盘点本年度探索对外服务的百万请求量的API网关设计实现
- 背景介绍
- 高性能API网关
- API网关架构优化
- 多级缓存架构设计
- 多级缓存富客户端
- 漏斗模型数据读取架构
- 异步刷新过期缓存
- 网关异步化调用模型
- 高性能批量API调用(减少对于网关的交互和通信)
- 并行调用和请求合并的策略
- 多维度流量控制
- 规则分配和归属分组
- 动态调整规则和热插拔
- 良好控制网络拥塞
背景介绍
公司对外开放的OpenAPI-Server服务,作为核心内部系统与外部系统之间的重要通讯枢纽,每天处理数百万次的API调用、亿级别的消息推送以及TB/PB级别的数据同步。经过多年流量的持续增长,该服务体系依然稳固可靠,展现出强大的负载能力。
高性能API网关
各个业务系统如商品中心、交易平台和用户中心等,均独立运作并持有各自的数据。为了实现这些系统间的数据交换,我们采用Dubbo3以及OpenFegin作为通讯框架。
为了确保数据的安全与可控性,我们面临着一个挑战:如何将这些数据开放给外部客户,以共同构建一个数据共享的数据平台化体系。
API网关架构优化
API网关通过采用管道设计模式,高效处理业务逻辑、安全保障、服务路由和调用等关键任务。为应对高并发请求,网关在架构上进行了针对性的优化,以确保能够应对近百万峰值QPS的挑战。
主要集中在以下这几点:
该架构能够支持千万级QPS(Queries Per Second)的请求。这意味着它被设计为能够处理大量的并发请求,这通常与高可用性、高性能的系统相关。
多级缓存架构设计
在API调用链路中,对元数据的获取至关重要,涉及多个关键信息,如API的流控信息、字段等级、类目详情、APP密钥、IP白名单、权限包数据以及用户授权信息等。在高并发场景下,元数据获取的QPS需求高达千万级别,因此优化元数据获取的性能成为API网关的核心挑战。
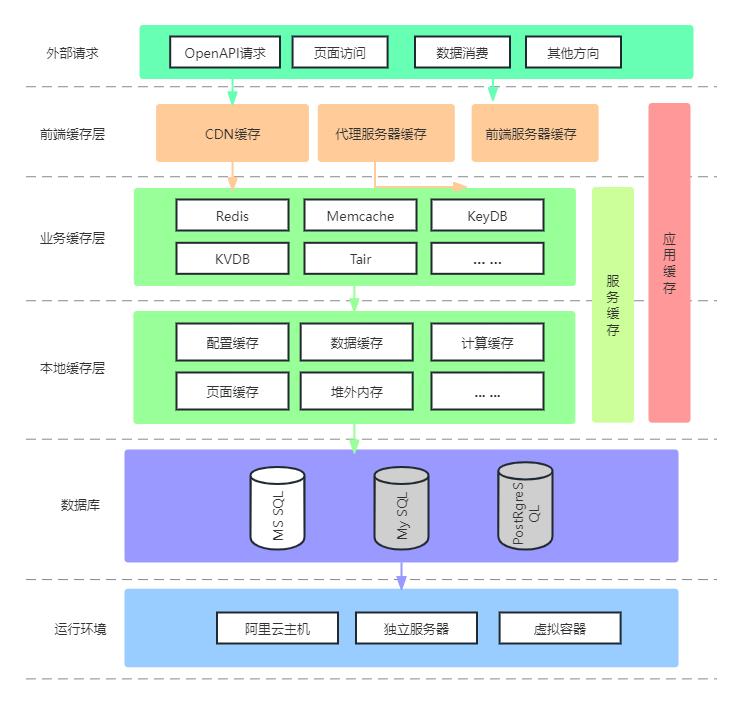
多级缓存架构:主要涉及元数据的读取,并为此采用了富客户端多级缓存的设计,这种设计的主要目的是为了提高数据读取的效率并减少对原始数据源的直接访问,缓存能够存储常用的数据,从而在需要时快速提供,而不是每次都去原始位置获取。
“多级”意味着缓存被设计为多层次,每一层都比前一层更接近数据源。这种层次结构可以更好地管理数据的生命周期,并能够逐层缓存数据。
多级缓存富客户端
在面临千万级QPS的元数据读取需求时,直接将所有请求打到数据库是不可取的,即便数据库已经进行了分库分表的处理。为了提升性能和响应速度,我们在数据库之前增加了一层分布式缓存,用于缓解数据库的压力。
-
