论文

标题:TINYCD: A (Not So) Deep Learning Model For Change Detection
paper:
https://arxiv.org/abs/2207.13159
code:
GitHub - AndreaCodegoni/Tiny_model_4_CD: Official implementation of TINYCD: A (NOT SO) DEEP LEARNING MODEL FOR CHANGE DETECTION
摘要
变化检测(CD)的目的是通过比较在不同时间拍摄的该地点的两幅图像来检测在同一区域发生的变化。CD具有挑战性的部分是跟踪用户想要突出显示的变化,例如新建筑,而忽略由于外部因素造成的变化,如环境、照明条件、雾或季节变化。深度学习领域的最新发展使研究人员在这一领域取得了突出的表现。特别是,不同的时空注意机制允许利用从模型中提取的空间特征,并通过利用两个可用的图像以时间方式将它们关联起来。缺点是这些模型变得越来越复杂和庞大,对于边缘应用来说往往是不可行的。当模型必须应用于工业领域或需要实时性能的应用时,这些都是限制。在这项工作中,我们提出了一种新的模型,称为TinyCD,证明了它既轻便又有效,能够在参数减少13-150倍的情况下实现与当前技术水平相当甚至更好的性能。在我们的方法中,我们利用低层特征的重要性来比较图像。要做到这一点,我们只使用几个主干模块。此策略使我们可以将网络参数的数量保持在较低水平。为了合成从两幅图像中提取的特征,我们引入了一种新的、参数经济的混合块,能够在空间和时间域上对特征进行互相关。最后,为了充分利用计算特征中包含的信息,我们定义了能够执行像素分类的PW-MLP块。
动机
变化检测的主要目的是构建一个模型,能够识别场景中两个不同时间之间发生的变化,CD模型比较时间t1和t2获得的两个共同配准的图像。
现有基于深度学习的变化检测模型都过于复杂和庞大,难以应用于工业场景,边缘应用。
贡献
- 探索图像比较间浅层特征的有效性,有助于显著减少模型参数量(使用EfficientNet_b4作为主干网络用于提取特征,显著减少参数量和计算量);
- 将两幅图的特征进行通道交叉混合(分组卷积+串联操作实现);
- 设计MAMB模块进行跳接,使用注意力机制并生成掩码,逐级精细化;
- 对每个像素分类生成最终的预测掩码。
我们的工作灵感来自于BIT [【论文笔记】Remote Sensing Image Change Detection with Transformers_m0_61899108的博客-CSDN博客_whu_cd]。事实上,我们认为,每个像素在不同分辨率下包含的信息,即语义标记,对于最终的分类是必不可少的,而且它们比空间注意提供的全局上下文更重要。此外,我们的直觉是,由于我们可以比较两个图像,所以我们只能使用低级别特征来突出及时发生的变化。为此,我们设计了一个暹罗U-Net类型的网络,其中主干由EfficientNetb4的前4个块表示。为了更好地在时空上融合通道中包含的信息,我们引入了一种混合策略,迫使网络以语义一致的方式融合和比较在时间T1和T2提取的特征。最后,为了充分利用每个像素/语义标记中包含的所有信息,我们在每个像素/语义标记上大量应用了多层感知器(MLP)。MLP用于在U-Net结构中创建空间注意掩码跳过连接。并将其应用于分类块中,对每个像素点进行分类。
方法
网络架构
网络包括4个部分:
- 预训练的主干网络构成孪生编码器;
- 混合和注意掩码块(MAMB)和瓶颈混合块组成主干结果;
- 上采样编码器用于改进低分辨率结果;
- 像素级分类器。

详细结构:

模型细节







实验
数据集: LEVIR-CD和WHU-CD

LEVIR-CD: LEVIR-CD | LEVIR-CD is a new large-scale remote sensing binary change detection dataset, which would help develop novel deep learning-based algorithms for remote sensing image change detection.
WHU-CD: https://study.rsgis.whu.edu.cn/pages/download/building_dataset.html
预处理后的数据集:
LEVIR-CD
wget https://www.dropbox.com/s/h9jl2ygznsaeg5d/LEVIR-CD-256.zipWHU-CD
wget https://www.dropbox.com/s/r76a00jcxp5d3hl/WHU-CD-256.zip实验细节


比较结果
LEVIR-CD数据集:

WHU-CD数据集:

参数量、计算量、结果比较:
可视化:


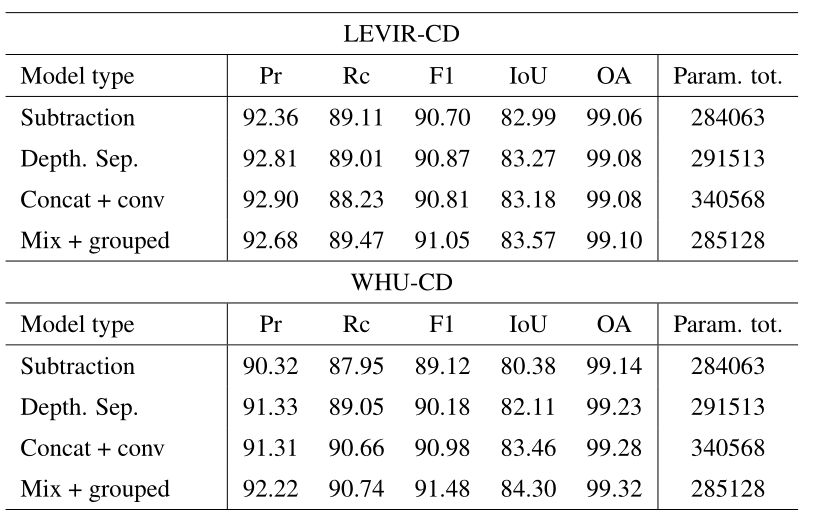
消融实验
是否使用跳接:

不同的生成方式:

关键代码
https://github.com/AndreaCodegoni/Tiny_model_4_CD
change_classifier.py
# change_classifier.py
# https://github.com/AndreaCodegoni/Tiny_model_4_CD
from typing import List
import torchvision
from models.layers import MixingMaskAttentionBlock, PixelwiseLinear, UpMask, MixingBlock
from torch import Tensor
from torch.nn import Module, ModuleList, Sigmoid
class ChangeClassifier(Module):
def __init__(
self,
bkbn_name="efficientnet_b4",
pretrained=True,
output_layer_bkbn="3",
freeze_backbone=False,
):
super().__init__()
# Load the pretrained backbone according to parameters:
self._backbone = _get_backbone(
bkbn_name, pretrained, output_layer_bkbn, freeze_backbone
)
# Initialize mixing blocks:
self._first_mix = MixingMaskAttentionBlock(6, 3, [3, 10, 5], [10, 5, 1])
self._mixing_mask = ModuleList(
[
MixingMaskAttentionBlock(48, 24, [24, 12, 6], [12, 6, 1]),
MixingMaskAttentionBlock(64, 32, [32, 16, 8], [16, 8, 1]),
MixingBlock(112, 56),
]
)
# Initialize Upsampling blocks:
self._up = ModuleList(
[
UpMask(64, 56, 64),
UpMask(128, 64, 64),
UpMask(256, 64, 32),
]
)
# Final classification layer:
self._classify = PixelwiseLinear([32, 16, 8], [16, 8, 1], Sigmoid())
def forward(self, ref: Tensor, test: Tensor) -> Tensor:
features = self._encode(ref, test)
latents = self._decode(features)
return self._classify(latents)
def _encode(self, ref, test) -> List[Tensor]:
features = [self._first_mix(ref, test)]
for num, layer in enumerate(self._backbone):
ref, test = layer(ref), layer(test)
if num != 0:
features.append(self._mixing_mask[num - 1](ref, test))
return features
def _decode(self, features) -> Tensor:
upping = features[-1]
for i, j in enumerate(range(-2, -5, -1)):
upping = self._up[i](upping, features[j])
return upping
def _get_backbone(
bkbn_name, pretrained, output_layer_bkbn, freeze_backbone
) -> ModuleList:
# The whole model:
entire_model = getattr(torchvision.models, bkbn_name)(
pretrained=pretrained
).features
# Slicing it:
derived_model = ModuleList([])
for name, layer in entire_model.named_children():
derived_model.append(layer)
if name == output_layer_bkbn:
break
# Freezing the backbone weights:
if freeze_backbone:
for param in derived_model.parameters():
param.requires_grad = False
return derived_model
layers.py
# layers.py
from typing import List, Optional
from torch import Tensor, reshape, stack
from torch.nn import (
Conv2d,
InstanceNorm2d,
Module,
PReLU,
Sequential,
Upsample,
)
class PixelwiseLinear(Module):
def __init__(
self,
fin: List[int],
fout: List[int],
last_activation: Module = None,
) -> None:
assert len(fout) == len(fin)
super().__init__()
n = len(fin)
self._linears = Sequential(
*[
Sequential(
Conv2d(fin[i], fout[i], kernel_size=1, bias=True),
PReLU()
if i < n - 1 or last_activation is None
else last_activation,
)
for i in range(n)
]
)
def forward(self, x: Tensor) -> Tensor:
# Processing the tensor:
return self._linears(x)
class MixingBlock(Module):
def __init__(
self,
ch_in: int,
ch_out: int,
):
super().__init__()
self._convmix = Sequential(
Conv2d(ch_in, ch_out, 3, groups=ch_out, padding=1),
PReLU(),
InstanceNorm2d(ch_out),
)
def forward(self, x: Tensor, y: Tensor) -> Tensor:
# Packing the tensors and interleaving the channels:
mixed = stack((x, y), dim=2)
mixed = reshape(mixed, (x.shape[0], -1, x.shape[2], x.shape[3]))
# Mixing:
return self._convmix(mixed)
class MixingMaskAttentionBlock(Module):
"""use the grouped convolution to make a sort of attention"""
def __init__(
self,
ch_in: int,
ch_out: int,
fin: List[int],
fout: List[int],
generate_masked: bool = False,
):
super().__init__()
self._mixing = MixingBlock(ch_in, ch_out)
self._linear = PixelwiseLinear(fin, fout)
self._final_normalization = InstanceNorm2d(ch_out) if generate_masked else None
self._mixing_out = MixingBlock(ch_in, ch_out) if generate_masked else None
def forward(self, x: Tensor, y: Tensor) -> Tensor:
z_mix = self._mixing(x, y)
z = self._linear(z_mix)
z_mix_out = 0 if self._mixing_out is None else self._mixing_out(x, y)
return (
z
if self._final_normalization is None
else self._final_normalization(z_mix_out * z)
)
class UpMask(Module):
def __init__(
self,
up_dimension: int,
nin: int,
nout: int,
):
super().__init__()
self._upsample = Upsample(
size=(up_dimension, up_dimension), mode="bilinear", align_corners=True
)
self._convolution = Sequential(
Conv2d(nin, nin, 3, 1, groups=nin, padding=1),
PReLU(),
InstanceNorm2d(nin),
Conv2d(nin, nout, kernel_size=1, stride=1),
PReLU(),
InstanceNorm2d(nout),
)
def forward(self, x: Tensor, y: Optional[Tensor] = None) -> Tensor:
x = self._upsample(x)
if y is not None:
x = x * y
return self._convolution(x)