1、最新的几款图像生成网络
-
eCNN
文献:Bahrami A, Karimian A, Fatemizadeh E, et al. A new deep convolutional neural network design with efficient learning capability: Application to CT image synthesis from MRI[J]. Medical physics, 2020, 47(10): 5158-5171. -
经典的pix2pix
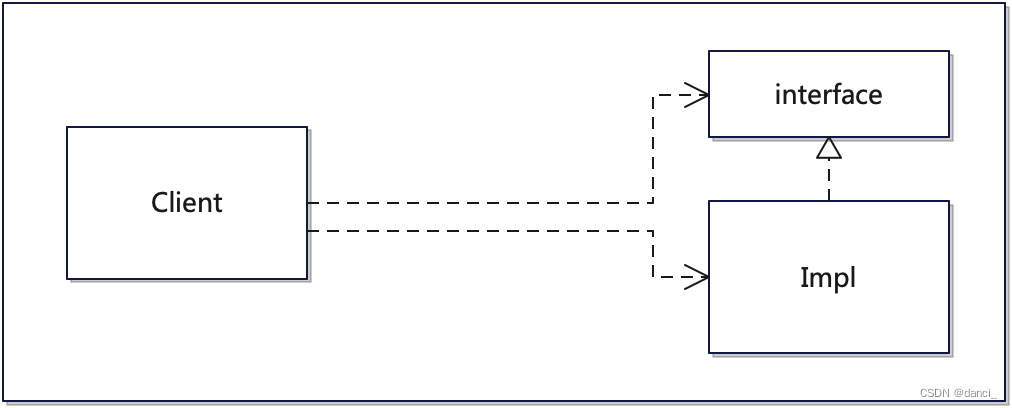
pix2pix是一种基于条件式生成对抗网络(CGAN)的图像转译模型,而条件式生成抵抗网络是生成对抗网络的一种扩展,它通过在生成器和判别器中引入条件信息来实现有条件的图像生成。生成器采用U-Net网络结构,融合底层细粒度特征和高层抽象;判别器采用patchGAN网络结构,在图块尺度提取纹理等高频信息。
那么简笔画猫转成真猫到底是一个什么原理腻,可以这样理解:你可以获取很多真猫的图片,用opencv的边缘提取,把每一张图片的边缘都给提取出来,构建一个像素到像素的映射数据集,也就是数据集包含两类图片,一类是边缘轮廓简笔画,另一类是真猫的图片,它们俩是一一对应的关系,所以pix2pix解决的是一个像素配对的图像转译问题,那么我们上次介绍的cyclegan呢解决的是一个非配对的图像转译问题。同样,这里也能用cyclegan来解决这些问题。image translation领域非常的好玩,既可以用配对的数据集去训练,也可以用不配对的数据集。
pix2pix是2017年的论文,现在看来比较老了,如果你现在还想做跟图像转译相关的项目的话,可以用更好更新的算法,比如UGATIT、StarGAN等。当然用pix2pix也是完全可以滴,但是要注意pix2pix使用起来可能会容易模式崩溃,训练不太稳定喔文献:Isola P, Zhu J Y, Zhou T, et al. Image-to-image translation with conditional adversarial networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 1125-1134.
pix2pix代码:https://github.com/phillipi/pix2pix
-
MedGAN,用GAN对医学成像进行迁移
MedGAN框架用Cas- Net作为生成器,通过一个对抗判别器从感知和像素角度进行惩罚,同时使用一个预先训练的特征提取器,以确保转换后的输出在样式、纹理和内容上与所需的目标图像匹配。
使用VGG-19网络作为特征抽取器,在ImageNet上做预训练。由5个卷积块组成,每个卷积块由2-4层和3个完全连接的层组成。虽然是在非医学图像上预训练的,但是VGG-19网络提取的特征在表示纹理和样式信息方面是有益的。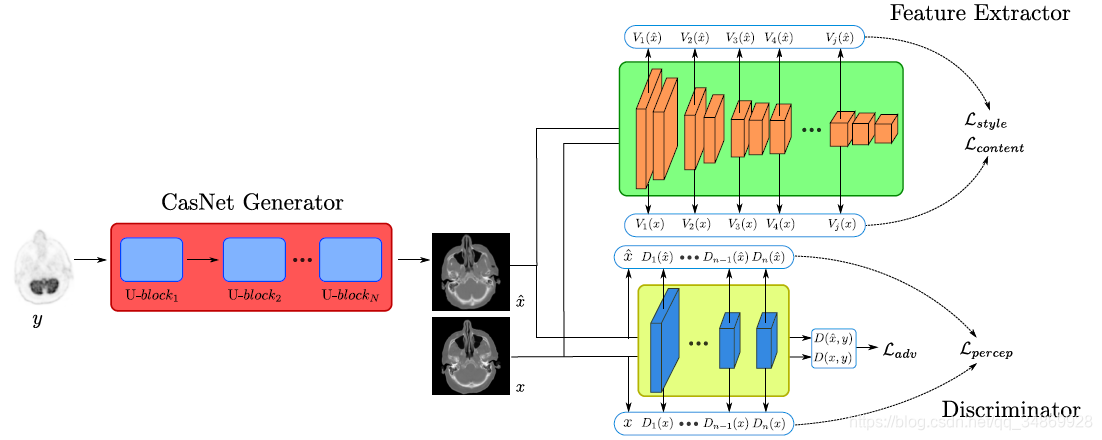
文献:Armanious K, Jiang C, Fischer M, et al. MedGAN: Medical image translation using GANs[J]. Computerized medical imaging and graphics, 2020, 79: 101684. -
TransUNet:Transformers Make Strong Encoders for Medical Image Segmentation用于医疗图像分割的transformers编码器详解
设计的Idea:UNet +transformers的结合体,使用的具体模块:ViT+ResNet50+skip connection。
文献:Chen J, Lu Y, Yu Q, et al. Transunet: Transformers make strong encoders for medical image segmentation[J]. arXiv preprint arXiv:2102.04306, 2021.
参考解析:https://blog.csdn.net/weixin_43656644/article/details/123563646 -
CGAN:
-传统的GAN或者其他的GAN都是通过一堆的训练数据,最后训练出了G网络,随机输入噪声最后产生的数据是这些训练数据类别中之一,我们提前无法预测是那哪一个?
因此,我们有的时候需要定向指定生成某些数据,比如我们想让G生成飞机,数字9,等等的图片数据。
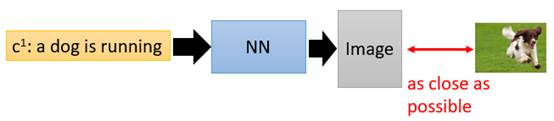
假设现在要做一个项目:输入一段文字,输出一张图片,要让这张图片足够清晰并且符合这段文字的描述。我们搭建一个传统的NeuralNetwork(下称NN)去训练。
考虑我们输入的文字是“train”,希望NN能输出清晰的火车照片,那在数据集中,下面左图是正面的火车,它们统统都是正确的火车图片;下面右图是侧面的火车,它们也统统都是正确的火车。