LRU(Least Recently Used)规则的本地缓存:支撑千万级QPS的读取需求意味着需要部署近百台缓存服务器,这不仅增加了硬件成本,还可能因为过多的网络请求而导致性能瓶颈。为了进一步提升效率和降低成本,在分布式缓存之前引入了基于LRU(Least Recently Used)规则的本地缓存。这种策略能够优先保留最近访问的数据,从而最大限度地减少了对分布式缓存和数据库的访问次数。
-
防止缓存被击穿:即当缓存中没有数据且数据库中也没有数据时,大量的请求会直接打到数据库上,我们在本地缓存之前增加了一层BloomFilter。
BloomFilter作为一种空间效率极高的概率数据结构,能够快速地判断一个元素是否可能存在于某个集合中,从而避免了不必要的数据库查询。
漏斗模型数据读取架构
构建了一套基于漏斗模型的元数据读取架构,如下图所示。该架构中的缓存控制中心能够动态地推送缓存规则,包括数据是否进行缓存、缓存时长以及本地缓存的大小等。
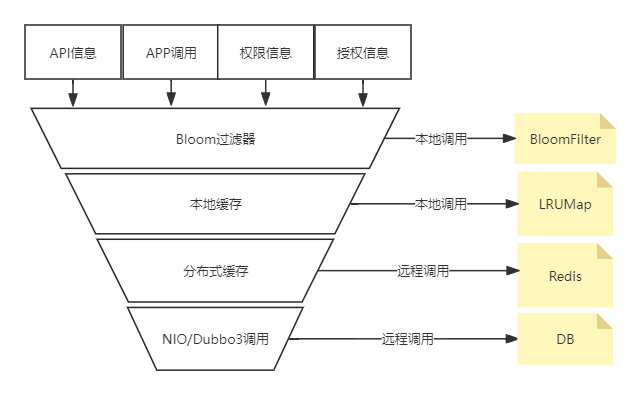
此外,为了解决缓存数据过期时可能出现的并发请求问题,网关会容忍在极端情况下拿到过期的元数据。由于大多数情况下对数据的时效性要求不高,这种策略能够有效地避免缓存数据过期导致的性能问题。同时,网关会异步提交任务来更新数据信息,确保数据的准确性和时效性。
异步刷新过期缓存
当某些数据过期或不再有效时,不是立即从源头重新获取,而是安排在后台异步地进行刷新。这种方式可以确保前台的服务或应用不受数据过期的影响,继续提供快速的数据访问。

网关异步化调用模型
同步调用受限于线程数量,而线程资源宝贵,在 API 网关这类高并发应用场景下,一定比例的 API 超时就会让所有调用的 RT 升高,异步化的引入彻底的隔离 API 之间的影响。
-
前置校验与请求分发
- 当外部请求到达网关时,首先由Servlet线程进行API调用的前置校验。这一步骤包括验证请求参数、权限检查等。
- 若校验通过,Servlet线程将根据业务逻辑决定使用Dubbo或HTTP NIO client发起远程服务调用。
- Dubbo或HTTP NIO client负责建立连接、发送请求,并等待远程服务的响应。在此过程中,Servlet线程被释放,不再阻塞。
-
异步响应处理
- 一旦Dubbo3或HTTP请求获得响应,系统以事件驱动的方式通知Worker工作线程池。这种通知机制确保了响应处理的高效和即时性。
- Worker工作线程从线程池中获取任务,并基于响应结果和API请求的上下文信息进行后续的数据处理。这可能包括数据转换、业务逻辑处理、结果封装等。
-
异步输出与响应
- 数据处理完成后,Servlet 3.0的异步处理特性被激活。这允许网关在不阻塞Servlet线程的情况下,将处理结果输出给外部调用请求。
