BEV感知算法学习
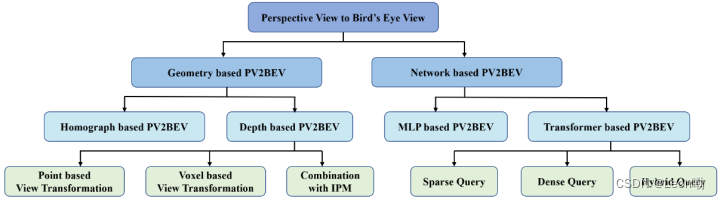
3D目标检测系列
Mono3D(Monocular 3D Object Detection for Autonomous Driving)
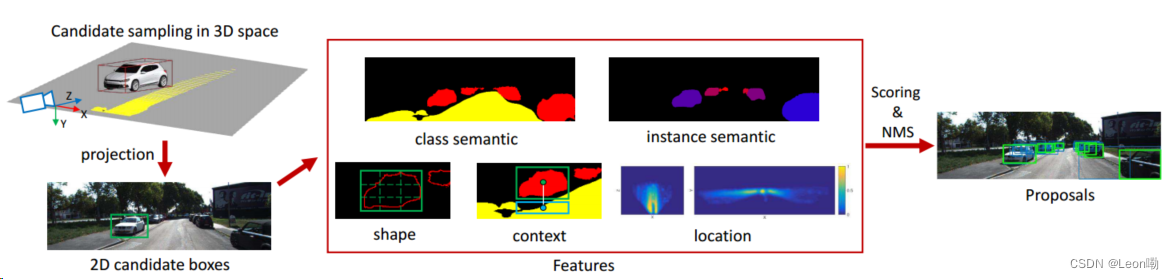
流程:
- 通过在地平面上假设先验,在3D空间中对具有典型物理尺寸的候选边界框进行采样;
- 然后我们将这些方框投影到图像平面上,从而避免了图像中的多尺度搜索;
- 我们通过利用多个特征对候选框进行评分:类语义、实例语义、轮廓、对象形状、上下文和位置先验;
- 经过非极大值抑制,得到最终的目标建议集。
PointPillars: Fast Encoders for Object Detection from Point Clouds
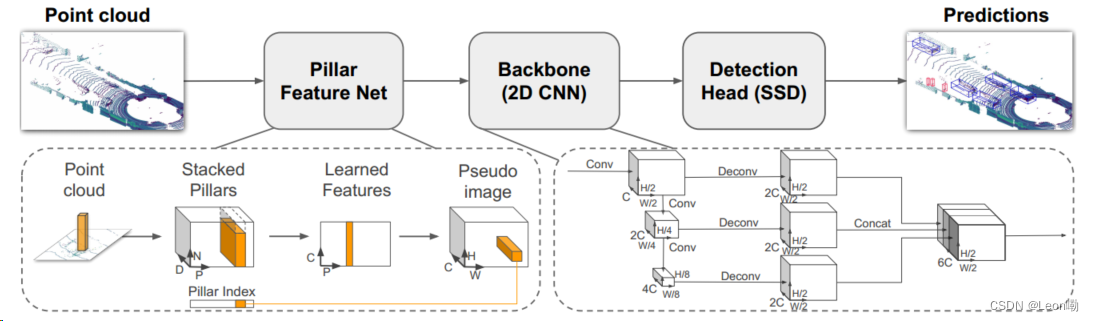
三大步骤:
① 特征编码器将点云转化为稀疏伪图像;
所谓伪图像就是从一个3D柱到图像的过程,即利用3d柱的9维特征表示图像的通道,利用柱子的数量和每个柱子里点的数量来表示图像的高和宽,再添加卷积层和激活函数处理这些点得到(C,P,N)大小的tensor,然后在N的维度执行max函数得到输出tensor维度大小(C, P),再将得到的特征分散到原始的柱子位置,就可以得到(C, H, W)大小的伪图像。
② 2D卷积骨干网络将伪图像处理为高级表示;
Backbone和VoxelNet类似,包含两个子网络,一个自上而下的网络以越来越小的空间分辨率产生特征,而第二个网络执行自上而下特征的上采样和级联。