那在训练这个NN的时候,network会觉得说,火车既要长得像左边的图片,也要长得像右边的图片,那最终network的output就会变成这一大堆images的平均,可想而知那会是一张非常模糊并且错误的照片。
我们需要引入GANs技术来保证NN产生清晰准确的照片。
我们把原始的NN叫做G(Generator),现在它吃两个输入,一个是条件word:c,另外一个是从原始图片中sample出的分布z,它的输出是一个image:x,它希望这个x尽可能地符合条件c的描述,同时足够清晰,如下图。
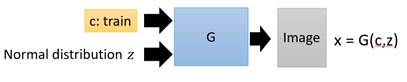
在GANs中为了保证输出image的质量会引入一个D(Discriminator),这个D用来判断输入的x是真实图片还是伪造图片,如下图。

但是传统GANs只能保证让x尽可能地像真实图片,它忽略了让x符合条件描述c的要求。于是,为了解决这一问题,CGAN便被提出了。
我们的目的是,既要让输出的图片真实,也要让输出的图片符合条件c的描述。Discriminator输入便被改成了同时输入c和x,输出要做两件事情,一个是判断x是否是真实图片,另一个是x和c是否是匹配的。

比如说,在下面这个情况中,条件c是train,图片x也是一张清晰的火车照片,那么D的输出就会是1。

而在下面两个情况中,左边虽然输出图片清晰,但不符合条件c;右边输出图片不真实。因此两种情况中D的输出都会是0。
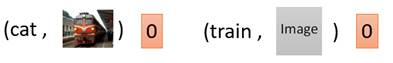
那CGAN的基本思路就是这样,下面我们具体看一下CGAN的算法实现。

因为CGAN是supervised学习,采样的每一项都是文字和图片的pair。CGAN的核心就是判断什么样的pair给高分,什么样的pair给低分。
参考资料:
- https://blog.csdn.net/weixin_44751294/article/details/117451095
- 李宏毅老师的b站视频
- https://blog.csdn.net/a312863063/article/details/83573968
- https://blog.csdn.net/qq_29367075/article/details/109149211