文章目录
- 线性回归模型(linear regression model)
- 损失/代价函数(cost function)——均方误差(mean squared error)
- 梯度下降算法(gradient descent algorithm)
- 参数(parameter)和超参数(hyperparameter)
- 代码实现样例
- 运行结果
源代码文件请点击此处!
线性回归模型(linear regression model)
- 线性回归模型:
f w , b ( x ) = w x + b f_{w,b}(x) = wx + b fw,b(x)=wx+b
其中, w w w 为权重(weight), b b b 为偏置(bias)
- 预测值(通常加一个帽子符号):
y ^ ( i ) = f w , b ( x ( i ) ) = w x ( i ) + b \hat{y}^{(i)} = f_{w,b}(x^{(i)}) = wx^{(i)} + b y^(i)=fw,b(x(i))=wx(i)+b
损失/代价函数(cost function)——均方误差(mean squared error)
- 一个训练样本: ( x ( i ) , y ( i ) ) (x^{(i)}, y^{(i)}) (x(i),y(i))
- 训练样本总数 = m m m
- 损失/代价函数是一个二次函数,在图像上是一个开口向上的抛物线的形状。
J ( w , b ) = 1 2 m ∑ i = 1 m [ f w , b ( x ( i ) ) − y ( i ) ] 2 = 1 2 m ∑ i = 1 m [ w x ( i ) + b − y ( i ) ] 2 \begin{aligned} J(w, b) &= \frac{1}{2m} \sum^{m}_{i=1} [f_{w,b}(x^{(i)}) - y^{(i)}]^2 \\ &= \frac{1}{2m} \sum^{m}_{i=1} [wx^{(i)} + b - y^{(i)}]^2 \end{aligned} J(w,b)=2m1i=1∑m[fw,b(x(i))−y(i)]2=2m1i=1∑m[wx(i)+b−y(i)]2
- 为什么需要乘以 1/2?因为对平方项求偏导后会出现系数 2,是为了约去这个系数。
梯度下降算法(gradient descent algorithm)
- α \alpha α:学习率(learning rate),用于控制梯度下降时的步长,以抵达损失函数的最小值处。若 α \alpha α 太小,梯度下降太慢;若 α \alpha α 太大,下降过程可能无法收敛。
- 梯度下降算法:
r e p e a t { t m p _ w = w − α ∂ J ( w , b ) w t m p _ b = b − α ∂ J ( w , b ) b w = t m p _ w b = t m p _ b } u n t i l c o n v e r g e \begin{aligned} repeat \{ \\ & tmp\_w = w - \alpha \frac{\partial J(w, b)}{w} \\ & tmp\_b = b - \alpha \frac{\partial J(w, b)}{b} \\ & w = tmp\_w \\ & b = tmp\_b \\ \} until \ & converge \end{aligned} repeat{}until tmp_w=w−αw∂J(w,b)tmp_b=b−αb∂J(w,b)w=tmp_wb=tmp_bconverge
其中,偏导数为
∂ J ( w , b ) w = 1 m ∑ i = 1 m [ f w , b ( x ( i ) ) − y ( i ) ] x ( i ) ∂ J ( w , b ) b = 1 m ∑ i = 1 m [ f w , b ( x ( i ) ) − y ( i ) ] \begin{aligned} & \frac{\partial J(w, b)}{w} = \frac{1}{m} \sum^{m}_{i=1} [f_{w,b}(x^{(i)}) - y^{(i)}] x^{(i)} \\ & \frac{\partial J(w, b)}{b} = \frac{1}{m} \sum^{m}_{i=1} [f_{w,b}(x^{(i)}) - y^{(i)}] \end{aligned} w∂J(w,b)=m1i=1∑m[fw,b(x(i))−y(i)]x(i)b∂J(w,b)=m1i=1∑m[fw,b(x(i))−y(i)]
参数(parameter)和超参数(hyperparameter)
- 超参数(hyperparameter):训练之前人为设置的任何数量都是超参数,例如学习率 α \alpha α
- 参数(parameter):模型在训练过程中创建或修改的任何数量都是参数,例如 w , b w, b w,b
代码实现样例
import numpy as np
import matplotlib.pyplot as plt
# 计算误差均方函数 J(w,b)
def cost_function(x, y, w, b):
m = x.shape[0] # 训练集的数据样本数
cost_sum = 0.0
for i in range(m):
f_wb = w * x[i] + b
cost = (f_wb - y[i]) ** 2
cost_sum += cost
return cost_sum / (2 * m)
# 计算梯度值 dJ/dw, dJ/db
def compute_gradient(x, y, w, b):
m = x.shape[0] # 训练集的数据样本数
d_w = 0.0
d_b = 0.0
for i in range(m):
f_wb = w * x[i] + b
d_wi = (f_wb - y[i]) * x[i]
d_bi = (f_wb - y[i])
d_w += d_wi
d_b += d_bi
dj_dw = d_w / m
dj_db = d_b / m
return dj_dw, dj_db
# 梯度下降算法
def linear_regression(x, y, w, b, learning_rate=0.01, epochs=1000):
J_history = [] # 记录每次迭代产生的误差值
for epoch in range(epochs):
dj_dw, dj_db = compute_gradient(x, y, w, b)
# w 和 b 需同步更新
w = w - learning_rate * dj_dw
b = b - learning_rate * dj_db
J_history.append(cost_function(x, y, w, b)) # 记录每次迭代产生的误差值
return w, b, J_history
# 绘制线性方程的图像
def draw_line(w, b, xmin, xmax, title):
x = np.linspace(xmin, xmax)
y = w * x + b
# plt.axis([0, 10, 0, 50]) # xmin, xmax, ymin, ymax
plt.xlabel("X-axis", size=15)
plt.ylabel("Y-axis", size=15)
plt.title(title, size=20)
plt.plot(x, y)
# 绘制散点图
def draw_scatter(x, y, title):
plt.xlabel("X-axis", size=15)
plt.ylabel("Y-axis", size=15)
plt.title(title, size=20)
plt.scatter(x, y)
# 从这里开始执行
if __name__ == '__main__':
# 训练集样本
x_train = np.array([1, 2, 3, 5, 6, 7])
y_train = np.array([15.5, 19.7, 24.4, 35.6, 40.7, 44.8])
w = 0.0 # 权重
b = 0.0 # 偏置
epochs = 10000 # 迭代次数
learning_rate = 0.01 # 学习率
J_history = [] # # 记录每次迭代产生的误差值
w, b, J_history = linear_regression(x_train, y_train, w, b, learning_rate, epochs)
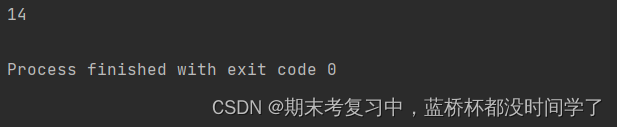
print(f"result: w = {w:0.4f}, b = {b:0.4f}") # 打印结果
# 绘制迭代计算得到的线性回归方程
plt.figure(1)
draw_line(w, b, 0, 10, "Linear Regression")
plt.scatter(x_train, y_train) # 将训练数据集也表示在图中
plt.show()
# 绘制误差值的散点图
plt.figure(2)
x_axis = list(range(0, 10000))
draw_scatter(x_axis, J_history, "Cost Function in Every Epoch")
plt.show()
运行结果