唇读(Lip Reading),也称视觉语音识别(Visual Speech Recognition),通过说话者口
型变化信息推断其所说的内容,旨在利用视觉信道信息补充听觉信道信息,在现实生活中有重要应用。例如,应用在医疗领域辅助听力受损的病人提高沟通交流能力,在军事领域提高情报获取和处理能力,在多媒体领域提高人机交互的多样性和鲁棒性等。随着深度学习技术的发展,以及数据集规模的不断完善,基于深度学习的框架方法已经逐渐取代传统方法,成为唇读的主流方法。
1 LRW数据集
1.1 数据集介绍
LRW 数据集是由牛津大学视觉几何团队于2016 年提出。因深度学习的兴起,大规模数据集的需求越来越大,LRW 数据集应运而生。不同于以往数据集,LRW 数据集数据来源于 BBC 广播电视节目而不是由志愿者或实验人员录制,使得该数据集数据量有了质的飞跃。数据集选择了 500最常出现的单词,截取说话人说这些单词的镜头,因此说话人超过 1000 个,话语实例超过 550000万个,一定程度上满足了深度学习对于数据量的需求。

该数据集由多达1000个包含500个不同单词的话语组成,由数百个不同的说话者说出。所有视频长度为29帧(1.16秒),单词出现在视频的中间。元数据中给出了单词duration,从中可以确定开始和结束帧。数据集统计信息如下表所示。
包含视频和元数据的软件包可供非商业学术研究使用。您需要与BBC研发部门签署一份数据共享协议才能访问。下载协议副本请到BBC野外唇读和野外数据集页唇读句子。一旦批准,您将被提供一个密码,然后包可以下载下面。
数据集官网地址:The Oxford-BBC Lip Reading in the Wild (LRW) Dataset
1.2 获取方式
- 根据网站https://www.bbc.co.uk/rd/projects/lip-reading-datasets提示,获取word版数据集申请文件,在文件最后签署使用协议,使用邮箱发送到该网站指定邮箱,等待一两天即可收到带有用户名和密码的邮件。
- 点击上图中“Download”链接,使用用户名密码登陆,即可下载数据集。

The package including the videos and the metadata is available for non-commercial, academic research. You will need to sign a Data Sharing agreement with BBC Research & Development before getting access. To download a copy of the agreement please go to the BBC Lip Reading in the Wild and Lip Reading Sentences in the Wild Datasets page. Once approved, you will be supplied with a password, and the package can then be downloaded below. Please cite [1] below if you make use of the dataset.
For all technical questions, please contact the author of [1].
File MD5 Checksum Part A Download 474f255cdf6da35f41824d2b8a00d076 Part B Download ef03d6ab52d14de38db23365e2e09308 Part C Download 532343bbb5f14ab14623c5cce5c8b930 Part D Download 78709823e18c3906e49b99536c5343de Part E Download abb5fcf3480f2899d09d0171b716026f Part F Download b311feea9705533350a030811501f859 Part G Download 37e525220e8d47bc7b8bee4753131390
Each part is 10GB. Download all parts and concatenate the files using the command cat lrw-v1* > lrw-v1.tar, and then uncompress by typing tar -xvf lrw-v1.tar. Train, validation and test sets are all contained in the package.
1.3 数据处理
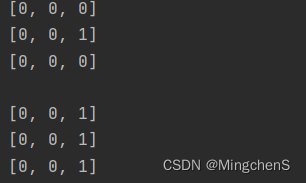
LRW数据集经过人脸定位和预裁切,嘴唇区域位于视频正中心,一般会再次中心裁切出一个96×96的区域,转换为灰度图,npz存储或pkl存储均可。LRW提供每一个样本的属性,记录在对应的txt文件中,有用的是最后一行duration属性,可依据此推断出word boundary,可参考以下代码:
def load_duration(self, file):
with open(file, 'r') as f:
lines = f.readlines()
for line in lines:
if line.find('Duration') != -1:
duration = float(line.split(' ')[1])
tensor = np.zeros(29)
mid = 29 / 2