③ 一个检测头检测回归3D框。
采用SSD检测头。
BEV系列
- LSS(Lift, Splat, Shoot: Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting to 3D)
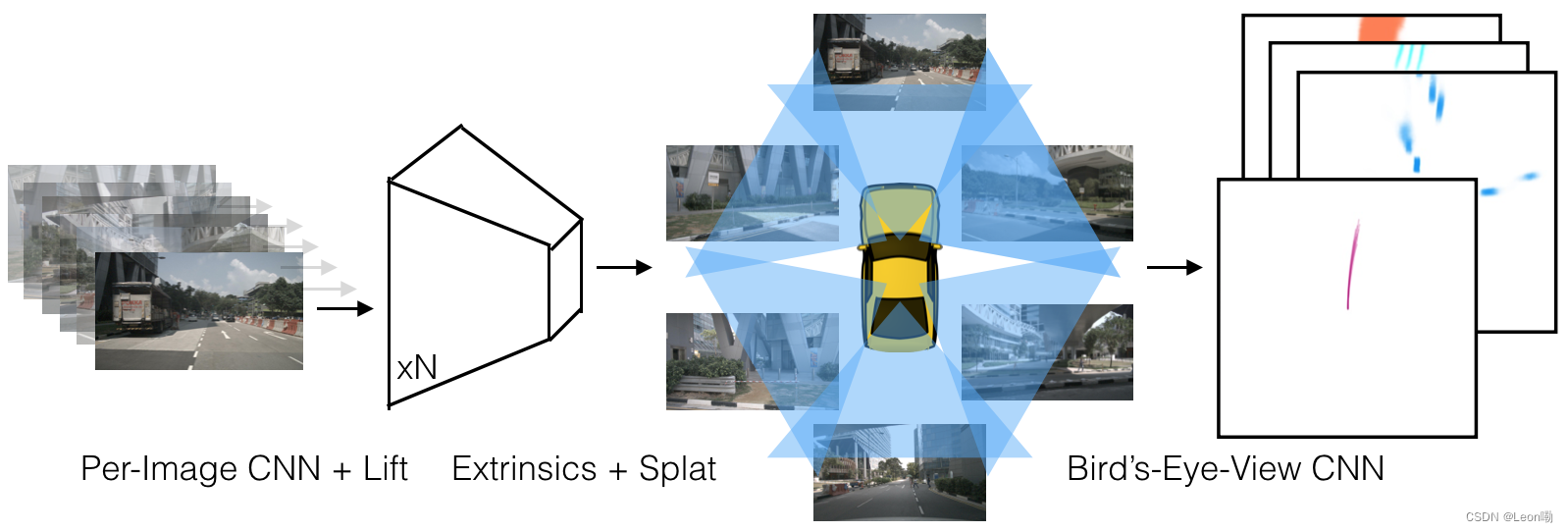
三个步骤:Lift, Splat, Shoot
1. Lift
目的:将图像从二维坐标系提升到所有相机共享的三维帧。
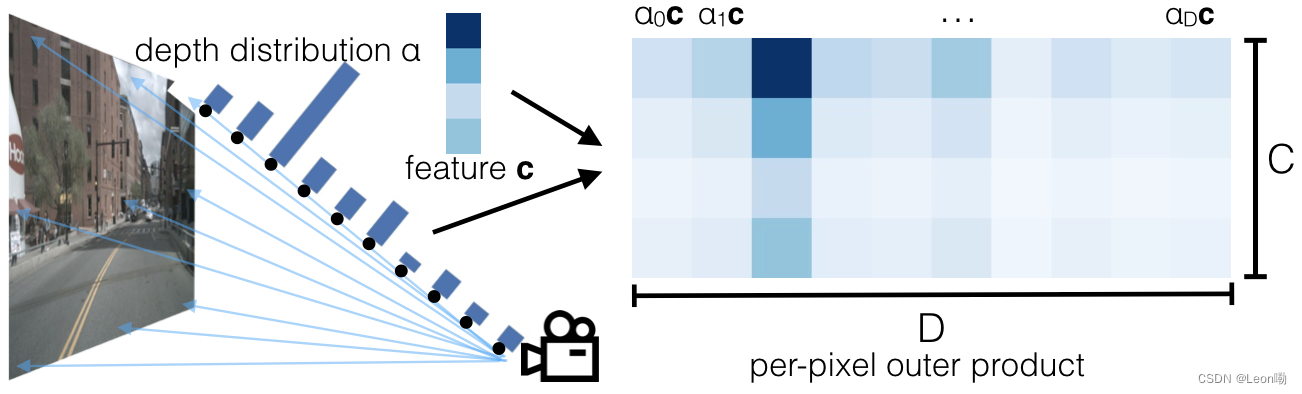
每个像素都分配了一组离散的深度,这样整个图像的维度就是D×H×W(跟点云一样)。对于每个像素p,网络预测了一个上下文向量c和深度分布α,点
p
d
p_{d}
pd处的特征
c
d
c_{d}
cd就可以表示为:
c
d
=
α
d
c
c_{d} = α_{d}c
cd=αdc也就是说,射线上每个点的特征由α和c的外积决定。
通过lift操作可以得到一个frustum形状的点云。
2. Splat:Pillar Pooling
参考PointPillars建立Pillar柱子,执行sum pooling操作产生C×H×W大小的tensor,可以被CNN处理用于BEV推理。
3. Shoot: Motion Planning
所谓规划即为预测车辆在K个模板轨迹上的分布,参考NMP(Neural Motion Planner)。
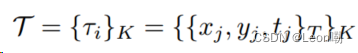
其中分布满足如下的形式,训练时即为减小模板和真实轨迹之间的损失: