_QUERY_KEY "\" : 1"
#define CUT_AFTER_NUMBER_LENGTH ( sizeof( CUT_AFTER_NUMBER ) - 1 )
/* Triggers the case in which i >= max for skipDecimals. */
#define CUT_AFTER_DECIMAL_POINT \
"{\"foo\":\"abc\",\"" FIRST_QUERY_KEY \
"\":{\"" SECOND_QUERY_KEY "\" : 1."
#define CUT_AFTER_DECIMAL_POINT_LENGTH ( sizeof( CUT_AFTER_DECIMAL_POINT ) - 1 )
/* Triggers the case in which ( i + 1U ) >= max for skipEscape. */
#define ESCAPE_CHAR_ALONE_NOT_ENCLOSED "\"\\"
#define ESCAPE_CHAR_ALONE_NOT_ENCLOSED_LENGTH ( sizeof( ESCAPE_CHAR_ALONE_NOT_ENCLOSED ) - 1 )
/* Triggers the case in which i >= max for skipExponent. */
#define CUT_AFTER_EXPONENT_MARKER "4e"
#define CUT_AFTER_EXPONENT_MARKER_LENGTH ( sizeof( CUT_AFTER_EXPONENT_MARKER ) - 1 )
/* Triggers the case in which i >= max for skipString. */
#define WHITE_SPACE " "
#define WHITE_SPACE_LENGTH ( sizeof( WHITE_SPACE ) - 1 )
/* Triggers the case in which i >= max for skipArrayScalars. */
#define CUT_AFTER_ARRAY_START_MARKER "{\"hello\": ["
#define CUT_AFTER_ARRAY_START_MARKER_LENGTH ( sizeof( CUT_AFTER_ARRAY_START_MARKER ) - 1 )
/* Triggers the cases in which i >= max for skipObjectScalars and nextKeyValuePair. */
#define CUT_AFTER_OBJECT_START_MARKER "{\"hello\": {"
#define CUT_AFTER_OBJECT_START_MARKER_LENGTH ( sizeof( CUT_AFTER_OBJECT_START_MARKER ) - 1 )
#define CUT_AFTER_KEY "{\"hello\""
#define CUT_AFTER_KEY_LENGTH ( sizeof( CUT_AFTER_KEY ) - 1 )
/* This prefix is used to generate multiple levels of nested objects. */
#define NESTED_OBJECT_PREFIX "{\"k\":"
#define NESTED_OBJECT_PREFIX_LENGTH ( sizeof( NESTED_OBJECT_PREFIX ) - 1 )
/* The value of the nested object with the largest depth. */
#define NESTED_OBJECT_VALUE "\"v\""
#define NESTED_OBJECT_VALUE_LENGTH ( sizeof( NESTED_OBJECT_VALUE ) - 1 )
#ifndef JSON_MAX_DEPTH
#define JSON_MAX_DEPTH 32
#endif
/* ============================ UNITY FIXTURES ============================ */
/* Called before each test method. */
void setUp()
{
}
/* Called after each test method. */
void tearDown()
{
}
/* Called at the beginning of the whole suite. */
void suiteSetUp()
{
}
/* Called at the end of the whole suite. */
int suiteTearDown( int numFailures )
{
return numFailures;
}
/* NB. This is whitespace as defined by the JSON standard (ECMA-404). */
#define isspace_( x ) \
( ( ( x ) == ' ' ) || ( ( x ) == '\t' ) || \
( ( x ) == '\n' ) || ( ( x ) == '\r' ) )
/**
* @brief Advance buffer index beyond whitespace.
*
* @param[in] buf The buffer to parse.
* @param[in,out] start The index at which to begin.
* @param[in] max The size of the buffer.
*/
static void skipSpace( const char * buf,
size_t * start,
size_t max )
{
size_t i = 0U;
assert( ( buf != NULL ) && ( start != NULL ) && ( max > 0U ) );
for( i = *start; i < max; i++ )
{
if( !isspace_( buf[ i ] ) )
{
break;
}
}
*start = i;
}
/**
* @brief Is the value a legal Unicode code point and encoded with
* the fewest bytes?
*
* The last Unicode code point is 0x10FFFF.
*
* Unicode 3.1 disallows UTF-8 interpretation of non-shortest form sequences.
* 1 byte encodes 0 through 7 bits
* 2 bytes encode 8 through 5+6 = 11 bits
* 3 bytes encode 12 through 4+6+6 = 16 bits
* 4 bytes encode 17 through 3+6+6+6 = 21 bits
*
* Unicode 3.2 disallows UTF-8 code point values in the surrogate range,
* [U+D800 to U+DFFF].
*
* @note Disallow ASCII, as this is called only for multibyte sequences.
*/
static bool shortestUTF8( size_t length,
uint32_t value )
{
bool ret = false;
uint32_t min = 0U, max = 0U;
assert( ( length >= 2U ) && ( length <= 4U ) );
switch( length )
{
case 2:
min = ( uint32_t ) 1 << 7U;
max = ( ( uint32_t ) 1 << 11U ) - 1U;
break;
case 3:
min = ( uint32_t ) 1 << 11U;
max = ( ( uint32_t ) 1 << 16U ) - 1U;
break;
default:
min = ( uint32_t ) 1 << 16U;
max = 0x10FFFFU;
break;
}
if( ( value >= min ) && ( value <= max ) &&
( ( value < 0xD800U ) || ( value > 0xDFFFU ) ) )
{
ret = true;
}
return ret;
}
/**
* @brief Count the leading 1s in a byte.
*
* The high-order 1 bits of the first byte in a UTF-8 encoding
* indicate the number of additional bytes to follow.
*
* @return the count
*/
static size_t countHighBits( uint8_t c )
{
uint8_t n = c;
size_t i = 0;
while( ( n & 0x80U ) != 0U )
{
i++;
n = ( n & 0x7FU ) << 1U;
}
return i;
}
/**
* @brief Advance buffer index beyond a UTF-8 code point.
*
* @param[in] buf The buffer to parse.
* @param[in,out] start The index at which to begin.
* @param[in] max The size of the buffer.
*
* @return true if a valid code point was present;
* false otherwise.
*
* 00-7F Single-byte character
* 80-BF Trailing byte
* C0-DF Leading byte of two-byte character
* E0-EF Leading byte of three-byte character
* F0-F7 Leading byte of four-byte character
* F8-FB Illegal (formerly leading byte of five-byte character)
* FC-FD Illegal (formerly leading byte of six-byte character)
* FE-FF Illegal
*
* The octet values C0, C1, and F5 to FF are illegal, since C0 and C1
* would introduce a non-shortest sequence, and F5 or above would
* introduce a value greater than the last code point, 0x10FFFF.
*/
static bool skipUTF8MultiByte( const char * buf,
size_t * start,
size_t max )
{
bool ret = false;
size_t i = 0U, bitCount = 0U, j = 0U;
uint32_t value = 0U;
char_ c = { 0 };
assert( ( buf != NULL ) && ( start != NULL ) && ( max > 0U ) );
i = *start;
assert( i < max );
assert( !isascii_( buf[ i ] ) );
c.c = buf[ i ];
if( ( c.u > 0xC1U ) && ( c.u < 0xF5U ) )
{
bitCount = countHighBits( c.u );
value = ( ( uint32_t ) c.u ) & ( ( ( uint32_t ) 1 << ( 7U - bitCount ) ) - 1U );
/* The bit count is 1 greater than the number of bytes,
* e.g., when j is 2, we skip one more byte. */
for( j = bitCount - 1U; j > 0U; j-- )
{
i++;
if( i >= max )
{
break;
}
c.c = buf[ i ];
/* Additional bytes must match 10xxxxxx. */
if( ( c.u & 0xC0U ) != 0x80U )
{
break;
}
value = ( value << 6U ) | ( c.u & 0x3FU );
}
if( ( j == 0U ) && ( shortestUTF8( bitCount, value ) == true ) )
{
*start = i + 1U;
ret = true;
}
}
return ret;
}
/**
* @brief Advance buffer index beyond an ASCII or UTF-8 code point.
*
* @param[in] buf The buffer to parse.
* @param[in,out] start The index at which to begin.
* @param[in] max The size of the buffer.
*
* @return true if a valid code point was present;
* false otherwise.
*/
static bool skipUTF8( const char * buf,
size_t * start,
size_t max )
{
bool ret = false;
assert( ( buf != NULL ) && ( start != NULL ) && ( max > 0U ) );
if( *start < max )
{
if( isascii_( buf[ *start ] ) )
{
*start += 1U;
ret = true;
}
else
{
ret = skipUTF8MultiByte( buf, start, max );
}
}
return ret;
}
/**
* @brief Convert a hexadecimal character to an integer.
*
* @param[in] c The character to convert.
*
* @return the integer value upon success or NOT_A_HEX_CHAR on failure.
*/
#define NOT_A_HEX_CHAR ( 0x10U )
static uint8_t hexToInt( char c )
{
char_ n = { 0 };
n.c = c;
if( ( c >= 'a' ) && ( c <= 'f' ) )
{
n.c -= 'a';
n.u += 10U;
}
else if( ( c >= 'A' ) && ( c <= 'F' ) )
{
n.c -= 'A';
n.u += 10U;
}
else if( isdigit_( c ) )
{
n.c -= '0';
}
else
{
n.u = NOT_A_HEX_CHAR;
}
return n.u;
}
/**
* @brief Advance buffer index beyond a single \u Unicode
* escape sequence and output the value.
*
* @param[in] buf The buffer to parse.
* @param[in,out] start The index at which to begin.
* @param[in] max The size of the buffer.
* @param[out] outValue The value of the hex digits.
*
* @return true if a valid escape sequence was present;
* false otherwise.
*
* @note For the sake of security, \u0000 is disallowed.
*/
static bool skipOneHexEscape( const char * buf,
size_t * start,
size_t max,
uint16_t * outValue )
{
bool ret = false;
size_t i = 0U, end = 0U;
uint16_t value = 0U;
assert( ( buf != NULL ) && ( start != NULL ) && ( max > 0U ) );
assert( outValue != NULL );
i = *start;
#define HEX_ESCAPE_LENGTH ( 6U ) /* e.g., \u1234 */
/* MISRA Ref 14.3.1 [Configuration dependent invariant] */
/* More details at: https://github.com/FreeRTOS/coreJSON/blob/main/MISRA.md#rule-143 */
/* coverity[misra_c_2012_rule_14_3_violation] */
end = ( i <= ( SIZE_MAX - HEX_ESCAPE_LENGTH ) ) ? ( i + HEX_ESCAPE_LENGTH ) : SIZE_MAX;
if( ( end < max ) && ( buf[ i ] == '\\' ) && ( buf[ i + 1U ] == 'u' ) )
{
for( i += 2U; i < end; i++ )
{
uint8_t n = hexToInt( buf[ i ] );
if( n == NOT_A_HEX_CHAR )
{
break;
}
value = ( value << 4U ) | n;
}
}
if( ( i == end ) && ( value > 0U ) )
{
ret = true;
*outValue = value;
*start = i;
}
return ret;
}
/**
* @brief Advance buffer index beyond one or a pair of \u Unicode escape sequences.
*
* @param[in] buf The buffer to parse.
* @param[in,out] start The index at which to begin.
* @param[in] max The size of the buffer.
*
* Surrogate pairs are two escape sequences that together denote
* a code point outside the Basic Multilingual Plane. They must
* occur as a pair with the first "high" value in [U+D800, U+DBFF],
* and the second "low" value in [U+DC00, U+DFFF].
*
* @return true if a valid escape sequence was present;
* false otherwise.
*
* @note For the sake of security, \u0000 is disallowed.
*/
#define isHighSurrogate( x ) ( ( ( x ) >= 0xD800U ) && ( ( x ) <= 0xDBFFU ) )
#define isLowSurrogate( x ) ( ( ( x ) >= 0xDC00U ) && ( ( x ) <= 0xDFFFU ) )
static bool skipHexEscape( const char * buf,
size_t * start,
size_t max )
{
bool ret = false;
size_t i = 0U;
uint16_t value = 0U;
assert( ( buf != NULL ) && ( start != NULL ) && ( max > 0U ) );
i = *start;
if( skipOneHexEscape( buf, &i, max, &value ) == true )
{
if( isHighSurrogate( value ) )
{
if( ( skipOneHexEscape( buf, &i, max, &value ) == true ) &&
( isLowSurrogate( value ) ) )
{
ret = true;
}
}
else if( isLowSurrogate( value ) )
{
/* premature low surrogate */
}
else
{
ret = true;
}
}
if( ret == true )
{
*start = i;
}
return ret;
}
/**
* @brief Advance buffer index beyond an escape sequence.
*
* @param[in] buf The buffer to parse.
* @param[in,out] start The index at which to begin.
* @param[in] max The size of the buffer.
*
* @return true if a valid escape sequence was present;
* false otherwise.
*
* @note For the sake of security, \NUL is disallowed.
*/
static bool skipEscape( const char * buf,
size_t * start,
size_t max )
{
bool ret = false;
size_t i = 0U;
assert( ( buf != NULL ) && ( start != NULL ) && ( max > 0U ) );
i = *start;
if( ( i < ( max - 1U ) ) && ( buf[ i ] == '\\' ) )
{
char c = buf[ i + 1U ];
switch( c )
{
case '\0':
break;
case 'u':
ret = skipHexEscape( buf, &i, max );
break;
case '"':
case '\\':
case '/':
case 'b':
case 'f':
case 'n':
case 'r':
case 't':
i += 2U;
ret = true;
break;
default:
/* a control character: (NUL,SPACE) */
if( iscntrl_( c ) )
{
i += 2U;
ret = true;
}
break;
}
}
if( ret == true )
{
*start = i;
}
return ret;
}
/**
* @brief Advance buffer index beyond a double-quoted string.
*
* @param[in] buf The buffer to parse.
* @param[in,out] start The index at which to begin.
* @param[in] max The size of the buffer.
*
* @return true if a valid string was present;
* false otherwise.
*/
static bool skipString( const char * buf,
size_t * start,
size_t max )
{
bool ret = false;
size_t i = 0;
assert( ( buf != NULL ) && ( start != NULL ) && ( max > 0U ) );
i = *start;
if( ( i < max ) && ( buf[ i ] == '"' ) )
{
i++;
while( i < max )
{
if( buf[ i ] == '"' )
{
ret = true;
i++;
break;
}
if( buf[ i ] == '\\' )
{
if( skipEscape( buf, &i, max ) != true )
{
break;
}
}
/* An unescaped control character is not allowed. */
else if( iscntrl_( buf[ i ] ) )
{
break;
}
else if( skipUTF8( buf, &i, max ) != true )
{
break;
}
else
{
/* MISRA 15.7 */
}
}
}
if( ret == true )
{
*start = i;
}
return ret;
}
/**
* @brief Compare the leading n bytes of two character sequences.
*
* @param[in] a first character sequence
* @param[in] b second character sequence
* @param[in] n number of bytes
*
* @return true if the sequences are the same;
* false otherwise
*/
static bool strnEq( const char * a,
const char * b,
size_t n )
{
size_t i = 0U;
assert( ( a != NULL ) && ( b != NULL ) );
for( i = 0; i < n; i++ )
{
if( a[ i ] != b[ i ] )
{
break;
}
}
return ( i == n ) ? true : false;
}
/**
* @brief Advance buffer index beyond a literal.
*
* @param[in] buf The buffer to parse.
* @param[in,out] start The index at which to begin.
* @param[in] max The size of the buffer.
* @param[in] literal The type of literal.
* @param[in] length The length of the literal.
*
* @return true if the literal was present;
* false otherwise.
*/
static bool skipLiteral( const char * buf,
size_t * start,
size_t max,
const char * literal,
size_t length )
{
bool ret = false;
assert( ( buf != NULL ) && ( start != NULL ) && ( max > 0U ) );
assert( literal != NULL );
if( ( *start < max ) && ( length <= ( max - *start ) ) )
{
ret = strnEq( &buf[ *start ], literal, length );
}
if( ret == true )
{
*start += length;
}
return ret;
}
/**
* @brief Advance buffer index beyond one or more digits.
* Optionally, output the integer value of the digits.
*
* @param[in] buf The buffer to parse.
* @param[in,out] start The index at which to begin.
* @param[in] max The size of the buffer.
* @param[out] outValue The integer value of the digits.
*
* @note outValue may be NULL. If not NULL, and the output
* exceeds ~2 billion, then -1 is output.
*
* @return true if a digit was present;
* false otherwise.
*/
#define MAX_FACTOR ( MAX_INDEX_VALUE / 10 )
static bool skipDigits( const char * buf,
size_t * start,
size_t max,
int32_t * outValue )
{
bool ret = false;
size_t i = 0U, saveStart = 0U;
int32_t value = 0U;
assert( ( buf != NULL ) && ( start != NULL ) && ( max > 0U ) );
saveStart = *start;
for( i = *start; i < max; i++ )
{
if( !isdigit_( buf[ i ] ) )
{
break;
}
if( ( outValue != NULL ) && ( value > -1 ) )
{
int8_t n = ( int8_t ) hexToInt( buf[ i ] );
if( value <= MAX_FACTOR )
{
value = ( value * 10 ) + n;
}
else
{
value = -1;
}
}
}
if( i > saveStart )
{
ret = true;
*start = i;
if( outValue != NULL )
{
*outValue = value;
}
}
return ret;
}
/**
* @brief Advance buffer index beyond the decimal portion of a number.
*
* @param[in] buf The buffer to parse.
* @param[in,out] start The index at which to begin.
* @param[in] max The size of the buffer.
*/
static void skipDecimals( const char * buf,
size_t * start,
size_t max )
{
size_t i = 0U;
assert( ( buf != NULL ) && ( start != NULL ) && ( max > 0U ) );
i = *start;
if( ( i < max ) && ( buf[ i ] == '.' ) )
{
i++;
if( skipDigits( buf, &i, max, NULL ) == true )
{
*start = i;
}
}
}
/**
* @brief Advance buffer index beyond the exponent portion of a number.
*
* @param[in] buf The buffer to parse.
* @param[in,out] start The index at which to begin.
* @param[in] max The size of the buffer.
*/
static void skipExponent( const char * buf,
size_t * start,
size_t max )
{
size_t i = 0U;
assert( ( buf != NULL ) && ( start != NULL ) && ( max > 0U ) );
i = *start;
if( ( i < max ) && ( ( buf[ i ] == 'e' ) || ( buf[ i ] == 'E' ) ) )
{
i++;
if( ( i < max ) && ( ( buf[ i ] == '-' ) || ( buf[ i ] == '+' ) ) )
{
i++;
}
if( skipDigits( buf, &i, max, NULL ) == true )
{
*start = i;
}
}
}
/**
* @brief Advance buffer index beyond a number.
*
* @param[in] buf The buffer to parse.
* @param[in,out] start The index at which to begin.
* @param[in] max The size of the buffer.
*
* @return true if a valid number was present;
* false otherwise.
*/
static bool skipNumber( const char * buf,
size_t * start,
size_t max )
{
bool ret = false;
size_t i = 0U;
assert( ( buf != NULL ) && ( start != NULL ) && ( max > 0U ) );
i = *start;
if( ( i < max ) && ( buf[ i ] == '-' ) )
{
i++;
}
if( i < max )
{
/* JSON disallows superfluous leading zeroes, so an
* initial zero must either be alone, or followed by
* a decimal or exponent.
*
* Should there be a digit after the zero, that digit
* will not be skipped by this function, and later parsing
* will judge this an illegal document. */
if( buf[ i ] == '0' )
{
ret = true;
i++;
}
else
{
ret = skipDigits( buf, &i, max, NULL );
}
}
if( ret == true )
{
skipDecimals( buf, &i, max );
skipExponent( buf, &i, max );
*start = i;
}
return ret;
}
/**
* @brief Advance buffer index beyond a JSON literal.
*
* @param[in] buf The buffer to parse.
* @param[in,out] start The index at which to begin.
* @param[in] max The size of the buffer.
*
* @return true if a valid literal was present;
* false otherwise.
*/
static bool skipAnyLiteral( const char * buf,
size_t * start,
size_t max )
{
bool ret = false;
#define skipLit_( x ) \
( skipLiteral( buf, start, max, ( x ), ( sizeof( x ) - 1UL ) ) == true )
if( skipLit_( "true" ) )
{
ret = true;
}
else if( skipLit_( "false" ) )
{
ret = true;
}
else if( skipLit_( "null" ) )
{
ret = true;
}
else
{
ret = false;
}
return ret;
}
/**
* @brief Advance buffer index beyond a scalar value.
*
* @param[in] buf The buffer to parse.
* @param[in,out] start The index at which to begin.
* @param[in] max The size of the buffer.
*
* @return true if a scalar value was present;
* false otherwise.
*/
static bool skipAnyScalar( const char * buf,
size_t * start,
size_t max )
{
bool ret = false;
if( skipString( buf, start, max ) == true )
{
ret = true;
}
else if( skipAnyLiteral( buf, start, max ) == true )
{
ret = true;
}
else if( skipNumber( buf, start, max ) == true )
{
ret = true;
}
else
{
ret = false;
}
return ret;
}
/**
* @brief Advance buffer index beyond a comma separator
* and surrounding whitespace.
*
* JSON uses a comma to separate values in an array and key-value
* pairs in an object. JSON does not permit a trailing comma.
*
* @param[in] buf The buffer to parse.
* @param[in,out] start The index at which to begin.
* @param[in] max The size of the buffer.
*
* @return true if a non-terminal comma was present;
* false otherwise.
*/
static bool skipSpaceAndComma( const char * buf,
size_t * start,
size_t max )
{
bool ret = false;
size_t i = 0U;
assert( ( buf != NULL ) && ( start != NULL ) && ( max > 0U ) );
skipSpace( buf, start, max );
i = *start;
if( ( i < max ) && ( buf[ i ] == ',' ) )
{
i++;
skipSpace( buf, &i, max );
if( ( i < max ) && !isCloseBracket_( buf[ i ] ) )
{
ret = true;
*start = i;
}
}
return ret;
}
/**
* @brief Advance buffer index beyond the scalar values of an array.
*
* @param[in] buf The buffer to parse.
* @param[in,out] start The index at which to begin.
* @param[in] max The size of the buffer.
*
* @note Stops advance if a value is an object or array.
*/
static void skipArrayScalars( const char * buf,
size_t * start,
size_t max )
{
size_t i = 0U;
assert( ( buf != NULL ) && ( start != NULL ) && ( max > 0U ) );
i = *start;
while( i < max )
{
if( skipAnyScalar( buf, &i, max ) != true )
{
break;
}
if( skipSpaceAndComma( buf, &i, max ) != true )
{
break;
}
}
*start = i;
}
/**
* @brief Advance buffer index beyond the scalar key-value pairs
* of an object.
*
* In JSON, objects consist of comma-separated key-value pairs.