start = int(mid - duration / 2 * 25)
end = int(mid + duration / 2 * 25)
tensor[start:end] = 1.0
return tensor2 LRW-1000 数据集
2.1 数据集介绍
LRW-1000 数据集是由中科院计算所、中国科学院大学和华中科技大学团队于 2018 年提出,旨在建立一个在室外环境下并且图像尺寸不一的大规模基准。该数据集涵盖了不同语音模式和成像条件下的自然变化,以应对实际应用中遇到的挑战。该数据集来源于中文电视节目,包含 1000 个类,每一个类对应由一个或几个汉字组成的汉语单词。该数据集是规模最大的中文单词唇读数据集,截取的镜头包括超过2000个说话人,将近 720000 个话语实例。该数据集数据的丰富性保证了深度学习模型得到充分的训练。同时,该数据集也是唯一一个公开的中文普通话唇读数据集。
LRW-1000是一个自然分布的大规模基准测试,用于在野外进行单词级别的语音阅读,包括1000个类和大约718,018个视频样本,这些样本来自2000多个个体演讲者。总共有100多万个汉字实例。每一类对应一个由一个或几个汉字组成的汉语单词的音节。此数据集的目的是涵盖不同语音模式和成像条件的自然变化,以结合在实际应用中遇到的挑战。在各个类别的样本数量、视频分辨率、光照条件以及说话人的姿态、年龄、性别、化妆等属性上都有很大的变化,如图1和图2所示。

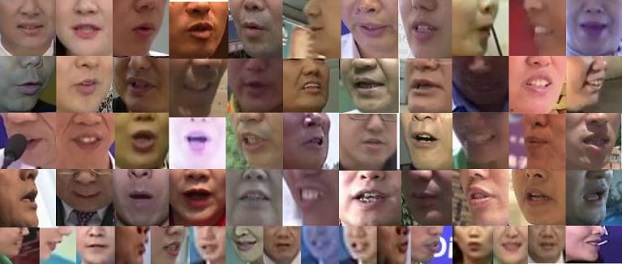
1000000汉字的实例
718,018个样本,平均每个类有718个样本
1000个类,每个类对应一个普通话单词的音节
2000多名不同的说话人,覆盖说话方式,包括语速、视点、年龄、性别、化妆等
3.评估协议
我们为实验提供了两个评价指标。A).由于这是一个分类任务,因此对所有1000个类的识别精度自然被视为基本度量。B).由于数据在许多方面表现出很大的多样性,例如每个类的样本数量,我们也提供了Kappa系数作为第二个评价指标。
数据集发布公告
实验室近日发布目前最大规模的中文词级唇读数据集LRW-1000。该数据集总计包含1000个中文词汇,总计大约718,018个样本。据我们所知,这是目前唇语识别领域规模最大的词级公开数据集,也是唯一公开的大规模中文唇语识别数据集。该数据集中视频序列均来源于电视节目,因此包含了复杂的变化条件,包括光照、说话人姿态、语速、视频分辨率等,是分布自然而极具挑战的唇读数据集。具体来说,LRW-1000具有以下特点:
- 关于说话人(Speakers):总计大约超过2000个不同的说话人,说话人的性别、姿态、年龄、化妆与否等均无限定,同时说话时的语速也未做严格限制,基本覆盖了自然场景下的说话情况。
- 关于数据样本(Word Samples):总计包含大约718,018个序列片段,每个序列片段对应于一个中文词汇,平均每个样本约0.3秒。在实际应用中大量存在的短词汇也正是研究的难点所在。
- 关于分辨率(Lip Region Resolution):该数据集取自各类电视节目,覆盖了较大的人脸分辨率范围,唇部区域分辨率从2020到300300不等,与实际应用情况基本相符。
注:其它详细信息请参考我们的论文:《LRW-1000: A Naturally-Distributed Large-Scale Benchmark for Lip Reading in the Wild》(https://arxiv.org/pdf/1810.06990.pdf)
考虑到数据集的难度,为方便进行唇语识别技术的对比与测试,我们分别依照说话人的姿态、唇部区域分辨率的大小以及每个中文词汇的长短,将数据划分为了不同难度的三个等级,如下:
在这里插入图片描述
综合来说,LRW-1000是目前最大的词级唇语识别数据集,也是目前唯一公开的大规模中文唇语识别数据集,欢迎各位同行申请使用。(联系邮箱:dalu.feng@vipl.ict.ac.cn; shuang.yang@ict.ac.cn)
数据集官网地址:Lip Reading: CAS-VSR-W1k (The original LRW-1000)
2.2 数据获取
lrw1 -1000数据库仅供大学和研究机构研究之用。如欲索取资料库副本,请按下列方法办理:
下载数据库发布协议[pdf],仔细阅读,并适当完成。请注意,协议必须由全职工作人员签署(即不接受学生)。然后将签署好的协议扫描后发送到lipreading@vipl.ict.ac.cn。收到您的回复后,我们会提供下载链接给您。
3 LRS2数据集
3.1 数据集介绍:
The dataset consists of thousands of spoken sentences from BBC television. Each sentences is up to 100 characters in length. The training, validation and test sets are divided according to broadcast date. The dataset statistics are given in the table below.

The utterances in the pre-training set correspond to part-sentences as well as multiple sentences, whereas the training set only consists of single full sentences or phrases. There is some overlap between the pre-training and the training sets.
