一、前言
对于时间序列的任务的交叉验证,很核心的问题在于数据是否leak,因为较其他数据最为不同的是时间信息,有先后的发生顺序。
如果用简单的打散数据顺序,之后抽取,进行交叉验证肯定是违反这个时间顺序的规则的,比如如下的交叉验证的方式:
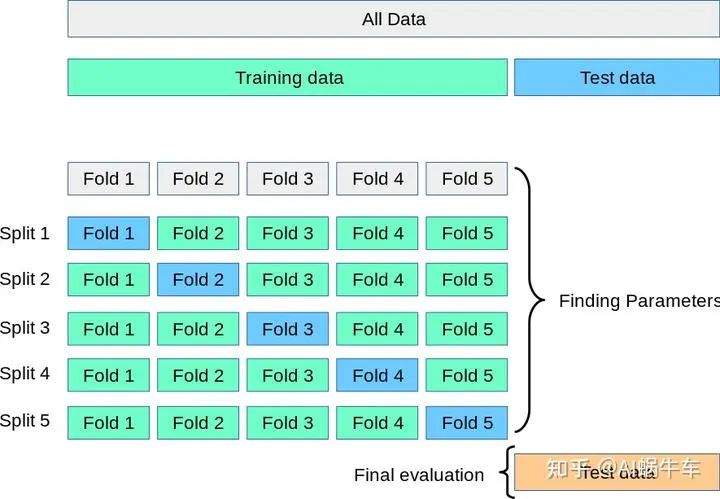
所以要用另外一种方式来保证分块的训练集和验证集是遵循时间的先后顺序的:GroupTimeSeriesSplit
二、GroupTimeSeriesSplit
2.1 代码
代码split.py
from sklearn.model_selection._split import _BaseKFold, indexable, _num_samples
from sklearn.utils.validation import _deprecate_positional_args
import numpy as np
# https://github.com/getgaurav2/scikit-learn/blob/d4a3af5cc9da3a76f0266932644b884c99724c57/sklearn/model_selection/_split.py#L2243
class GroupTimeSeriesSplit(_BaseKFold):
@_deprecate_positional_args
def __init__(self,
n_splits=5,
*,
max_train_size=None
):
super().__init__(n_splits, shuffle=False, random_state=None)
self.max_train_size = max_train_size
def split(self, X, y=None, groups=None):
"""Generate indices to split data into training and test set.
Parameters
----------
X : array-like of shape (n_samples, n_features)
Training data, where n_samples is the number of samples
and n_features is the number of features.
y : array-like of shape (n_samples,)
Always ignored, exists for compatibility.
groups : array-like of shape (n_samples,)
Group labels for the samples used while splitting the dataset into
train/test set.
Yields
------
train : ndarray
The training set indices for that split.
test : ndarray
The testing set indices for that split.
"""
if groups is None:
raise ValueError(
"The 'groups' parameter should not be None")
X, y, groups = indexable(X, y, groups)
n_samples = _num_samples(X)
n_splits = self.n_splits
n_folds = n_splits + 1
group_dict = {}
u, ind = np.unique(groups, return_index=True)
unique_groups = u[np.argsort(ind)]
n_groups = _num_samples(unique_groups)
for idx in np.arange(n_samples):
if (groups[idx] in group_dict):
group_dict[groups[idx]].append(idx)
else:
group_dict[groups[idx]] = [idx]
if n_folds > n_groups:
raise ValueError(
("Cannot have number of folds={0} greater than"
" the number of groups={1}").format(n_folds,
n_groups))
group_test_size = n_groups // n_folds
group_test_starts = range(n_groups - n_splits * group_test_size,
n_groups, group_test_size)
for group_test_start in group_test_starts:
train_array = []
test_array = []
for train_group_idx in unique_groups[:group_test_start]:
train_array_tmp = group_dict[train_group_idx]
train_array = np.sort(np.unique(
np.concatenate((train_array,
train_array_tmp)),
axis=None), axis=None)
train_end = train_array.size
if self.max_train_size and self.max_train_size < train_end:
train_array = train_array[train_end -
self.max_train_size:train_end]
for test_group_idx in unique_groups[group_test_start:
group_test_start +
group_test_size]:
test_array_tmp = group_dict[test_group_idx]
test_array = np.sort(np.unique(
np.concatenate((test_array,
test_array_tmp)),
axis=None), axis=None)
yield [int(i) for i in train_array], [int(i) for i in test_array]使用方式:
from split import GroupTimeSeriesSplit
import pandas as pd
import numpy as np
index = [0, 0, 1, 1, 2, 2, 3, 3, 4, 4, 5, 5, 5, 5]
data = pd.DataFrame(index, columns=['c'])
print(data)
for train_idx, val_idx in GroupTimeSeriesSplit(n_splits=5).split(data, groups=index):
print("_________")
print(data.loc[train_idx, 'c'].unique())
print(data.loc[val_idx, 'c'].unique())
# date = pd.to_datetime(data_pd[self.training_set.time_col], unit='s')
# day = date.dt.to_period('D')
#
# data = pd.DataFrame(pd.date_range(start='2022-01-30 00:00:00', end='2022-02-05 00:00:00', freq='h'), columns=['date'])
# date = pd.to_datetime(data['date'], unit='s')
# day = date.dt.to_period('h')
# print(len(np.unique(day)))
#
# for train_idx, val_idx in GroupTimeSeriesSplit(n_splits=5).split(data, groups=day):
# print(len(data.loc[train_idx, 'date'].unique()), data.loc[train_idx, 'date'].unique())
# print(len(data.loc[val_idx, 'date'].unique()), data.loc[val_idx, 'date'].unique())
# print("------")可以自行把注释去掉或者to_period('D')改成这样看下结果理解过程。
结果为:
_________
[0]
[1]
_________
[0 1]
[2]
_________
[0 1 2]
[3]
_________
[0 1 2 3]
[4]
_________
[0 1 2 3 4]
[5]参数部分:
n_splits:分几次
X: 数据
y: label
groups: 分组数据
根据分组数据进行分组,所以这里有个条件就是分组的个数要大于n_splits
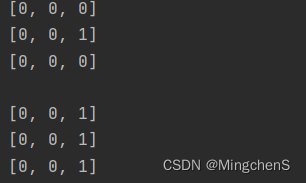
整个过程可以用这个图来辅助理解下
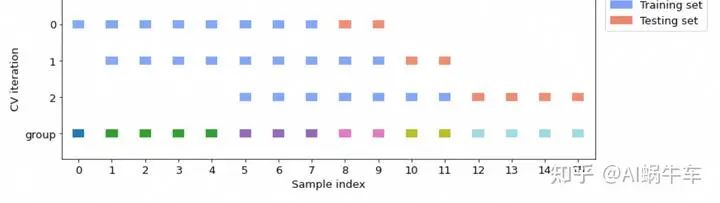
group首先会算一下 unique的个数,在图中group那行不一样的颜色代表不一样的index代表的group,会根据group的分组,进行相关的按照时间的组合,每次平移一个group,其中三个group对应的数据为训练集,而紧接着时间后的一个group的数据为验证集。
2.2 高级方式
如果想用更多的功能,比如训练集和验证集gap一些数据,或者根据数据的大小自定义训练集和验证集的数据比例关系等。
可以采用这个数据科学extend库:https://rasbt.github.io/mlxtend/
from mlxtend.evaluate import GroupTimeSeriesSplit2.2.1 设置训练集和验证集group个数比例
这种情况下,split的个数就会自适应得出
cv_args = {"test_size": 1, "train_size": 4}
cv = GroupTimeSeriesSplit(**cv_args)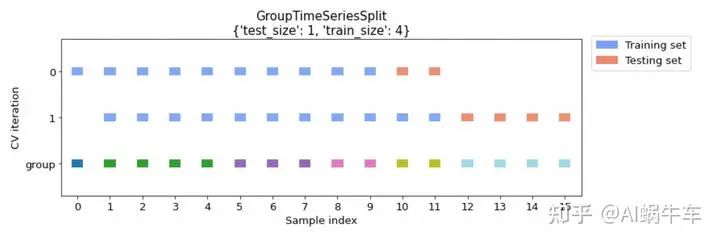
2.2.2 设置split_num的个数
cv_args = {"test_size": 2, "n_splits": 3}
cv = GroupTimeSeriesSplit(**cv_args)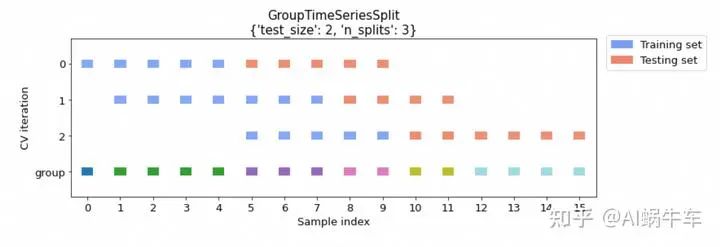
会根据要求的test_size的test group个数,以及split的个数,来自适应训练集大小
2.2.3 gap
cv_args = {"test_size": 1, "n_splits": 3, "gap_size": 1}
cv = GroupTimeSeriesSplit(**cv_args)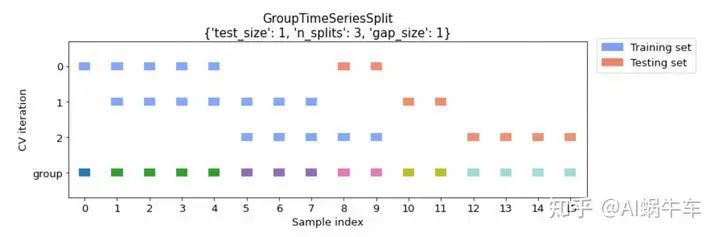
参考
https://rasbt.github.io/mlxtend/user_guide/evaluate/GroupTimeSeriesSplit/
https://www.kaggle.com/code/jorijnsmit/found-the-holy-grail-grouptimeseriessplit/notebook
推荐阅读:
我的2022届互联网校招分享
我的2021总结
浅谈算法岗和开发岗的区别
互联网校招研发薪资汇总
公众号:AI蜗牛车
保持谦逊、保持自律、保持进步

发送【蜗牛】获取一份《手把手AI项目》(AI蜗牛车著)
发送【1222】获取一份不错的leetcode刷题笔记
发送【AI四大名著】获取四本经典AI电子书