* A key is always a string (a scalar) while a value may be a
* scalar, an object, or an array. A colon must appear between
* each key and value.
*
* @param[in] buf The buffer to parse.
* @param[in,out] start The index at which to begin.
* @param[in] max The size of the buffer.
*
* @note Stops advance if a value is an object or array.
*/
static void skipObjectScalars( const char * buf,
size_t * start,
size_t max )
{
size_t i = 0U;
bool comma = false;
assert( ( buf != NULL ) && ( start != NULL ) && ( max > 0U ) );
i = *start;
while( i < max )
{
if( skipString( buf, &i, max ) != true )
{
break;
}
skipSpace( buf, &i, max );
if( ( i < max ) && ( buf[ i ] != ':' ) )
{
break;
}
i++;
skipSpace( buf, &i, max );
if( ( i < max ) && isOpenBracket_( buf[ i ] ) )
{
*start = i;
break;
}
if( skipAnyScalar( buf, &i, max ) != true )
{
break;
}
comma = skipSpaceAndComma( buf, &i, max );
*start = i;
if( comma != true )
{
break;
}
}
}
/**
* @brief Advance buffer index beyond one or more scalars.
*
* @param[in] buf The buffer to parse.
* @param[in,out] start The index at which to begin.
* @param[in] max The size of the buffer.
* @param[in] mode The first character of an array '[' or object '{'.
*/
static void skipScalars( const char * buf,
size_t * start,
size_t max,
char mode )
{
assert( isOpenBracket_( mode ) );
skipSpace( buf, start, max );
if( mode == '[' )
{
skipArrayScalars( buf, start, max );
}
else
{
skipObjectScalars( buf, start, max );
}
}
/**
* @brief Advance buffer index beyond a collection and handle nesting.
*
* A stack is used to continue parsing the prior collection type
* when a nested collection is finished.
*
* @param[in] buf The buffer to parse.
* @param[in,out] start The index at which to begin.
* @param[in] max The size of the buffer.
*
* @return #JSONSuccess if the buffer contents are a valid JSON collection;
* #JSONIllegalDocument if the buffer contents are NOT valid JSON;
* #JSONMaxDepthExceeded if object and array nesting exceeds a threshold;
* #JSONPartial if the buffer contents are potentially valid but incomplete.
*/
#ifndef JSON_MAX_DEPTH
#define JSON_MAX_DEPTH 32
#endif
static JSONStatus_t skipCollection( const char * buf,
size_t * start,
size_t max )
{
JSONStatus_t ret = JSONPartial;
char c, stack[ JSON_MAX_DEPTH ];
int16_t depth = -1;
size_t i = 0U;
assert( ( buf != NULL ) && ( start != NULL ) && ( max > 0U ) );
i = *start;
while( i < max )
{
c = buf[ i ];
i++;
switch( c )
{
case '{':
case '[':
depth++;
if( depth >= JSON_MAX_DEPTH )
{
ret = JSONMaxDepthExceeded;
break;
}
stack[ depth ] = c;
skipScalars( buf, &i, max, stack[ depth ] );
break;
case '}':
case ']':
if( ( depth > 0 ) && ( depth < JSON_MAX_DEPTH ) &&
isMatchingBracket_( stack[ depth ], c ) )
{
depth--;
if( ( skipSpaceAndComma( buf, &i, max ) == true ) &&
isOpenBracket_( stack[ depth ] ) )
{
skipScalars( buf, &i, max, stack[ depth ] );
}
break;
}
ret = ( ( depth == 0 ) && isMatchingBracket_( stack[ depth ], c ) ) ?
JSONSuccess : JSONIllegalDocument;
break;
default:
ret = JSONIllegalDocument;
break;
}
if( ret != JSONPartial )
{
break;
}
}
if( ret == JSONSuccess )
{
*start = i;
}
return ret;
}
/**
* @brief Output index and length for the next value.
*
* Also advances the buffer index beyond the value.
* The value may be a scalar or a collection.
* The start index should point to the beginning of the value.
*
* @param[in] buf The buffer to parse.
* @param[in,out] start The index at which to begin.
* @param[in] max The size of the buffer.
* @param[out] value A pointer to receive the index of the value.
* @param[out] valueLength A pointer to receive the length of the value.
*
* @return true if a value was present;
* false otherwise.
*/
static bool nextValue( const char * buf,
size_t * start,
size_t max,
size_t * value,
size_t * valueLength )
{
bool ret = true;
size_t i = 0U, valueStart = 0U;
assert( ( buf != NULL ) && ( start != NULL ) && ( max > 0U ) );
assert( ( value != NULL ) && ( valueLength != NULL ) );
i = *start;
valueStart = i;
if( skipAnyScalar( buf, &i, max ) == true )
{
*value = valueStart;
*valueLength = i - valueStart;
}
else if( skipCollection( buf, &i, max ) == JSONSuccess )
{
*value = valueStart;
*valueLength = i - valueStart;
}
else
{
ret = false;
}
if( ret == true )
{
*start = i;
}
return ret;
}
/**
* @brief Output indexes for the next key-value pair of an object.
*
* Also advances the buffer index beyond the key-value pair.
* The value may be a scalar or a collection.
*
* @param[in] buf The buffer to parse.
* @param[in,out] start The index at which to begin.
* @param[in] max The size of the buffer.
* @param[out] key A pointer to receive the index of the key.
* @param[out] keyLength A pointer to receive the length of the key.
* @param[out] value A pointer to receive the index of the value.
* @param[out] valueLength A pointer to receive the length of the value.
*
* @return true if a key-value pair was present;
* false otherwise.
*/
static bool nextKeyValuePair( const char * buf,
size_t * start,
size_t max,
size_t * key,
size_t * keyLength,
size_t * value,
size_t * valueLength )
{
bool ret = true;
size_t i = 0U, keyStart = 0U;
assert( ( buf != NULL ) && ( start != NULL ) && ( max > 0U ) );
assert( ( key != NULL ) && ( keyLength != NULL ) );
assert( ( value != NULL ) && ( valueLength != NULL ) );
i = *start;
keyStart = i;
if( skipString( buf, &i, max ) == true )
{
*key = keyStart + 1U;
*keyLength = i - keyStart - 2U;
}
else
{
ret = false;
}
if( ret == true )
{
skipSpace( buf, &i, max );
if( ( i < max ) && ( buf[ i ] == ':' ) )
{
i++;
skipSpace( buf, &i, max );
}
else
{
ret = false;
}
}
if( ret == true )
{
ret = nextValue( buf, &i, max, value, valueLength );
}
if( ret == true )
{
*start = i;
}
return ret;
}
/**
* @brief Find a key in a JSON object and output a pointer to its value.
*
* @param[in] buf The buffer to search.
* @param[in] max size of the buffer.
* @param[in] query The object keys and array indexes to search for.
* @param[in] queryLength Length of the key.
* @param[out] outValue A pointer to receive the index of the value found.
* @param[out] outValueLength A pointer to receive the length of the value found.
*
* Iterate over the key-value pairs of an object, looking for a matching key.
*
* @return true if the query is matched and the value output;
* false otherwise.
*
* @note Parsing stops upon finding a match.
*/
static bool objectSearch( const char * buf,
size_t max,
const char * query,
size_t queryLength,
size_t * outValue,
size_t * outValueLength )
{
bool ret = false;
size_t i = 0U, key = 0U, keyLength = 0U, value = 0U, valueLength = 0U;
assert( ( buf != NULL ) && ( query != NULL ) );
assert( ( outValue != NULL ) && ( outValueLength != NULL ) );
skipSpace( buf, &i, max );
if( ( i < max ) && ( buf[ i ] == '{' ) )
{
i++;
skipSpace( buf, &i, max );
while( i < max )
{
if( nextKeyValuePair( buf, &i, max, &key, &keyLength,
&value, &valueLength ) != true )
{
break;
}
if( ( queryLength == keyLength ) &&
( strnEq( query, &buf[ key ], keyLength ) == true ) )
{
ret = true;
break;
}
if( skipSpaceAndComma( buf, &i, max ) != true )
{
break;
}
}
}
if( ret == true )
{
*outValue = value;
*outValueLength = valueLength;
}
return ret;
}
/**
* @brief Find an index in a JSON array and output a pointer to its value.
*
* @param[in] buf The buffer to search.
* @param[in] max size of the buffer.
* @param[in] queryIndex The index to search for.
* @param[out] outValue A pointer to receive the index of the value found.
* @param[out] outValueLength A pointer to receive the length of the value found.
*
* Iterate over the values of an array, looking for a matching index.
*
* @return true if the queryIndex is found and the value output;
* false otherwise.
*
* @note Parsing stops upon finding a match.
*/
static bool arraySearch( const char * buf,
size_t max,
uint32_t queryIndex,
size_t * outValue,
size_t * outValueLength )
{
bool ret = false;
size_t i = 0U, value = 0U, valueLength = 0U;
uint32_t currentIndex = 0U;
assert( buf != NULL );
assert( ( outValue != NULL ) && ( outValueLength != NULL ) );
skipSpace( buf, &i, max );
if( ( i < max ) && ( buf[ i ] == '[' ) )
{
i++;
skipSpace( buf, &i, max );
while( i < max )
{
if( nextValue( buf, &i, max, &value, &valueLength ) != true )
{
break;
}
if( currentIndex == queryIndex )
{
ret = true;
break;
}
if( ( skipSpaceAndComma( buf, &i, max ) != true ) ||
( currentIndex == UINT32_MAX ) )
{
break;
}
currentIndex++;
}
}
if( ret == true )
{
*outValue = value;
*outValueLength = valueLength;
}
return ret;
}
/**
* @brief Advance buffer index beyond a query part.
*
* The part is the portion of the query which is not
* a separator or array index.
*
* @param[in] buf The buffer to parse.
* @param[in,out] start The index at which to begin.
* @param[in] max The size of the buffer.
* @param[out] outLength The length of the query part.
*
* @return true if a valid string was present;
* false otherwise.
*/
#ifndef JSON_QUERY_KEY_SEPARATOR
#define JSON_QUERY_KEY_SEPARATOR '.'
#endif
#define isSeparator_( x ) ( ( x ) == JSON_QUERY_KEY_SEPARATOR )
static bool skipQueryPart( const char * buf,
size_t * start,
size_t max,
size_t * outLength )
{
bool ret = false;
size_t i = 0U;
assert( ( buf != NULL ) && ( start != NULL ) && ( outLength != NULL ) );
assert( max > 0U );
i = *start;
while( ( i < max ) &&
!isSeparator_( buf[ i ] ) &&
!isSquareOpen_( buf[ i ] ) )
{
i++;
}
if( i > *start )
{
ret = true;
*outLength = i - *start;
*start = i;
}
return ret;
}
/**
* @brief Handle a nested search by iterating over the parts of the query.
*
* @param[in] buf The buffer to search.
* @param[in] max size of the buffer.
* @param[in] query The object keys and array indexes to search for.
* @param[in] queryLength Length of the key.
* @param[out] outValue A pointer to receive the index of the value found.
* @param[out] outValueLength A pointer to receive the length of the value found.
*
* @return #JSONSuccess if the query is matched and the value output;
* #JSONBadParameter if the query is empty, or any part is empty,
* or an index is too large to convert;
* #JSONNotFound if the query is NOT found.
*
* @note Parsing stops upon finding a match.
*/
static JSONStatus_t multiSearch( const char * buf,
size_t max,
const char * query,
size_t queryLength,
size_t * outValue,
size_t * outValueLength )
{
JSONStatus_t ret = JSONSuccess;
size_t i = 0U, start = 0U, queryStart = 0U, value = 0U, length = max;
assert( ( buf != NULL ) && ( query != NULL ) );
assert( ( outValue != NULL ) && ( outValueLength != NULL ) );
assert( ( max > 0U ) && ( queryLength > 0U ) );
while( i < queryLength )
{
bool found = false;
if( isSquareOpen_( query[ i ] ) )
{
int32_t queryIndex = -1;
i++;
( void ) skipDigits( query, &i, queryLength, &queryIndex );
if( ( queryIndex < 0 ) ||
( i >= queryLength ) || !isSquareClose_( query[ i ] ) )
{
ret = JSONBadParameter;
break;
}
i++;
found = arraySearch( &buf[ start ], length, ( uint32_t ) queryIndex, &value, &length );
}
else
{
size_t keyLength = 0;
queryStart = i;
if( ( skipQueryPart( query, &i, queryLength, &keyLength ) != true ) ||
/* catch an empty key part or a trailing separator */
( i == ( queryLength - 1U ) ) )
{
ret = JSONBadParameter;
break;
}
found = objectSearch( &buf[ start ], length, &query[ queryStart ], keyLength, &value, &length );
}
if( found == false )
{
ret = JSONNotFound;
break;
}
start += value;
if( ( i < queryLength ) && isSeparator_( query[ i ] ) )
{
i++;
}
}
if( ret == JSONSuccess )
{
*outValue = start;
*outValueLength = length;
}
return ret;
}
/**
* @brief Output the next key-value pair or value from a collection.
*
* @param[in] buf The buffer to search.
* @param[in] max size of the buffer.
* @param[in] start The index at which the collection begins.
* @param[in,out] next The index at which to seek the next value.
* @param[out] outKey A pointer to receive the index of the value found.
* @param[out] outKeyLength A pointer to receive the length of the value found.
* @param[out] outValue A pointer to receive the index of the value found.
* @param[out] outValueLength A pointer to receive the length of the value found.
*
* @return #JSONSuccess if a value is output;
* #JSONIllegalDocument if the buffer does not begin with '[' or '{';
* #JSONNotFound if there are no further values in the collection.
*/
static JSONStatus_t iterate( const char * buf,
size_t max,
size_t * start,
size_t * next,
size_t * outKey,
size_t * outKeyLength,
size_t * outValue,
size_t * outValueLength )
{
JSONStatus_t ret = JSONNotFound;
bool found = false;
assert( ( buf != NULL ) && ( max > 0U ) );
assert( ( start != NULL ) && ( next != NULL ) );
assert( ( outKey != NULL ) && ( outKeyLength != NULL ) );
assert( ( outValue != NULL ) && ( outValueLength != NULL ) );
if( *start < max )
{
switch( buf[ *start ] )
{
case '[':
found = nextValue( buf, next, max, outValue, outValueLength );
if( found == true )
{
*outKey = 0;
*outKeyLength = 0;
}
break;
case '{':
found = nextKeyValuePair( buf, next, max, outKey, outKeyLength,
outValue, outValueLength );
break;
default:
ret = JSONIllegalDocument;
break;
}
}
if( found == true )
{
ret = JSONSuccess;
( void ) skipSpaceAndComma( buf, next, max );
}
return ret;
}
/* ========================================================================== */
/**
* @brief Create a nested JSON array that exceeds JSON_MAX_DEPTH.
*/
char * allocateMaxDepthArray( void )
{
size_t i, len = ( JSON_MAX_DEPTH + 1 ) * 2;
char * nestedArray;
nestedArray = malloc( sizeof( char ) * ( len + 1 ) );
for( i = 0; i < len / 2; i++ )
{
nestedArray[ i ] = '[';
nestedArray[ len - 1 - i ] = ']';
}
nestedArray[ len ] = '\0';
return nestedArray;
}
/**
* @brief Create a nested JSON object that exceeds JSON_MAX_DEPTH.
*/
char * allocateMaxDepthObject( void )
{
size_t i = 0, len = NESTED_OBJECT_VALUE_LENGTH +
( JSON_MAX_DEPTH + 1 ) * ( NESTED_OBJECT_PREFIX_LENGTH +
CLOSING_CURLY_BRACKET_LENGTH );
char * nestedObject, * nestedObjectCur;
nestedObject = malloc( sizeof( char ) * ( len + 1 ) );
nestedObjectCur = nestedObject;
while( i < ( JSON_MAX_DEPTH + 1 ) * NESTED_OBJECT_PREFIX_LENGTH )
{
memcpy( nestedObjectCur, NESTED_OBJECT_PREFIX, NESTED_OBJECT_PREFIX_LENGTH );
i += NESTED_OBJECT_PREFIX_LENGTH;
nestedObjectCur += NESTED_OBJECT_PREFIX_LENGTH;
}
memcpy( nestedObjectCur, NESTED_OBJECT_VALUE, NESTED_OBJECT_VALUE_LENGTH );
i += NESTED_OBJECT_VALUE_LENGTH;
nestedObjectCur += NESTED_OBJECT_VALUE_LENGTH;
/* This loop writes the correct number of closing brackets so long as there
* are JSON_MAX_DEPTH + 1 entries for each bracket accounted for in len. */
while( i < len )
{
*( nestedObjectCur++ ) = '}';
i++;
}
nestedObject[ len ] = '\0';
return nestedObject;
}
/**
* @brief Test that JSON_Validate is able to classify any null or bad parameters.
*/
void test_JSON_Validate_Invalid_Params( void )
{
JSONStatus_t jsonStatus;
jsonStatus = JSON_Validate( NULL, 0 );
TEST_ASSERT_EQUAL( JSONNullParameter, jsonStatus );
jsonStatus = JSON_Validate( JSON_DOC_LEGAL_TRAILING_SPACE,
0 );
TEST_ASSERT_EQUAL( JSONBadParameter, jsonStatus );
}
/**
* @brief Test that JSON_Validate is able to classify valid JSON correctly.
*/
void test_JSON_Validate_Legal_Documents( void )
{
JSONStatus_t jsonStatus;
jsonStatus = JSON_Validate( JSON_DOC_VARIED_SCALARS, JSON_DOC_VARIED_SCALARS_LENGTH );
TEST_ASSERT_EQUAL( JSONSuccess, jsonStatus );
jsonStatus = JSON_Validate( JSON_DOC_LEGAL_TRAILING_SPACE,
JSON_DOC_LEGAL_TRAILING_SPACE_LENGTH );
TEST_ASSERT_EQUAL( JSONSuccess, jsonStatus );
jsonStatus = JSON_Validate( JSON_DOC_MULTIPLE_VALID_ESCAPES,
JSON_DOC_MULTIPLE_VALID_ESCAPES_LENGTH );
TEST_ASSERT_EQUAL( JSONSuccess, jsonStatus );
jsonStatus = JSON_Validate( JSON_DOC_LEGAL_UTF8_BYTE_SEQUENCES,
JSON_DOC_LEGAL_UTF8_BYTE_SEQUENCES_LENGTH );
TEST_ASSERT_EQUAL( JSONSuccess, jsonStatus );
jsonStatus = JSON_Validate( JSON_DOC_LEGAL_UNICODE_ESCAPE_SURROGATES,
JSON_DOC_LEGAL_UNICODE_ESCAPE_SURROGATES_LENGTH );
TEST_ASSERT_EQUAL( JSONSuccess, jsonStatus );
jsonStatus = JSON_Validate( JSON_DOC_UNICODE_ESCAPE_SEQUENCES_BMP,
JSON_DOC_UNICODE_ESCAPE_SEQUENCES_BMP_LENGTH );
TEST_ASSERT_EQUAL( JSONSuccess, jsonStatus );
jsonStatus = JSON_Validate( JSON_DOC_LEGAL_ARRAY,
JSON_DOC_LEGAL_ARRAY_LENGTH );
TEST_ASSERT_EQUAL( JSONSuccess, jsonStatus );
}
/**
* @brief Test that JSON_Validate is able to classify an illegal JSON document correctly.
*/
void test_JSON_Validate_Illegal_Documents( void )
{
JSONStatus_t jsonStatus;
jsonStatus = JSON_Validate( INCORRECT_OBJECT_SEPARATOR,
INCORRECT_OBJECT_SEPARATOR_LENGTH );
TEST_ASSERT_EQUAL( JSONIllegalDocument, jsonStatus );
jsonStatus = JSON_Validate( ILLEGAL_KEY_NOT_STRING,
ILLEGAL_KEY_NOT_STRING_LENGTH );
TEST_ASSERT_EQUAL( JSONIllegalDocument, jsonStatus );
jsonStatus = JSON_Validate( WRONG_KEY_VALUE_SEPARATOR,
WRONG_KEY_VALUE_SEPARATOR_LENGTH );
TEST_ASSERT_EQUAL( JSONIllegalDocument, jsonStatus );
jsonStatus = JSON_Validate( TRAILING_COMMA_IN_ARRAY,
TRAILING_COMMA_IN_ARRAY_LENGTH );
TEST_ASSERT_EQUAL( JSONIllegalDocument, jsonStatus );
jsonStatus = JSON_Validate( CUT_AFTER_COMMA_SEPARATOR,
CUT_AFTER_COMMA_SEPARATOR_LENGTH );
TEST_ASSERT_EQUAL( JSONIllegalDocument, jsonStatus );
jsonStatus = JSON_Validate( CUT_AFTER_KEY,
CUT_AFTER_KEY_LENGTH );
TEST_ASSERT_EQUAL( JSONIllegalDocument, jsonStatus );
jsonStatus = JSON_Validate( TRAILING_COMMA_AFTER_VALUE,
TRAILING_COMMA_AFTER_VALUE_LENGTH );
TEST_ASSERT_EQUAL( JSONIllegalDocument, jsonStatus );
