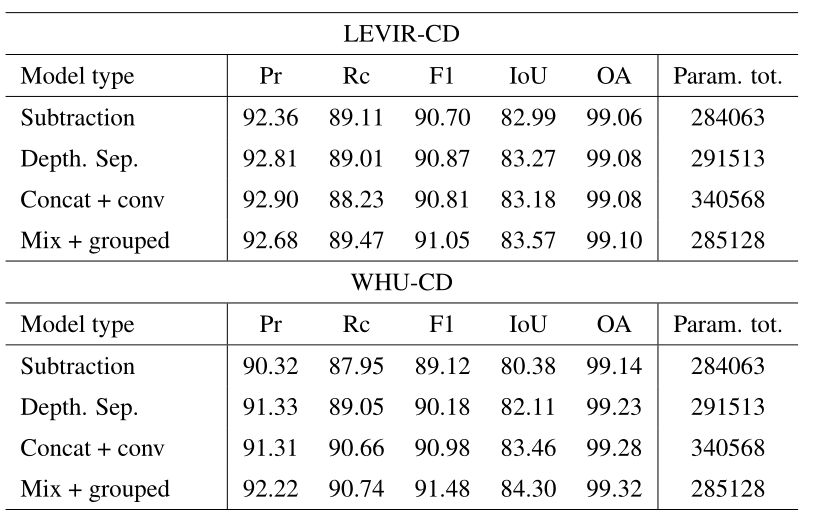
对称加密
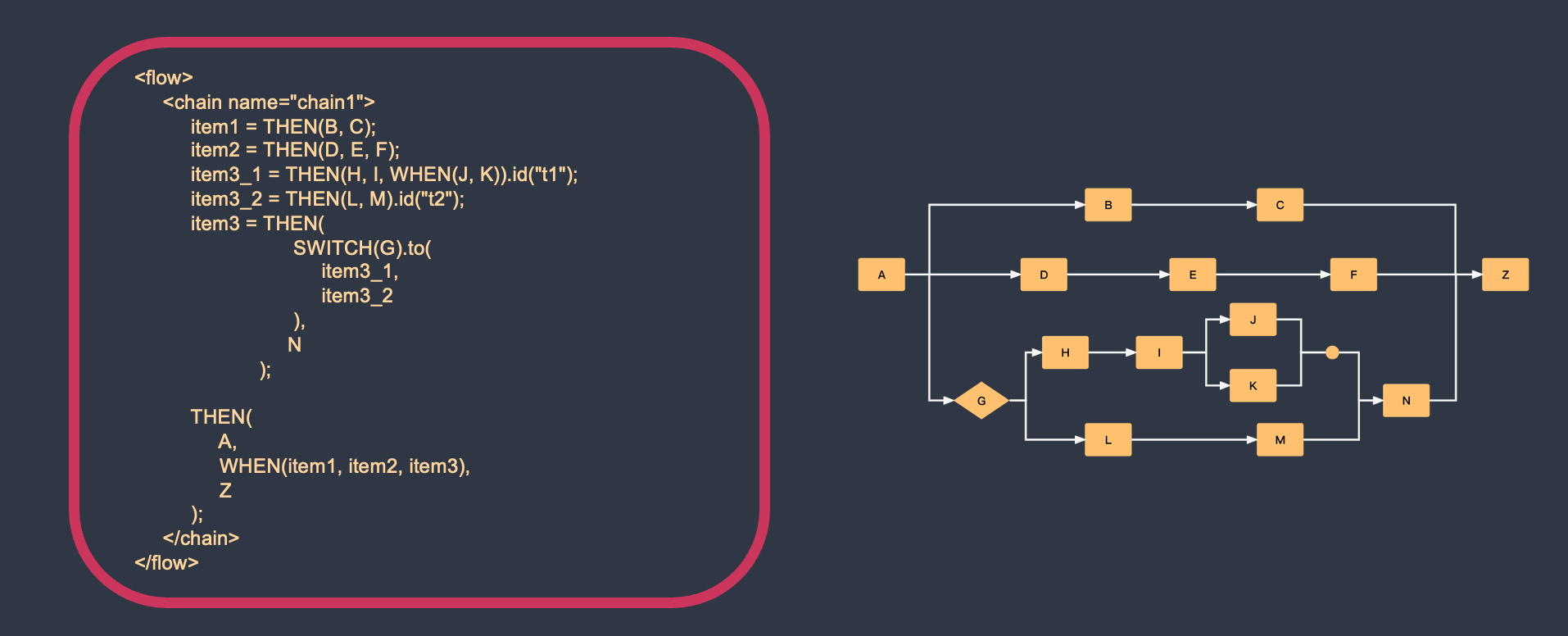
加密和解密时使用的是同一个秘钥,这种加密方法称为对称加密,也称为单密钥加密。
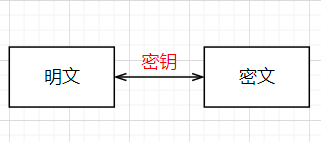
优点:算法公开、计算量小、加密速度快、加密效率高。
缺点:如果一方的秘钥被泄露,那么加密信息也就不安全了。
示例AES
private static void encode(){
System.out.println("1.请输入要加密的原文");
String text = scanner.nextLine();
System.out.println("2.请输入16位密钥");
String password = scanner.next();
while(password.length() != 16){
scanner.nextLine();
System.out.println("[密钥长度需为16位!]");
password = scanner.next();
}
// key
Key key = new SecretKeySpec(password.getBytes(), "AES");
// 加密 -> Base64编码
byte[] result = null;
try {
Cipher cipher = Cipher.getInstance("AES/ECB/PKCS5Padding");
cipher.init(Cipher.ENCRYPT_MODE, key);
result = cipher.doFinal(text.getBytes());
} catch (Exception e) {
e.printStackTrace();
}
byte[] encode = Base64.getEncoder().encode(result);
System.out.println("加密后的密文:\n" + new String(encode));
}
private static void decode() {
System.out.println("1.请输入要解密的密文");
String encrptText = scanner.nextLine();
System.out.println("2.请输入16位密钥");
String password = scanner.next();
while(password.length() != 16){
scanner.nextLine();
System.out.println("[密钥长度需为16位!]");
password = scanner.next();
}
// key
Key key = new SecretKeySpec(password.getBytes(), "AES");
// Base64解码 -> 解密
byte[] result = null;
byte[] decode = Base64.getDecoder().decode(encrptText.getBytes());
try {
Cipher cipher = Cipher.getInstance("AES/ECB/PKCS5Padding");
cipher.init(Cipher.DECRYPT_MODE, key);
result = cipher.doFinal(decode);
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("解密后的原文:\n" + new String(result));
}
非对称加密
非对称加密算法需要两个密钥来进行加密和解密,这两个密钥是公开密钥和私有密钥。
公开密钥与私有密钥是一对。
如果用公钥对数据进行加密,只有用对应的私钥才能解密。
如果用私钥对数据进行加密,只有用对应的公钥才能解密。
工作过程
1、乙方生成一对密钥(公钥和私钥)并将公钥公开。
2、甲方使用公钥对机密信息进行加密,发送给乙方。
3、乙方用自己保存的另一把密钥(私钥)对加密后的信息进行解密。
在传输过程中,即使截获了传输的密文,并得到了乙的公钥,也无法破解密文,因为只有乙的私钥才能解密密文。
同样,如果乙要回复加密信息给甲,那么需要甲先公布甲的公钥给乙用于加密,甲自己保存甲的私钥用于解密。
byte[]和String互转时注意
UTF
Acronym for Unicode (or UCS) Transformation Format.
Character Encoding Scheme