Although there might be some label noise in the pre-training and the training sets, the test set has undergone additional verification; so, to the best of our knowledge, there are no errors in the test set.
| Set | Dates | # utterances | # word instances | Vocab |
| Pre-train | 11/2010-06/2016 | 96,318 | 2,064,118 | 41,427 |
| Train | 11/2010-06/2016 | 45,839 | 329,180 | 17,660 |
| Validation | 06/2016-09/2016 | 1,082 | 7,866 | 1,984 |
| Test | 09/2016-03/2017 | 1,243 | 6,663 | 1,698 |
Important: We have renamed the dataset to LRS2, in order to differentiate it from the LRS and the MV-LRS datasets described in [1] and [2]. The contents of this webpage and the dataset remains the same.
LRS2数据集官网:The Oxford-BBC Lip Reading Sentences 2
3.2 获取方式
- 根据网站https://www.bbc.co.uk/rd/projects/lip-reading-datasets提示,获取word版数据集申请文件,在文件最后签署使用协议,使用邮箱发送到该网站指定邮箱,等待一两天即可收到带有用户名和密码的邮件。
- 点击上图中“Download”链接,使用用户名密码登陆,即可下载数据集。共计50GB左右,下载所需时间较长。
The package including the videos and the metadata is available for non-commercial, academic research. You will need to sign a Data Sharing agreement with BBC Research & Development before getting access. To download a copy of the agreement please go to the BBC Lip Reading in the Wild and Lip Reading Sentences in the Wild Datasets page. Once approved, you will be supplied with a password, and the package can then be downloaded below. Please cite [1] below if you make use of the dataset.
For all technical questions, please contact the author of [1].
File MD5 Checksum Part A Download 076acd9849425cf0e4ddfe0e8891e1a7 Part B Download 602f0ac4f9f9f150b81a9fdf073ae345 Part C Download c6e884d365cbcf840c4a8dd74dbfb535 Part D Download 8e53fc6260b244e71dafa71cd1f7eb5e Part E Download 18b715baad746cab5c803984cb97931e Filelist: Pretrain Download 6b05788d6a16166c15cdee5cfd8bbbd6 Filelist: Train Download ae240cd86c8432afb5a6b8935c863f24 Filelist: Val Download 3b7502de5c102519d62477f209c4cd35 Filelist: Test Download e76bb897a2141f3581266daa850966bc Each part is approximately 10GB. Download all parts and concatenate the files using the command cat lrs2_v1_parta* > lrs2_v1.tar.
3.3 数据处理
首先用cat命令拼接文件,之后用tar命令解压文件,即可得到完整数据集。linux直接使用即可,windows安装git bash再进行解压,可参考windows下Git BASH安装。进入分区文件所在的目录,使用此命令进行拼接(注意将名改为对应的数据集名)。
cat lrs2_v1_parta* > lrs2_v1.tar
tar -xvf lrs2_v1.tar
3.4 解析数据集
代码来源:https://github.com/Rudrabha/Wav2Lip/blob/master/preprocess.py
import sys
if sys.version_info[0] < 3 and sys.version_info[1] < 2:
raise Exception("Must be using >= Python 3.2")
from os import listdir, path
if not path.isfile('face_detection/detection/sfd/s3fd.pth'):
raise FileNotFoundError('Save the s3fd model to face_detection/detection/sfd/s3fd.pth \
before running this script!')
import multiprocessing as mp
from concurrent.futures import ThreadPoolExecutor, as_completed
import numpy as np
import argparse, os, cv2, traceback, subprocess
from tqdm import tqdm
from glob import glob
import audio
from hparams import hparams as hp
import face_detection
parser = argparse.ArgumentParser()
parser.add_argument('--ngpu', help='Number of GPUs across which to run in parallel', default=1, type=int)
parser.add_argument('--batch_size', help='Single GPU Face detection batch size', default=32, type=int)
parser.add_argument("--data_root", help="Root folder of the LRS2 dataset", required=True)
parser.add_argument("--preprocessed_root", help="Root folder of the preprocessed dataset", required=True)
args = parser.parse_args()
fa = [face_detection.FaceAlignment(face_detection.LandmarksType._2D, flip_input=False,
device='cuda:{}'.format(id)) for id in range(args.ngpu)]
template = 'ffmpeg -loglevel panic -y -i {} -strict -2 {}'
# template2 = 'ffmpeg -hide_banner -loglevel panic -threads 1 -y -i {} -async 1 -ac 1 -vn -acodec pcm_s16le -ar 16000 {}'
def process_video_file(vfile, args, gpu_id):
video_stream = cv2.VideoCapture(vfile)
frames = []
while 1:
still_reading, frame = video_stream.read()
if not still_reading:
video_stream.release()
break
frames.append(frame)
vidname = os.path.basename(vfile).split('.')[0]
dirname = vfile.split('/')[-2]
fulldir = path.join(args.preprocessed_root, dirname, vidname)
os.makedirs(fulldir, exist_ok=True)
batches = [frames[i:i + args.batch_size] for i in range(0, len(frames), args.batch_size)]
i = -1
for fb in batches:
preds = fa[gpu_id].get_detections_for_batch(np.asarray(fb))
for j, f in enumerate(preds):
i += 1
if f is None:
continue
x1, y1, x2, y2 = f