jsonStatus = JSON_Validate( MISSING_COMMA_AFTER_VALUE,
MISSING_COMMA_AFTER_VALUE_LENGTH );
TEST_ASSERT_EQUAL( JSONIllegalDocument, jsonStatus );
jsonStatus = JSON_Validate( MISSING_VALUE_AFTER_KEY,
MISSING_VALUE_AFTER_KEY_LENGTH );
TEST_ASSERT_EQUAL( JSONIllegalDocument, jsonStatus );
jsonStatus = JSON_Validate( MISMATCHED_BRACKETS,
MISMATCHED_BRACKETS_LENGTH );
TEST_ASSERT_EQUAL( JSONIllegalDocument, jsonStatus );
jsonStatus = JSON_Validate( MISMATCHED_BRACKETS2,
MISMATCHED_BRACKETS2_LENGTH );
TEST_ASSERT_EQUAL( JSONIllegalDocument, jsonStatus );
jsonStatus = JSON_Validate( MISMATCHED_BRACKETS3,
MISMATCHED_BRACKETS3_LENGTH );
TEST_ASSERT_EQUAL( JSONIllegalDocument, jsonStatus );
jsonStatus = JSON_Validate( MISMATCHED_BRACKETS4,
MISMATCHED_BRACKETS4_LENGTH );
TEST_ASSERT_EQUAL( JSONIllegalDocument, jsonStatus );
jsonStatus = JSON_Validate( NUL_ESCAPE, NUL_ESCAPE_LENGTH );
TEST_ASSERT_EQUAL( JSONIllegalDocument, jsonStatus );
jsonStatus = JSON_Validate( SPACE_CONTROL_CHAR, SPACE_CONTROL_CHAR_LENGTH );
TEST_ASSERT_EQUAL( JSONIllegalDocument, jsonStatus );
jsonStatus = JSON_Validate( LT_ZERO_CONTROL_CHAR, LT_ZERO_CONTROL_CHAR_LENGTH );
TEST_ASSERT_EQUAL( JSONIllegalDocument, jsonStatus );
jsonStatus = JSON_Validate( CLOSING_SQUARE_BRACKET,
CLOSING_SQUARE_BRACKET_LENGTH );
TEST_ASSERT_EQUAL( JSONIllegalDocument, jsonStatus );
jsonStatus = JSON_Validate( CLOSING_CURLY_BRACKET,
CLOSING_CURLY_BRACKET_LENGTH );
TEST_ASSERT_EQUAL( JSONIllegalDocument, jsonStatus );
jsonStatus = JSON_Validate( CUT_AFTER_EXPONENT_MARKER,
CUT_AFTER_EXPONENT_MARKER_LENGTH );
TEST_ASSERT_EQUAL( JSONIllegalDocument, jsonStatus );
jsonStatus = JSON_Validate( MISSING_ENCLOSING_ARRAY_MARKER,
MISSING_ENCLOSING_ARRAY_MARKER_LENGTH );
TEST_ASSERT_EQUAL( JSONIllegalDocument, jsonStatus );
jsonStatus = JSON_Validate( LETTER_AS_EXPONENT,
LETTER_AS_EXPONENT_LENGTH );
TEST_ASSERT_EQUAL( JSONIllegalDocument, jsonStatus );
jsonStatus = JSON_Validate( CUT_AFTER_DECIMAL_POINT,
CUT_AFTER_DECIMAL_POINT_LENGTH );
TEST_ASSERT_EQUAL( JSONIllegalDocument, jsonStatus );
jsonStatus = JSON_Validate( LEADING_ZEROS_IN_NUMBER,
LEADING_ZEROS_IN_NUMBER_LENGTH );
TEST_ASSERT_EQUAL( JSONIllegalDocument, jsonStatus );
jsonStatus = JSON_Validate( ILLEGAL_SCALAR_IN_ARRAY,
ILLEGAL_SCALAR_IN_ARRAY_LENGTH );
TEST_ASSERT_EQUAL( JSONIllegalDocument, jsonStatus );
jsonStatus = JSON_Validate( ESCAPE_CHAR_ALONE, ESCAPE_CHAR_ALONE_LENGTH );
TEST_ASSERT_EQUAL( JSONIllegalDocument, jsonStatus );
jsonStatus = JSON_Validate( ESCAPE_CHAR_ALONE_NOT_ENCLOSED,
ESCAPE_CHAR_ALONE_NOT_ENCLOSED_LENGTH );
TEST_ASSERT_EQUAL( JSONIllegalDocument, jsonStatus );
jsonStatus = JSON_Validate( UNESCAPED_CONTROL_CHAR,
UNESCAPED_CONTROL_CHAR_LENGTH );
TEST_ASSERT_EQUAL( JSONIllegalDocument, jsonStatus );
jsonStatus = JSON_Validate( ILLEGAL_UTF8_NEXT_BYTE,
ILLEGAL_UTF8_NEXT_BYTE_LENGTH );
TEST_ASSERT_EQUAL( JSONIllegalDocument, jsonStatus );
jsonStatus = JSON_Validate( ILLEGAL_UTF8_START_C1,
ILLEGAL_UTF8_START_C1_LENGTH );
TEST_ASSERT_EQUAL( JSONIllegalDocument, jsonStatus );
jsonStatus = JSON_Validate( ILLEGAL_UTF8_START_F5,
ILLEGAL_UTF8_START_F5_LENGTH );
TEST_ASSERT_EQUAL( JSONIllegalDocument, jsonStatus );
jsonStatus = JSON_Validate( CUT_AFTER_UTF8_FIRST_BYTE,
CUT_AFTER_UTF8_FIRST_BYTE_LENGTH );
TEST_ASSERT_EQUAL( JSONIllegalDocument, jsonStatus );
jsonStatus = JSON_Validate( ILLEGAL_UTF8_NEXT_BYTES,
ILLEGAL_UTF8_NEXT_BYTES_LENGTH );
TEST_ASSERT_EQUAL( JSONIllegalDocument, jsonStatus );
jsonStatus = JSON_Validate( ILLEGAL_UTF8_GT_MIN_CP_FOUR_BYTES,
ILLEGAL_UTF8_GT_MIN_CP_FOUR_BYTES_LENGTH );
TEST_ASSERT_EQUAL( JSONIllegalDocument, jsonStatus );
jsonStatus = JSON_Validate( ILLEGAL_UTF8_GT_MIN_CP_THREE_BYTES,
ILLEGAL_UTF8_GT_MIN_CP_THREE_BYTES_LENGTH );
TEST_ASSERT_EQUAL( JSONIllegalDocument, jsonStatus );
jsonStatus = JSON_Validate( ILLEGAL_UTF8_LT_MAX_CP_FOUR_BYTES,
ILLEGAL_UTF8_LT_MAX_CP_FOUR_BYTES_LENGTH );
TEST_ASSERT_EQUAL( JSONIllegalDocument, jsonStatus );
jsonStatus = JSON_Validate( ILLEGAL_UTF8_SURROGATE_RANGE_MIN,
ILLEGAL_UTF8_SURROGATE_RANGE_MIN_LENGTH );
TEST_ASSERT_EQUAL( JSONIllegalDocument, jsonStatus );
jsonStatus = JSON_Validate( ILLEGAL_UTF8_SURROGATE_RANGE_MAX,
ILLEGAL_UTF8_SURROGATE_RANGE_MAX_LENGTH );
TEST_ASSERT_EQUAL( JSONIllegalDocument, jsonStatus );
jsonStatus = JSON_Validate( ILLEGAL_UTF8_SURROGATE_RANGE_MAX,
ILLEGAL_UTF8_SURROGATE_RANGE_MAX_LENGTH );
TEST_ASSERT_EQUAL( JSONIllegalDocument, jsonStatus );
jsonStatus = JSON_Validate( ILLEGAL_UNICODE_LITERAL_HEX,
ILLEGAL_UNICODE_LITERAL_HEX_LENGTH );
TEST_ASSERT_EQUAL( JSONIllegalDocument, jsonStatus );
jsonStatus = JSON_Validate( UNICODE_VALID_HIGH_NO_LOW_SURROGATE,
UNICODE_VALID_HIGH_NO_LOW_SURROGATE_LENGTH );
TEST_ASSERT_EQUAL( JSONIllegalDocument, jsonStatus );
jsonStatus = JSON_Validate( UNICODE_WRONG_ESCAPE_AFTER_HIGH_SURROGATE,
UNICODE_WRONG_ESCAPE_AFTER_HIGH_SURROGATE_LENGTH );
TEST_ASSERT_EQUAL( JSONIllegalDocument, jsonStatus );
jsonStatus = JSON_Validate( UNICODE_STRING_END_AFTER_HIGH_SURROGATE,
UNICODE_STRING_END_AFTER_HIGH_SURROGATE_LENGTH );
TEST_ASSERT_EQUAL( JSONIllegalDocument, jsonStatus );
jsonStatus = JSON_Validate( UNICODE_PREMATURE_LOW_SURROGATE,
UNICODE_PREMATURE_LOW_SURROGATE_LENGTH );
TEST_ASSERT_EQUAL( JSONIllegalDocument, jsonStatus );
jsonStatus = JSON_Validate( UNICODE_INVALID_LOWERCASE_HEX,
UNICODE_INVALID_LOWERCASE_HEX_LENGTH );
TEST_ASSERT_EQUAL( JSONIllegalDocument, jsonStatus );
jsonStatus = JSON_Validate( UNICODE_INVALID_UPPERCASE_HEX,
UNICODE_INVALID_UPPERCASE_HEX_LENGTH );
TEST_ASSERT_EQUAL( JSONIllegalDocument, jsonStatus );
jsonStatus = JSON_Validate( UNICODE_NON_LETTER_OR_DIGIT_HEX,
UNICODE_NON_LETTER_OR_DIGIT_HEX_LENGTH );
TEST_ASSERT_EQUAL( JSONIllegalDocument, jsonStatus );
jsonStatus = JSON_Validate( UNICODE_BOTH_SURROGATES_HIGH,
UNICODE_BOTH_SURROGATES_HIGH_LENGTH );
TEST_ASSERT_EQUAL( JSONIllegalDocument, jsonStatus );
jsonStatus = JSON_Validate( UNICODE_ESCAPE_SEQUENCE_ZERO_CP,
UNICODE_ESCAPE_SEQUENCE_ZERO_CP_LENGTH );
TEST_ASSERT_EQUAL( JSONIllegalDocument, jsonStatus );
jsonStatus = JSON_Validate( UNICODE_VALID_HIGH_INVALID_LOW_SURROGATE,
UNICODE_VALID_HIGH_INVALID_LOW_SURROGATE_LENGTH );
TEST_ASSERT_EQUAL( JSONIllegalDocument, jsonStatus );
}
/**
* @brief Test that JSON_Validate is able to classify a partial JSON document correctly.
*/
void test_JSON_Validate_Partial_Documents( void )
{
JSONStatus_t jsonStatus;
jsonStatus = JSON_Validate( OPENING_CURLY_BRACKET,
OPENING_CURLY_BRACKET_LENGTH );
TEST_ASSERT_EQUAL( JSONPartial, jsonStatus );
jsonStatus = JSON_Validate( WHITE_SPACE, WHITE_SPACE_LENGTH );
TEST_ASSERT_EQUAL( JSONPartial, jsonStatus );
jsonStatus = JSON_Validate( CUT_AFTER_OBJECT_OPEN_BRACE,
CUT_AFTER_OBJECT_OPEN_BRACE_LENGTH );
TEST_ASSERT_EQUAL( JSONPartial, jsonStatus );
jsonStatus = JSON_Validate( CUT_AFTER_NUMBER,
CUT_AFTER_NUMBER_LENGTH );
TEST_ASSERT_EQUAL( JSONPartial, jsonStatus );
jsonStatus = JSON_Validate( CUT_AFTER_ARRAY_START_MARKER,
CUT_AFTER_ARRAY_START_MARKER_LENGTH );
TEST_ASSERT_EQUAL( JSONPartial, jsonStatus );
jsonStatus = JSON_Validate( CUT_AFTER_OBJECT_START_MARKER,
CUT_AFTER_OBJECT_START_MARKER_LENGTH );
TEST_ASSERT_EQUAL( JSONPartial, jsonStatus );
}
/**
* @brief Test that JSON_Search can find the right value given a query key.
