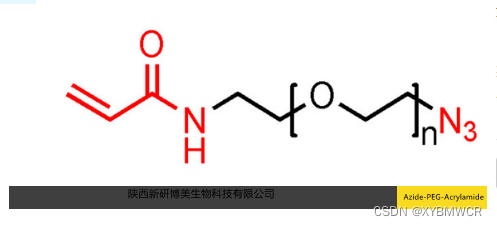
我觉得以下两篇文章,在感受野的含义和计算上,说的是比较好的。
1、深度学习:VGG(Vision Geometrical Group)论文详细讲解_HanZee的博客-CSDN博客
2、关于感受野的总结 - 知乎
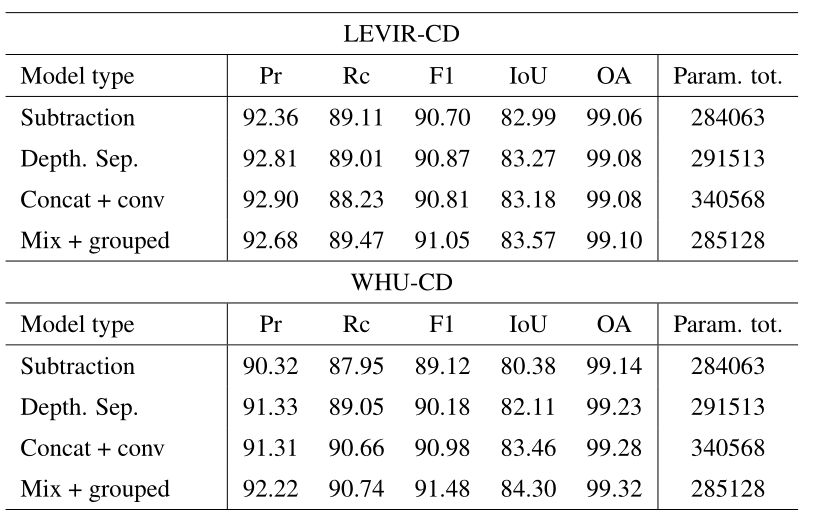
我们知道一个图片经过了一个7 * 7卷积的feature map的感受野是7 * 7,而图片经历了三个3 * 3后的frature map也是7 * 7
这时候我们就说第三次卷积后的输出相对于最开始输入的感受野大小也是7*7。
所以感受野一定要提到一个“相对的”概念,相对于上一层的输入以及相对于最开始的网络输入肯定是不同的!
另外注意: = 1,这个很容易理解,最初始的层(还未进行)的感受野自然是相对自己,那么相对于自己自然是1个像素对应1个像素,这个感受野自然就是1了。
我们接下来特别进一步解释和理解一下感受野:
前面所说的都是理论上得感受野,而特征得有效感受野(实际起作用的感受野)是远小于理论感受野的。
如下图所示。具体数学分析比较复杂,不再赘述,感兴趣的话可以参考论文[2]。

下面我从直观上解释一下有效感受野背后的原因。以一个两层 ,
的网络为例,该网络的理论感受野为5。
RF1 = RF0 + (kernelsize - 1)* stride = 1 + 2 * 1=3
RF2 = RF1 + (kernelsize - 1)* stride = 3 + 2 * 1=5

图片来源:关于感受野的总结 - 知乎
现在流行的目标检测网络大部分都是基于anchor的,比如SSD系列,v2以后的yolo,还有faster rcnn系列。
基于anchor的目标检测网络会预设一组大小不同的anchor,比如32x32、64x64、128x128、256x256,这么多anchor,我们应该放置在哪几层比较合适呢?这个时候感受野的大小是一个重要的考虑因素。
放置anchor层的特征感受野应该跟anchor大小相匹配(特征感受野这个怎么理解呢,就是该层特征图所对应网络最开始输入的感受野大小),感受野比anchor大太多不好。
如果感受野比anchor小很多,就好比只给你一只脚,让你说出这是什么鸟一样。如果感受野比anchor大很多,则好比给你一张世界地图,让你指出故宫在哪儿一样。
《S3FD: Single Shot Scale-invariant Face Detector》这篇人脸检测器论文就是依据感受野来设计anchor的大小的一个例子,文中的原话是
we design anchor scales based on the effective receptive field
《FaceBoxes: A CPU Real-time Face Detector with High Accuracy》这篇论文在设计多尺度anchor的时候,依据同样是感受野,文章的一个贡献为
We introduce the Multiple Scale Convolutional Layers
(MSCL) to handle various scales of face via enriching
receptive fields and discretizing anchors over layers
引文:
[2]Understanding the Effective Receptive Field in Deep Convolutional Neural Networks