cv2.imwrite(path.join(fulldir, '{}.jpg'.format(i)), fb[j][y1:y2, x1:x2])
def process_audio_file(vfile, args):
vidname = os.path.basename(vfile).split('.')[0]
dirname = vfile.split('/')[-2]
fulldir = path.join(args.preprocessed_root, dirname, vidname)
os.makedirs(fulldir, exist_ok=True)
wavpath = path.join(fulldir, 'audio.wav')
command = template.format(vfile, wavpath)
subprocess.call(command, shell=True)
def mp_handler(job):
vfile, args, gpu_id = job
try:
process_video_file(vfile, args, gpu_id)
except KeyboardInterrupt:
exit(0)
except:
traceback.print_exc()
def main(args):
print('Started processing for {} with {} GPUs'.format(args.data_root, args.ngpu))
filelist = glob(path.join(args.data_root, '*/*.mp4'))
jobs = [(vfile, args, i%args.ngpu) for i, vfile in enumerate(filelist)]
p = ThreadPoolExecutor(args.ngpu)
futures = [p.submit(mp_handler, j) for j in jobs]
_ = [r.result() for r in tqdm(as_completed(futures), total=len(futures))]
print('Dumping audios...')
for vfile in tqdm(filelist):
try:
process_audio_file(vfile, args)
except KeyboardInterrupt:
exit(0)
except:
traceback.print_exc()
continue
if __name__ == '__main__':
main(args)4 GRID 数据集
4.1 数据集介绍
GRID 数据集是由美国谢菲尔德大学团队于2006 年提出,旨在为语音感知和自动语音识别研究提供实验数据。该数据集在实验室环境下录制,只有 34 个志愿者,这在大型数据集中人数算比较少的,但每个志愿者说 1000 个短语,共 34000个话语实例。该数据集短语构成符合一定的规律,每个短语包含 6 个单词,不是常见的短语,而是在 6 类单词中每类随机挑选一个组成随机短语。这 6 类单词分别是“命令”、“颜色”、“介词”、“字母”、“数字”和“副词”,例如:Bin blueat A 1 again。每类单词规定了数量,单词总数共 51 个。数据集是完全公开的,不需要与发布者联系,也不需要填写保密协议即可在网上下载使用。
数据集官网地址:The GRID audiovisual sentence corpus
4.2 数据集获取
| talker | 25 kHz endpointed audio (about 100M each) | raw 50 kHz audio (300M each) | video (normal) (480 M each) | video (high, pt1) (1.2 G each) | video (high, pt2) (1.2 G each) | word alignments (190 K each) |
|---|---|---|---|---|---|---|
| 1 | download | download | download | download | download | download |
| 2 | download | download | download | download | download | download |
| 3 | download | download | download | download | download | download |
| 4 | download | download | download | download | download | download |
| 5 | download | download | download | download | download | download |
| 6 | download | download | download | download | download | download |
| 7 | download | download | download | download | download | download |
| 8 | download | download | download | download | download | download |
| 9 | download | download | download | download | download | download |
| 10 | download | download | download | download | download | download |
| 11 | download | download | download | download | download | download |
| 12 | download | download | download | download | download | download |
| 13 | download | download | download | download | download | download |
| 14 | download | download | download | download | download | download |
| 15 | download | download | download | download | download | download |
| 16 | download | download | download | download | download | download |
| 17 | download | download | download | download | download | download |
| 18 | download | download | download | download | download | download |
| 19 | download | download | download | download | download | download |
| 20 | download | download | download | download | download | download |
| 21 | download | download | Oops! No video | Oops! No video | Oops! No video | download |
| 22 | download | download | download | download | download | download |
| 23 | download | download | download | download | download | download |
| 24 | download | download | download | download | download | download |
| 25 | download | download | download | download | download | download |
| 26 | download | download | download | download | download | download |
| 27 | download | download | download | download | download | download |
| 28 | download | download | download | download | download | download |
| 29 | download | download | download | download | download | download |
| 30 | download | download | download | download | download | download |
| 31 | download | download | download | download | download | download |
| 32 | download | download | download | download | download | download |
| 33 | download | download | download | download | download | download |
| 34 | download | download | download | download | download | download |






![[UI5 常用控件] 05.FlexBox, VBox,HBox,HorizontalLayout,VerticalLayout](https://img-blog.csdnimg.cn/direct/9382617aa00640019700dce227df4fa5.png)