*/
void test_JSON_Search_Legal_Documents( void )
{
JSONStatus_t jsonStatus;
char * outValue;
size_t outValueLength;
JSONTypes_t outType;
jsonStatus = JSON_SearchT( JSON_DOC_LEGAL_TRAILING_SPACE,
JSON_DOC_LEGAL_TRAILING_SPACE_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength,
&outType );
TEST_ASSERT_EQUAL( JSONSuccess, jsonStatus );
TEST_ASSERT_EQUAL( COMPLETE_QUERY_KEY_ANSWER_TYPE, outType );
TEST_ASSERT_EQUAL( outValueLength, COMPLETE_QUERY_KEY_ANSWER_LENGTH );
TEST_ASSERT_EQUAL_STRING_LEN( COMPLETE_QUERY_KEY_ANSWER,
outValue,
outValueLength );
jsonStatus = JSON_Search( JSON_DOC_LEGAL_TRAILING_SPACE,
JSON_DOC_LEGAL_TRAILING_SPACE_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONSuccess, jsonStatus );
TEST_ASSERT_EQUAL( outValueLength, COMPLETE_QUERY_KEY_ANSWER_LENGTH );
TEST_ASSERT_EQUAL_STRING_LEN( COMPLETE_QUERY_KEY_ANSWER,
outValue,
outValueLength );
jsonStatus = JSON_Search( JSON_DOC_VARIED_SCALARS,
JSON_DOC_VARIED_SCALARS_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONSuccess, jsonStatus );
TEST_ASSERT_EQUAL( COMPLETE_QUERY_KEY_ANSWER_LENGTH, outValueLength );
TEST_ASSERT_EQUAL_STRING_LEN( COMPLETE_QUERY_KEY_ANSWER,
outValue,
COMPLETE_QUERY_KEY_ANSWER_LENGTH );
jsonStatus = JSON_SearchT( JSON_DOC_VARIED_SCALARS,
JSON_DOC_VARIED_SCALARS_LENGTH,
FIRST_QUERY_KEY,
FIRST_QUERY_KEY_LENGTH,
&outValue,
&outValueLength,
&outType );
TEST_ASSERT_EQUAL( JSONSuccess, jsonStatus );
TEST_ASSERT_EQUAL( FIRST_QUERY_KEY_ANSWER_TYPE, outType );
TEST_ASSERT_EQUAL( FIRST_QUERY_KEY_ANSWER_LENGTH, outValueLength );
TEST_ASSERT_EQUAL_STRING_LEN( FIRST_QUERY_KEY_ANSWER,
outValue,
FIRST_QUERY_KEY_ANSWER_LENGTH );
jsonStatus = JSON_Search( JSON_DOC_MULTIPLE_VALID_ESCAPES,
JSON_DOC_MULTIPLE_VALID_ESCAPES_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONSuccess, jsonStatus );
TEST_ASSERT_EQUAL( MULTIPLE_VALID_ESCAPES_LENGTH, outValueLength );
TEST_ASSERT_EQUAL_STRING_LEN( MULTIPLE_VALID_ESCAPES,
outValue,
MULTIPLE_VALID_ESCAPES_LENGTH );
jsonStatus = JSON_Search( JSON_DOC_LEGAL_UTF8_BYTE_SEQUENCES,
JSON_DOC_LEGAL_UTF8_BYTE_SEQUENCES_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONSuccess, jsonStatus );
TEST_ASSERT_EQUAL( LEGAL_UTF8_BYTE_SEQUENCES_LENGTH, outValueLength );
TEST_ASSERT_EQUAL_STRING_LEN( LEGAL_UTF8_BYTE_SEQUENCES,
outValue,
LEGAL_UTF8_BYTE_SEQUENCES_LENGTH );
jsonStatus = JSON_Search( JSON_DOC_LEGAL_UNICODE_ESCAPE_SURROGATES,
JSON_DOC_LEGAL_UNICODE_ESCAPE_SURROGATES_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONSuccess, jsonStatus );
TEST_ASSERT_EQUAL( LEGAL_UNICODE_ESCAPE_SURROGATES_LENGTH, outValueLength );
TEST_ASSERT_EQUAL_STRING_LEN( LEGAL_UNICODE_ESCAPE_SURROGATES,
outValue,
LEGAL_UNICODE_ESCAPE_SURROGATES_LENGTH );
jsonStatus = JSON_Search( JSON_DOC_UNICODE_ESCAPE_SEQUENCES_BMP,
JSON_DOC_UNICODE_ESCAPE_SEQUENCES_BMP_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONSuccess, jsonStatus );
TEST_ASSERT_EQUAL( UNICODE_ESCAPE_SEQUENCES_BMP_LENGTH, outValueLength );
TEST_ASSERT_EQUAL_STRING_LEN( UNICODE_ESCAPE_SEQUENCES_BMP,
outValue,
UNICODE_ESCAPE_SEQUENCES_BMP_LENGTH );
}
/**
* @brief Test that JSON_Search can find the right value given a query key using arrays.
*/
void test_JSON_Search_Legal_Array_Documents( void )
{
JSONStatus_t jsonStatus;
char * outValue;
size_t outValueLength;
JSONTypes_t outType;
#define doSearch( query, type, answer ) \
jsonStatus = JSON_SearchT( JSON_DOC_LEGAL_ARRAY, \
JSON_DOC_LEGAL_ARRAY_LENGTH, \
( query ), \
( sizeof( query ) - 1 ), \
&outValue, \
&outValueLength, \
&outType ); \
TEST_ASSERT_EQUAL( JSONSuccess, jsonStatus ); \
TEST_ASSERT_EQUAL( type, outType ); \
TEST_ASSERT_EQUAL( outValueLength, ( sizeof( answer ) - 1 ) ); \
TEST_ASSERT_EQUAL_STRING_LEN( ( answer ), \
outValue, \
outValueLength );
doSearch( "[0]", ARRAY_ELEMENT_0_TYPE, ARRAY_ELEMENT_0 );
doSearch( "[1]", ARRAY_ELEMENT_1_TYPE, ARRAY_ELEMENT_1 );
doSearch( "[2]." FIRST_QUERY_KEY, ARRAY_ELEMENT_2_SUB_0_TYPE, ARRAY_ELEMENT_2_SUB_0 );
doSearch( "[2]." SECOND_QUERY_KEY, ARRAY_ELEMENT_2_SUB_1_TYPE, ARRAY_ELEMENT_2_SUB_1 );
doSearch( "[2]." SECOND_QUERY_KEY "[0]", ARRAY_ELEMENT_2_SUB_1_SUB_0_TYPE, ARRAY_ELEMENT_2_SUB_1_SUB_0 );
doSearch( "[2]." SECOND_QUERY_KEY "[1]", ARRAY_ELEMENT_2_SUB_1_SUB_1_TYPE, ARRAY_ELEMENT_2_SUB_1_SUB_1 );
doSearch( "[3]", ARRAY_ELEMENT_3_TYPE, ARRAY_ELEMENT_3 );
doSearch( "[4]", ARRAY_ELEMENT_4_TYPE, ARRAY_ELEMENT_4 );
doSearch( "[5]", ARRAY_ELEMENT_5_TYPE, ARRAY_ELEMENT_5 );
}
/**
* @brief Test that JSON_Iterate returns the given values from a JSON array.
*/
void test_JSON_Iterate_Legal_Array_Documents( void )
{
JSONStatus_t jsonStatus;
size_t start = 0, next = 0;
JSONPair_t pair = { 0 };
#define iterateArray( type, answer ) \
jsonStatus = JSON_Iterate( JSON_DOC_LEGAL_ARRAY, \
JSON_DOC_LEGAL_ARRAY_LENGTH, \
&start, \
&next, \
&pair ); \
TEST_ASSERT_EQUAL( JSONSuccess, jsonStatus ); \
TEST_ASSERT_EQUAL( NULL, pair.key ); \
TEST_ASSERT_EQUAL( 0, pair.keyLength ); \
TEST_ASSERT_EQUAL( type, pair.jsonType ); \
TEST_ASSERT_EQUAL( ( sizeof( answer ) - 1 ), pair.valueLength ); \
TEST_ASSERT_EQUAL_STRING_LEN( ( answer ), \
pair.value, \
pair.valueLength );
iterateArray( ARRAY_ELEMENT_0_TYPE, ARRAY_ELEMENT_0 );
iterateArray( ARRAY_ELEMENT_1_TYPE, ARRAY_ELEMENT_1 );
iterateArray( ARRAY_ELEMENT_2_TYPE, ARRAY_ELEMENT_2 );
iterateArray( ARRAY_ELEMENT_3_TYPE, ARRAY_ELEMENT_3 );
iterateArray( ARRAY_ELEMENT_4_TYPE, ARRAY_ELEMENT_4 );
iterateArray( ARRAY_ELEMENT_5_TYPE, ARRAY_ELEMENT_5 );
jsonStatus = JSON_Iterate( JSON_DOC_LEGAL_ARRAY,
JSON_DOC_LEGAL_ARRAY_LENGTH,
&start,
&next,
&pair );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
}
/**
* @brief Test that JSON_Iterate returns the given keys and values from a JSON object.
*/
void test_JSON_Iterate_Legal_Object_Documents( void )
{
JSONStatus_t jsonStatus;
size_t start = 0, next = 0;
JSONPair_t pair = { 0 };
#define iterateObject( key_, type, answer ) \
jsonStatus = JSON_Iterate( JSON_NESTED_OBJECT, \
JSON_NESTED_OBJECT_LENGTH, \
&start, \
&next, \
&pair ); \
TEST_ASSERT_EQUAL( JSONSuccess, jsonStatus ); \
TEST_ASSERT_EQUAL( ( sizeof( key_ ) - 1 ), pair.keyLength ); \
TEST_ASSERT_EQUAL_STRING_LEN( ( key_ ), \
pair.key, \
pair.keyLength ); \
TEST_ASSERT_EQUAL( type, pair.jsonType ); \
TEST_ASSERT_EQUAL( ( sizeof( answer ) - 1 ), pair.valueLength ); \
TEST_ASSERT_EQUAL_STRING_LEN( ( answer ), \
pair.value, \
pair.valueLength );
iterateObject( FIRST_QUERY_KEY, ARRAY_ELEMENT_2_SUB_0_TYPE, ARRAY_ELEMENT_2_SUB_0 );
iterateObject( SECOND_QUERY_KEY, ARRAY_ELEMENT_2_SUB_1_TYPE, ARRAY_ELEMENT_2_SUB_1 );
jsonStatus = JSON_Iterate( JSON_NESTED_OBJECT,
JSON_NESTED_OBJECT_LENGTH,
&start,
&next,
&pair );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
}
/**
* @brief Test that JSON_Iterate returns an error for an invalid collection.
*/
void test_JSON_Iterate_Illegal_Documents( void )
{
JSONStatus_t jsonStatus;
size_t start = 0, next = 0;
JSONPair_t pair = { 0 };
jsonStatus = JSON_Iterate( FIRST_QUERY_KEY,
FIRST_QUERY_KEY_LENGTH,
&start,
&next,
&pair );
TEST_ASSERT_EQUAL( JSONIllegalDocument, jsonStatus );
}
/**
* @brief Test that JSON_Search can returns JSONNotFound when a query key does
* not apply to a JSON document.
*/
void test_JSON_Search_Query_Key_Not_Found( void )
{
JSONStatus_t jsonStatus;
char * outValue;
size_t outValueLength;
jsonStatus = JSON_Search( JSON_DOC_QUERY_KEY_NOT_FOUND,
JSON_DOC_QUERY_KEY_NOT_FOUND_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( JSON_DOC_QUERY_KEY_NOT_FOUND,
JSON_DOC_QUERY_KEY_NOT_FOUND_LENGTH,
"[0]",
( sizeof( "[0]" ) - 1 ),
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( JSON_DOC_LEGAL_ARRAY,
JSON_DOC_LEGAL_ARRAY_LENGTH,
"[9]",
( sizeof( "[9]" ) - 1 ),
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( WHITE_SPACE,
WHITE_SPACE_LENGTH,
"[0]",
( sizeof( "[0]" ) - 1 ),
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( "[" WHITE_SPACE,
WHITE_SPACE_LENGTH + 1,
"[0]",
( sizeof( "[0]" ) - 1 ),
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( ILLEGAL_SCALAR_IN_ARRAY2,
ILLEGAL_SCALAR_IN_ARRAY2_LENGTH,
"[1]",
( sizeof( "[1]" ) - 1 ),
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
}
/**
* @brief Test that JSON_Search can find the right value given an incorrect query
* key or Illegal JSON string.