A character encoding form plus byte serialization. There are seven character encoding schemes in Unicode: UTF-8, UTF-16, UTF-16BE, UTF-16LE, UTF-32, UTF-32BE, and UTF-32LE.
UTF-8
A multibyte encoding for text that represents each Unicode character with 1 to 4 bytes, and which is backward-compatible with ASCII. UTF-8 is the predominant form of Unicode in web pages.
Unicode只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
UTF-8是在互联网上使用最广的一种 Unicode 的实现方式。
/**
* 默认的是 UTF-8 编解码
* 编码: String -> byte[], 汉字编码为 3个字节, 数字字符编码为 1个字节
* 解码: byte[] -> String
* @param args
*/
public static void main(String[] args) {
/**
* OK: String -> byte[] -> String
*/
String str = "你玩的服务xx";
byte[] bytes = str.getBytes();
String newStr = new String(bytes);
/**
* Error: byte[] -> String -> byte[]
* 原因是:
* 给定的字节数组实际上是自定义的
* 进行解码时, 将 -37 和 -10 解码为了�
* 重新编码时, 将 � 编码为了 -17, -65, -67
* 所以前后不一致
* 如何解决:
* 使用 ISO-8859-1(单字节编解码)
*/
byte[] anotherBytes = {40, -37, -10, 24, 9}; // [40, -37, -10, 24, 9]
String anotherString = new String(anotherBytes); // "(��\u0018\t"
byte[] anotherNewBytes = anotherString.getBytes(); // [40, -17, -65, -67, -17, -65, -67, 24, 9]
}
为什么中文编码后得到的字节数组是负的

Unicode符号范围 | UTF-8编码方式
(十六进制) | (二进制)
----------------------+----------------------------------------
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
# 中文一般是4E00~9FA5, 对应上表的第三行, 可以看到对应的编码三个字节第一位都是1, 也就是负数
# UTF-8的编码规则
1) 对于单字节的符号, 字节的第一位设为0,后面7位为这个符号的Unicode码.因此对于英语字母,UTF-8编码和ASCII码是相同的.
2) 对于n字节的符号(n>1), 第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10.剩下的没有提及的二进制位,全部为这个符号的 Unicode码。
严的Unicode是4E25(100 1110 0010 0101),根据上表, 4E25处在第三行的范围内(0000 0800 - 0000 FFFF).
因此严的UTF-8编码需要三个字节,即格式是1110xxxx 10xxxxxx 10xxxxxx.
然后,从严的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0.
这样就得到了,严的UTF-8编码是(1110 0100) (1011 1000) (1010 0101), 转换成十六进制就是E4B8A5.
Base64编码原理
byte数组转换成String,再getBytes()之后byte数组与原数组不同
ASCII,UNICODE,UTF8编码规则
Java对称加密
AES解密报错,Input length must be multiple of 16 when decrypting
AES加密,Input length must be multiple of 16 when decryp
中文转byte数组时变成了负数
ASCII,Unicode和UTF-8
中日韩汉字Unicode编码表
unicode官网