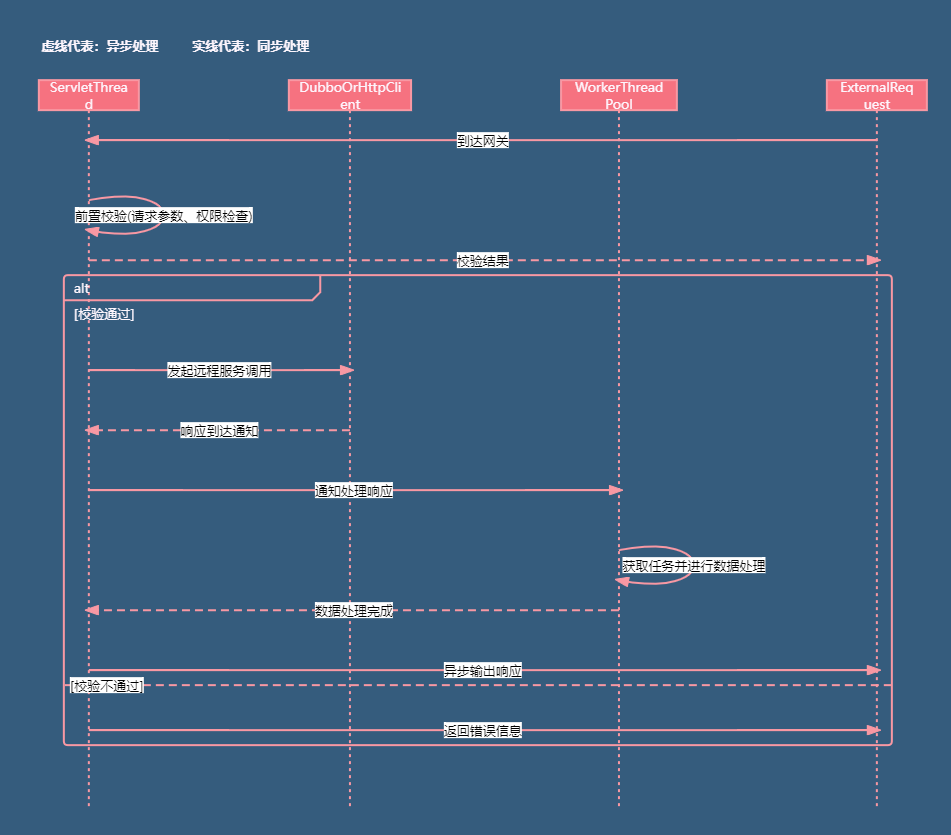
此架构流程通过前置校验、异步远程服务调用、事件驱动的工作线程处理以及Servlet 3.0的异步输出,实现了请求的全异步化处理。这不仅提高了系统的并发性能,还优化了资源利用,使得网关能够高效、稳定地处理大量外部请求。
- 数据处理完成后,Servlet 3.0的异步处理特性被激活。这允许网关在不阻塞Servlet线程的情况下,将处理结果输出给外部调用请求。
高性能批量API调用(减少对于网关的交互和通信)
在高并发场景下,OpenAPI-Server系统面临着巨大的挑战。为了提高OpenAPI-Server处理请求API的性能,降低请求响应时间和网络消耗,我们采取了一系列措施。
并行调用和请求合并的策略
需要调用多个API才能完成某项业务的逻辑单元。传统的串行调用模式会导致较长的响应时间(RT)和过多的网络报文传输,特别是在网络环境不稳定的情况下,这一问题更加突出。
如下图所示:
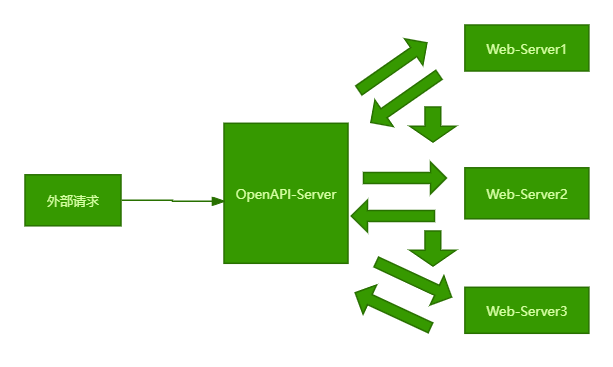
为了优化这一流程,我们提出了并行调用和请求合并的策略。通过并行调用,多个API可以同时被请求,从而显著减少总体响应时间。如下图所示:
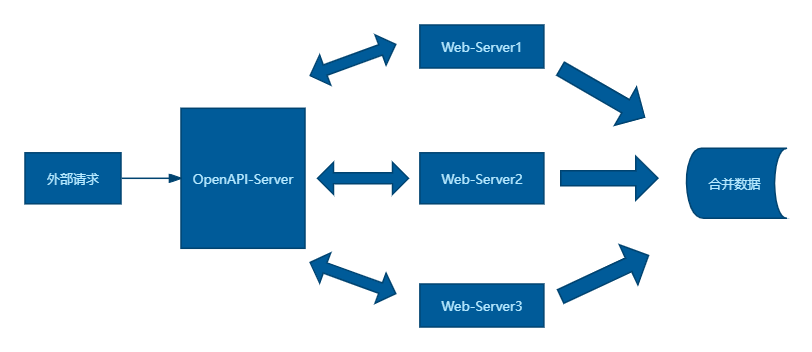
而请求合并则能够将多个API请求合并为一个,减少不必要的网络传输和报文重复,进一步降低网络消耗。
多维度流量控制
API网关面临日调用量高达百万及千万的挑战,尤其在业务热期,调用基数庞大、调用者众多,且各API服务能力不均。为确保各API稳定服务,不被流量冲垮,多维度流量控制成为API网关的关键环节。
提供包括API每秒流控、单日调用量控制及APPKEY单日调用量控制等在内的通用流量控制规则。流量控制面临特殊挑战,如单个API能力有限,无法满足实际调用需求。
规则分配和归属分组
API网关通过流量分组策略,灵活配置各组别比例,确保核心业务调用优先通过。核心调用放入分组1,实时性要求高的调用放入分组2,其余放入分组3。
动态调整规则和热插拔
此策略提高了核心和实时性要求高的调用的成功率。此外,API网关支持插件化,可编写自定义流控插件并动态部署,通过Groovy脚本或表达式定义规则,满足多样流控需求。
良好控制网络拥塞
此外,架构不仅仅关注数据处理和缓存,还考虑到了网络环境的优化。在物理环境中,特别是机房中,网络拥塞可能会影响数据的传输速度和系统的整体性能。该架构通过其设计和实践,有效地管理和减轻了网络拥塞的影响,确保了数据传输的效率和稳定性。

高度优化和考虑全面的架构设计,旨在提高数据访问速度、处理高并发请求,并确保在网络环境中的稳定性和性能,这个部分会针对于细节放在单独的运维篇去调整和设计说明。