*/
void test_JSON_Search_Illegal_Documents( void )
{
JSONStatus_t jsonStatus;
char * outValue;
size_t outValueLength;
jsonStatus = JSON_Search( WHITE_SPACE,
WHITE_SPACE_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( PADDED_OPENING_CURLY_BRACKET,
PADDED_OPENING_CURLY_BRACKET_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( CUT_AFTER_OBJECT_OPEN_BRACE,
CUT_AFTER_OBJECT_OPEN_BRACE_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( CLOSING_CURLY_BRACKET,
CLOSING_CURLY_BRACKET_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( OPENING_CURLY_BRACKET,
OPENING_CURLY_BRACKET_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( CLOSING_SQUARE_BRACKET,
CLOSING_SQUARE_BRACKET_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( INCORRECT_OBJECT_SEPARATOR,
INCORRECT_OBJECT_SEPARATOR_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( ILLEGAL_KEY_NOT_STRING,
ILLEGAL_KEY_NOT_STRING_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( WRONG_KEY_VALUE_SEPARATOR,
WRONG_KEY_VALUE_SEPARATOR_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( CUT_AFTER_KEY,
CUT_AFTER_KEY_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( TRAILING_COMMA_IN_ARRAY,
TRAILING_COMMA_IN_ARRAY_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( CUT_AFTER_COMMA_SEPARATOR,
CUT_AFTER_COMMA_SEPARATOR_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( TRAILING_COMMA_AFTER_VALUE,
TRAILING_COMMA_AFTER_VALUE_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( NUL_ESCAPE,
NUL_ESCAPE_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( SPACE_CONTROL_CHAR,
SPACE_CONTROL_CHAR_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( LT_ZERO_CONTROL_CHAR,
LT_ZERO_CONTROL_CHAR_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( CLOSING_CURLY_BRACKET,
CLOSING_CURLY_BRACKET_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( MISSING_ENCLOSING_ARRAY_MARKER,
MISSING_ENCLOSING_ARRAY_MARKER_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( LETTER_AS_EXPONENT,
LETTER_AS_EXPONENT_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( CUT_AFTER_DECIMAL_POINT,
CUT_AFTER_DECIMAL_POINT_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( LEADING_ZEROS_IN_NUMBER,
LEADING_ZEROS_IN_NUMBER_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( ILLEGAL_SCALAR_IN_ARRAY,
ILLEGAL_SCALAR_IN_ARRAY_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( ESCAPE_CHAR_ALONE,
ESCAPE_CHAR_ALONE_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( UNESCAPED_CONTROL_CHAR,
UNESCAPED_CONTROL_CHAR_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( ILLEGAL_UTF8_NEXT_BYTE,
ILLEGAL_UTF8_NEXT_BYTE_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( ILLEGAL_UTF8_START_C1,
ILLEGAL_UTF8_START_C1_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( ILLEGAL_UTF8_START_F5,
ILLEGAL_UTF8_START_F5_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( CUT_AFTER_UTF8_FIRST_BYTE,
CUT_AFTER_UTF8_FIRST_BYTE_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( ILLEGAL_UTF8_NEXT_BYTES,
ILLEGAL_UTF8_NEXT_BYTES_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( ILLEGAL_UTF8_GT_MIN_CP_FOUR_BYTES,
ILLEGAL_UTF8_GT_MIN_CP_FOUR_BYTES_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( ILLEGAL_UTF8_GT_MIN_CP_THREE_BYTES,
ILLEGAL_UTF8_GT_MIN_CP_THREE_BYTES_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( ILLEGAL_UTF8_LT_MAX_CP_FOUR_BYTES,
ILLEGAL_UTF8_LT_MAX_CP_FOUR_BYTES_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( ILLEGAL_UTF8_SURROGATE_RANGE_MIN,
ILLEGAL_UTF8_SURROGATE_RANGE_MIN_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( ILLEGAL_UTF8_SURROGATE_RANGE_MAX,
ILLEGAL_UTF8_SURROGATE_RANGE_MAX_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( ILLEGAL_UTF8_SURROGATE_RANGE_MAX,
ILLEGAL_UTF8_SURROGATE_RANGE_MAX_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( ILLEGAL_UNICODE_LITERAL_HEX,
ILLEGAL_UNICODE_LITERAL_HEX_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( UNICODE_VALID_HIGH_NO_LOW_SURROGATE,
UNICODE_VALID_HIGH_NO_LOW_SURROGATE_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( UNICODE_WRONG_ESCAPE_AFTER_HIGH_SURROGATE,
UNICODE_WRONG_ESCAPE_AFTER_HIGH_SURROGATE_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( UNICODE_STRING_END_AFTER_HIGH_SURROGATE,
UNICODE_STRING_END_AFTER_HIGH_SURROGATE_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( UNICODE_PREMATURE_LOW_SURROGATE,
UNICODE_PREMATURE_LOW_SURROGATE_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( UNICODE_INVALID_LOWERCASE_HEX,
UNICODE_INVALID_LOWERCASE_HEX_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( UNICODE_INVALID_UPPERCASE_HEX,
UNICODE_INVALID_UPPERCASE_HEX_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( UNICODE_NON_LETTER_OR_DIGIT_HEX,
UNICODE_NON_LETTER_OR_DIGIT_HEX_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( UNICODE_BOTH_SURROGATES_HIGH,
UNICODE_BOTH_SURROGATES_HIGH_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( UNICODE_ESCAPE_SEQUENCE_ZERO_CP,
UNICODE_ESCAPE_SEQUENCE_ZERO_CP_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( UNICODE_VALID_HIGH_INVALID_LOW_SURROGATE,
UNICODE_VALID_HIGH_INVALID_LOW_SURROGATE_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
}
/**
* @brief Test that JSON_Search is able to classify any null or bad parameters.
*/
void test_JSON_Search_Invalid_Params( void )
{
JSONStatus_t jsonStatus;
char * outValue;
size_t outValueLength;
jsonStatus = JSON_Search( NULL,
0,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNullParameter, jsonStatus );
jsonStatus = JSON_Search( JSON_DOC_VARIED_SCALARS,
JSON_DOC_VARIED_SCALARS_LENGTH,
NULL,
0,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNullParameter, jsonStatus );
jsonStatus = JSON_Search( JSON_DOC_VARIED_SCALARS,
JSON_DOC_VARIED_SCALARS_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
NULL,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNullParameter, jsonStatus );
jsonStatus = JSON_Search( JSON_DOC_VARIED_SCALARS,
JSON_DOC_VARIED_SCALARS_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
NULL );
TEST_ASSERT_EQUAL( JSONNullParameter, jsonStatus );
jsonStatus = JSON_Search( JSON_DOC_VARIED_SCALARS,
0,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONBadParameter, jsonStatus );
jsonStatus = JSON_Search( JSON_DOC_VARIED_SCALARS,
JSON_DOC_VARIED_SCALARS_LENGTH,
COMPLETE_QUERY_KEY,
0,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONBadParameter, jsonStatus );
jsonStatus = JSON_Search( JSON_DOC_VARIED_SCALARS,
JSON_DOC_VARIED_SCALARS_LENGTH,
QUERY_KEY_TRAILING_SEPARATOR,
QUERY_KEY_TRAILING_SEPARATOR_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONBadParameter, jsonStatus );
jsonStatus = JSON_Search( JSON_DOC_VARIED_SCALARS,
JSON_DOC_VARIED_SCALARS_LENGTH,
QUERY_KEY_EMPTY,
QUERY_KEY_EMPTY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONBadParameter, jsonStatus );
jsonStatus = JSON_Search( JSON_DOC_VARIED_SCALARS,
JSON_DOC_VARIED_SCALARS_LENGTH,
"[",
( sizeof( "[" ) - 1 ),
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONBadParameter, jsonStatus );
jsonStatus = JSON_Search( JSON_DOC_VARIED_SCALARS,
JSON_DOC_VARIED_SCALARS_LENGTH,
"[0",
( sizeof( "[0" ) - 1 ),
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONBadParameter, jsonStatus );
jsonStatus = JSON_Search( JSON_DOC_VARIED_SCALARS,
JSON_DOC_VARIED_SCALARS_LENGTH,
"[0}",
( sizeof( "[0}" ) - 1 ),
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONBadParameter, jsonStatus );
}
/**
* @brief Test that JSON_Iterate is able to classify any null or bad parameters.
*/
void test_JSON_Iterate_Invalid_Params( void )
{
JSONStatus_t jsonStatus;
size_t start = 0, next = 0;
JSONPair_t pair = { 0 };
jsonStatus = JSON_Iterate( NULL,
JSON_DOC_LEGAL_ARRAY_LENGTH,
&start,
&next,
&pair );
TEST_ASSERT_EQUAL( JSONNullParameter, jsonStatus );
jsonStatus = JSON_Iterate( JSON_DOC_LEGAL_ARRAY,
0,
&start,
&next,
&pair );
TEST_ASSERT_EQUAL( JSONBadParameter, jsonStatus );
jsonStatus = JSON_Iterate( JSON_DOC_LEGAL_ARRAY,
JSON_DOC_LEGAL_ARRAY_LENGTH,
NULL,
&next,
&pair );
TEST_ASSERT_EQUAL( JSONNullParameter, jsonStatus );
jsonStatus = JSON_Iterate( JSON_DOC_LEGAL_ARRAY,
JSON_DOC_LEGAL_ARRAY_LENGTH,
&start,
NULL,
&pair );
TEST_ASSERT_EQUAL( JSONNullParameter, jsonStatus );
jsonStatus = JSON_Iterate( JSON_DOC_LEGAL_ARRAY,
JSON_DOC_LEGAL_ARRAY_LENGTH,
&start,
&next,
NULL );
TEST_ASSERT_EQUAL( JSONNullParameter, jsonStatus );
start = JSON_DOC_LEGAL_ARRAY_LENGTH + 1;
jsonStatus = JSON_Iterate( JSON_DOC_LEGAL_ARRAY,
JSON_DOC_LEGAL_ARRAY_LENGTH,
&start,
&next,
&pair );
TEST_ASSERT_EQUAL( JSONBadParameter, jsonStatus );
start = 0;
next = JSON_DOC_LEGAL_ARRAY_LENGTH + 1;
jsonStatus = JSON_Iterate( JSON_DOC_LEGAL_ARRAY,
JSON_DOC_LEGAL_ARRAY_LENGTH,
&start,
&next,
&pair );
TEST_ASSERT_EQUAL( JSONBadParameter, jsonStatus );
}
/**
* @brief Test that JSON_Search is able to classify a partial JSON document correctly.
*
* @note JSON_Search returns JSONIllegalDocument when it finds a partial document.
*/
void test_JSON_Search_Partial_Documents( void )
{
JSONStatus_t jsonStatus;
char * outValue;
size_t outValueLength;
jsonStatus = JSON_Search( CUT_AFTER_NUMBER,
CUT_AFTER_NUMBER_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( CUT_AFTER_ARRAY_START_MARKER,
CUT_AFTER_ARRAY_START_MARKER_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( CUT_AFTER_OBJECT_START_MARKER,
CUT_AFTER_OBJECT_START_MARKER_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
jsonStatus = JSON_Search( CUT_AFTER_KEY,
CUT_AFTER_KEY_LENGTH,
COMPLETE_QUERY_KEY,
COMPLETE_QUERY_KEY_LENGTH,
&outValue,
&outValueLength );
TEST_ASSERT_EQUAL( JSONNotFound, jsonStatus );
}
/**
* @brief Test that a nested collection can only have up to JSON_MAX_DEPTH levels
* of nesting.
*/
void test_JSON_Max_Depth( void )
{
JSONStatus_t jsonStatus;
char * maxNestedObject, * maxNestedArray;
maxNestedArray = allocateMaxDepthArray();
jsonStatus = JSON_Validate( maxNestedArray,
strlen( maxNestedArray ) );
TEST_ASSERT_EQUAL( JSONMaxDepthExceeded, jsonStatus );
maxNestedObject = allocateMaxDepthObject();
jsonStatus = JSON_Validate( maxNestedObject,
strlen( maxNestedObject ) );
TEST_ASSERT_EQUAL( JSONMaxDepthExceeded, jsonStatus );
free( maxNestedArray );
free( maxNestedObject );
}
/**
* @brief Trip all asserts in internal functions.
*/
void test_JSON_asserts( void )
{
char buf[] = "x", queryKey[] = "y";
size_t start = 1, max = 1, length = 1, next = 0;
uint16_t u = 0;
size_t key, keyLength, value, valueLength;
int32_t queryIndex = 0;
catch_assert( skipSpace( NULL, &start, max ) );
catch_assert( skipSpace( buf, NULL, max ) );
/* assert: max != 0 */
catch_assert( skipSpace( buf, &start, 0 ) );
/* first argument is length; assert: 2 <= length <= 4 */
catch_assert( shortestUTF8( 1, u ) );
catch_assert( shortestUTF8( 5, u ) );
catch_assert( skipUTF8MultiByte( NULL, &start, max ) );
catch_assert( skipUTF8MultiByte( buf, NULL, max ) );
catch_assert( skipUTF8MultiByte( buf, &start, 0 ) );
/* assert: start < max */
catch_assert( skipUTF8MultiByte( buf, &start, max ) );
/* assert: buf[0] < '\0' */
catch_assert( skipUTF8MultiByte( buf, &start, ( start + 1 ) ) );
catch_assert( skipUTF8( NULL, &start, max ) );
catch_assert( skipUTF8( buf, NULL, max ) );
catch_assert( skipUTF8( buf, &start, 0 ) );
catch_assert( skipOneHexEscape( NULL, &start, max, &u ) );
catch_assert( skipOneHexEscape( buf, NULL, max, &u ) );
catch_assert( skipOneHexEscape( buf, &start, 0, &u ) );
catch_assert( skipOneHexEscape( buf, &start, max, NULL ) );
catch_assert( skipHexEscape( NULL, &start, max ) );
catch_assert( skipHexEscape( buf, NULL, max ) );
catch_assert( skipHexEscape( buf, &start, 0 ) );
catch_assert( skipEscape( NULL, &start, max ) );
catch_assert( skipEscape( buf, NULL, max ) );
catch_assert( skipEscape( buf, &start, 0 ) );
catch_assert( skipString( NULL, &start, max ) );
catch_assert( skipString( buf, NULL, max ) );
catch_assert( skipString( buf, &start, 0 ) );
catch_assert( strnEq( NULL, buf, max ) );
catch_assert( strnEq( buf, NULL, max ) );
catch_assert( skipLiteral( NULL, &start, max, "lit", length ) );
catch_assert( skipLiteral( buf, NULL, max, "lit", length ) );
catch_assert( skipLiteral( buf, &start, 0, "lit", length ) );
catch_assert( skipLiteral( buf, &start, max, NULL, length ) );
catch_assert( skipDigits( NULL, &start, max, NULL ) );
catch_assert( skipDigits( buf, NULL, max, NULL ) );
catch_assert( skipDigits( buf, &start, 0, NULL ) );
catch_assert( skipDecimals( NULL, &start, max ) );
catch_assert( skipDecimals( buf, NULL, max ) );
catch_assert( skipDecimals( buf, &start, 0 ) );
catch_assert( skipExponent( NULL, &start, max ) );
catch_assert( skipExponent( buf, NULL, max ) );
catch_assert( skipExponent( buf, &start, 0 ) );
catch_assert( skipNumber( NULL, &start, max ) );
catch_assert( skipNumber( buf, NULL, max ) );
catch_assert( skipNumber( buf, &start, 0 ) );
catch_assert( skipSpaceAndComma( NULL, &start, max ) );
catch_assert( skipSpaceAndComma( buf, NULL, max ) );
catch_assert( skipSpaceAndComma( buf, &start, 0 ) );
catch_assert( skipArrayScalars( NULL, &start, max ) );
catch_assert( skipArrayScalars( buf, NULL, max ) );
catch_assert( skipArrayScalars( buf, &start, 0 ) );
catch_assert( skipObjectScalars( NULL, &start, max ) );
catch_assert( skipObjectScalars( buf, NULL, max ) );
catch_assert( skipObjectScalars( buf, &start, 0 ) );
/* assert: mode is '[' or '{' */
catch_assert( skipScalars( buf, &start, max, '(' ) );
catch_assert( skipCollection( NULL, &start, max ) );
catch_assert( skipCollection( buf, NULL, max ) );
catch_assert( skipCollection( buf, &start, 0 ) );
catch_assert( nextValue( NULL, &start, max, &value, &valueLength ) );
catch_assert( nextValue( buf, NULL, max, &value, &valueLength ) );
catch_assert( nextValue( buf, &start, 0, &value, &valueLength ) );
catch_assert( nextValue( buf, &start, max, NULL, &valueLength ) );
catch_assert( nextValue( buf, &start, max, &value, NULL ) );
catch_assert( nextKeyValuePair( NULL, &start, max, &key, &keyLength, &value, &valueLength ) );
catch_assert( nextKeyValuePair( buf, NULL, max, &key, &keyLength, &value, &valueLength ) );
catch_assert( nextKeyValuePair( buf, &start, 0, &key, &keyLength, &value, &valueLength ) );
catch_assert( nextKeyValuePair( buf, &start, max, NULL, &keyLength, &value, &valueLength ) );
catch_assert( nextKeyValuePair( buf, &start, max, &key, NULL, &value, &valueLength ) );
catch_assert( nextKeyValuePair( buf, &start, max, &key, &keyLength, NULL, &valueLength ) );
catch_assert( nextKeyValuePair( buf, &start, max, &key, &keyLength, &value, NULL ) );
catch_assert( objectSearch( NULL, max, queryKey, keyLength, &value, &valueLength ) );
catch_assert( objectSearch( buf, max, NULL, keyLength, &value, &valueLength ) );
catch_assert( objectSearch( buf, max, queryKey, keyLength, NULL, &valueLength ) );
catch_assert( objectSearch( buf, max, queryKey, keyLength, &value, NULL ) );
catch_assert( arraySearch( NULL, max, queryIndex, &value, &valueLength ) );
catch_assert( arraySearch( buf, max, queryIndex, NULL, &valueLength ) );
catch_assert( arraySearch( buf, max, queryIndex, &value, NULL ) );
catch_assert( skipQueryPart( NULL, &start, max, &valueLength ) );
catch_assert( skipQueryPart( buf, NULL, max, &valueLength ) );
catch_assert( skipQueryPart( buf, &start, 0, &valueLength ) );
catch_assert( skipQueryPart( buf, &start, max, NULL ) );
catch_assert( multiSearch( NULL, max, queryKey, keyLength, &value, &valueLength ) );
catch_assert( multiSearch( buf, 0, queryKey, keyLength, &value, &valueLength ) );
catch_assert( multiSearch( buf, max, NULL, keyLength, &value, &valueLength ) );
catch_assert( multiSearch( buf, max, queryKey, 0, &value, &valueLength ) );
catch_assert( multiSearch( buf, max, queryKey, keyLength, NULL, &valueLength ) );
catch_assert( multiSearch( buf, max, queryKey, keyLength, &value, NULL ) );
catch_assert( iterate( NULL, max, &start, &next, &key, &keyLength, &value, &valueLength ) );
catch_assert( iterate( buf, 0, &start, &next, &key, &keyLength, &value, &valueLength ) );
catch_assert( iterate( buf, max, NULL, &next, &key, &keyLength, &value, &valueLength ) );
catch_assert( iterate( buf, max, &start, NULL, &key, &keyLength, &value, &valueLength ) );
catch_assert( iterate( buf, max, &start, &next, NULL, &keyLength, &value, &valueLength ) );
catch_assert( iterate( buf, max, &start, &next, &key, NULL, &value, &valueLength ) );
catch_assert( iterate( buf, max, &start, &next, &key, &keyLength, NULL, &valueLength ) );
catch_assert( iterate( buf, max, &start, &next, &key, &keyLength, &value, NULL ) );
}
/**
* @brief These checks are not otherwise reached.
*/
void test_JSON_unreached( void )
{
char buf[ 2 ];
size_t start, max;
/* return false when start >= max */
start = max = 1;
TEST_ASSERT_EQUAL( false, skipUTF8( "abc", &start, max ) );
/* return false when buf[ 0 ] != '\\' */
buf[ 0 ] = 'x';
start = 0;
TEST_ASSERT_EQUAL( false, skipEscape( buf, &start, sizeof( buf ) ) );
/* set output value to -1 when integer conversion exceeds max */
{
#define TOO_BIG "100000000000"
int32_t out;
start = 0;
TEST_ASSERT_EQUAL( true, skipDigits( TOO_BIG, &start, ( sizeof( TOO_BIG ) - 1 ), &out ) );
TEST_ASSERT_EQUAL( -1, out );
}
/* return JSONNotFound when start >= max */
{
size_t next, key, keyLength, value, valueLength;
start = max = 1;
TEST_ASSERT_EQUAL( JSONNotFound,
iterate( buf, max, &start, &next, &key, &keyLength, &value, &valueLength ) );
}
}
/**
* @brief Test overflows.
*/
void test_JSON_overflows( void )
{
char buf[] = UNICODE_ESCAPE_SEQUENCES_BMP;
size_t start;
uint16_t u;
start = SIZE_MAX;
TEST_ASSERT_EQUAL( false, skipOneHexEscape( buf, &start, SIZE_MAX, &u ) );
}
void core_json_test_unity(void)
{
RUN_TEST(test_JSON_Validate_Invalid_Params);
RUN_TEST(test_JSON_Validate_Legal_Documents);
RUN_TEST(test_JSON_Validate_Illegal_Documents);
RUN_TEST(test_JSON_Validate_Partial_Documents);
RUN_TEST(test_JSON_Search_Legal_Documents);
RUN_TEST(test_JSON_Search_Legal_Array_Documents);
RUN_TEST(test_JSON_Iterate_Legal_Array_Documents);
RUN_TEST(test_JSON_Iterate_Legal_Object_Documents);
RUN_TEST(test_JSON_Iterate_Illegal_Documents);
RUN_TEST(test_JSON_Search_Query_Key_Not_Found);
RUN_TEST(test_JSON_Search_Illegal_Documents);
RUN_TEST(test_JSON_Search_Invalid_Params);
RUN_TEST(test_JSON_Iterate_Invalid_Params);
RUN_TEST(test_JSON_Search_Partial_Documents);
RUN_TEST(test_JSON_Max_Depth);
// RUN_TEST(test_JSON_asserts);
RUN_TEST(test_JSON_unreached);
RUN_TEST(test_JSON_overflows);
UNITY_END();
}
SHELL_EXPORT_CMD(SHELL_CMD_PERMISSION(0) | SHELL_CMD_TYPE(SHELL_TYPE_CMD_FUNC),
core_json_test_unity, core_json_test_unity, This is unity for json);
![[ansible] playbook运用](https://img-blog.csdnimg.cn/direct/c7b90c3d4966472dbfc938518e25df44.png)